


Agli Albori del Nuovo Mondo
Prima che tutto prenda forma, esiste un istante in cui ogni possibilità è ancora aperta


Il primo mese del 2025 è iniziato con la proverbiale quiete prima della tempesta, per poi gettare le basi per quello che si preannuncia un anno a dir poco elettrizzante.
Siamo nella piena “golden age” della robotica, Trump ha iniziato il suo secondo mandato promettendo di rendere gli Stati Uniti una nazione ancor più innovativa di prima, l’Europa sta ricevendo scossoni da tutte le direzioni che potrebbero svegliarla dal torpore burocratico, la Cina sta diventando sempre più agguerrita nel campo dell’intelligenza artificiale, siamo a pochi passi dal terzo step verso l’avvento dell’AGI, quello degli Agenti AI autonomi, l’hardware per la computazione sta diventando sempre più piccolo, efficiente, potente ed economico, e questo magazine sta per raggiungere il traguardo dei primi 500 iscritti!
Col passare del tempo, gli effetti delle incredibili innovazioni tecnologiche di questi anni finiranno col riplasmare completamente la nostra realtà, fino al punto in cui ci guarderemo indietro domandandoci come facevamo a vivere come prima. In modo non particolarmente dissimile da come oggi pensiamo alle persone vissute nel 1800.
Tempi meravigliosi ci attendono e voi che state leggendo queste frasi siete i veri pionieri del Nuovo Mondo.
La mia personale ambizione per quest’anno è quella di riuscire a trasformare questo magazine in una vera e propria Startup innovativa, collocata all’intersezione tra il mondo dei media e della tecnologia. Per farlo, le mie sole forze non bastano e cerco qualcuno con cui espandere il team di lavoro, così da poter creare più contenuti e portare gli approfondimenti di Tales from the Latent Space anche su Instagram per ampliare la portata del progetto. Cerco quindi una collaborazione a medio-lungo termine per gestire la pagina del magazine e creare più contenuti. Si offre una quota in quella che sarà la futura azienda legata al magazine e formazione di alto livello sui principali strumenti AI, in cambio di una ragionevole quantità di tempo da concordare. Se l'idea ti intriga o conosci qualcuno con la giusta ambizione e competenza che possa abbracciare questa missione, contattami su LinkedIn.
Prossimamente, condividerò anche il business plan dell’azienda che voglio costruire, insieme a un manifesto d’intenti che racconti la visione complessiva del progetto.
Nel frattempo, consiglio di iniziare ad allontanarsi dalla linea gialla, che il treno per il Nuovo Mondo è in arrivo…

Che cos’è il Fine-Tuning?
Dopo aver parlato di LoRA e RAG, passando per lo Spazio Latente, che è un po’ il tessuto connettore di tutte queste tecniche che permettono di specializzare un modello di intelligenza artificiale, è arrivato il momento di affrontare anche il fine-tuning, ovvero l’unico metodo per mutare profondamente le conoscenze e capacità di un modello. Per farlo, utilizzerò ancora una volta la metafora della libreria, che si presta incredibilmente bene per questo scopo.

Immaginiamo quindi di entrare in una sterminata libreria, dalle scaffalature altissime e ricche di libri di ogni genere: romanzi, saggi, fumetti, enciclopedie, manuali di cucina e antologie di poesie in lingue dimenticate. Questa libreria, in alcuni articoli delle pubblicazioni precedente, era l’immagine con cui avevo descritto l’IA generativa e il suo immenso Spazio Latente di possibilità. Quando il vasto patrimonio di conoscenze “generaliste” di modelli come GPT, Claude o Gemini non ci basta e abbiamo bisogno di specializzare un’IA in compiti o domini molto specifici, possiamo ricorrere al fine-tuning. Una tecnica che possiamo immaginare come un restyling della libreria per renderla più specializzata in un determinato campo del sapere. Questo può includere una riorganizzazione dei libri esistenti per rispondere meglio a particolari necessità, assicurandosi che certe sezioni siano più facili da consultare, ad esempio, migliorando la capacità del modello di rispondere in modo accurato in un contesto medico o legale. Questo processo non va a rimuovere o sostituire completamente tutti gli scaffali e i volumi presenti nella libreria, le informazioni generali rimangono disponibili, ma vengono aggiunte e organizzate nuove sezioni.
Il fine-tuning rende la libreria "su misura" per un pubblico o una necessità particolare, proprio come se un bibliotecario decidesse di aggiungere una nuova selezione di libri per uno specifico target di lettori.
Per dirlo in altri termini, il fine-tuning è un processo che permette di specializzare o affinare un modello di intelligenza artificiale precedentemente addestrato su un vasto insieme di dati generici. Per comprendere meglio questa dinamica, proviamo a tornare nella nostra libreria metaforica: gli “scaffali” già esistenti (ovvero i parametri interni del modello) comprendono conoscenze generali sugli argomenti più disparati. Il modello di base, è già in grado di fornire risposte generiche su un sacco di tematiche: letteratura, storia, biologia, matematica, geografia, e via dicendo.
Gli output di un LLM potrebbero però non essere sempre accurati, soprattutto su argomenti più specialistici e di nicchia. Per fare un altro esempio, potremmo necessitare di un modello in grado di analizzare con precisione dei testi di diritto societario italiano, o che sappia generare descrizioni dettagliate per i prodotti di uno strano e-commerce che vende oggetti di elettronica dei primi anni 2000. In questi casi, è necessario eseguire un addestramento mirato sulle informazioni pertinenti per quel dominio specifico. Quindi il fine-tuning consiste nel prendere un modello pre-addestrato (la libreria della nostra metafora), fornirgli dei nuovi dati specializzati (i libri) e farglieli assimilare, così da aggiornare e rifinire la sua preparazione in quell’area. Questo approccio ha due grossi vantaggi:
Riduce i costi di addestramento, perché non dovendo partire da zero si va a risparmiare tempo e risorse computazionali
Sfrutta l’esperienza pregressa, perché il modello ha già una solida comprensione del linguaggio (o delle immagini, se parliamo di modelli di computer vision o per la generazione di immagini). Diventando quindi più efficace e meno propenso a commettere errori grossolani
Confronto con l’addestramento “from scratch”
Quando si parla di “allenare un modello da zero”, ci si riferisce al momento in cui si inizializza un modello con parametri casuali e lo si addestra step by step a riconoscere pattern e strutture di un insieme di dati. È come costruire una libreria partendo da una stanza vuota, andando a creare tutti gli scaffali di cui abbiamo bisogno per aggiungere i libri catalogati uno a uno. Un processo lungo e dispendioso.

Fine-tuning, invece, è come prendere una libreria già pronta e ben fornita (il modello pre-addestrato) e aggiungere solo i nuovi volumi che ci interessano. La struttura portante della libreria (i parametri del modello di base) non viene smantellata; tutt’al più, si fanno interventi mirati e calibrati.
Un modello linguistico generico come GPT-4 può cavarsela bene nel rispondere a domande di cultura generale o a svolgere compiti di comprensione del testo, ma non è ottimale per il servizio di customer care di una specifica azienda di software, o un sistema di diagnostica medica che analizzi cartelle cliniche e referti. In questi casi, le informazioni, le espressioni, i concetti e le convenzioni linguistiche sono molto peculiari: ecco dunque perché può servire un fine-tuning ad hoc.
Un altro aspetto cruciale è la performance. I modelli di base, pur essendo molto potenti, non possono eccellere in tutti i micro-compiti legati al linguaggio, come ad esempio la classificazione dei sentimenti: un LLM puà generare pagine e pagine di testo coerente, ma se vogliamo renderlo un critico cinematografico capace di assegnare un voto (positivo, neutro o negativo) a una recensione, un fine-tuning su un dataset di recensioni etichettate può far impennare l’accuratezza del sistema.
Un fine-tuning su un dominio ben definito, con dati di qualità, riduce anche il rischio di allucinazioni riguardanti quel dato argomento, perché il modello impara a concentrare la sua “attenzione” su un insieme più ristretto di informazioni verificate.
Funzionamento tecnico
Nel machine learning, l’addestramento di un modello (in questo caso un modello di deep learning) si realizza regolando i pesi o parametri interni della sua rete neurale, in modo che risponda meglio ai dati di input. Un modello pre-addestrato possiede già valori dei pesi ottimali per un ampio spettro di compiti. Durante il fine-tuning, vengono apportati dei piccoli aggiustamenti a questi parametri, usando un dataset specializzato nel compito d’interesse.
A livello computazionale, si esegue un passaggio di retropropagazione dell’errore (backpropagation), ma su un numero ridotto di epoche (ossia i cicli di passaggio sull’intero dataset) rispetto a un addestramento from scratch, perché non c’è bisogno di riscrivere da capo la “conoscenza” di base del modello.
Oltre ai pesi, un aspetto fondamentale è la regolazione di alcuni parametri esterni (detti “iperparametri”) quali il tasso di apprendimento (learning rate), la dimensione dei batch (batch size) e il numero di epoche. Se impostati correttamente, questi iperparametri possono evitare fenomeni come l’overfitting (il modello che “impara a memoria” il dataset invece di coglierne gli aspetti generali) o il catastrophic forgetting, in cui il modello perde la competenza generale mentre impara nuovi dati.
Il fine-tuning può essere di tre tipi:
Full fine-tuning: si aggiornano tutti i pesi del modello
Partial fine-tuning: si aggiornano soltanto i livelli finali (per esempio, l’ultima parte del modello che svolge il compito di classificazione)
Freezing: si lascia la maggior parte dei livelli “congelati” con i loro pesi originali, agendo solo su pochi strati o addirittura aggiungendo nuovi livelli dedicati (ad esempio, “adapter layers”)

