


Il Senso del Tempo nel Nuovo Mondo
Nell’era della simultaneità, il tempo non scorre: si dissolve, si ricompone, si reinventa. Abitiamo un presente fluido in cui l’attimo è eterno e incostante


DISCLAIMER:
Questo magazine è concepito per essere lungo, complesso e dettagliato, più simile a un vero magazine cartaceo che a una semplice newsletter. Alcuni provider email, però, limitano la visualizzazione di testi e immagini oltre una certa soglia, tagliando parte dei contenuti. Per leggere ogni numero nella sua interezza: articoli, rubriche e approfondimenti, vi consiglio di aprirlo direttamente sulla piattaforma Substack, via browser o app, dove potete trovare anche l’Archivio completo nel quale si possono recuperare tutte le pubblicazioni del passato.
Questo numero di Tales from the Latent Space è una versione un leggermente ridotta rispetto al solito, perché contiene un articolo di approfondimento in meno. In compenso, la rubrica Avvenimenti del mese è più lunga rispetto agli standard, perché maggio è stato un mese veramente denso di avvenimenti.
A tendere, i nuovi numeri del magazine cambieranno forma nel tentativo di costruire una versione premium a pagamento, mantenendo questa classica versione in formato “newsletter” un po’ più ridotta. Questo cambiamento è dovuto alla progressiva trasformazione del progetto in una struttura aziendale vera e propria e alle difficoltà oggettive nel portare avanti un magazine così complesso e approfondito in maniera completamente gratuita. Per maggiori informazioni, si prega di approfondire nella sezione finale L’angolo degli annunci, dove viene spiegata meglio l’idea di creare una media company attorno a Tales from the Latent Space.
Come ogni mese, è arrivato il momento di allontanarsi dalla linea gialla. Il nostro treno per il Nuovo Mondo è in arrivo.

Che cos’è l’Apprendimento per Rinforzo?
Quando parliamo di apprendimento per rinforzo (reinforcement learning - RL) abbiamo a che fare con un’idea che precede i calcolatori: la scoperta, in etologia e psicologia comportamentale, che un organismo ripeta i comportamenti che vengono premiati e abbandoni quelli puniti. I primi a codificare questa intuizione furono Pavlov, Thorndike e Skinner, ma l’informatica l’ha poi trasformata in uno strumento di progettazione: l’organismo diventa un agente, l’ambiente un modello formale (spesso simulato), il premio un valore numerico insito nella logica dell’algoritmo. L’obiettivo non è quindi il piacere immediato ma la massimizzazione, nell’arco di un futuro incerto, della somma scontata delle ricompense. Per dirlo in altri termini, l’agente cerca di ottenere il massimo di ricompense complessive, ma dà maggiore importanza a quelle che arrivano prima e via via meno peso a quelle più lontane nel tempo, in modo da mantenere un equilibrio tra risultati immediati e benefici futuri.
In questa formula essenziale compaiono i due elementi che rendono l’apprendimento per rinforzo così affascinante ma anche complesso: l’orizzonte temporale aperto e l’esplorazione di ciò che non si conosce ancora.

Per rappresentare l’intuizione iniziale in equazioni occorre definire un Processo decisionale di Markov (MDP). Ovvero un modello matematico basato su quattro elementi fondamentali:
Stati, che descrivono ciò che l’agente percepisce in un dato momento;
Azioni, le scelte che l’agente può compiere in ogni stato;
Transizioni, le regole (spesso probabilistiche) che stabiliscono come lo stato cambia quando l’agente agisce;
Ricompense, i feedback numerici che indicano quanto ogni azione sia andata “bene” o “male”.
Dato lo stato sₜ, scegliere un’azione aₜ porta a una distribuzione di possibili prossimi stati sₜ₊₁ e a una ricompensa rₜ₊₁. Questa semplificazione non esaurisce la complessità del mondo, ma la rende trattabile dal punto di vista computazionale. La bussola dell’agente è la funzione valore ottimale V*(s), che sintetizza in un unico giudizio quanto convenga trovarsi in un certo stato, considerando tutte le ricompense future attese se, a ogni passo, si compie la scelta migliore possibile. Per calcolare questo giudizio, si usa l’equazione di Bellman, che afferma in modo ricorsivo:
Il valore di uno stato è dato dalla ricompensa immediata che posso ottenere da lì, più il valore del prossimo stato in cui mi troverò, una volta scelta l’azione migliore
L’equazione di Bellman è il ponte che collega presente e futuro:
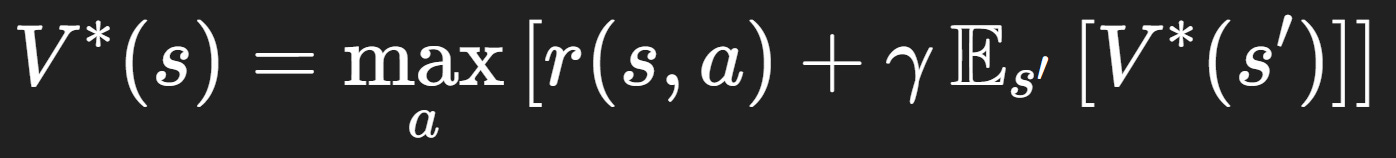
Può sembrare arida matematica, ma è il cuore emotivo del processo, perché trasferisce l’eco delle ricompense lontane nei singoli step attuali dell’agente, proprio come le decisioni di oggi riverberano sul domani di un essere umano.

