


I Pionieri del Nuovo Mondo
Di come la tecnologia sta cambiando radicalmente ogni approccio alla creatività


Dall’idea all’esecuzione
È da più di un anno che scrivo post su Linkedin riguardanti il rapporto tra creatività e tecnologia, eppure l’idea di iniziare una newsletter non era mai emersa per davvero. Ho sempre visto questo tipo di attività come un grosso investimento di tempo che tendenzialmente non ripaga, e i miei impegni lavorativi mi renderebbero assai difficile mantenere una pubblicazione costante. Lunedì 24 giugno però mi è scattato un qualcosa che stava probabilmente ribollendo dentro di me da un po’ di tempo, e mi son detto: Facciamolo! - Ho lanciato un sondaggio nelle mie Instagram stories per capire se questa cosa potesse effettivamente interessare a qualcuno che non fossero solo i miei due amici che mi supporterebbero anche se decidessi di organizzare un attentato (si scherza, cari amici della CIA), e ho ricevuto ben 10 voti di approvazione, e sì, non sono mai stato uno particolarmente popolare, ma tanto mi bastava.
5 ore dopo ho pensato al titolo e a come strutturare il tutto. Ho capito che avrebbe dovuto essere un appuntamento mensile, e non solo per mia pigrizia. Il motivo principale che mi spinge a fare solo 12 pubblicazioni all’anno, è che le newsletter settimanali mi annoiano, mi ci iscrivo ma non le apro mai e continuo a rimandare la lettura finché non se ne accumulano troppe e decido di cestinarle direttamente senza neanche dargli un’occhiata. Ecco, gradirei che la mia non incombesse nello stesso destino, e puntare su una pubblicazione meno frequente, ma più curata, penso che potrà aiutare - Ho quindi deciso di ispirarmi ai magazine, piuttosto che ad altre newsletter, così da avere tutto lo spazio creativo di cui ho bisogno per parlare liberamente di creatività.
Tornando a noi, il giorno dopo ero già all’opera per concretizzare l’idea. Ho pensato al titolo del progetto (che dopo vi spiegherò), creato il logo usando Midjourney e preparato l’account di Substack. Il giorno dopo ancora, ho concluso gli ultimi dettagli e aperto ufficialmente le iscrizioni, annunciando anche che domenica avrei fatto la prima pubblicazione. Da quel momento non mi sarei più potuto tirare indietro, e infatti son qua che scrivo l’introduzione all’una di notte. Mi ci vorrà un po’ per prendere il ritmo, ma come ho imparato negli ultimi anni: done is better than perfect.
Insomma, dall’idea all’esecuzione in 6 giorni, se questa non è dedizione…
Bene, ora entriamo nel vivo e iniziamo a parlare delle cose serie!
Cosa aspettarsi da questo progetto?
Quando poche righe fa vi dicevo che il progetto si ispira ai magazine, non lo stavo dicendo giusto per darmi un tono. Questa non è una newsletter, ma un vero e proprio magazine digitale unico nel suo genere, all’interno del quale potete aspettarvi le rubriche più disparate, che prenderanno forma un po’ alla volta.
Per il momento, questo è ciò che ho in mente di inserire:
Approfondimenti più o meno tecnici per principianti
Notizie che ritengo essere rilevanti
Focus artistici
Risorse open-source per smanettoni
Recensioni/tutorial di strumenti o nuove funzionalità nel panorama AI
Consigli per approfondire meglio certe tematiche
Una rubrica solo su Midjourney
Ricerche scientifiche interessanti che trovo in giro
Interviste/collaborazioni con personalità rilevanti in quest’ambito
Riflessioni e progetti artistici personali
Ovviamente non è verosimile che io riesca a inserire tutto questo in ogni singola pubblicazione, quindi aspettatevi una gran varietà contenutistica di mese in mese, e delle pubblicazioni un po’ più lunghe rispetto a questo primo numero.
Cosa significa Tales from the Latent Space?
Non vi nascondo che il principale motivo per il quale ho scelto questo nome, è che suona dannatamente bene. Tales from the Latent Space richiama l'idea di esplorare un mondo nascosto, pieno di possibilità infinite che possono emergere da una sorta di brodo primordiale fatto di dati. È un luogo dove l'immaginazione prende forma, un crocevia tra l'umano e la macchina. Qui, ogni racconto è un pezzo di un puzzle più grande, un invito a esplorare l'insolito e a scoprire come la tecnologia può trasformare la nostra creatività in modi sorprendenti.
In questo spazio, scompare il confine tra creatore e creazione, permettendoci di collaborare con l'intelligenza artificiale come non avremmo mai potuto pensare. Questo non è solo un luogo di sconfinate possibilità tecniche, ma un terreno fertile per l'innovazione artistica e culturale.
Attenzione, allontanarsi dalla linea gialla, stiamo per partire…

