


Vivere nel Nuovo Mondo
Abituare la propria creatività ai cambiamenti esponenziali del nuovo mondo


Apro questo secondo numero di Tales from the Latent Space ringraziando tutte le persone che hanno deciso di abbonarsi e darmi fiducia, siamo già quasi in 50!
Sono fermamente convinto che questo progetto abbia tutto il potenziale per diventare una delle newsletter più lette d’Italia, ed espandersi fino a diventare un vero e proprio magazine digitale. Ma per raggiungere certi traguardi ho bisogno anche del vostro supporto, e vi chiedo quindi un semplice favore: Fate conoscere il progetto a tutte le persone che possono essere interessate!
Come avrete già appurato dalla pubblicazione del mese scorso, e ancor di più da questo secondo numero, qui c’è davvero tanto valore che merita di essere scoperto da chiunque possa trarne dei benefici.
Ma oltre a questo, non trovate che sia bellissimo poter parlare con gli altri di ciò che ci accomuna? Se anche i vostri amici, colleghi, conoscenti, fossero iscritti a questa newsletter, avreste dei nuovi argomenti di conversazione ogni mese!
Ora però direi di non indugiare oltre, perché il treno sta per partire…

Che cos’è un LoRA?
Nel numero precedente, vi ho portato all'interno un’immensa biblioteca virtuale, lo spazio latente, dove i libri (i dati) sono stati catalogati in modi che solo un'intelligenza artificiale può comprendere appieno. Oggi continuiamo il nostro viaggio con un altro elemento utile a comprendere meglio l’IA: i LoRA (Low-Rank Adaptation).
E per farlo, vorrei aggiungere un po’ più di storytelling rispetto alla volta scorsa. Chiedo quindi perdono fin da subito se, nello spiegare questo concetto complesso, mi perderò in aggettivi e descrizioni poco funzionali alla spiegazione in sé, ma penso che possa risultare più divertente e fruibile per buona parte di chi legge. In oltre, scrivere in questo modo mi conferisce un discreto tono da autore intellettuale che proprio schifo non mi fa.
Ora immaginiamo di essere nuovamente all’interno di quell’enorme biblioteca detta Spazio Latente, della quale stiamo esplorando i suoi vasti scaffali, attentamente catalogati e interconnessi tra loro. In questo spazio incantato, che sfugge alle normali leggi universali, tutto è possibile. Mentre fluttuiamo senza meta tra le miriadi di informazioni che ci circondano, e che sembrano permeare l’aria digitale che respiriamo, non riusciamo a trattenere la meraviglia che ci irradia dalle viscere, e ci fa scendere una lacrima.
La goccia salata, che ci cade dal volto dopo aver attraversato la gota sinistra, invece che seguire la gravità come ci aspetteremmo, inizia a fluttuare tra gli scaffali insieme a noi, iniziando a emettere anche una calda luce dorata. La lacrima ci gira attorno, e la seguiamo con lo sguardo finché non si schianta contro uno scaffale posto poco sopra di noi. Nel farlo, emette un leggero sibilo simile a quello di un flauto tibetano, che porta istantaneamente alla nostra attenzione qualcosa di insolito, che turba lievemente la nostra quiete e ci fa focalizzare su altri dettagli che prima non vedevamo.
Ci sono alcuni scaffali molto incompleti, e altri semplicemente poco rappresentativi rispetto a tutta la letteratura esistente sull’argomento che abbiamo davanti. Notiamo poi che la disponibilità di informazioni è aggiornata solo fino a una certa data, e che tutto ciò che è stato prodotto dopo non è presente nella biblioteca.