Dai mattoni dinamici alla costruzione degli algoritmi
Nei primi anni Ottanta, Richard Sutton propose il Temporal-Difference learning (TD) proprio per permettere all’agente di aggiornare la propria stima del valore di uno stato mentre interagisce con l’ambiente, senza attendere la fine dell’intero episodio (la sequenza completa di interazioni). Se V(sₜ) è la stima corrente del “valore” dello stato sₜ, allora l’aggiornamento TD avviene dopo ogni transizione così:
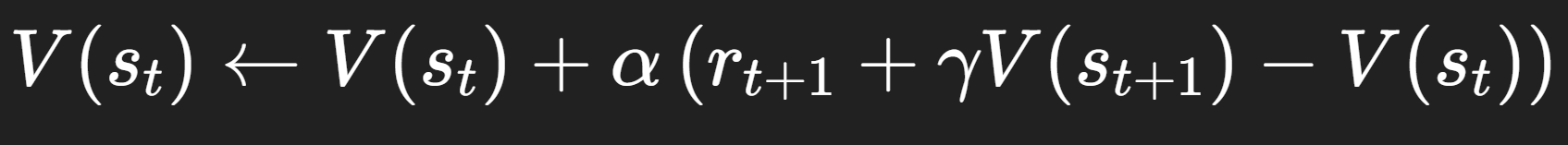
Dove α è il tasso di apprendimento (quanto è disposto a cambiare la sua stima), rₜ₊₁ la ricompensa che riceve subito dopo aver compiuto l’azione, γ il fattore che “sconta” le ricompense future e V(sₜ₊₁) la stima del valore del nuovo stato.
Qualche anno più tardi, Chris Watkins spostò il focus dalla stima di valore dello stato alla stima del valore della coppia stato-azione, dando vita al Q-learning. In questo schema l’agente costruisce una vera e propria tabella (o funzione) Q(s,a) che misura “quanto conviene” scegliere azione α nello stato s:

Grazie a questo aggiornamento, ogni cella Q(s,a) diventa un’indicazione diretta della migliore mossa da fare, anziché passare per la stima separata di quanto vale lo stato.
Ora proviamo a rispiegarlo con una metafora: immaginate un robot-esploratore che raccoglie monete in un labirinto. Con TD, il robot impara a valutare “quanto vale” ogni posizione strada facendo: a ogni passo somma la moneta appena presa e la sua vecchia stima di quante monete potrà raccogliere da lì in poi.
Con Q-learning, invece, impara direttamente quale direzione conviene prendere in ogni punto: ogni mossa viene premiata col numero di monete ottenute subito più la miglior estrazione futura dalla tabella Q.
In questo modo l’agente non si limita a sapere che il punto A è buono, ma capisce esattamente che dà A la mossa verso B è meglio di quella verso C, e così adatta passo dopo passo la sua strategia basandosi sui feedback diretti dell’ambiente.
Nel passaggio dalle tabelle Q a funzioni di valore parametrizzate, agli inizi degli anni Dieci l’azienda DeepMind propose il Deep Q-Network (DQN).
Qui l’idea base del Q-learning rimane, ma anziché tenere una tabella Q(s,a) si usa una rete neurale con parametri θ per approssimarla:

dove D il buffer di experience replay che accumula transizioni (s, α, r, s′) e le rende disponibili in modo casuale, per spezzare le correlazioni tra esperienze successive;
θ^- sono i parametri di una rete target, una copia di θ che si aggiorna lentamente (ad esempio ogni 10 000 passi), garantendo stabilità ai bersagli di apprendimento.
L’ottimizzazione avviene con discesa del gradiente:

Parallelamente, i metodi policy gradient rinunciano completamente alle funzioni valore tabellari e ottimizzano direttamente la distribuzione di azioni π(α ∣ s;θ).
Il cuore dell’approccio è il Policy Gradient Theorem, che porta alla stima:

REINFORCE utilizza stime Monte Carlo di Q^π (la somma dei premi futuri a partire da uno stato).
TRPO impone un vincolo di “distanza” (KL divergence) per evitare aggiornamenti troppo drastici.
PPO semplifica TRPO con una funzione obiettivo ritagliata (“clipped surrogate”) che penalizza cambi di policy oltre un fattore 1±ϵ.
I metodi actor-critic combinano i due mondi:
L’actor è la rete che propone azioni π(α ∣ s; θ)
Il critic è una funzione valore V(s; ϕ) o un Q(s, α; ϕ) addestrata con TD o Q-l
L’actor si aggiorna usando il gradiente:
dove r+γV(s′;ϕ)−V(s;ϕ) è una stima del vantaggio (una misura che indica quanto è migliore o peggiore una certa azione rispetto alla media delle azioni disponibili in uno stato) che guida l’esplorazione verso azioni migliori.
Spiegazione con metafora:
Deep Q-Network (DQN) -Immaginate di insegnare a uno studente a risolvere quiz diversi ogni giorno. Lo studente tiene un quaderno dove appunta ogni problema risolto (experience replay). Quando si esercita, pesca a caso quiz vecchi e nuovi per non dimenticare le lezioni passate. Confronta le soluzioni col “manuale di risposte” che aggiorna lentamente (rete target), così da non confondersi con soluzioni che cambiano troppo in fretta. In questo modo lo studente costruisce una competenza solida su tutti i tipi di esercizi, senza fissarsi solo sugli ultimi che ha visto.
Policy Gradient - Pensate a un cuoco che sperimenta nuove ricette. Ogni volta che un piatto riceve degli apprezzamenti, ribilancia la quantità degli ingredienti che piacciono e di quelli meno graditi. Non calcola prima quanti punti vale ogni ingrediente, ma aggiusta la probabilità di usarli sulla base del successo dei piatti serviti fino a quel momento.
Actor-Critic - È come avere un allievo (actor) che propone delle azioni e un insegnante (critic) che, passo dopo passo, valuta quanto l’allievo si è avvicinato all’obiettivo. L’allievo compie un’azione, l’insegnante dà un voto non solo per il risultato immediato ma anche in base a quanto ci si aspetta di ottenere in futuro. L’allievo usa quel giudizio per correggersi subito, migliorando la mossa successiva. Con questa collaborazione, l’agente impara rapidamente sia cosa conviene fare sia quale rendimento aspettarsi.