In una delle pubblicazioni precedenti vi ho parlato dei LoRA (Low Rank Adaptation), un metodo estremamente efficiente per il fine-tuning dei modelli di grandi dimensioni. Tornando per un attimo alla nostra metafora della libreria: invece di riorganizzare tutto l’ordine dei libri, con un LoRA si aggiungono poche scaffalature extra in determinati punti, in modo che i nuovi dati possano essere integrati con poche modifiche mirate.
Concettualmente, il LoRA si basa sul fatto che gran parte delle informazioni apprese dai modelli di deep learning possa essere espressa attraverso componenti a “basso rango” (low-rank), un po’ come dire che la libreria si può descrivere con un numero ridotto di “coordinate” fondamentali. Aggiungendo piccole matrici a basso rango, si ottiene un adattamento specifico senza dover modificare (o quasi) l’imponente struttura del modello preesistente.
Passaggi operativi
Il primo passo per un buon fine-tuning è raccogliere un dataset rappresentativo del dominio in cui si desidera specializzare il modello. Supponiamo, ad esempio, di voler creare un chatbot per l’assistenza clienti in ambito bancario. Avremo bisogno di testi e dialoghi che rispecchino il linguaggio dei clienti, le possibili richieste, e le terminologie bancarie più comuni.
Non è solo una questione di quantità: la qualità e la coerenza del dataset sono fondamentali. Dati rumorosi (contenenti errori, incongruenze, duplicati, contraddizioni) possono confondere il modello o fargli apprendere pattern indesiderati. È come inserire in libreria dei volumi scritti con errori di stampa, capitoli mancanti o informazioni erronee.

Dopo aver raccolto i dati, si procede a dividerli in tre parti:
Training set: usato per aggiornare i pesi del modello
Validation set: usato durante l’addestramento per controllare che il modello non stia perdendo la sua capacità di generalizzazione (evitando l’overfitting)
Test set: usato alla fine dell’addestramento per misurare nel modo più imparziale possibile le prestazioni del modello
Come accennato, la regolazione del tasso di apprendimento, batch size, epoche e altre impostazioni può fare la differenza tra un fine-tuning mediocre e uno eccellente. Una buona prassi è eseguire alcuni esperimenti (grid search o altre tecniche di ottimizzazione) per trovare la combinazione migliore.
Una volta preparati i dati e scelti gli iperparametri, si avvia l’addestramento. Nei primi cicli, il modello inizia ad adattarsi al linguaggio e ai concetti tipici del dominio. Man mano, se i dati sono sufficienti e coerenti, le performance dovrebbero migliorare.
Terminato il fine-tuning, è buona norma valutare il modello su varie metriche:
Accuracy, Precision, Recall, F1-score (se si tratta di classificazione).
ROUGE, BLEU, METEOR (se si tratta di generazione di testo).
Altre metriche specifiche per il dominio o il compito.
In base ai risultati, si può decidere se aggiungere ulteriori dati, correggere eventuali errori nel dataset, regolare diversamente gli iperparametri, e ripetere il processo. È come riorganizzare leggermente gli scaffali della libreria per migliorare l’accesso ai libri specializzati, sostituendo o aggiornando eventualmente alcuni volumi.
Che si tratti di alleggerire il carico di lavoro degli operatori umani, di automatizzare processi complessi o di proporre soluzioni innovative in ambito ricerca, il fine-tuning rimane la chiave di volta per trasformare “grandi cervelli” generici in “esperti” capaci di competenze ben targettizzate. E la “libreria” dell’IA, grazie a queste aggiunte e modifiche, può espandersi e migliorare quasi all’infinito, rimanendo sempre aperta a nuovi saperi e frontiere da esplorare.
Avvenimenti del mese
Le notizie più interessanti e creative dal mondo della tecnologia, accuratamente selezionate per districarsi tra il rumore informativo.

Rivoluzionare il design industriale
Il 3 gennaio, la startup Zoo, che si occupa di creare software e infrastrutture per il design di hardware, ha rilasciato una demo del suo modello Text-to-CAD.

Si tratta di una nuova funzionalità per il loro prodotto di punta: Modeling App, un'interfaccia open-source per la progettazione di hardware.
Prima di questo aggiornamento, l’applicazione consentiva di generare modelli CAD con del codice o tramite azioni punta e clicca sul modello 3D, mentre ora permette l’utilizzo di un prompt testuale (Text-to-CAD).
In futuro, possiamo aspettarci un unico ciclo integrato: design, simulazione, miglioramento, componente pronto per la fabbricazione.
Supercomputer tascabili
Il 6 gennaio, NVIDIA ha presentato una serie di prodotti straordinari durante il CES, una delle più importanti conferenze al mondo sulla tecnologia.

Tra i vari annunci spicca Project DIGITS, un supercomputer AI dal costo di $3000 che può stare sul palmo di una mano; la nuova serie di schede grafiche RTX 5000, con la 5070 Ti che raggiunge prestazioni equiparabili a una 4090 (lato gaming) mantenendo circa 1/4 del prezzo; NVLink72, un bridge chip-to-chip che può collegare fino a 72 GPU Blackwell e 36 CPU Grace in un unico sistema; La famiglia di modelli Llama Nemotron, pensati per gli agenti AI; Cosmos, una piattaforma che integra nuovi world foundation model per insegnare all’IA il funzionamento del mondo reale; Thor Blackwell, un nuovo chip per la guida autonoma e i robot.
Più avanti nel magazine puoi trovare un articolo di approfondimento su tutte le novità più interessanti dal CES 2025.
Modelli miniaturizzati
L’8 gennaio, Microsoft ha rilasciato Phi-4, l’ultima versione del suo LLM open-source miniaturizzato che raggiunge performance paragonabili a GPT-4o.

Phi-4 è un modello all'avanguardia basato su una combinazione di dati sintetici, dati da siti Web di pubblico dominio filtrati, libri accademici acquisiti e set di Q&A. L'obiettivo di questo approccio era garantire che i piccoli modelli fossero addestrati con dati focalizzati su ragionamento avanzato e di alta qualità.
Dal 4k ai fotogrammi
Il 10 gennaio, Runway rilascia il suo upscaler nativo, che permette agli utenti di ingrandire le proprie clip generate con Gen-3 Alpha fino alla risoluzione di 4K.

Questo upscaler può ingrandire di 4 volte i video di Runway, mantenendo inalterati i fotogrammi di partenza, segno che utilizza probabilmente un algoritmo di ML per moltiplicare i pixel invece di generare nuovamente ogni frame con una risoluzione più alta, come accade per molti image upscaler basati su IA generativa.
Poco dopo, il 17 gennaio, viene rilasciato anche Frames, il loro nuovo modello avanzato per la generazione di immagini che vanta un gusto estetico incredibile.
Purtroppo però, il modello è disponibile solo per gli abbonamenti enterprise e unlimited. Una scelta molto discutibile che esclude deliberatamente una buona fetta degli utenti di Runway da quello che è uno dei loro prodotti migliori.
Personaggi coerenti nei video
Sempre il 10 gennaio, Haliou AI rilascia Subject Reference, un aggiornamento del suo modello Minimax per mantenere coerenza nei personaggi da una scena all’altra.

Subject Reference (S2V-01) permette di generare clip video con personaggi coerenti partendo da una singola immagine. Oltre a essere una funzionalità molto intuitiva, ha bisogno di meno dell’1% delle risorse computazionali richieste dagli altri metodi.
I risultati non sono ancora perfetti, e gli output migliori si ottengono partendo da un'immagine in cui il soggetto è frontale e ben illuminato, ma si tratta comunque di un grandissimo passo in avanti, che ci avvicina sempre più alla possibilità di realizzare interi film con l'intelligenza artificiale.
ChatGPT come assistente personale
Il 14 gennaio, OpenAI ha rilasciato Tasks, una nuova funzionalità che permette agli utenti di programmare degli eventi o dei promemoria con ChatGPT.