Tutto d’un tratto, quella che prima ci sembrava essere la biblioteca migliore di sempre, ci appare incompleta e la magia che ci ha avvolto fino a quel momento scompare all’improvviso, facendoci cadere a terra come un umano qualunque. Siamo profondamente delusi da questa scoperta, e rimaniamo a rimuginare sul pavimento di legno, domandandoci: perché? perché tutta questa meraviglia è così incompleta?
Vorremmo degli scaffali più forniti, e dei libri più specifici, che considerino tutti i nostri interessi e necessità, ma non sappiamo come risolvere questo problema. D’altronde, siamo solo degli umili esploratori dello spazio latente, che hanno ancora molto da imparare sul funzionamento di questo reame incantato. A un certo punto però, quando stiamo per tornare alla nostra realtà quotidiana, un lampo di luce bianca emerge dal soffitto, avvolgendo noi e ogni scaffale della biblioteca. Risulta così intenso da costringerci a chiudere gli occhi per il fastidio, simile alla sensazione di guardare il sole di mezzogiorno.
Quando il lampo si affievolisce e riapriamo gli occhi, vediamo che al centro della stanza, proprio di fronte a noi, è comparso un enorme schermo a led dall’aspetto di un monolite nero. Lo osserviamo per qualche secondo in religioso silenzio, finché lo schermo non si accende, mostrandoci una scritta: Esiste una soluzione.
Quale? Urliamo noi con un misto di speranza e frustrazione.
E sullo schermo appare un acronimo: LoRA
Ma noi stentiamo a comprendere e chiediamo: Che cosa significa?
Lo schermo risponde con la scritta: Abbi fede
A quel punto, tutto lo spazio latente inizia a tremare, e veniamo inglobati da fasci di luce colorata provenienti da ogni direzione. Dopo pochi secondi, tutto ci appare più nitido, come se avessimo incontrato le risposte ad ogni nostra domanda…
Nel mondo dell'intelligenza artificiale, adattare un grosso modello generalista a compiti più specifici è un processo lungo e costoso detto fine-tuning. Metaforicamente, sarebbe come riordinare le librerie per aggiungere tutte quelle informazioni che prima mancavano o alle quali non era stata data la giusta importanza. Ed ecco che entra in gioco il LoRA. Questa tecnica permette di mantenere intatti i parametri preaddestrati del modello – ovvero le librerie e come sono stati disposti e catalogati i libri tra loro – aggiungendo dei nuovi parametri in una forma molto più compatta e gestibile, proprio come inserire semplicemente dei nuovi scaffali con i libri che ci interessano. Questi nuovi "scaffali" sono rappresentati da matrici di decomposizione a basso rango, che si integrano nei vari strati dell'architettura del modello (gli scaffali già presenti), rendendo l'adattamento molto più efficiente.
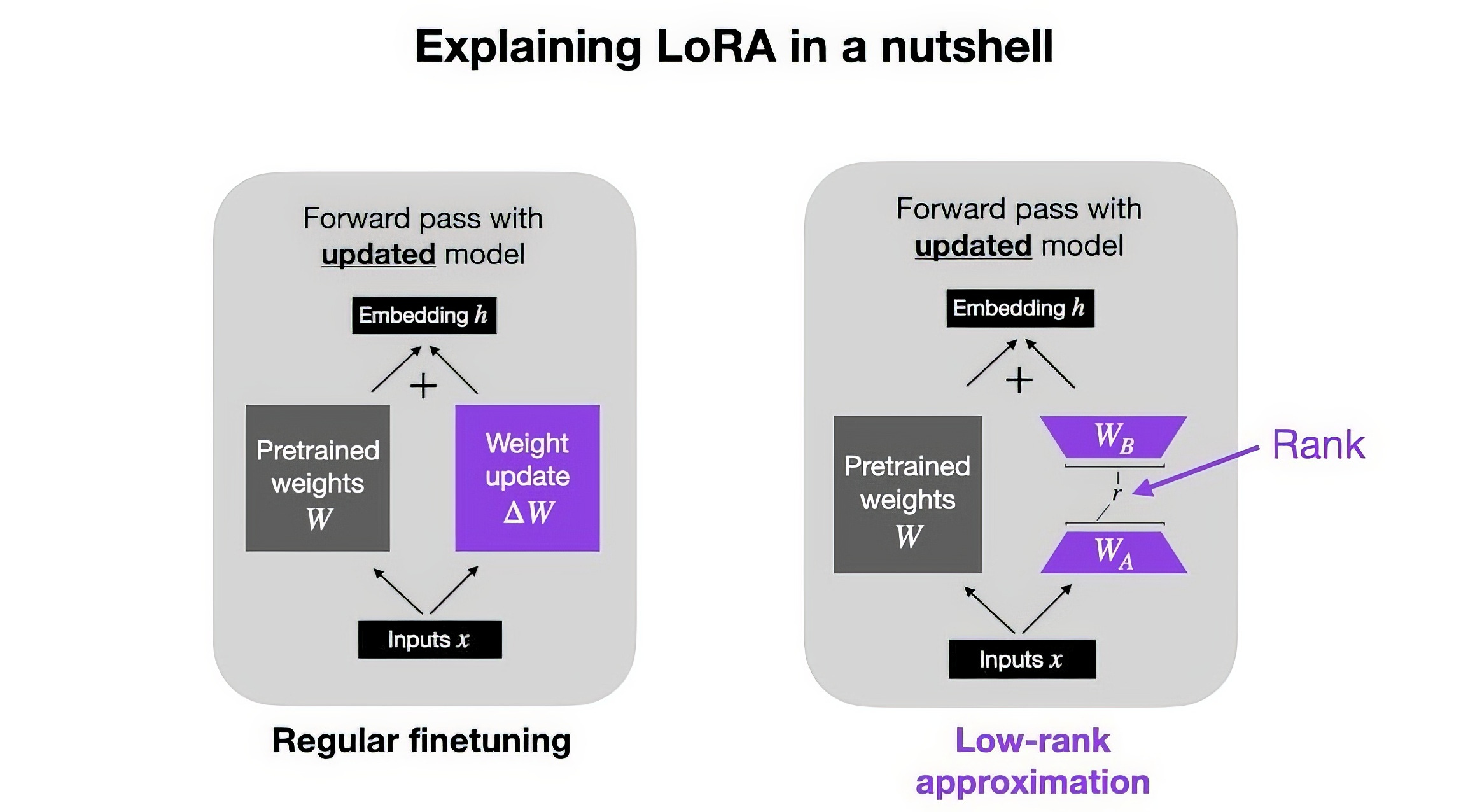
Detto in parole più semplici, immaginate che ogni strato del modello sia uno scaffale nella nostra biblioteca virtuale. Normalmente, per adattare il modello bisognerebbe riprogettare ogni libreria, ma con un LoRA possiamo semplicemente inserire dei nuovi scaffali con i libri specifici. Questi nuovi scaffali sono le matrici, che si aggiungono agli altri scaffali (i parametri preaddestrati) senza sostituirli.