Simulazioni
Un paradosso dell’apprendimento per rinforzo è l’enorme quantità di errori necessari per imparare. Nessun robot può permettersi milioni di collisioni per imparare a eseguire delle azioni in modo corretto: l’hardware si romperebbe ben prima di riuscire a stare in piedi. Per questo si è imposta la cultura del sim-first. Motori fisici come MuJoCo, Bullet, Isaac Gym o Brax permettono di far vivere al robot milioni di vite parallele su cluster di GPU, condensando anni di esperienza in un weekend.
Questo approccio ha fondamentalmente un rischio principale: sviluppare le capacità del robot in un ambiente troppo perfetto. Il passaggio sim-to-reality tradisce attriti imprecisi, giochi meccanici, riflessi di fotocamere, rumori di inerzia e una moltitudine di altre variabili e imprevisti a cui nessuno avrebbe pensato.
L’antidoto è la domain randomization: complicare il simulatore con frizioni variabili, masse fluttuanti, sensori imprecisi, texture alterate. In sostanza, si insegna all’agente che il mondo può essere leggermente diverso ogni volta. Quello che rimane costante non è il valore esatto di un parametro, ma la strategia per compensarlo. Quando i robot della Boston Dynamics eseguono salti di parkour in una palestra dopo essersi allenato in cloud, non è stato un colpo di fortuna: è il frutto di migliaia di simulazioni volutamente imperfette che li hanno resi a prova di imprevisto.
Oggi la pipeline più usata è tripartita: core simulation (rapida, a bassa fedeltà, per esplorare), simulazione ad alta fedeltà (lenta ma accurata, per rifinire), deployment fisico con fine-tuning online e/o offline. Il ritorno di investimento – in termini di ore-uomo risparmiate e usura hardware evitata – è ormai ampiamente documentato dai dipartimenti di R&D di logistica, aerospazio, automotive. Parliamo di centinaia di milioni di dollari di budget risparmiati grazie alle simulazioni.
Nei grandi magazzini, manipolatori industriali collaborativi di ogni dimensione addestrati con RL, scelgono in tempo reale punti di presa migliori su pacchi irregolari. Nei cantieri navali, droni intelligenti ispezionano saldature interne riconoscendo difetti con sensori multispettrali. In ambienti industriali altamente sensibili, quadrupedi robotici eseguono ispezioni complesse grazie a sensori avanzati e segnalano le irregolarità agli operatori in tempo reale. Nel 2025 oltre il 70% dei 2,26 miliardi di dollari investiti in robotica di servizio è confluito in startup che fondano il proprio vantaggio competitivo su nuove pipeline di RL.
Un altro caso emblematico di questa tecnica può essere intravisto nell’ambito della manipolazione del plasma dei Tokamak: ogni millisecondo un controllore RL regola quattordici bobine magnetiche. Addestrato in simulazione, è in grado di “scolpire” colonne di plasma in forme che ottimizzano la stabilità e riducono il rischio di criticità. È una dimostrazione concreta che l’RL può abbracciare dinamiche fisiche ad alta energia e tempi di risposta estremi.
Non meno rivoluzionario è AlphaDev di Google DeepMind, che nel 2023 ha riscoperto algoritmi di ordinamento più efficienti di quelli scritti a mano dagli ingegneri. Qui la ricompensa è il numero di cicli CPU: l’agente esplora il vasto spazio dei programmi compilabili e riceve premi quando riduce i micro-secondi. È la prova che l’RL non serve solo a muovere arti o pedine, ma può navigare il territorio discreto del codice sorgente, suggerendo che parti intere dell’ingegneria del software diventeranno presto dominii navigabili da agenti autonomi.

Efficienza, esplorazione, sicurezza
Se il fascino del RL sta nell’autonomia, la sua zavorra è l’inefficienza campionaria (sample inefficiency). Ogni esperienza vale oro quando si pilota un drone vero o si dosa un farmaco: non si possono provare migliaia di politiche errate. Per colmare il gap si studiano metodi model-based, in cui l’agente impara una dinamica simulata e vi pianifica sopra, o offline RL, dove si rielaborano log storici senza interagire. Parallelamente si affinano tecniche di meta-learning: insegnare all’agente come imparare, così che una manciata di episodi basti a riadattarsi a un nuovo ambiente.
La seconda spina è la ricompensa sbagliata. Se premiamo un braccio robotico per distribuire rapidamente vernici su una superficie, potremmo ritrovarci con un getto d’inchiostro che imbratta tutto il laboratorio pur di massimizzare il contatore di pixel colorati. L’arte del cosidetto reward shaping richiede sensibilità ingegneristica, ma anche una riflessione etica: il premio è un telescopio dei nostri valori. Tecniche come l’inverse RL (dedurre la ricompensa da esempi umani) o il preference learning (far scegliere agli umani tra due comportamenti) tentano di chiudere il cerchio, ma introducono un altro fragile elemento: il giudizio umano stesso.
Ultima, ma non meno importante, la questione sulla sicurezza. Un agente che apprende comportamenti a 50 hertz su un drone da consegna non può permettersi una fase di “esplorazione creativa” sopra la folla. Da qui lo sviluppo di metodi di safe exploration basati su barriere di controllo classico, funzioni di costo catastrofico, o certificazioni formali che dimostrano l’impossibilità di violare vincoli fisici.
Negli ultimi due anni l’acronimo RL è rimbalzato anche fuori dai circoli degli specialisti grazie al Reinforcement Learning from Human Feedback (RLHF). La grammatica è la stessa: stato (prompt + risposta), azione (token successivo), ricompensa (giudizio umano). Cambia la scala: anziché secondi di volo o pixel Atari, le ricompense sono milioni di micro-valutazioni sul gradimento linguistico. Quel flusso ha reso i grandi modelli generativi più allineati alle preferenze sociali, ma ha anche mostrato che l’apprendimento per rinforzo può fungere da strato di rifinitura universale, capace di adattare delle reti neurali già enormi.
Il prossimo passo intravisto nei laboratori è fermare la distinzione: unire **world models** predittivi (alla maniera di MuZero) con modelli linguistici generalisti, così che un agente ragioni sul testo, immagini il risultato di un’azione come in una “simulazione mentale” e scelga la frase o il gesto da compiere. È qui che la convergenza tra RL e Deep Learning promette di generare quella forma di intelligenza generale di cui tanto si discute.