Che cos’è lo Spazio Latente?
Al di là delle metafore suggestive, lo spazio latente (detto anche spazio di incorporamento) esiste per davvero, ed è tra i principali componenti dei moderni modelli di IA generativa. Inauguro quindi la rubrica degli approfondimenti tecnici per cercare di spiegare questo concetto ai neofiti.
Possiamo immaginarlo come un’immensa biblioteca, nella quale ogni libro è stato catalogato secondo un insieme di pattern molto particolari. Invece che essere ordinati per titolo, autore e genere, questi libri sono stati analizzati da un computer che ha compreso tutte le loro caratteristiche, da quelle più ovvie come lo stile di scrittura, a quelle più insolite come la frequenza di certe parole rispetto ad altre. Queste caratteristiche sono poi state riassunte con dei numeri, che possono rappresentare qualunque specifica del libro. Suddetto “riassunto numerico” permette di organizzare e comparare i libri in modo molto efficiente, anche se ad un occhio esterno non risulta ben comprensibile.
Lo spazio latente è simile a questa biblioteca, ma si crea coi dati di addestramento di alcuni tipi di intelligenza artificiale, come GPT, Claude, Midjourney, Stable Diffusion, ecc. Quando una rete neurale artificiale elabora dei dati, che possono essere testo, immagini, audio, video, o altro, cerca di trovare il modo per rappresentarli in una forma più compatta e astratta, ovvero con dei vettori (i numeri di cui parlavamo prima) che catturano le caratteristiche distintive dei dati originali.