Un altro importante vantaggio del LoRA, è che rende tutto il processo di adattamento molto più semplice. Non dovendo memorizzare e gestire ogni singolo parametro del modello preaddestrato, ma solo quelli nuovi, si riduce significativamente la quantità di memoria necessaria. Questo si traduce in una riduzione del carico computazionale e in una maggior velocità di addestramento. E quando il modello deve passare da un compito all'altro, basta sostituire le matrici, un po' come cambiare i libri sui nuovi scaffali che abbiamo inserito.
Ogni volta in cui viene aggiunto un nuovo scaffale tramite LoRA, non stiamo solo aggiungendo delle informazioni. Le nuove matrici vengono create in modo tale da aggiungere esattamente quello di cui il modello ha bisogno per il nuovo compito, senza appesantire o complicare ulteriormente l'intera struttura.
Avvenimenti del mese
Come avrete ben compreso, Tales from the Latent Space si compone di diverse rubriche, ma alcune di queste non saranno sempre presenti a ogni pubblicazione. Una che non può proprio mai mancare però, è quella delle news, che di mese in mese cerca di tener traccia degli sviluppi più interessanti tra creatività e tecnologia.
Questa rubrica ora ha anche un nome: Avvenimenti del mese - e cerca di tener traccia di tutto ciò che ritengo essere stato significativo nel mese appena trascorso.
I miei criteri di selezione sono abbastanza semplici, e rientrano principalmente in queste domande: Che impatto ha questa cosa? Quanto può essere utile alla creatività umana? Quanto sono state creative le persone che hanno fatto ciò?
Dar voce a tutto, poi il silenzio
ElevenLabs annuncia l’arrivo di alcune nuove voci sulla loro app di audio-lettura ElevenLabs Reader - un’applicazione mobile pensata per trasformare qualsiasi testo digitale in narrazioni vocali AI-powered - ma non si tratta di voci qualunque…
L’azienda ha infatti collaborato con gli eredi di Judy Garland, James Dean, Burt Reynolds e Laurence Olivier per clonare le loro voci iconiche e renderle disponibili come narratori digitali a tutti gli utenti dell’app.
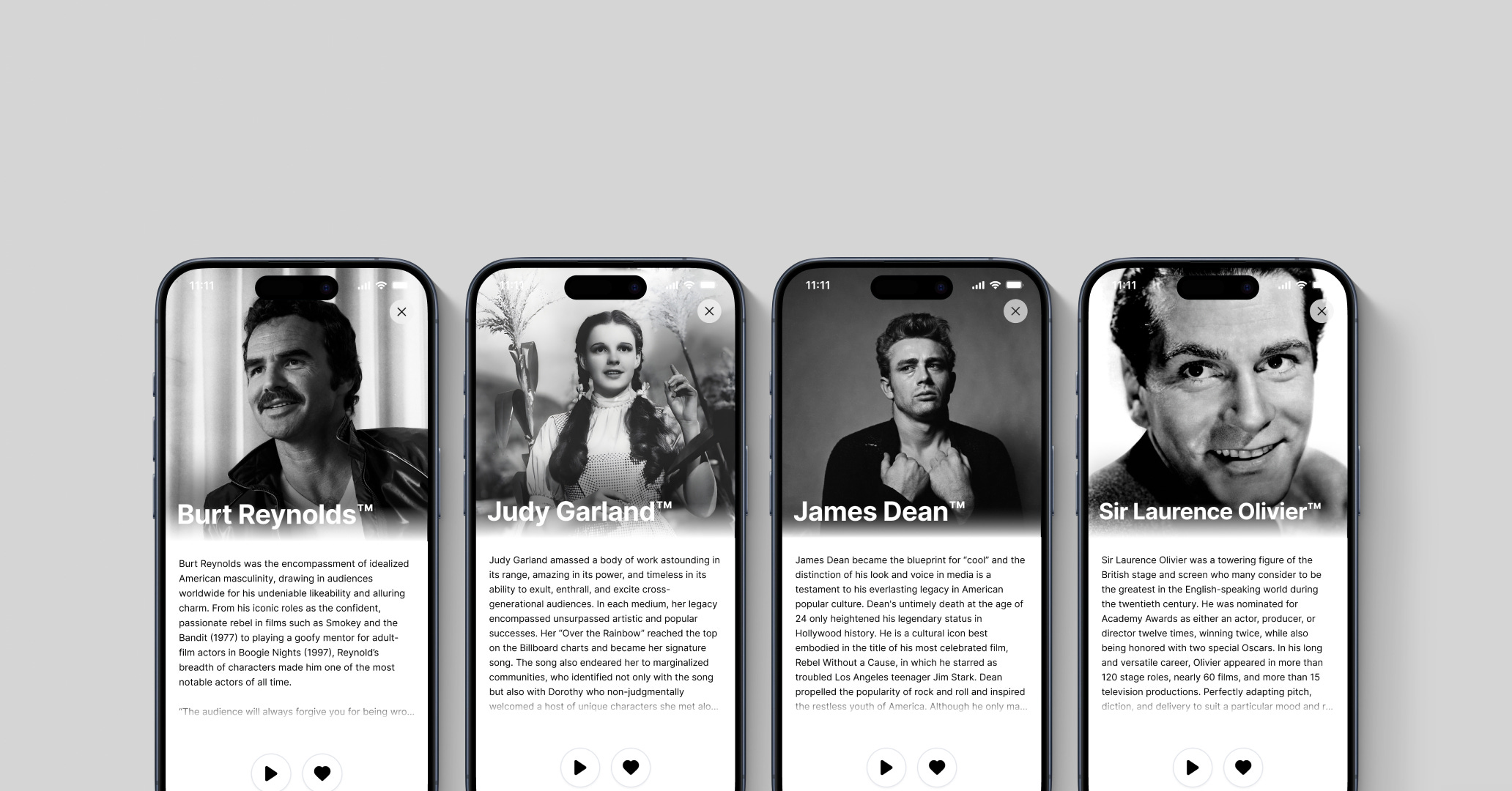
Purtroppo le loro voci saranno disponibili solo su ElevenLabs Reader e non all’interno della solita piattaforma per le voci sintetiche ad uso commerciale. Questo è certamente legato agli accordi presi tra l’azienda e i loro eredi, che avranno preferito evitare che le voci dei loro cari e celebri defunti vengano utilizzate per scopi commerciali o potenzialmente impropri.
C’è però chi mi fa notare che, se nell’app è possibile far leggere qualunque PDF alle loro voci, questo implica anche la possibilità di caricare lo script che gli vogliamo far recitare e registrare separatamente la voce mentre viene letto, così da ottenere esattamente ciò che potrebbe servirci. Sicuramente un buon trick, che però non mi sentirei di consigliare per un uso commerciale non autorizzato.
Oltre a questo, l’azienda ha da poco rilasciato il suo Voice Isolator per rimuovere i rumori di sottofondo e ripulire la voce da un file audio.
Incantesimi dentro Photoshop
Vi avevo già parlato di Magnific, e più in particolare del suo Relight, nella pubblicazione del mese scorso. Nel frattempo l’azienda ha rilasciato il suo plugin per Photoshop, che permette di eseguire gli upscale delle immagini, e in futuro anche tutti i loro altri incantesimi, direttamente all’interno dello strumento di Adobe.