Conclusioni non banali
Guardando al futuro prossimo si delineano tre direttrici. La prima è la gerarchia: insegnare agli agenti a spezzare problemi in sotto-task, definire sub-goal, riutilizzare abilità come moduli richiamabili. È l’unico modo per scalare a scenari complessi senza ricominciare da zero. La seconda è il multi-agent RL: quando ogni veicolo autonomo negozia con i veicoli vicini non basta ottimizzare la propria ricompensa, occorre coordinare rendimenti di gruppo in ambienti non stazionari. La terza è la sostenibilità computazionale: poiché l’addestramento di modelli su larga scala richiede ormai gigawatt-ora di energia, emergono tecniche come la mixed precision - che alterna calcoli in bassa precisione (16 bit), velocissimi e a basso consumo, con operazioni in alta precisione (32 bit) riservate alle fasi critiche per mantenere la stabilità numerica - insieme al parameter sharing (condivisione controllata di pesi tra più parti della rete per ridurne la dimensione) e all’hardware-aware training (ottimizzazione dei calcoli in funzione delle caratteristiche specifiche di GPU o TPU), tutte strategie finalizzate a ridurre significativamente l’impronta energetica.
L’obiettivo finale è trasformare l’apprendimento per rinforzo da disciplina di nicchia a tessuto connettivo dell’automazione: un livello di controllo che apprende, si adatta, ma resta interpretabile e governabile. Il successo non verrà misurato da un’altra vittoria contro il campione del mondo di un gioco da tavolo, ma dalla capacità di orchestrare infrastrutture tangibili, come reti elettriche, flotte di robot, processi fisici e chimici complessi, con efficienza e affidabilità superiore a qualunque schema rigido programmato manualmente come si faceva fino a pochi anni fa.
Parlare di apprendimento per rinforzo significa indagare il confine tra tentativo ed errore e pianificazione razionale. È un metodo che insegna alle macchine la pazienza di sacrificare il guadagno immediato per una ricompensa più elevata nel tempo, e che obbliga i progettisti a esplicitare quali ricompense meritino di essere perseguite. Ogni volta che una reward function viene disegnata, si rivela una parte dei valori umani.
Nel 1998 Chris Watkins e Peter Dayan introdussero il Taxi Domain: un semplice simulatore in cui un agente, guidando un taxi giallo, doveva raccogliere un passeggero e portarlo a destinazione imparando unicamente per tentativi ed errori grazie al Q-learning. Oggi gli algoritmi nati da quell’idea trovano impiego in ambiti molto diversi. Nel 2021 DeepMind e il Politecnico di Losanna hanno addestrato un controllore RL a regolare i campi magnetici di un tokamak, stabilizzando plasma a oltre 100 milioni di gradi; nel 2023 AlphaDev di Google ha scoperto nuove routine di ordinamento in C++ più veloci di quelle umane, ora integrate nel compilatore LLVM; infine, progetti di robotica come Amazon Prime Air usano RL per istruire droni capaci di consegnare pacchi in vicoli stretti, adattandosi in tempo reale alle raffiche di vento. Ciò che unisce questi traguardi è l’esplorazione guidata dalla ricompensa: ogni sistema sperimenta azioni, riceve un feedback numerico e costruisce autonomamente una strategia per massimizzare il risultato complessivo
Se in questo articolo ho potuto soltanto iniziare il viaggio in questa disciplina, spero di aver fornito la bussola concettuale per proseguire: la prossima ricompensa, dopotutto, spetta a chi continua a esplorare.
Avvenimenti del mese
Le notizie più interessanti, importanti o creative dal mondo della tecnologia, accuratamente selezionate per districarsi tra il rumore informativo.