Tasks permette al modello di eseguire delle richieste nel futuro o di ripetere dei compiti più volte nel corso del tempo. Per accedervi, bisogna cliccare sul menù a tendina in alto e selezionare "GPT-4o con attività pianificate", per poi chiedere un promemoria qualunque, anche con un'istruzione.
Ad esempio gli possiamo chiedere: "ricordami di fare la spesa domani alle 12 e prepara una lista con tutti gli ingredienti di cui ho bisogno per cucinare pasta e fagioli"; oppure: “mandami un riepilogo delle notizie più interessanti delle ultime 24 ore dal mondo tech ogni mattina alle 10”.
Task è ancora in fase beta e può presentare diversi errori. In oltre, non è compatibile con i modelli o1, con la lettura dei documenti, i custom GPT e la modalità vocale.
Il 21 gennaio, viene annunciato Stargate Project, l’equivalente odierno del Progetto Manhattan del secolo scorso, durante una conferenza alla casa bianca. Stargate sarà una nuova azienda creata in joint venture tra OpenAI, Oracle, Soft Bank e MGX, con l’obiettivo di investire 500 miliardi di dollari in quattro anni per creare un’infrastruttura AI dedicata solo a OpenAI che la utilizzerà per creare l’AGI.
Arm, Microsoft, NVIDIA, Oracle e OpenAI sono i principali partner tecnologici iniziali. La costruzione del primo centro di Stargate è attualmente in corso in Texas e stanno valutando altri potenziali siti in tutti gli Stati Uniti per ulteriori campus. Come parte di Stargate, Oracle, NVIDIA e OpenAI collaboreranno strettamente per costruire e gestire questo nuovo sistema computazionale.
Poco dopo, il 23 gennaio, viene rilasciata una versione beta di Operator, il primo vero Agente AI di OpenAI. Operator può navigare sul web per svolgere attività specifiche per conto dell’utente, gestendo un’ampia gamma di compiti ripetitivi all’interno del browser. Ad esempio, può compilare moduli, ordinare la spesa, prenotare una camera d'albergo o un biglietto aereo e persino creare meme.
L’utente deve intervenire solo in questi casi:
Fare login
Inserire dati di pagamento
Risolvere CAPTCHA
Operator si basa su un nuovo modello chiamato Computer-Using Agent (CUA), che combina le capacità visive di GPT-4o con il ragionamento tramite RL.

CUA suddivide le task in piani multi-step e si autocorregge adattivamente quando incontra dei nuovi problemi. Questa capacità segna il passo successivo nello sviluppo dell'intelligenza artificiale, consentendo ai modelli di utilizzare gli stessi strumenti su cui gli umani fanno affidamento quotidianamente, aprendo le porte all’era degli Agenti AI. CUA segna nuovi record nei benchmark, ottenendo il 38,1% su OSWorld, un test pensato per misurare l’utilizzo completo del computer. Grazie al ragionamento multi-step, supera anche Computer Use di Anthropic.
CUA è ancora un’anteprima di ricerca, disponibile solo agli utenti Pro negli US (quindi con l'abbonamento da $200 al mese). OpenAI ha però in programma di espandere l'accesso anche agli utenti Plus, Team ed Enterprise, ma forse non in Europa, a causa dell’AI Act. Stanno anche lavorando per rendere CUA disponibile tramite API, in modo che gli sviluppatori possano utilizzarlo per creare i propri agenti che utilizzano il computer.
Il giorno seguente, il 24 gennaio, viene rilasciato anche un aggiornamento per Canvas, che può finalmente sfruttare o1 e renderizzare codice HTML e React.
Controllare il movimento
Il 15 gennaio, la startup Kinetix ha presentato Character Motion Control, un metodo per controllare il movimento dei personaggi nei modelli di diffusione per i video.

Fino a poco tempo fa, non c’era modo di controllare con precisione il modo in cui i personaggi si muovono e agiscono nei video che generati con l'intelligenza artificiale, ma questo strumento cambia le carte in tavola.
Con Character Motion Control si può recitare davanti alla camera e dare vita alla propria visione esatta. Basterà descrivere la scena con un prompt testuale, caricare un video per guidare il movimento del personaggio e il gioco è fatto.
I modelli video continuano a migliorare
Sempre il 15 gennaio, Luma Labs ha rilasciato Ray 2, il suo nuovo modello video che offre un grado di realismo e precisione straordinario.

Luma è una startup molto particolare, che nell'ultimo anno ha vissuto delle evoluzioni a dir poco notevoli, spaziando dal 3D alla generazione di video. Il suo primo prodotto era un'app che permetteva di "scannerizzare" oggetti e ambientazioni con la fotocamera del telefono per ricrearli in 3D. Poi ha creato Genie, un modello text-to-3D.
E a giugno dell'anno scorso ha rilasciato Dream Machine, un modello AI per i video che sembrava avere una qualità incredibile ma che è stato rapidamente surclassato dalla concorrenza. L'uscita di DM 1.5, seguito quasi subito dalla versione 1.6 dotata di "camera control" aveva momentaneamente ribilanciato la situazione. Ma nel settore video AI puoi essere il migliore solo per pochi giorni. Così hanno lanciato Photon, un ottimo modello per le immagini, insieme a un totale restyling dell'app di Dream Machine, che si è trasformata in una piattaforma a 360° per la creatività.
Quindi il modello video smette di chiamarsi Dream Machine, e viene rinominato "Ray" per cedere il nome alla nuova piattaforma. Ray 2 (che sarebbe Dream Machine 2.0) vanta un'architettura multi-modale 10 volte più potente rispetto alla versione 1.6, e questo porta alla sua incredibile qualità.
Ray 2 ha un'ottima aderenza ai prompt, può generare scene complesse e dinamiche mantenendo alto il grado di dettaglio e rispettando la fisica.
Il 29 gennaio Luma ha rilasciato anche il suo video upscaler, che permette di portare a 4K la risoluzione dei video generati all’interno di Dream Machine.
Un nuovo paradigma per il design dei materiali
Il 16 gennaio, Microsoft ha rilasciato Mattergen, un modello di intelligenza artificiale generativa progettato per rivoluzionare la scoperta di nuovi materiali inorganici.

L'identificazione di materiali con proprietà specifiche ha sempre richiesto processi sperimentali lunghi e costosi o lo screening computazionale di vasti database. MatterGen adotta un approccio innovativo, generando direttamente materiali nuovi in base ai requisiti progettuali desiderati, come proprietà chimiche, meccaniche, elettroniche o magnetiche. Questo modello di diffusione opera sulla geometria 3D dei materiali, modificando le posizioni atomiche e le strutture reticolari per creare materiali stabili e innovativi.
I test iniziali hanno dimostrato che MatterGen supera i metodi tradizionali nello scoprire materiali con proprietà specifiche, aprendo nuove prospettive per la creazione di nuove tecnologie rivoluzionarie.
La balena che cucina
Il 20 gennaio, la startup cinese DeepSeek ha rilasciato R1, un modello di ragionamento completamente open-source che può competere con o1 di OpenAI.

Si tratta di un modello sviluppato con un approccio di addestramento multi-fase, che utilizza dati minimamente etichettati prima dell'addestramento tramite reinforcement learning. R1 è stato distribuito con licenza MIT, rendendolo accessibile per qualsiasi utilizzo, inclusa la ricerca, la commercializzazione e la distillazione. Partendo da R1, DeepSeek ha distillato altri 6 modelli più piccoli, sempre open-source.
L’uscita di questo modello ha scatenato una quantità incredibile di controversie: DeepSeek ha subito attacchi informatici pochi giorni dopo il rilascio di R1, portando a restrizioni temporanee nelle registrazioni degli utenti ed esponendo i dati di milioni di conversazioni, dati utente e token di autenticazione. Questo ha sollevato molte preoccupazioni sulla sicurezza e stabilità dei servizi cinesi. Nel frattempo, OpenAI ha accusato l’azienda di aver utilizzato gli output di O1 per distillare R1, una pratica proibita dai termini di utilizzo di OpenAI.
Questo ha portato il Garante della Privacy a pubblicare un comunicato riguardante proprio DeepSeek e i suoi servizi.
Un'altra questione controversa riguarda le censure presenti nei modelli cinesi che, per ovvie ragioni, rifiutano di rispondere a domande riguardanti Xi Jinping, Hong Kong, Piazza Tienanmen, gli Uiguri e tutti quegli argomenti dei quali non si potrebbe mai parlare liberamente nel paese del CCP. Anche la gestione dei dati personali è sotto i riflettori: ci sono timori che le informazioni sensibili degli utenti vengano memorizzate in Cina, dove le leggi sulla privacy sono a dir poco inesistenti, richiamando parallelismi con le preoccupazioni già viste con TikTok e sollevando questioni di sicurezza nazionale.
Si ipotizza anche che l’impatto di DeepSeek sia stato così grande da far crollare le azioni di NVIDIA del 18% in un giorno, a causa dei dubbi sulla sostenibilità dei costi elevati per lo sviluppo dell'AI in confronto alle dichiarazioni di DeepSeek di aver ottenuto risultati simili con 1/100 delle risorse. Questo ha provocato una certa agitazione nel mercato e ha sollevato domande sul vero costo dell'innovazione nell'AI, ma diverse fonti sostengono che DeepSeek abbia mentito sul budget per addestrare R1, e la cosa non stupisce affatto.
Un’azienda cinese ha tutti gli interessi nell’affermare di aver creato una tecnologia paragonabile al meglio delle aziende statunitensi a una frazione del costo, sia in termini di propaganda politica, sia perché le sanzioni imposte alla Cina dovrebbero impedire alle sue aziende di avere a disposizione grosse quantità di GPU NVIDIA, cosa che invece riescono a ottenere passando attraverso Singapore.
Mentre le polemiche si espandono, il 27 gennaio DeepSeek lancia un altro modello open-source, Janus-Pro. Un’IA multimodale super compatta che batte Dall-E 3 di OpenAI e alcune versioni di Stable Diffusion nei benchmark GenEval e DPG-Bench.
I benchmark possono però trarre in inganno, e diversi utenti hanno subito fatto notare che il modello non è poi così eccezionale.