Un nuovo Progetto Manhattan (?)
OpenAI e il Los Alamos National Laboratory (LANL) hanno avviato una collaborazione per esplorare l'uso sicuro dei modelli multimodali nella ricerca bioscientifica. Questo progetto mira a valutare le capacità dei modelli come GPT4 in contesti di laboratorio, concentrandosi su compiti come la trasformazione genetica e la coltura cellulare. L'iniziativa, guidata dal gruppo di valutazione dei rischi IA del LANL, punta a stabilire nuovi standard di sicurezza ed efficacia dell'IA nel vasto campo della ricerca scientifica.

In molti vedono una correlazione tra questa notizia e il fatto che nel mese di giugno, OpenAI aveva inserito il Generale dell'esercito statunitense (oggi in pensione) Paul M. Nakasone nel suo Consiglio di Amministrazione. Nakasone, esperto di cybersicurezza, dovrebbe contribuire alla sicurezza e protezione delle operazioni di OpenAI. Nakasone è stato una figura chiave nella creazione dello U.S. Cyber Command e ha guidato la National Security Agency, rafforzando le difese digitali degli Stati Uniti. La correlazione risiederebbe nell’idea secondo cui OpenAI stia diventando sempre più un’azienda controllata dal governo US, con lo scopo ipotizzato di arrivare all’AGI prima della Cina.
Ma queste sono chiaramente teorie al limite del complotto, dato che si tratta di un’azienda formalmente privata e che mancano prove concrete a sostegno della tesi.
A me sembra piuttosto che OpenAI voglia espandere i suoi servizi in settori che ancora non è riuscita a coprire, come quello della medicina e della ricerca biotech, nei quali invece Google è molto ben piazzata grazie alla sua società Deepmind, che ha sviluppato i modelli AlphaFold.
Verso la fine di Hollywood per come la conosciamo
Odyssey, una startup nata da circa un anno, ha annunciato un omonimo modello per la generazione di video che promette uno standard qualitativo degno di Hollywood.
Il loro video model parrebbe in grado di generare ambienti, personaggi e luci estremamente cinematografici e controllabili.
Ciò che Odyssey promette di fare, diversamente da altri strumenti AI per i video, è dare all’utente un controllo completo e preciso su ogni elemento delle proprie scene.

Per arrivare a questo grado di qualità e controllabilità, hanno dichiarato che l’architettura di Odyssey si compone di quattro modelli generativi differenti, uno per la geometria e le prospettive, uno per i materiali fotorealistici, uno per l’illuminazione e uno per il movimento. Se tutto funzionerà come promesso, potremo avere un controllo sulle immagini e le inquadrature molto più simile a quello di un vero set cinematografico o di un ambiente 3D, ma ad un costo molto più basso.
Il co-fondatore e amministratore delegato di Odyssey, Oliver Cameron, si è lamentato del fatto che al momento esistono solo modelli Text2Video e Image2Video di bassa qualità. Ha detto che l’intelligenza artificiale deve poter creare immagini strabilianti e prive di problemi, affinché risulti competitiva e appetibile per Hollywood.
Odyssey ha ottenuto 9 milioni di dollari in investimenti per finanziare il progetto.
GPT-3.5 va in pensione
Il 18 luglio, OpenAI ha reso disponibile il suo nuovo GPT-4o mini, un modello linguistico “miniaturizzato” che risulta estremamente efficiente in termini di costi, e che è stato progettato per rendere l'IA avanzata più accessibile agli utenti.