Questi vettori formano uno spazio virtuale, detto appunto spazio latente, all’interno del quale i dati con più similitudini si collocano più vicini tra loro, e vice versa. Ad esempio, nello spazio latente di un modello che genera immagini, tutte le immagini di cani saranno raggruppate vicine. La stessa cosa accade con le immagini di banane, che saranno anche lontane da quelle dei cani.
Quindi, lo spazio latente è come una mappa numerica che ordina, relaziona e rappresenta i dati in maniera efficiente per il modello di IA, permettendogli di fare previsioni, riconoscimenti o generazioni di nuovi dati con un certo grado di accuratezza.
Cosa è successo nell’ultimo mese?
Dalla fine di maggio al momento in cui sto scrivendo queste righe (29 giugno), nel panorama dell’IA generativa sono successe un sacco di cose! Al punto da aver faticato davvero molto per star dietro a tutto. Eccovi quindi una mia personale selezione di notizie che ritengo essere molto rilevanti:
Dalla Cina con furore
Kling è un nuovo modello per la generazione di video prodotto dall’azienda cinese Kuaishou. Da quando è stato rilasciato in beta meno di un mese fa, ha stupito tutti per la qualità delle sue immagini che si avvicinano tantissimo al livello di Sora.
Tra le sue caratteristiche principali, c’è la possibilità di generare video in 1080p a 30fps fino a due minuti di lunghezza (anche se qualcuno che l’ha provato dice 3 minuti), e la capacità di risultare estremamente realistico nel rappresentare le interazioni fisiche tra gli oggetti nello spazio.
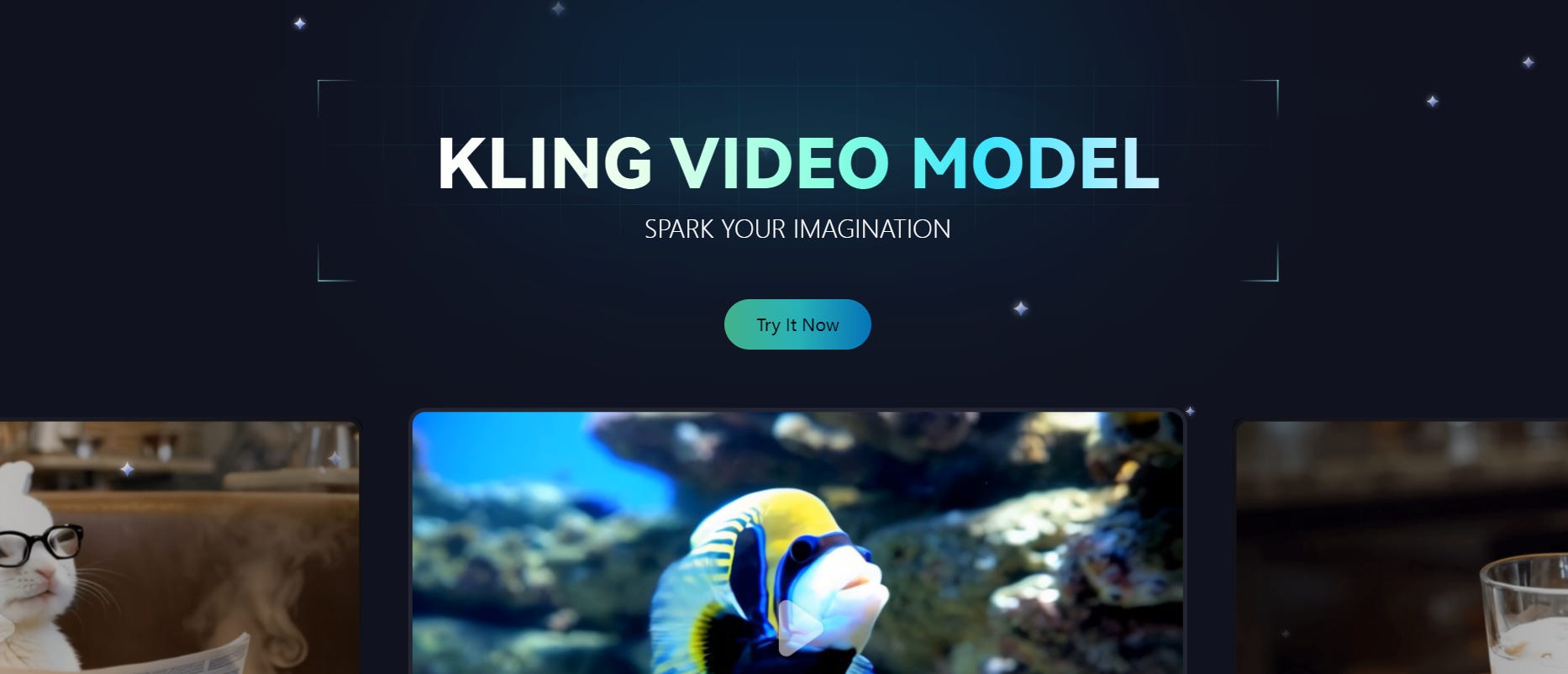
Ok ma come è possibile? Sul loro sito viene abbozzata una spiegazione, ma senza dei paper dettagliati risulta un po’ difficile da capire:
KLING AI utilizza un sistema di attenzione spazio-temporale 3D per modellare accuratamente il movimento e le interazioni fisiche. Utilizza anche un diffusion transformer per combinare concetti e creare scene immaginarie. Ciò consente al modello di generare video lunghi e ad alta risoluzione in modo efficiente.
La spiegazione è molto abbozzata, ma ci fa intuire che il 3D gioca un ruolo fondamentale nella generazione di video realistici.
La macchina dei sogni
A proposito di 3D, sempre nel mese di giugno Luma Labs ha rilasciato Dream Machine, un altro incredibile modello per i video. Prima dell’avvento di questo prodotto, Luma era nota per l’omonima app che permette di “scansionare” una scena o un oggetto reale con la fotocamera dello smartphone, per poi riprodurlo tridimensionalmente grazie alla tecnologia NeRF.