Risultati a parte, Janus-Pro è basato su DeepSeek-LLM-1.5b-base e DeepSeek-LLM-7b-base, e la sua principale innovazione consiste nel separare la codifica visiva in percorsi distinti, pur mantenendo un’unica architettura di tipo transformer per l’elaborazione. Questo approccio risolve i problemi di conflitto tra comprensione e generazione delle immagini, offrendo anche una maggior flessibilità.
L’operatore cinese
Il 22 gennaio, il colosso cinese ByteDance rilascia UI-TARS, un Agente AI open-source con licenza Apache 2.0 che può utilizzare il computer in autonomia.
UI-TARS è un modello di agente GUI avanzato, progettato per automatizzare attività informatiche complesse. Sviluppato in collaborazione con la Tsinghua University, integra percezione dello schermo, azioni con mouse e tastiera, ragionamento e memoria in un framework scalabile e adattabile. Addestrato partendo da Qwen-2-VL 7B e 72B di Alibaba, UI-TARS è disponibile in tre versioni, rispettivamente da 2, 7 e 72 miliardi di parametri. Ha dimostrato prestazioni all'avanguardia in 10 benchmark legati all’uso del computer, superando costantemente Computer Use di Anthropic.
In un test era stato chiesto a UI-TARS di trovare voli di andata e ritorno da Seattle a New York. Il modello ha quindi navigato con successo sul sito web di una compagnia aerea, ha inserito i dettagli del viaggio e ha ordinato le opzioni in base al prezzo, il tutto fornendo una spiegazione dettagliata delle sue azioni.
L'architettura del modello gli consente di comprendere e interagire con vari elementi grafici di applicazioni desktop, mobile e web. Utilizza input multimodali, tra cui testo, immagini e interazioni, per comprendere le interfacce ed eseguire attività in modo autonomo. UI-TARS utilizza anche il ragionamento, in modo simile a o1 di OpenAI, consentendogli di imparare dagli errori e adattarsi a situazioni impreviste con un intervento umano minimo.
Alibaba e i 72miliardi di parametri
Il 28 gennaio, il colosso cinese Alibaba Group rilascia Qwen2.5-Max, un LLM Mixture of Experts state of the art, che però non è open-source come i modelli di DeepSeek.
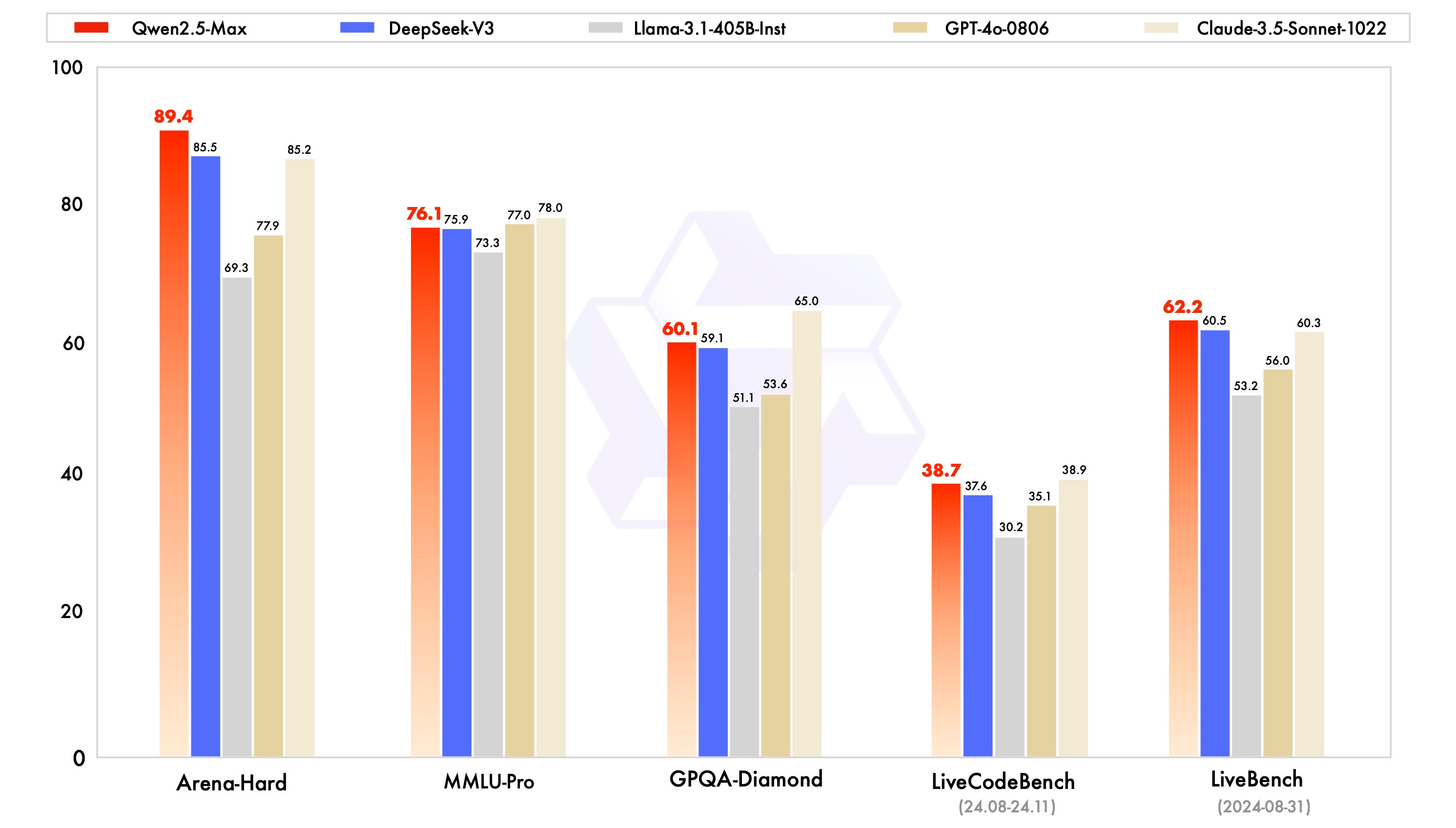
Qwen2.5-Max batte DeepSeek V3 in benchmark come Arena Hard, LiveBench, LiveCodeBench, GPQA-Diamond, ma le sue API costano più di GPT-4o.
Si può testare gratuitamente dall'interfaccia Qwen Chat, che include anche altre funzionalità come gli artifacts e la generazione di video. Consiglio però estrema cautela nell’utilizzare l’ennesima applicazione cinese. Alcune best practice per limitare il furto di dati sono: registrarsi con una gmail creata appositamente, non inserire mai informazioni sensibili in chat e usare una VPN per accedere al sito.
L’edicola dei paper scientifici
Tre paper di ricerca per il mese di gennaio.

Key-value memory in the brain - Un nuovo modello di memoria ispirato dalla psicologia e dalle neuroscienze rivoluziona il modo in cui comprendiamo l'archiviazione e il recupero delle informazioni. I sistemi di memoria chiave-valore separano nettamente le rappresentazioni utilizzate per l'archiviazione (valori) da quelle per il recupero (chiavi), risolvendo le limitazioni dei modelli tradizionali basati sulla similarità. Questo approccio permette di ottimizzare sia la fedeltà nell'archiviazione che la discriminabilità durante il recupero. Dalla loro applicazione nell'apprendimento automatico alle possibili implementazioni biologiche, questi sistemi aprono nuove prospettive per la nostra comprensione del funzionamento della memoria.
Noise_Step - L'addestramento di grandi modelli di machine learning richiede enormi risorse computazionali ed energetiche, accessibili solo a poche aziende. Questo paper dimostra che l'inferenza degli LLM può essere eseguita con una precisione di 1.58 bit senza perdita di performance. Questo studio compie un ulteriore passo avanti, introducendo un algoritmo che permette di addestrare direttamente in precisione ternaria. Senza fare uso di backpropagation o momentum, il metodo può funzionare parallelamente all'inferenza del modello, mantenendo costi simili. L'algoritmo consente una riduzione drastica del consumo energetico e della memoria, rendendo l'addestramento dei modelli più sostenibile ed efficiente, aprendo la strada a un'adozione massiva dell’IA.
Diffusion-Vas - La permanenza degli oggetti, ovvero la capacità di riconoscere un oggetto anche quando è completamente nascosto, è una caratteristica fondamentale dell'intelligenza umana. Gli attuali metodi di segmentazione si concentrano solo sugli oggetti visibili e trascurano questa dimensione "amodale". Le tecniche esistenti, spesso limitate a immagini singole o oggetti rigidi, non riescono a gestire le complesse occlusioni presenti in molti video. Per risolvere questo problema, i ricercatori di questo paper hanno sviluppato un approccio innovativo che affronta la segmentazione amodale nei video come un compito di generazione condizionale. Utilizzando modelli generativi per i video, questo metodo sfrutta sequenze di maschere visibili di un oggetto e mappe di pseudo-profondità per identificare e ricostruire i confini nascosti di un oggetto. Una seconda fase completa i dettagli mancanti, facendo inpainting delle regioni occluse. Il metodo è stato testato su quattro dataset e ha dimostrato miglioramenti significativi, con un incremento delle performance fino al 13% per la segmentazione delle aree nascoste degli oggetti.
Il mercatino dell’open-source
Tre progetti open-source con codice per il mese di gennaio.