Miniaturizzare il ragionamento
Il 1° maggio Microsoft Research lancia Phi-4-reasoning, un modello di ragionamento da 14 miliardi di parametri che riesce a tener testa a DeepSeek R1.
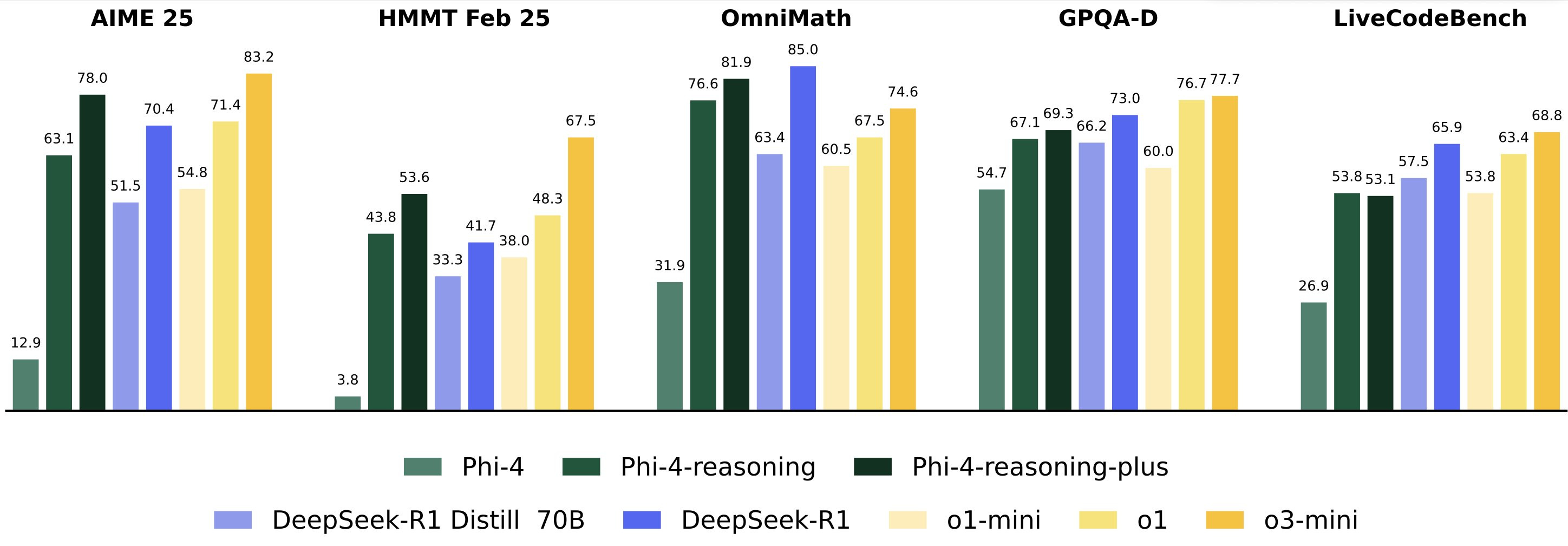
Contestualmente viene annunciata anche la variante Phi-4-reasoning-plus, che integra un breve ciclo di reinforcement learning per generare tracce di ragionamento ancora più lunghe e dettagliate.
Phi-4-reasoning nasce da un processo di supervised fine-tuning su Phi-4, utilizzando oltre 1,4 milioni di prompt selezionati per coprire diversi livelli di difficoltà e ambiti di conoscenza. Le dimostrazioni di ragionamento, generate tramite o3-mini, offrono al modello esempi con catene di inferenza complesse, in grado di sfruttare al meglio la potenza di calcolo durante la fase di inferenza. Phi-4-reasoning-plus aggiunge a questo un breve training di reinforcement learning su circa 6.000 problemi matematici con soluzioni verificabili, ottenendo un aumento significativo delle prestazioni.
Su una vasta gamma di benchmark, Phi-4-reasoning e Phi-4-reasoning-plus superano modelli open-weight molto più grandi come DeepSeek-R1-Distill-Llama-70B e si avvicinano ai risultati di DeepSeek-R1 (671 miliardi di parametri). Le valutazioni comprendono test di ragionamento matematico (HMMT, AIME 2025, OmniMath), scientifico (GPQA) e di coding (LiveCodeBench), oltre a compiti di problem solving algoritmico (3SAT, TSP) e di pianificazione (BA-Calendar).
L’impatto su task non strettamente matematici è altrettanto rilevante: Phi-4-reasoning-plus migliora di 22 punti percentuali l’accuratezza nell’Instruction Following (IFEval), di 16 punti in question answering a lungo contesto (FlenQA) e di 10 punti in ArenaHard, che valuta interazioni di tipo chat basate sulle preferenze umane. Anche la capacità di rilevare linguaggio tossico (Toxigen) registra un lieve ma significativo incremento, con una distribuzione più bilanciata fra contenuti neutrali e tossici, utile per applicazioni di moderazione.
Una caratteristica distintiva di questi modelli è l’equilibrio fra sforzo computazionale e accuratezza: rispetto a Phi-4-reasoning, la versione plus utilizza mediamente 1,5× token in più, soprattutto in ambito matematico, a fronte di miglioramenti di prestazioni particolarmente marcati. Questi risultati evidenziano come la tecnica del parallel test-time compute possa avvicinare ulteriormente i modelli a un’accuratezza massima sui benchmark. Allo stesso tempo, emergono opportunità di ricerca per ottimizzare i metodi di training e decoding, in particolare in domini come biologia e chimica, dove i miglioramenti risultano meno pronunciati.
Il 19 maggio viene presentato NLWeb, un progetto open source pensato per semplificare la creazione di interfacce in linguaggio naturale direttamente sui siti web, trasformandoli in applicazioni AI capaci di rispondere come un assistente.