L’app in questione è sempre stata gratuita, e vien quindi da pensare che sia stata usata dall’azienda per raccogliere grandi quantità di dati tridimensionali con i quali hanno addestrato il modello per i video.
Come il suo rivale Kling, anche questo modello ha una qualità comparabile a quella di Sora, e personalmente ritengo che al momento sia il miglior video model sul mercato.
Ma non finisce qui, perché giusto qualche giorno fa Dream Machine è stato aggiornato con la nuova funzionalità Keyframe, che ci permette di fare una sorta di morphing tra due immagini animate.
Il ritorno dall’oltretomba
Sentendosi probabilmente sotto pressione per gli annunci e le uscite di tutti questi nuovi modelli video super performanti, Runway ML annuncia in pompa magna l’imminente arrivo di Gen3, erede dell’ormai obsoleto Gen2.

Runway è un servizio che ho utilizzato in maniera molto approfondita, esplorandolo in ogni suo aspetto e funzionalità. L’ho sempre ritenuto uno strumento dal grosso potenziale per via delle sue ottime funzionalità di controllo delle inquadrature e dei movimenti di macchina, oltre che per la presenza di una timeline di video editing, ma i suoi modelli Gen1 e Gen2 non hanno mai brillato per qualità.
Dalle anteprime che hanno mostrato, anche Gen3 sembra avvicinarsi molto alla qualità visiva di Sora, ma al momento è disponibile solo per chi fa parte del loro Creative Partners Program.
Una constatazione che mi sento di fare, è che le clip prodotte dagli utenti con l’accesso in anteprima sono qualitativamente molto inferiori rispetto a quelle mostrate dall’azienda circa due settimane prima - probabilmente perché, sentendo questi utenti, non hanno ancora sbloccato la funzionalità image2video, e il text2video è generalmente meno performante. Questo mi fa pensare che abbiano rilasciato un modello ancora molto acerbo giusto per non rimanere indietro e perdere troppi abbonati. Sono scelte che comprendo, ma sarebbe anche bello poter vedere meno marketing e più trasparenza da parte di queste aziende.
Nuovi giocatori che scendono in campo
Giusto per non farci mancare nulla, nel mese di giugno è approdata sul mercato una nuova azienda che sta creando i suoi modelli per i video.
Mi sto riferendo a Hedra Labs, che ha come obiettivo la creazione modelli fondativi per potenziare la prossima generazione di storyteller, e ha da poco rilasciato in beta il suo primo modello Character-1.

Character-1 permette di generare video con personaggi umani espressivi e controllabili, ma al momento trovo che sia ancora un po’ indietro rispetto ad altri modelli simili o agli avatar di servizi come Heygen e Synthesia. Il potenziale è sicuramente interessante, e vi comunicherò gli eventuali sviluppi nei prossimi numeri.
Il mercatino dell’open-source

In ogni numero di Tales from the Latent Space, troverete questa piccola rubrica dedicata alle risorse open-source, che può tornare molto utile ai lettori più smanettoni. In questa prima edizione ho 3 risorse per voi:
DeepFaceLive - Permette di modificare il proprio volto in diretta da una webcam o da un video utilizzando dei modelli addestrati su altre facce. Ha anche tutta una serie di altre funzionalità legate all’animazione dei volti e al face swap partendo da singole immagini. Utile per chi vuol sperimentare coi deepfake.
V* - Si tratta di un meccanismo di ricerca visiva guidato da LLM che utilizza questi modelli di linguaggio per delle query visive efficienti. Se combinato con un MLLM (multimodal large language model), questo meccanismo migliora il ragionamento collaborativo, la comprensione contestuale e il targeting preciso di elementi visivi specifici. In sostanza, permette di utilizzare il linguaggio naturale per fare ricerche all’interno di immagini. Ad esempio, possiamo caricare un’immagine piena di oggetti e chiedere al modello di indentificarne uno in particolare. Questo potrebbe tornare molto utile nella risoluzione di alcuni crimini partendo dalle immagini di telecamere a circuito chiuso.
Make Real - Permette di disegnare una UI e renderla subito funzionante ottenendo un file HTLM testabile fin da subito all’interno di un iframe.
Personalizzare Midjourney
Una delle componenti più interessanti dell'IA generativa, è la possibilità di personalizzare l'esperienza utente in modi che sarebbero stati impensabili fino a pochi anni fa, e il team di Midjourney questa cosa l’ha capita molto bene!
Infatti, poche settimane fa hanno aggiunto una nuova funzionalità chiamata model personalization, che permette di adattare l'algoritmo di Midjourney ai propri gusti personali, rimuovendo una grossa parte dei suoi “bias visivi”.
Questo è reso possibile da un sistema di votazione disponible sulla piattaforma. Per farla breve, possiamo scegliere tra due immagini quale preferiamo maggiormente, e dopo aver votato almeno 200 coppie, Midjourney avrà imparato i nostri gusti estetici e da quel momento potremo personalizzare la generazione di immagini inserendo il parametro —p alla fine dei nostri prompt.