LLM Visualization - Permette di visualizzare il modello 3D funzionante di una rete in stile GPT. Il network è visibile con i pesi funzionanti mentre riordina un piccolo elenco di lettere A, B e C. Nella demo viene utilizzato come esempio nano-gpt, un modello con soli 85.584 parametri che, pur avendo un'architettura meno complessa rispetto ai più moderni modelli multimodali come GPT-4o o Gemini 2.0, rende bene l'idea di quello che c'è dietro a una rete neurale del genere.
TangoFlux - Un nuovo modello text-to-audio costituito da blocchi FluxTransformer, ovvero Diffusion Transformers (DiT) e Multimodal Diffusion Transformers (MMDiT) condizionati su un prompt testuale e un embedding di durata (duration embedding) per generare audio a 44,1 kHz fino a 30 secondi. TangoFlux apprende una traiettoria di flusso rettificata in una rappresentazione audio latente codificata da un autoencoder variazionale (VAE). La pipeline di training di TangoFlux è costituita da tre fasi: pre-training, fine-tuning e ottimizzazione delle preferenze con CRPO. In particolare, il CRPO genera iterativamente nuovi dati sintetici e costruisce coppie di preferenze per l'ottimizzazione delle preferenze utilizzando DPO loss per il flow matching.
TryOffAnyone - Un nuovo metodo, basato su un fine-tuning di Stable Diffusion, per generare immagini di vestiti su modelli partendo da singole foto. Il metodo presenta un design semplificato di rete a fase singola, che integra maschere specifiche per indumento così da isolare ed elaborare efficacemente il vestito target. Semplificando l'architettura di rete tramite l'addestramento selettivo dei blocchi transformer e rimuovendo gli strati di attenzione incrociata non necessari, la complessità computazionale si riduce significativamente, ottenendo prestazioni SOTA su dataset di benchmark come VITON-HD.
Tutto il Meglio del CES 2025
Come ogni anno, all’inizio di questo mese si è tenuto a Las Vegas il Consumer Electronics Show (CES), che per il 2025 si è svolto dal 7 al 10 gennaio. Ancora una volta, è stato il più grande palcoscenico globale per l'innovazione, svelando una pletora di tecnologie rivoluzionarie che hanno il potenziale di rimodellare i settori più disparati. L'evento di quest'anno è stato caratterizzato da significativi progressi nell'intelligenza artificiale, negli hardware computazionali, nella robotica, nella tecnologia sanitaria e nelle soluzioni sostenibili.
In questo piccolo report, trovate una selezione di quelle che ho ritenuto essere le novità più significative della conferenza.

L’evento si è aperto con l’attesissimo Keynote di NVIDIA del 6 gennaio, durante il quale sono stati presentati alcuni dei prodotti più interessanti di tutta la conferenza.
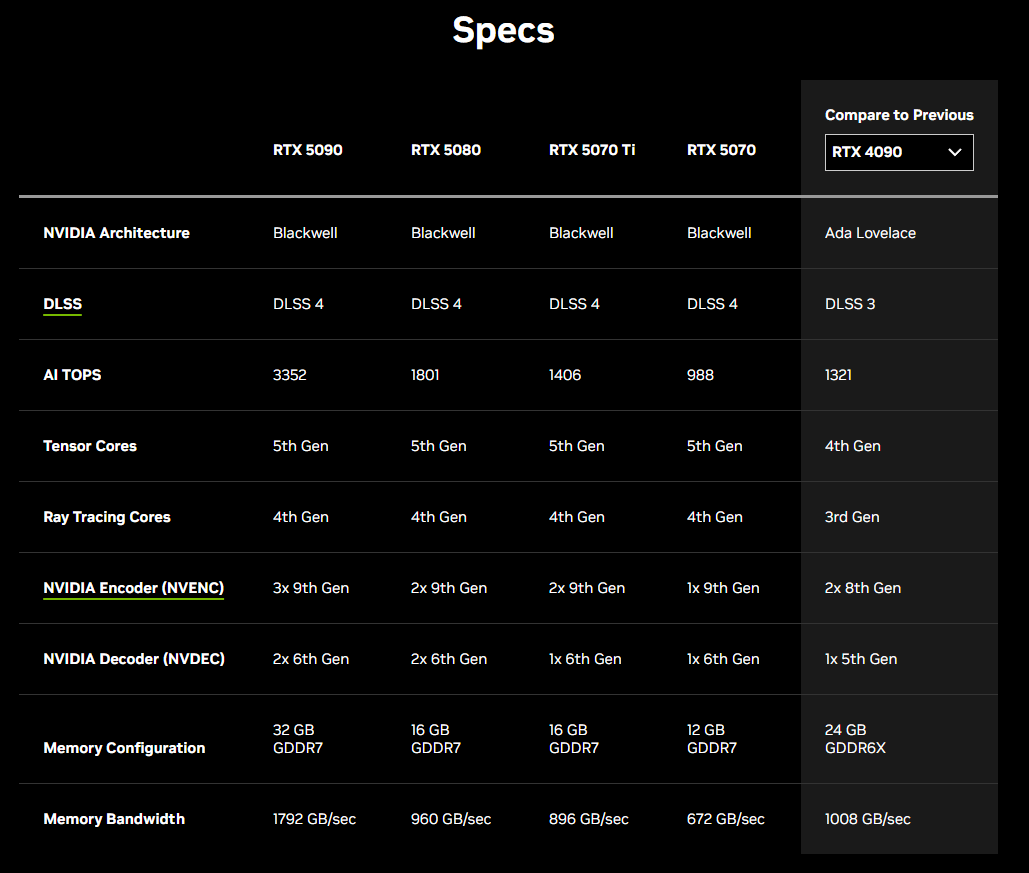
L’annuncio che tutti si aspettavano e forse anche il più atteso, è senza ombra di dubbio quello della nuova serie di schede grafiche RTX 50, che hanno stupito per il loro ottimo rapporto qualità-prezzo.

La serie RTX 50 è basata sulla nuova architettura Blackwell di NVIDIA, che migliora le prestazioni e l'efficienza. La RTX 5090, il modello di punta, è dotata di 92 miliardi di transistor, che forniscono oltre 3.352 trilioni di operazioni AI al secondo (TOPS) di potenza di calcolo. Ciò si traduce in prestazioni fino al doppio del suo predecessore.
Una caratteristica di spicco della serie RTX 50 è l'introduzione di DLSS 4, l'ultima iterazione della tecnologia Deep Learning Super Sampling di NVIDIA. DLSS 4 utilizza l'IA per generare più frame per fotogrammi renderizzati tradizionalmente, aumentando significativamente gli FPS e migliorando le prestazioni dei giochi. Questa tecnologia include anche un nuovo modello Transformer per una migliore stabilità, illuminazione e dettagli del movimento.
La RTX 5090 ha un assorbimento di potenza di 575 W, che richiede un robusto alimentatore da 1.000 W. La RTX 5080, con un consumo di 360 W, richiede un’alimentazione da 850 W. Questi requisiti garantiscono prestazioni stabili anche durante le attività più intensive.
Per sfruttare le funzionalità AI migliorate della serie 50, NVIDIA ha rilasciato aggiornamenti per i framework AI e gli SDK chiave. CUDA Toolkit 12.8 e NVIDIA TensorRT 10.8 sono disponibili per ottimizzare le prestazioni AI di questa nuova serie. Questi aggiornamenti garantiscono compatibilità e forniscono agli sviluppatori gli strumenti necessari per massimizzare il potenziale dei nuovi hardware.
A un certo punto del Keynote, Jensen Huang ha tirato fuori quello che sembrava lo scudo di Capitan America in versione NVIDIA, per presentare il nuovo NVLink72.
Si tratta di un’interconnessione chip-to-chip che unisce 72 GPU Blackwell e 36 CPU Grace in un singolo rack che offre 130 TB/s di comunicazione GPU a bassa latenza. Con una larghezza di banda complessiva di 1,8 PB/sec (più di tutto il traffico internet attuale) e una potenza di 1.4 ExaFLOPS (più di un grosso datacenter con migliaia di H100).
Prestazioni Tensor Core:
FP4: 1.440 PFLOPS
FP8/FP6: 720 PFLOPS
INT8: 720 POPS
FP16/BF16: 360 PFLOPS
TF32: 180 PFLOPS
FP64: 3.240 TFLOPS
Memoria:
Memoria GPU: fino a 13,5 TB HBM3e con una larghezza di banda di 576 TB/s
Memoria CPU: fino a 17 TB LPDDR5X con larghezza di banda fino a 18,4 TB/s
Specifiche CPU: un totale di 2.592 core Arm Neoverse V2
Questa architettura introduce una nuova generazione di Tensor Core con formati di microscaling innovativi, che migliorano la precisione e l’efficienza a vantaggio degli LLM e di altre applicazioni AI. Una caratteristica significativa di questo sistema è il suo NVLink di quinta generazione, che collega fino a 576 GPU all'interno di un singolo dominio NVLink. Ogni vassoio switch NVLink fornisce 144 porte NVLink da 100 GB, garantendo una connettività completa per le GPU del sistema.