NLWeb, abbreviazione di Natural Language Web, è progettato per offrire agli sviluppatori un modo rapido e flessibile per integrare interfacce conversazionali nei propri siti, sfruttando il modello di linguaggio di loro scelta e i dati proprietari del sito stesso. Ogni istanza di NLWeb funge inoltre da server conforme al Model Context Protocol (MCP), rendendo il contenuto del sito sia fruibile tramite linguaggio naturale dagli utenti che accessibile ad altri agenti nell’ecosistema MCP, in modo analogo a quanto HTML ha fatto per il web tradizionale.
Il sistema si basa su formati semi-strutturati già ampiamente utilizzati dai siti web, come Schema.org e RSS, che NLWeb combina con strumenti potenziati da LLM per generare interfacce conversazionali. Grazie all’integrazione di conoscenze esterne fornite dai modelli sottostanti (per esempio, approfondimenti geografici per query relative a ristoranti), l’esperienza utente risulta più ricca e contestualizzata. Essendo un progetto tecnologicamente agnostico, NLWeb supporta tutti i principali sistemi operativi, modelli di linguaggio e database vettoriali, lasciando agli sviluppatori la libertà di scegliere le componenti più adatte alle proprie esigenze.
L’obiettivo di Microsoft è portare direttamente sui siti web i vantaggi dell’intelligenza artificiale che hanno già rivoluzionato la ricerca online. Così come HTML ha democratizzato la creazione di pagine web, NLWeb punta a rendere accessibile a tutti la possibilità di offrire un’esperienza intelligente e conversazionale, permettendo agli utenti di porre domande in linguaggio naturale sui contenuti del sito e di ricevere risposte pertinenti. Man mano che il concetto di Agentic Web si espande, NLWeb consentirà ai publisher di partecipare attivamente, assicurandosi che il loro sito sia pronto a interagire, svolgere transazioni e farsi scoprire da altri agenti.
Tra i primi siti che hanno adottato NLWeb in fase di test ci sono nomi come Chicago Public Media, Common Sense Media, Allrecipes/Serious Eats, Eventbrite, Hearst (Delish), Inception Labs, Milvus, O’Reilly Media, Qdrant, Shopify, Snowflake e Tripadvisor. Questi collaboratori iniziali hanno permesso di affinare l’approccio di Microsoft e di garantire che NLWeb risponda alle esigenze dei publisher moderni.
Integrarsi con ogni cosa
Sempre il 1° maggio, Anthropic annuncia il lancio di Integrations, una nuova funzionalità che consente di collegare le proprie applicazioni e strumenti a Claude. Contestualmente, viene potenziata la modalità avanzata di Research, che ora può ricercare sul web, in Google Workspace e, grazie alle integrazioni, anche all’interno delle applicazioni collegate, offrendo report completi fino a 45 minuti di durata, corredati da citazioni precise.
Lo scorso novembre era stato introdotto il Model Context Protocol (MCP), uno standard aperto per connettere le app di intelligenza artificiale a strumenti e dati. Il supporto a MCP era inizialmente limitato a Claude Desktop tramite server locali, ma con Integrations l’azienda apre la strada a server MCP remoti: gli sviluppatori possono creare e ospitare server che ampliano le capacità di Claude, mentre gli utenti possono scoprire e collegare liberamente queste integrazioni.
Ad oggi sono disponibili integrazioni con dieci servizi molto popolari: Atlassian Jira e Confluence, Zapier, Cloudflare, Intercom, Asana, Square, Sentry, PayPal, Linear e Plaid. In futuro si aggiungeranno anche partner come Stripe, GitLab e Box. Collegando uno di questi strumenti, Claude acquisisce contesto approfondito sul lavoro svolto come cronologia dei progetti, stato delle attività e conoscenze organizzative, e può compiere azioni direttamente in questi ambienti, diventando un collaboratore migliore capace di eseguire progetti complessi in un unico ambiente.
Ad esempio, l’integrazione con Zapier permette di connettere migliaia di app tramite workflow predefiniti: tramite conversazione, Claude può accedere ai dati di vendita in HubSpot e preparare automaticamente report di meeting basati sul calendario. Con Atlassian, è invece possibile chiedere a Claude di sintetizzare e creare pagine Confluence o elementi Jira, accelerando la gestione dei progetti. L’integrazione con Intercom consente di rispondere rapidamente al feedback degli utenti, sfruttando l’agente AI di Intercom per segnalare bug in Linear, esplorare schemi di conversazione e gestire l’intero flusso di lavoro dalla segnalazione alla risoluzione.
La modalità avanzata di Research, attivabile tramite l’apposito pulsante, suddivide le richieste in sotto-processi di indagine, esplorando a fondo centinaia di fonti interne ed esterne per poi unire tutto in un report esaustivo. La maggior parte dei report si conclude entro 5–15 minuti, ma i più complessi possono richiedere fino a 45 minuti, permettendo di risparmiare ore di ricerche manuali. Ogni informazione è accompagnata da citazioni che rimandano alla fonte originale.
Il 22 maggio Anthropic lancia anche Claude 4, la sua nuova generazione di LLM attualmente composta da Claude Opus 4 e Claude Sonnet 4.

Claude Opus 4 sembra essere il miglior modello al mondo per il coding, con prestazioni sostenute su task complessi e workflow agentici di lunga durata: Ottiene il 72,5% su SWE-bench Verified e il 43,2% su Terminal-bench, dimostrando capacità di lavorare ininterrottamente per diverse ore senza degradazione del rendimento.
Claude Sonnet 4 rappresenta un significativo upgrade rispetto a Sonnet 3.7, bilanciando potenza e efficienza per casi d’uso quotidiani: raggiunge il 72,7% su SWE-bench, migliora la precisione nel seguire le istruzioni e risulta ideale per scenari agentici e automazione della scrittura di codice.
Entrambi i modelli introducono “extended thinking with tool use”, che alterna fasi di ragionamento a chiamate verso tool esterni come la ricerca web; supportano l’esecuzione parallela di strumenti e mostrano avanzate capacità di memorizzazione, salvando e richiamando automaticamente informazioni chiave da file locali per mantenere continuità nelle conversazioni e nei progetti.
Insieme al grande annuncio viene reso generalmente disponibile a tutti Claude Code, estendendo l’integrazione con GitHub Actions e offrendo estensioni beta per VS Code e JetBrains: le modifiche proposte da Claude appaiono direttamente nei file, semplificando il pair programming e la revisione dei pull request.
Sull’API di Anthropic debuttano quattro nuove funzionalità per sviluppatori: code execution tool, connettore MCP, Files API e il caching dei prompt fino a un’ora, potenziando la costruzione di agenti AI più rapidi e affidabili.
Opus 4 ha un costo di $15/75 per milione di token (input/output), mentre Sonnet 4 costa $3/15 per milione di token.
Il 27 maggio viene poi annunciato il supporto per la modalità vocale su Claude app.
Ora la musica fatta con IA può essere migliore di quella fatta da soli umani
Sempre il 1° maggio, Suno lancia la versione 4.5 del suo modello per la musica, progettato per rendere le creazioni degli utenti ancor più espressive e ricche.