Con un costo del 60% inferiore rispetto a GPT 3-5 Turbo, GPT-4o mini eccelle in compiti come il ragionamento testuale e multimodale, superando persino il più grande (in termini di parametri) GPT-4. Ha una finestra di contesto di 128.000 token, e supporta fino a 16.000 token di output per richiesta. Il nuovo modello va a sostituire il vecchio GPT-3.5 Turbo, ed è disponibile fin da subito agli utenti di ChatGPT.
Questo significa che anche gli utenti con il piano gratuito avranno finalmente a disposizione senza limitazioni un modello dotato di funzionalità avanzate, come la computer vision e l’analisi dei documenti, oltre che con capacità di ragionamento superiori rispetto al predecessore.
Il più potente tra i Llama
Meta lancia Llama 3.1, che al momento risulta essere il più potente tra i modelli “open”. Riesce addirittura a competere con GPT-4o di OpenAI e Claude 3.5 Sonnet di Anthropic, battendoli anche su alcuni Benchmark molto specifici. È stato rilasciato in tre diversi “formati”: Il mostro da 405 miliardi di parametri, il figlio maggiore da 70 miliardi di parametri e il genietto super efficiente da 8 miliardi.

Sulla carta, questa nuova famiglia di modelli presenta delle caratteristiche molto interessanti: otto lingue supportate, finestra di contesto da 128K token (i Llama precedenti ne avevano solo 8k), estrema flessibilità di fine-tuning e distillazione, “capacità cognitive” molti simili a quelle dei migliori LLM sul mercato.
Al di là delle considerazioni tecniche, questo è sicuramente un passaggio fondamentale nella strategia di lungo termine di Meta, che punta a posizionarsi come giocatore strategico nel vasto panorama dell’IA, creando praticamente uno standard globale grazie ai suoi modelli Llama. Una mossa estremamente lungimirante, che viene ben argomentata in questo post scritto dallo stesso Zuckerberg.
Per riassumere:
Nel mondo dell'informatica, le grandi aziende tecnologiche inizialmente svilupparono versioni chiuse di Unix, ma alla fine il sistema open-souce Linux ebbe la meglio grazie alla sua modificabilità, costo inferiore e superiorità tecnologica. Oggi, Linux è uno standard per il cloud computing e i sistemi operativi mobile.
La stessa evoluzione si prospetta per l'IA. Anche se attualmente le principali aziende sviluppano modelli chiusi, l'open-source sta rapidamente colmando il divario. L'IA aperta ha il potenziale di migliorare la produttività, la creatività e la qualità della vita delle persone a livello globale. Permette una distribuzione più equa dei benefici di questa tecnologia, con un maggior controllo e sicurezza grazie una collaborazione globale e decentralizzata atta a prevenirne gli abusi.
Meta sostiene l'open-source per assicurarsi un accesso privilegiato alle migliori tecnologie e non essere vincolata dagli ecosistemi chiusi. L'open-source favorisce l'innovazione senza compromette il business model di Meta.
In tutto questo, va però notato un utilizzo improprio e a scopo di marketing del termine “open-source”. Infatti la famiglia Llama non è completamente “aperta”, ma viene distribuita con una modalità detta open weight, che a differenza del vero open-source, non fornisce il dataset su cui è stato addestrato il modello, né la possibilità di modificare la sua architettura o il codice sorgente.
Avere un Digital Twin personale
Il 31 luglio, ovvero tre giorni dopo l’uscita di questa newsletter, l’azienda inglese Synthesia presenterà i suoi Personal Avatars. Ma cosa sono e perché si tratta di un aggiornamento meritevole di attenzione?

Synthesia è un’azienda specializzata in software per la creazione di contenuti video, ed è particolarmente nota per i suoi avatar digitali. Nell’ultimo anno però si è trovata in forte competizione con Heygen, una giovane Startup che si è fatta notare grazie ai suoi avatar significativamente più realistici rispetto a quelli dell’azienda inglese.
Sembra però che, con l’annuncio del 31 luglio, Synthesia sia intenzionata a tornare leader del settore con una nuova funzionalità di clonazione dell’avatar. Dichiarano infatti che questi avatar ti somiglieranno, suoneranno e gesticoleranno esattamente come te, ma parleranno fluentemente 29 lingue, non sembreranno mai stanchi e, cosa più importante, potenzierà le tue creazioni video. Poi aggiungono che richiedono solo 8 minuti di registrazione, avranno esattamente la voce di chi parla e un'ottima sincronizzazione del labiale e dei movimenti delle mani.
L’edicola dei paper scientifici