La sorpresa più grande è stata probabilmente Project DIGITS, un rivoluzionario supercomputer AI personale dal costo di 3.000 dollari, progettato per democratizzare l'accesso al computing ad alte prestazioni. Questo sistema desktop compatto consente a sviluppatori, ricercatori e studenti di sperimentare modelli AI avanzati senza dover fare affidamento su infrastrutture di data center esterne.
Al centro di Project DIGITS si trova il GB10 Superchip, che integra la CPU Grace di NVIDIA e la GPU Blackwell. Questa combinazione offre fino a 1 petaflop di prestazioni AI con precisione FP4, consentendo un'elaborazione rapida di attività AI complesse. Il sistema vanta 128 GB di memoria unificata DDR5X a basso consumo, garantendo un accesso ai dati ad alta larghezza di banda e una comunicazione efficiente tra CPU e GPU. Ha 4 TB di archiviazione SSD NVMe per offrire ampio spazio a dataset, modelli e applicazioni AI.
DIGITS è progettato per eseguire localmente modelli AI fino a 200 miliardi di parametri, rendendolo adatto a un'ampia gamma di applicazioni, dall'elaborazione del linguaggio naturale alla visione artificiale. Per attività più impegnative, è possibile connettere due DIGITS per raddoppiarne le capacità e supportare modelli AI fino a 405 miliardi di parametri.
Il computer viene fornito con un sistema operativo Linux già installato, insieme a tutto lo stack software AI di NVIDIA. Sono inclusi strumenti di sviluppo, librerie, framework e modelli pre-addestrati disponibili tramite il catalogo NVIDIA NGC.
Il rilascio di Project DIGITS è previsto per maggio 2025.

Si è parlato anche della piattaforma Cosmos, progettata per accelerare lo sviluppo di sistemi di intelligenza artificiale fisica come i veicoli autonomi e la robotica. Cosmos integra dei World Foundation Model generativi all'avanguardia (WFM), tokenizzatori avanzati, guardrail e una pipeline di elaborazione dati accelerata.
Cosmos include una suite di modelli pre-addestrati progettati per generare video e stati del mondo fisico, essenziali per lo sviluppo della robotica. Questi modelli sono addestrati su set di dati estesi, tra cui 20 milioni di ore di dati legati alla robotica e alla guida, garantendo una comprensione completa di vari ambienti.
I modelli di Cosmos vanno da 4 a 14 miliardi di parametri per soddisfare diverse esigenze applicative. C’è anche un modello di upsampling da 12B di parametri che migliora i prompt testuali e un modello da 7B di parametri ottimizzato per la decodifica di sequenze video, particolarmente utile per la realtà aumentata.
Il tokenizzatore visivo di Cosmos converte immagini e video in token ad alta fedeltà, offrendo una compressione 8 volte migliore e un'elaborazione 12 volte più rapida rispetto ai tokenizzatori esistenti. Questa efficienza accelera l'elaborazione dei dati e riduce i requisiti di archiviazione.
Per l’elaborazione dei dati c’è NeMo Curator, una pipeline accelerata dall’architettura CUDA che permette una rapida pulizia ed etichettatura di vasti dataset video. Ad esempio, l'elaborazione di 20 milioni di ore di video può essere eseguita in soli 14 giorni utilizzando NVIDIA Blackwell, un'attività che richiederebbe oltre tre anni con pipeline solo CPU. Cosmos incorpora anche dei guardrail pre e post generazione per filtrare marchi, contenuti non sicuri e prompt dannosi, garantendo la generazione di output appropriati e sicuri.
Cosmos WFM e il tokenizer sono disponibili con la licenza Open Model di NVIDIA, che democratizza l'accesso a strumenti AI avanzati e promuove l'innovazione. Tutto questo si integra perfettamente con altre piattaforme NVIDIA, come Omniverse per le simulazioni e DGX Cloud per l'implementazione, fornendo una suite completa di strumenti per lo sviluppo di AI fisica.

L’ultima chicca di NVIDIA è il chip DRIVE AGX Thor, un hardware rivoluzionario per l'automotive e la robotica che sostituisce il suo predecessore DRIVE Orin.
Basato sull'architettura Blackwell, DRIVE Thor è progettato per soddisfare le rigorose esigenze dei veicoli autonomi (AV) e della robotica avanzata.
Il chip incorpora una CPU Arm Neoverse V3AE, progettata per soddisfare le specifiche esigenze di sicurezza e prestazioni delle applicazioni per l'automotive. Può eseguire 1.000 trilioni di operazioni in virgola mobile al secondo, gestendo attività di inferenza AI fondamentali per la guida autonoma e la robotica.
DRIVE Thor è dotato dell'interconnessione chip-to-chip NVLink-C2C, che consente di collegare più SoC per prestazioni scalabili. Thor integra varie funzionalità di bordo, tra cui la guida autonoma, i sistemi avanzati di assistenza alla guida (ADAS) e le funzionalità del cockpit digitale in un singolo SoC. Questo riduce la complessità e i costi per i produttori. Dispone anche di un’ottima efficienza energetica, fondamentale per i veicoli elettrici e la robotica alimentata a batteria, prolungando così la vita operativa e riducendo i vincoli termici.

Tra le altre novità interessanti del CES, John Deere ha presentato una nuova generazione di macchinari agricoli e da costruzione completamente autonomi, consolidando la sua leadership nell'agricoltura di precisione e nell'automazione. Gli ultimi modelli includono il trattore autonomo 9RX, il trattore autonomo Orchard 5ML, il dumper articolato autonomo 460 P-Tier (ADT) e un tosaerba elettrico a batteria autonomo, tutti progettati per migliorare l'efficienza, ridurre la dipendenza dalla manodopera e aumentare la produttività. Queste macchine integrano visione artificiale, sistemi di telecamere avanzati e LiDAR per la navigazione di precisione.
Il trattore autonomo 9RX è progettato per operazioni agricole su larga scala, specificamente ottimizzato per la lavorazione del terreno. Dotato di 16 telecamere ad alta risoluzione, fornisce una consapevolezza del campo a 360 gradi, consentendo un funzionamento completamente autonomo senza supervisione umana. Il suo avanzato sistema di intelligenza artificiale elabora i dati visivi in tempo reale, rilevando gli ostacoli, regolando la velocità e ottimizzando la lavorazione.
Il trattore Orchard 5ML automatizza il compito ripetitivo e sensibile di irrorazione ad aria compressa in frutteti e vigneti. Pur utilizzando lo stesso kit di autonomia del 9RX, questo modello integra anche nuovi sensori LiDAR, consentendogli di navigare con precisione in ambienti dalle chiome dense.
Per il settore edile, John Deere ha introdotto il 460 P-Tier Autonomous Articulated Dump Truck (ADT), progettato per gestire il trasporto di materiali in cave e cantieri. Come le sue controparti agricole, impiega l'ultimo kit di autonomia dell’azienda, che gli permette di funzionare senza operatore in ambienti di lavoro ripetitivi e pericolosi.
John Deere ha presentato anche un tosaerba autonomo elettrico, ideale per le aziende di giardinaggio. È dotato di otto telecamere alimentate da intelligenza artificiale per una copertura completa a 360 gradi, garantendo una navigazione precisa e sicura senza intervento umano.

Si è tenuto anche un focus sulla cosiddetta robotica indossabile con l’esoscheletro XoMotion di Human in Motion Robotics. Questa struttura avanzata ha attirato l’attenzione per il suo design innovativo e il potenziale di trasformare la vita di tutte quelle persone con problemi di mobilità derivanti da lesioni del midollo spinale, ictus e altre condizioni neurologiche. A differenza dei tradizionali dispositivi di assistenza alla deambulazione, XoMotion può autobilanciarsi, consentendo agli utenti di muoversi a mani libere per svolgere le attività quotidiane con maggior facilità.
XoMotion ha ricevuto il CES Innovation Award.