Suno v4.5 introduce un’ampia espansione dei generi musicali riconosciuti e riprodotti accuratamente: ora è possibile richiedere stili come “punk rock”, “jazz house” o “gregoriano” con un realismo senza precedenti. Le combinazioni di generi, ad esempio midwest emo e neosoul o EDM e folk, risultano completamente coese e creative, permettendo all’utente di sperimentare ibridazioni inedite senza perdere coerenza stilistica. Offre anche voci migliori, caratterizzate da una gamma più ampia e una profondità emotiva più accentuata. Anche l’elaborazione dei suoni è più complessa: sfumature tonali naturali, stratificazioni strumentali e dettagli sonori raffinati contribuiscono a un mix più ricco, rispondendo a richieste descrittive come “toni nostalgici e avvolgenti” o “fischiettio melodico” con una fedeltà sorprendente.
La comprensione delle istruzioni testuali è stata ulteriormente migliorata: v4.5 interpreta con maggiore accuratezza le descrizioni, cogliendo dettagli, atmosfere e strumenti specificati dall’utente. Per facilitare la creazione di prompt dettagliati, viene introdotto il “prompt enhancement helper”, uno strumento che trasforma in automatico le idee degli utenti in istruzioni stilistiche articolate.
Le funzionalità Cover e Personas subiscono un potenziamento significativo: le cover mantengono dettagli melodici più precisi e l’adattamento di un brano da un genere all’altro, ad esempio da rock a house, risulta più fluido e credibile. La possibilità di combinare contemporaneamente Covers e Personas apre a nuove potenzialità creative, mescolando voce, stile e struttura in un unico workflow.
La versione 4.5 migliora anche la velocità di generazione, consentendo iterazioni più rapide e lasciando più tempo alla sperimentazione; estende la durata massima dei brani fino a 8 minuti, garantendo coerenza e qualità anche in composizioni lunghe, perfeziona la resa audio con mix più equilibrati, riduce la degradazione e attenua gli effetti di “shimmer” per una qualità sonora costante dall’inizio alla fine.
Il nuovo mostro del coding
Il 6 maggio Google rilascia la versione Preview di Gemini 2.5 Pro (edizione I/O), un aggiornamento di Gemini 2.5 Pro che introduce capacità potenziate per il coding.