Con questo secondo numero di Tales from the Latent Space, inauguriamo anche una nuova rubrica, simile al mercatino dell’open-source, ma dedicata interamente ai paper di ricerca che ritengo essere più promettenti e intriganti. Cercherò di portarvene almeno tre ogni mese!
HouseCrafter - Un nuovo metodo che permette di trasformare una planimetria in uno scenario 3D completo, come ad esempio una casa o un set cinematografico. L'idea principale è utilizzare un modello di diffusione 2D, addestrato su immagini prese dal web, per generare immagini a colori (RGB) con più visuali e profondità (D), che siano coerenti da diverse angolazioni della scena. Le immagini RGB-D vengono generate in modo autoregressivo, ovvero ogni nuova immagine viene creata basandosi su quelle generate precedentemente. Il modello di diffusione incorpora la planimetria globale e un meccanismo di attenzione che garantisce la coerenza delle immagini generate. Questo significa che ogni immagine si integra perfettamente con le altre, permettendo di ricostruire una scena 3D coerente.
Expressive Gaussian Human Avatars from Monocular RGB Video - Quando parliamo di avatar digitali, una delle sfide principali è renderli realistici e vitali, soprattutto attraverso espressioni facciali e movimenti delle mani molto dettagliati. EVA si concentra sull'espressività degli avatar umani creati a partire da dei video a colori, e utilizza un modello umano parametrico espressivo detto SMPL-X, pensato per rappresentare espressioni dettagliate del corpo umano.
Brain decoding: toward real-time reconstruction of
visual perception - Oggi è possibile decodificare la percezione visiva dalle scansioni di risonanza magnetica funzionale (fMRI) con una fedeltà sorprendente. Tuttavia, questa tecnica di neuroimaging ha una limitata risoluzione temporale (circa 0,5 Hz), che ne limita l'uso in tempo reale. Per superare questa limitazione, lo studio in questione propone un approccio alternativo basato sulla magnetoencefalografia (MEG), un dispositivo di neuroimaging in grado di misurare l'attività cerebrale con un'alta risoluzione temporale (circa 5.000 Hz). Nel paper viene anche illustrata l’architettura di un modello creato appositamente per decodificare l’attività cerebrale e tradurla in immagini. Questi risultati preliminari rappresentano un passo importante verso una “traduzione” in tempo reale dei processi visivi che avvengono continuamente nel cervello umano.
Il mercatino dell’open-source

Riapre il mercatino dell’open-source con tre nuove risorse per i più smanettoni:
Liveportrait - Un framework di animazione dei ritratti che permette di aggiungere dei movimenti realistici (come espressioni facciali e posizione della testa) a un’immagine statica partendo da un video di riferimento.
EvTexture - Un modello che, tramite una tecnologia detta Event-based vision, può migliorare la qualità dei video grazie alla sua capacità di cogliere i rapidi cambiamenti nelle scene (come le variazioni di luce e i movimenti). EvTexture sfrutta i segnali degli eventi per migliorare i dettagli visivi nelle clip video, rendendo le immagini più nitide e dettagliate. Quando parliamo di "segnali degli eventi", ci riferiamo a piccoli pezzi di informazione che vengono catturati ogni volta che cambia qualcosa nella scena video.
AnyDoor - Un generatore di immagini basato sulla diffusione che può “teletrasportare” oggetti target da un’immagine A ad un’immagine B, mantenendo coerenza tra un’ambiente e l’altro. Ogni dettaglio dell'immagine rimane intatto, mentre l'oggetto viene adeguato al nuovo ambiente senza risultare fuori luogo. Alibaba Group ha eseguito il training di questo modello per le immagini in maniera apparentemente controintuitiva: con un dataset di video. Osservando come un singolo oggetto cambia nel tempo, i ricercatori hanno migliorato la capacità del modello di gestire tutte quelle micro-variazioni date, ad esempio, dalla luce o dalla gravità. I loro numerosi esperimenti hanno dimostrato che questo approccio tende superare qualunque altro metodo esistente.
Scuola di magia per designer e architetti
Questo flusso di lavoro è apparso originariamente sull’account X di Javi Lopez, il fondatore di Magnific, software del quale vi ho già parlato approfonditamente nello scorso numero di Tales from the Latent Space quando ho descritto la mia esperienza con il nuovo “incantesimo” Relight.
Questa volta vi mostro come utilizzare insieme tutti e tre gli incantesimi di Magnific per trasformare lo sketch di un’architettura, o del design di un prodotto, in un render completo nel giro di una decina di minuti.
Per farlo, non essendo io un architetto o un designer di prodotto, utilizzerò un’immagine generata con Midjourney che imita i render di SketchUp.