Un altro prodotto interessante è lo specchio intelligente Omnia dell’azienda Withings, un concetto innovativo che integra un monitoraggio avanzato della salute con l'intelligenza artificiale per fornire agli utenti una panoramica completa sul loro benessere. Questo specchio a figura intera può eseguire una scansione corporea a 360°, valutando vari parametri sanitari e offrendo approfondimenti su misura.
Omnia è dotato di una superficie riflettente con una base integrata che funziona come una bilancia. Questo design consente di stare sulla base mentre lo specchio esegue una scansione corporea completa. Dotato di sensori avanzati, questo dispositivo misura un'ampia gamma di parametri sanitari, tra cui:
Peso e composizione corporea: la base misura il peso, il rapporto muscolo-grasso, il grasso viscerale e altri parametri della composizione corporea.
Salute del cuore: valuta la frequenza cardiaca, la pressione sanguigna e può eseguire elettrocardiogrammi per monitorare la salute cardiovascolare.
Funzione polmonare: lo specchio valuta la salute polmonare, fornendo approfondimenti sulla funzione respiratoria.
Dati metabolici: analizza gli indicatori di salute metabolica, offrendo una visione completa sulla salute generale dell'utente.
I dati raccolti vengono visualizzati direttamente sulla superficie dello specchio, fornendo un feedback visivo immediato. Un assistente vocale AI offre informazioni in tempo reale, risponde a domande relative alla salute e fornisce una guida per incoraggiare abitudini più salutari.
Omnia è progettato per integrarsi con il vasto ecosistema di dispositivi sanitari Withings, come smartwatch, misuratori della pressione sanguigna e rilevatori del sonno. Questa integrazione consente una visione olistica della salute dell'utente aggregando dati da più fonti. Oltre al monitoraggio della salute personale, offre funzionalità di telemedicina che consentono agli utenti di connettersi con professionisti sanitari direttamente tramite lo specchio. Questa funzionalità facilita le consultazioni virtuali e la condivisione di dati sanitari con il personale medico, promuovendo una gestione sanitaria proattiva.
Withings non ha annunciato una data di rilascio specifica o dettagli sui prezzi.

L’ultima cosa di cui voglio parlare è una nuova possibilità per gli abitanti delle città di monetizzare la larghezza di banda Internet inutilizzata tramite nuovi tipi di ripetitori Wi-Fi. Questo sviluppo offre un nuovo potenziale flusso di reddito, migliorando al contempo l'accessibilità a Internet nelle aree densamente popolate.
Negli ambienti urbani, molte persone sottoscrivono piani Internet ad alta velocità, ma spesso utilizzano solo una frazione della larghezza di banda disponibile. Dopo aver riconosciuto questa dinamica frequente, l’azienda Baseus ha sviluppato dei dispositivi che consentono agli utenti di condividere a pagamento la loro banda Internet in eccesso. Questo modello avvantaggia sia il fornitore di larghezza di banda, che guadagna un reddito extra, sia il destinatario, che ottiene un accesso a Internet affidabile senza la necessità di un abbonamento personale.
Il prodotto si chiama EnerGeek MiFi Power Bank e combina le funzionalità di un caricabatterie portatile con quelle di un hotspot mobile. Con una batteria da 20.000 mAh, supporta reti 4G in oltre 100 paesi e può connettere fino a 10 dispositivi tramite Wi-Fi o Bluetooth, offrendo velocità di download fino a 50 Mbps. Gli utenti possono personalizzare i piani dati tramite un'app mobile senza canoni mensili o restrizioni di utilizzo, rendendolo un'opzione flessibile per coloro che desiderano condividere o accedere a Internet in movimento.

Altri prodotti degni di nota sono:
Revol Baby Care: una culla smart che tiene traccia dei parametri vitali del bambino e lo calma per farlo addormentare con l'IA predittiva
Xpeng Aeroht: una combinazione tra un veicolo terrestre e un drone
Portalgraph: un proiettore di ologrammi interattivi
Nuwa Smart Pen: una penna che tiene traccia digitale delle note scritte a mano
L’insolita relazione tra Street Art e tecnologia
L’intervistato del nuovo numero di Tales from the Latent Space è Andrea Ravo Mattoni, un artista che ha saputo intrecciare passato, presente e futuro, trasformando le strade in musei a cielo aperto. Dalle origini come graffiti writer negli anni ‘90 fino all’integrazione dell’intelligenza artificiale nel suo processo creativo, il suo percorso è un esempio perfetto dell’intersezione tra creatività e tecnologia.
In questa intervista ci racconta come la sua ricerca abbia ridefinito i confini tra arte urbana e pittura classica, traducendo capolavori senza tempo attraverso la bomboletta spray e il linguaggio contemporaneo della street art. Tra la fascinazione per l’IA generativa e una visione lucida sul futuro della creatività, il suo racconto ci invita a riflettere su come la tecnologia possa diventare strumento di riscoperta e reinterpretazione, senza mai perdere il contatto con l’umanità del gesto artistico.
Questa intervista si colloca nella più ampia visione del magazine di offrire uno spazio unico ai creativi di tutto il mondo che utilizzano la tecnologia come ampliamento delle loro possibilità espressive. A partire da quest’anno, la rubrica includerà anche interviste a ingegneri, programmatori, matematici e imprenditori, per diversificare i contenuti e promuovere l'idea che la creatività non appartiene solo ad artisti e designer, ma che si tratta di un raffinato processo di problem solving intrinseco alla natura dell’essere umano e alle sue capacità cognitive.