Quando abilitiamo questo parametro, otterremo un codice univoco condivisibile che racchiude i nostri gusti visivi. Se qualcuno vuol provarlo, il mio codice è b8j4vs5.
Il codice del parametro —p può anche essere combinato con i codici di altri utenti, e con il parametro —sref, che a sua volta può venir mischiato con altri codici style reference e gli URL di immagini di riferimento. Ad esempio:
[mio prompt] —p [mio codice] [codice altrui] —sref [codice] [codice] [url]
Per controllare l’intensità del parametro di personalizzazione, bisogna utilizzare il parametro stylize, che normalmente influisce sulla “libertà” che diamo a Midjourney di seguire il suo stile di base, che risulta spesso un po’ stereotipato.
Con --s 0 il parametro è disattivato, --s 100 è l'impostazione predefinita, --s 1000 è il massimo dell’intensità. Personalmente, quando uso —p mi piace mantenere —s in un range compreso tra 500 e 1000 in base ai risultati che voglio ottenere.
Sperimentando con questo parametro, ho notato che tende a migliorare leggermente anche la qualità complessiva delle immagini.
Di seguito, potete vedere come il parametro —p influenzi significativamente la generazione di immagini a parità di prompt.


E luce fu
Da un po’ di tempo sono stato inserito nel programma di beta testing di Magnific, un software nato con l’obiettivo di essere il miglior upscaler* sul mercato, e che da diversi mesi ha iniziato a espandersi con altri strumenti (che loro chiamano “incantesimi”) per l’editing delle immagini.
L’ultimo incantesimo che hanno rilasciato si chiama Relight, e ho avuto la possibilità di testarlo in anteprima. Relight permette di trasformare l’illuminazione di un’immagine A, utilizzando come riferimento un’immagine B, un prompt testuale o una lightmap, ovvero una rappresentazione bidimensionale di uno schema luci, dove il nero indica le ombre e i colori più luminosi sono i punti luce.
*col termine upscaler si intende un software pensato per ingrandire le immagini aumentandone la risoluzione complessiva. In alcuni casi si utilizza un modello di machine learning in grado di moltiplicare il numero di pixel di un’immagine, mentre Magnific utilizza Stable Diffusion per fare una sorta di “scansione” dell’immagine e riprodurla nuovamente in una risoluzione maggiore. Questo comporta delle variazioni più o meno lievi rispetto all’originale.

Ho sperimentato col nuovo strumento in lungo e in largo per poter riportare le mie oneste e attente considerazioni. Le immagini che vedrete qui sotto, non sono state selezionate per dimostrare qualcosa in particolare (cherry picking) e non sono state modificate, sono le generazioni originali così come le ho ottenute dallo strumento.
Il primo test l’ho fatto utilizzando un'immagine con dei forti contrasti e ho notato subito alcuni piccoli problemi che mi hanno fatto storcere il naso:
1⃣ Ha molta difficoltà nel mantenere i colori dei vestiti
2⃣ Alcune ombre rimangono identiche all'immagine originale
3⃣ Il tono della pelle ne risente molto

Poi ho provato con un'illustrazione su sfondo neutro, e i risultati non erano niente male! In questo caso l'illuminazione è stata trasposta molto meglio.
L'unico problema che ho riscontrato, è che a volte inventa (o rimuove) parti e dettagli del personaggio. Nel robottino in esempio, a volte scompaiono le antenne, cambia la conformazione delle mani, e un po’ anche dei piedi. In un’immagine che non ho selezionato, perché ho poi risolto modificando un parametro, si era proprio inventato di sana pianta dei nuovi componenti nei piedi del robot. Questo è dovuto alla natura intrinseca dello strumento, che si basa su un modello di diffusione latente.