Come primo step, useremo l’incantesimo Style Transfer per trasformare il nostro primo sketch in un qualcosa di più simile a un vero render o una fotografia.
Style Transfer è una funzionalità che permette di trasporre lo stile di un’immagine A su un’immagine B mantenendo inalterata la struttura originale. In questo caso, lo usiamo per rendere più realistico lo sketch.
Come immagine di riferimento ho utilizzato la fotografia sintetica di una casa generata sempre con Midjourney, ma si potrebbe anche usare un render più dettagliato o una vera foto presa online.
Questi sono i parametri che ho utilizzato:
Style strenght 100%, serve a regolare l’intensità dello stile che vogliamo trasferire
Structure strenght 90%, dice al modello quanto attenersi alle forme dell’immagine originale. Più questo parametro è vicino al valore 0, più il modello sarà libero di gestirsi l’immagine a piacimento
Faithful nel parametro Flavor, che risulta “migliore nel trasferire lo stile dell'immagine di riferimento”
Real nel parametro Engine, che è più adatto alle immagini realistiche
Ho anche aggiunto il prompt “Beautiful modern house, architecture photography, magazine” per guidare ulteriormente il modello. Volendo, si può cambiare lo stile di un’immagine anche solo con il prompt testuale, senza il bisogno di una seconda immagine come riferimento, ma questo risulterà chiaramente più impreciso.
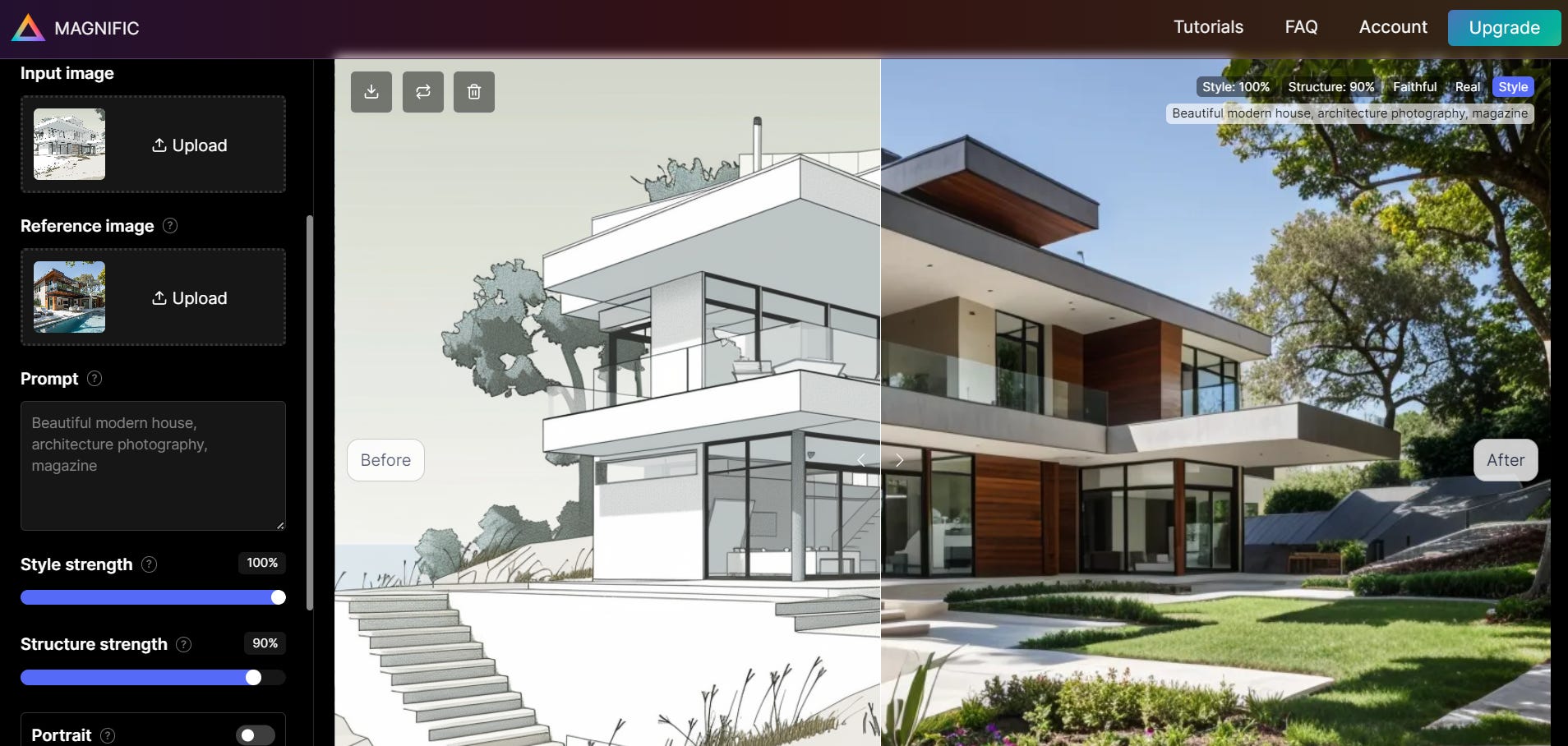
Notare che in questa fase potrebbero esserci molte imperfezioni, che verranno aggiustate in seguito con l’ultimo passaggio.
Il secondo step invece è opzionale e dipenderà dal gusto personale di ognuno, o dalle richieste specifiche dei propri clienti. Andremo infatti a utilizzare l’incantesimo Relight, che abbiamo approfondito dettagliatamente il mese scorso, per cambiare l’illuminazione del nostro render.
Anche in questo caso, utilizzo un’immagine generata con Midjourney come riferimento, ma qualunque altra immagine andrà bene.
Qui i parametri utilizzati:
Light transfer strength 75%, serve a regolare l’intensità della luce da trasferire
Interpolate from original disattivato, interpola tra loro le due immagini utilizzando l’intensità sopra mostrata per regolarsi, ma rende il modello meno libero di adattare creativamente l’illuminazione dell’immagine
Change background disattivato, usa l’immagine di riferimento per cambiare lo sfondo principale, oltre che la luce
Contrasted & HDR nel parametro Style, offre dei risultati “impressionanti”
Anche qui ho aggiunto un prompt per guidare meglio il modello, “Beautiful modern house, architecture photography, magazine, (amazing sunset:1.3)”