Apriamo con la domanda di rito del magazine: Ci descriveresti il tuo rapporto con la tecnologia?
Il mio rapporto con la tecnologia nasce da quando sono piccolo, sono nato nel 1981, sono sempre stato appassionato di videogiochi, quindi parto dall'approccio con Atari, Geek Tiger, Amiga 500, per poi approdare ai primi PC, quindi 386, 486 33 MHz, 486 66 MHz, Pentium, sempre ovviamente in ambiente DOS inizialmente, poi ambiente Windows, poi ovviamente l'avvento di Internet e tutto ciò che ne consegue. Quindi sono sempre stato molto attento alle tecnologie, per poi arrivare anche all'avvento dei social network, della VR e poi dell'intelligenza artificiale. Contemporaneamente anche a una grande passione per la fotografia e quindi l'avvento del digitale mi ha fortemente influenzato.
Il tuo percorso inizia come graffiti writer negli anni '90, e chi conosce la tua arte sa bene che qualcosa di quel periodo è rimasto anche oggi. Spiegheresti ai lettori la relazione tra quegli anni e le tue produzioni odierne, magari delineando un percorso di evoluzione artistica?
Parto come Graffiti Writer nel 1995, in un ambito ovviamente molto differente da quello odierno, perché non c'era internet e la fotografia era ancora a pellicola. Diciamo, io sono la seconda generazione di Writer italiani, vengo da Varese, quindi un luogo di provincia che però in realtà negli anni ‘90 aveva molto fermento legato alla cultura hip hop, perché c'erano due gruppi rap molto importanti che erano TR e Sottotono, e questo faceva sì che fosse un polo molto importante in questa cultura a livello italiano, quindi ho avuto l'opportunità di conoscere tanti Writer dell’epoca. In quel periodo si lavorava attraverso l'esperienza diretta, guardando gli altri lavorare, non c'era YouTube, non c'erano tutorial, c'erano solo fanzine che giravano, oppure si andava alle Jam per vedere gli altri Writer dipingere. Questo è stato il mio approccio, quindi è qui che ho imparato a utilizzare le bombolette spray. Dopo le scuole superiori ho iniziato a studiare all'Accademia di Belle Arti di Brera, questo mi ha portato ad approcciare altre tecniche, approfondire altri stili, per poi tornare con la bomboletta spray, però con una mentalità molto diversa, molto più da pittore.
Come è nata l'idea, dimostratasi poi vincente, di realizzare delle pinacoteche a cielo aperto?
Questa è un'idea che avevo nel cassetto da tanti anni, ho sempre lavorato a progetti molto differenti, analizzando ad esempio tutto quello che era il cambiamento dei social network, attraverso la pittura ho fatto esperimenti di ogni genere e questo era un progetto che avevo in testa da molto tempo. Quello di legare due mondi molto distanti, che erano la tradizione della copia, una cosa molto antica che possiamo far risalire addirittura all'antica Grecia, con le statue romane che venivano copiate da quelle greche. Spostandoci poi avanti di qualche centinaio di anni, quando il caravaggismo si diffonde attraverso le copie, in epoche pre-Gutenberg ovviamente. Per essere trasmessa, l'immagine a colori aveva bisogno di una copia fisica reale.
Ho adottato questa tradizione per poi associarla alla tecnica della bomboletta spray, che proviene ovviamente dal mondo del Graffiti Writing. Questa idea di Pinacoteca a cielo aperto è nata proprio dall'idea di unire questi due mondi, riproducendo per la prima volta nel 2016 la Cattura di Cristo di Caravaggio, che è stato il mio primo lavoro. Ormai ho dipinto più di 150 muri in giro per tutto il mondo, però l'idea era proprio quella di portare all'esterno dei musei queste opere d'arte classica e tradurle sulle grandi pareti, non parlo di copia, ma piuttosto di traduzione, perché non utilizzo la stessa tecnica e la stessa taglia, ma bombolette spray e ingrandimenti molto, molto grandi. Questa è stata l'idea, la base del progetto intitolato Recupero del classicismo nel contemporaneo.
Come si relazionano le tue opere con l'ambiente urbano circostante?
Le mie opere si relazionano ovviamente attraverso una correlazione con il territorio. Prima di tutto vado a scegliere i soggetti in base al territorio dove sto operando, quindi se c'è la presenza di un museo o il territorio ha visto la nascita di un pittore classico molto importante. A volte agisco con delle micro correlazioni, a volte con delle macro correlazioni, nel senso che a volte è proprio un piccolo paese che ospita quella particolare opera, io la vado a riprodurre, la faccio uscire fuori dall'istituzione museale per poi incuriosire le persone e farle rientrare all'interno del museo. Altre volte mi è capitato di lavorare con delle macro correlazioni, quindi magari in quella regione è nato tale pittore e io lo vado a riprodurre. C'è una relazione anche con la superficie, cioè la taglia del muro, la collocazione, dove è posizionato.
C'è qualche opera che ritieni particolarmente rappresentativa della tua visione artistica?
L’opera che ritengo particolarmente significativa sicuramente è il primo muro, l'opera che ho dipinto a Varese, alla Rotonda dell'Iper, che è la Cattura di Cristo di Caravaggio. Un'altra opera che mi sta particolarmente a cuore è Le Tricheur à l’as de carreau di Georges de La Tour, che ho dipinto all'Università di Nanterre a Parigi. Anche questa è stata un'opera per me molto importante, una delle prime in Francia, che ha dato il via a tutto quello che è stato il mio percorso artistico in Francia. E poi, se devo dire, una terza opera che mi sta particolarmente a cuore è sicuramente il muro che ho fatto in Brasile per i 50 anni di gemellaggio tra la città di Sao Paolo e la città di Milano, dove ho rappresentato un quadro di Moretto da Brescia che è conservato a Santa Maria del Celso a Milano, che rappresenta proprio San Paolo e l'ho portato in Brasile su un muro di 45 metri. Al momento, è stata l'opera più grande che ho fatto.
Come ti sei approcciato inizialmente all'intelligenza artificiale generativa? E come hai trovato il modo per integrarla nel tuo lavoro?
Come detto nella prima domanda, io sono un grande appassionato di tecnologia. Quando è arrivata l'intelligenza artificiale, sono veramente rimasto folgorato da quello che era la tecnica del Text to Image. Parlo di due anni e mezzo fa, quindi stava appena diventando alla portata di tutti. Se guardo quello che posso creare adesso, sembrano passati vent'anni di avanzamento. In realtà, è trascorso molto meno tempo, ma è stato uno degli impatti visivi più forti che abbia mai avuto. Avendo vissuto tutte le più grandi rivoluzioni tecnologiche ed elettroniche degli ultimi anni, questa esperienza è stata particolarmente sconvolgente. Non mi aspettavo qualcosa di così magnifico. Sono stato subito folgorato e non ne ho avuto paura, ho sempre pensato che potesse essere un assistente, un qualcosa che mi permettesse di avere comunque di fianco una tecnologia che poteva darmi una mano in quello che sviluppavo.
Poi il mio approccio è stato ovviamente quello di tradurre e copiare ciò che l'intelligenza artificiale restituiva dai miei Prompt. Ho creato un mio modello partendo da Stable Diffusion, addestrandolo su determinati artisti classici. Questo perché mi permetteva di ottenere immagini uniche, di mia esclusiva proprietà, e ho trovato questa esperienza molto interessante. Ho iniziato così a miscelare vari artisti dell'arte classica, e questo è un filone che porto avanti parallelamente all'altro progetto di recupero del classicismo nel contemporaneo. La mia tecnica rimane sempre la stessa: utilizzo le bombolette spray sia su tela che su grandi superfici murali.
Secondo te, un artista è definibile più da cosa sa fare tecnicamente o dalle sue idee concettuali e dalla visione? Ti pongo questa domanda perché noto che molti creativi hanno un totale ripudio nei confronti dell'IA, definendola come un "rigurgito" e lamentandosi del fatto che permette chiunque di generare belle immagini senza dover imparare la tecnica
Questa definizione lascia un po' il tempo che trova, una sorta di rigurgito. Nel senso che genera immagini, ma si tratta di immagini digitali, quindi di cosa stiamo parlando, esattamente? Forse possono lamentarsi coloro che lavorano nell'ambito della computer grafica, ma ricordiamo che la computer grafica di alto livello esiste da relativamente pochi anni.
Ecco un esempio semplice: mio padre era un grafico pubblicitario e illustratore; è morto nel 2011. All'inizio lavorava con aerografo e Letraset, prima dell'avvento della computer grafica. Negli anni '90 gli mancavano quasi dieci anni alla pensione, e ha dovuto adattarsi all'uso dei computer. È così che ho iniziato anch'io, lavorando sui 386 e 486. All'inizio lavoravo con Corel Draw e PageMaker, poi è arrivato Photoshop. Ho vissuto in prima persona tutta l'evoluzione della computer grafica. Negli anni '80, mio padre realizzava molte copertine di videogiochi. Quando non c'era ancora la computer grafica, e i videogame erano veramente a livello grafico, passatemi in termini, scarsi, e quindi le copertine dovevano essere super fighe per riuscire a vendere. Mio padre aveva copertine che andavano su The Game Machine, faceva un sacco di pubblicità ed illustrazioni a riguardo. Poi con l'avvento della computer grafica è cambiato un po' tutto, ecco. Ora è arrivata l'intelligenza artificiale, bene, è un'evoluzione, quindi chi si sta lamentando è gente che in realtà poi ha preso il posto di altre gente come mio padre all'epoca, che è stata sostituita attraverso l'utilizzo della computer grafica, quindi di che cosa stiamo parlando? Del nulla, nel mondo c'è sempre stata un'evoluzione, ci sono sempre state delle grandi rivoluzioni.
Prendiamo l'esempio della fotografia: quando Daguerre la introdusse, ci fu un grande fermento. Molti sostenevano che la pittura fosse morta con l'avvento della fotografia e che questa rubasse le immagini. Ecco, la fotografia oggi ha più di 150 anni e non vedo assolutamente nessun tipo di cambiamento, è uno strumento come l’IA. Se la gente impara utilizzarlo, bene, se non lo vuole utilizzare, amen. Se invece si vuole lamentare o cercare di fermarlo, è come tentare di fermare uno tsunami con un foglio A4.
Utilizzare l'IA nelle proprie creazioni significa, in un certo senso, riconoscerle una capacità di interpretare il "bello". Qual è per te il confine tra l'estetica generata dall’IA e quella creata dall’umano?
A mio avviso, il confine è sempre più sottile. Dipende da noi: attraverso i prompt o il caricamento di altre immagini definiamo la direzione. L'intelligenza artificiale generativa non è legata solo al text-to-image, ma anche all'image-to-image, quindi, in realtà, posso anche combinare altre immagini o modificarle leggermente. Per questo motivo, non riesco a individuare un vero e proprio confine.
Tornando al discorso, chi possiede la tecnica la utilizza e la traduce in opere. Se invece rimangono semplicemente immagini digitali, allora lasciano il tempo che trovano. Non è il mio campo: io sono un pittore e la pittura non può essere sostituita dall'intelligenza artificiale. Se in futuro un androide o un cyborg fosse in grado di dipingere, non cambierebbe nulla per me. Il mio lavoro acquisterà ancora più valore, così come accade da decenni in altri settori, come ad esempio il ricamo. Con l'arrivo dei telai automatici durante la prima rivoluzione industriale il ricamo automatico si è diffuso. Oggi, dopo oltre un secolo, il ricamo fatto a mano continua a essere più valorizzato, perché attribuiamo un enorme valore al tempo e all'errore umano, considerandolo persino un elemento estetico.
L'errore, sotto certi aspetti, è persino affascinante. Per questo il ricamo automatico ha un valore inferiore. La tecnologia funziona così, ma l'uomo continua a dare importanza alla manualità e al confronto con essa. Quindi il mio lavoro non cambia. Anzi, ripeto, è uno strumento che mi permette di progredire
Proviamo a giocare con le definizioni: secondo te, gli ingegneri che, tra complesse architetture neurali e algoritmi matematici, hanno creato i primi modelli che generano immagini di alta qualità, potrebbero essere definiti come degli "artisti"? Perché?
No, non potrebbero essere definiti come degli artisti, altrimenti dovrebbero essere definiti artisti anche i programmatori di Photoshop, o quelli che hanno programmato CorelDRAW, o quelli che hanno inventato il tubetto a olio. Prima si facevano i colori all'interno degli atelier, poi sono nati i tubetti a olio e gli artisti sono potuti uscire all'esterno, sono nati gli impressionisti grazie a questa tecnologia. Queste persone sono programmatori che hanno aiutato gli artisti, quindi non riesco a definirli artisti in realtà, hanno solo creato degli strumenti per gli artisti.