Uno dei migliori casi d'uso che ho trovato, è quello dei rendering architettonici. Con Relight è possibile svolgere una buona parte di questo tipo di lavoro senza Photoshop, velocizzando drasticamente i tempi di esecuzione e di prototipazione.
Penso che tutte le accademie e gli studi di architettura dovrebbero avere a disposizione questo strumento. E a tal proposito, nella pubblicazione del mese prossimo vi parlerò in maniera approfondita di un workflow che, combinando tutti gli strumenti di Magnific, può trasformare la bozza di un’architettura in un rendering spaventosamente realistico!
(dite quindi ai vostri amici architetti di iscriversi)

Ho poi notato che sui ritratti con un'illuminazione più neutrale si ottengono dei risultati decisamente migliori, al punto che si potrebbero utilizzare professionalmente.
Purtroppo rimane il problema degli abiti che non vengono mantenuti uguali al 100%. Nell'esempio potete vedere che nella zona delle spalle sono stati inventati alcuni dettagli, ma penso che sia un compromesso accettabile rispetto alle potenzialità di questo strumento ancora in beta.

A malincuore, devo dire che i risultati più deludenti li ho ottenuti con le foto di prodotti reali. Online (principalmente su X e Linkedin) potete trovare un sacco di post dai claim roboanti in cui gli autori, che non sono certamente dei grandi intenditori di foto prodotto, raccontano di come Relight sia lo strumento perfetto per questo tipo di immagini, ma purtroppo la realtà è molto diversa.
Come potete vedere nell’esempio qui sotto, lo strumento non è in grado di mantenere intatti alcuni dettagli essenziali come scritte, loghi e numeri sul quadrante. Questo difetto lo rende inadatto a un uso professionale, soprattutto per certi prodotti come orologi, automobili e oggetti di design, che devono apparire esattamente per come sono nella realtà.

L'unica eccezione a cui riesco a pensare, riguarda i prodotti molto semplici e spesso artigianali come le saponette, che non richiedono un’accuratezza del 100%.

Il mio ultimo test ha riguardato i meme, che a discapito di quel che si potrebbe pensare, negli ultimi anni stanno diventando una forma di comunicazione molto seria. Per chi si occupa di meme, Relight è obiettivamente uno strumento super divertente che apre le porte a tantissime possibilità creative!

Se Christo avesse incontrato l’IA
Nel 2010, l’artista Lorenzo Servi, in arte SerraGlia, ha iniziato a fotografare tutti gli oggetti coperti che gli capitava di vedere in giro. Ha poi recentemente utilizzato l’intelligenza artificiale per trasformare queste foto in un nuovo linguaggio visivo.

4o
Le immagini generate con IA puntano al realismo, alla precisione, all’utilità pratica, mentre questo progetto abbraccia l'astrazione, fondendo il reale con l’immaginario.
Quando vediamo qualcosa di nuovo, che sia un oggetto, una persona, un evento o una dinamica sociale, cerchiamo istintivamente di capirlo confrontandolo con qualcosa che ci è familiare, pensando in maniera più o meno consapevole: Mi ricorda...
Ma secondo l’artista, questo può limitare la nostra percezione e ciò che possiamo vedere nella vita di tutti i giorni.
Possiamo davvero vedere qualcosa che non abbiamo mai visto prima?
Possiamo apprezzare qualcosa di completamente nuovo e stupirci come se fosse la prima volta?Questo progetto è un parco giochi per la tua immaginazione, che ti invita a vedere oltre il familiare.
Quando ho visto questo splendido progetto, non ho potuto esimermi dal pensare alle opere di Christo e Jeanne-Claude, che hanno fatto dell’impacchettamento un loro tratto distintivo, esprimendo dei concetti molti simili all’idea di Lorenzo Servi.
Wrapped Wonders, è ora esposto in una mostra collettiva nell'Art Center Purnu, in Finlandia. Rimarrà in esposizione dal 15 giugno all’11 agosto 2024.