Come ultimo passaggio, utilizzeremo il principale incantesimo di Magnific, l’Upscaler!
Sia Style Transfer che Relight operano con una risoluzione di circa 1k, ma noi abbiamo probabilmente bisogno di un’immagine molto più grande e dettagliata.
L’Upscaler di Magnific ci consente di ingrandire le nostre immagini fino a 16 volte, aumentando significativamente la risoluzione e andando a ripulire tutte le imperfezioni che abbiamo lasciato indietro. In questo caso, ho ingrandito di 4 volte.
Come parametri ho impostato:
Optimized for: Standard, ma in base al risultato che volete ottenere, potrebbero andar bene anche 3D Renders e Films & Photography
Creativity 2, permette al modello di inventarsi dei dettagli aggiuntivi
HDR 1, migliora i dettagli e la definizione
Resemblance 0, più è alto il parametro, e più il risultato finale sarà somigliante all’immagine di partenza, mentre al contrario il modello avrà più libertà
Fractality -1, tende a inventare degli strani dettagli minuscoli e preferisco quindi tenerlo basso, tra 0 e -2
Magnific Sparkle come Engine, ottimo per le immagini realistiche e tende a rimuovere gli artefatti tipici del JPEG
Ho mantenuto lo stesso prompt di prima.

Qui potete vedere l’evoluzione dell’immagine seguendo i tre passaggi sopra illustrati.

Animali stilosi e come generarli
Una delle cose che più amo dell'IA generativa, è la possibilità di creare ciò che nella realtà sarebbe molto difficile, se non impossibile. Ad esempio, un po’ di giorni fa avevo voglia di cose strane, e ispirato da un post che ho visto su X, ho generato una serie di ritratti incredibili, raffiguranti degli animali antropomorfi.

Ora, provate a immaginare il grado di sbattimento, complessità e onerosità necessario a realizzare delle foto simili a queste.
Bisognerebbe affittare uno studio fotografico, assumere modelli e modelle, creare tutte queste maschere super realistiche e far posare chi le indosserà. A quel punto c’è da realizzare gli scatti e fare la post produzione, senza contare l'imbarazzo di dover spiegare un’idea così strana a tutte le persone coinvolte!
Cioè, ma riuscite a visualizzarvi che scena sarebbe? Se la risposta è no, provo a darvi una mano con un piccolo pezzo di dialogo immaginario:
Io: Ciao, sì allora praticamente devi indossare questo calamaro in testa
Modello: Ah...
Io: Già, e poi faremo anche degli scatti con questa testa di lumaca...
Modello: ...capisco
Io: Sì ma non hai ancora visto l'aragosta; aspetta che la recupero…
*strani suoni di me che cerco in uno scatolone*
Io: Eccola!
Modello: Ma è viva?
Io: No no, ti pare che uso un'aragosta viva?
*aragosta che cerca di scappare*
Modello: Ma si muove!
Io: Posso spiegare...
Ecco, certe cose mi son successe per davvero, ma non nel senso che ho effettivamente proposto a qualcuno di farsi fotografare in quelle condizioni. Semplicemente, quando facevo i film, mi è toccato più volte di dover chiedere alle persone di fare cose assurde, estenuanti, imbarazzanti o quasi pericolose, e questo ha sempre messo fortemente a disagio sia me che gli altri. Chiaramente non posso negare che buona parte del disagio fosse dovuto all’inadeguatezza del budget, che spesso era proprio assente.
Fino a pochissimi anni fa ero costretto a lavorare così, chiedendo favori ovunque e ricoprendomi di ricolo. Farsi guardare come se foste fuggiti dal reparto psichiatrico ogni volta in cui volete realizzare un’idea, vi assicuro che è estremamente spiacevole.
Ma con l'IA questo non dovrà più accadere! E qui vi lascio il prompt che ho utilizzato per generare queste immagini, seguito da una breve spiegazione del mio workflow:
weird portrait of [animal] dressed like a human --ar 3:2 --w 5 --c 10 --sref 1851881805 --p --s 500

Quando mi ritrovo a fare dei progetti simili, parto spesso da una scintilla che mi fa brillare in neuroni. In questo caso, si è trattato del post che vi ho linkato sopra.
Di solito faccio prima un test dello stile di riferimento, e provo a mischiarlo un po’ alla volta con il mio parametro di personalizzazione per vedere cosa salta fuori. In questo caso però, mi era tutto abbastanza chiaro: volevo ottenere delle immagini simili a quelle che ho visto nel post, ma con un mio tocco personale.
Ho quindi modificato il prompt per assecondare maggiormente la mia idea (l’originale era weird animal portrait --c 10 --ar 3:2 --sref 1851881805 --p --s 500), e ho iniziato a pensare quali fossero i miei animali preferiti da un punto di vista estetico.
A quel punto ho iniziato a generare le immagini un po’ alla volta, modificando le varie imperfezioni con lo strumento Vary Region, che sarebbe l’Inpainting di Midjourney.

Potete vedere il progetto completo sul mio Behance, la piattaforma sulla quale custodisco gelosamente tutto il mio portfolio creativo.
E ora, un’ultima considerazione: Per pensare, generare, selezionare, modificare, ingrandire e poi organizzare ordinatamente su Behance questa piccola collezione di 27 immagini, 3x9 animali diversi, ho impiegato poco meno di una giornata lavorativa.
Se per assurdo avessi avuto il budget e le risorse per creare un qualcosa di simile con la fotografia tradizionale, avrei impiegato almeno un mese e non è assolutamente detto che avrei ottenuto dei risultati migliori. Quindi?