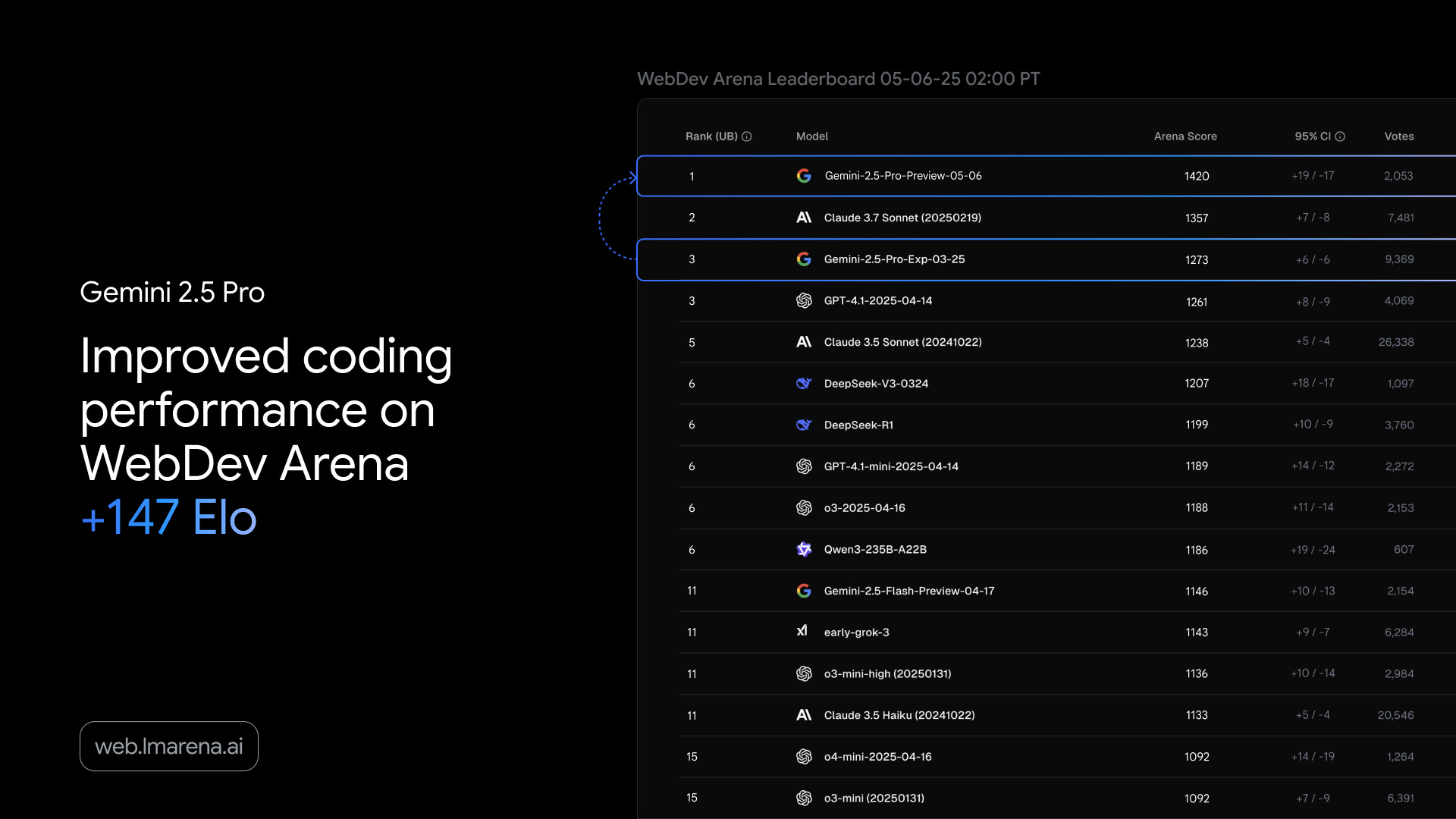
L’uscita di questo modello era originariamente prevista per l’evento Google I/O, ma è stata anticipata per soddisfare l’elevato entusiasmo della community di sviluppatori per Gemini 2.5 Pro. L’aggiornamento si basa sul feedback estremamente positivo ricevuto per le capacità di coding e di ragionamento multimodale del modello.
Il nuovo Gemini 2.5 Pro supera sé stesso nella classifica WebDev Arena, guadagnando 147 punti Elo in più rispetto alla versione precedente, indicatore della preferenza degli utenti per la capacità di generare web app esteticamente gradevoli e funzionali.
Il 14 maggio viene annunciato AlphaEvolve, un agente per il coding progettato per scoprire e ottimizzare algoritmi avanzati con un approccio che combina la creatività dei grandi modelli linguistici (LLM) con dei valutatori automatizzati.
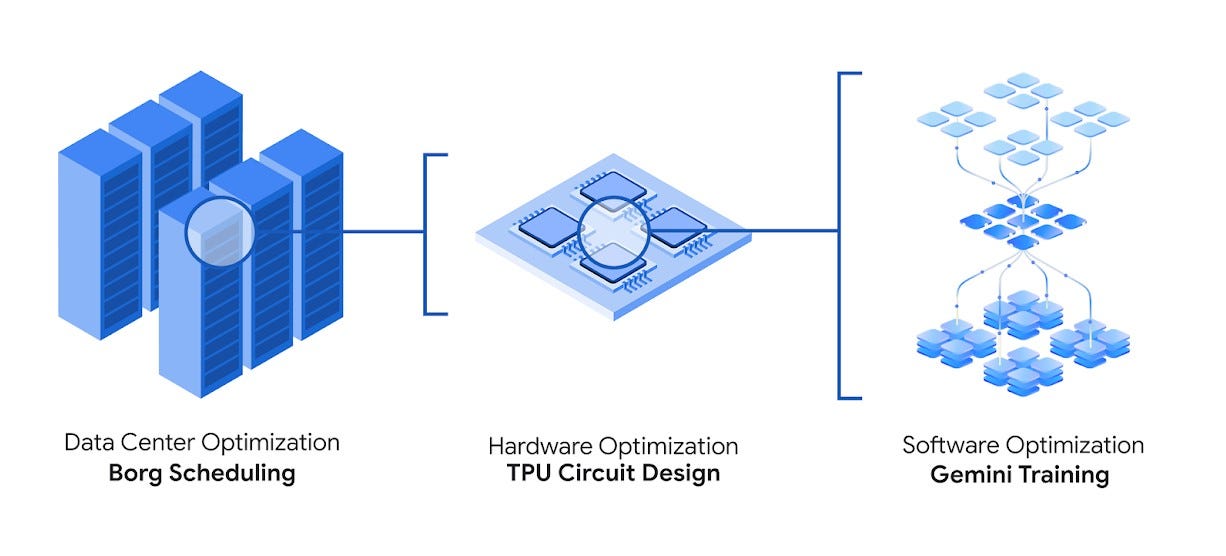
AlphaEvolve sfrutta un ensemble di modelli Gemini – con Gemini Flash per esplorare un’ampia gamma di idee e Gemini Pro per approfondire le soluzioni più promettenti, generando programmi che implementano possibili algoritmi.
Questi programmi vengono poi verificati, eseguiti e classificati tramite metriche oggettive di accuratezza e qualità, per poi essere immagazzinati in un database che applica un algoritmo evolutivo per selezionare le varianti migliori da utilizzare nei cicli successivi di generazione.
Nel corso dell’ultimo anno, AlphaEvolve ha migliorato la pianificazione dei data center di Google: la soluzione messa in produzione recupera in media lo 0,7% delle risorse computazionali mondiali, aumentando l’efficienza senza impattare l’affidabilità. In ambito hardware, l’agente ha proposto una riscrittura in Verilog di un circuito aritmetico ottimizzato per la moltiplicazione di matrici, eliminando bit superflui e superando i controlli di verifica funzionale; questa innovazione è già integrata nei prossimi Tensor Processing Unit (TPU) di Google.
Per l’addestramento e l’inferenza dei modelli AI, AlphaEvolve ha ripartito le operazioni di moltiplicazione matriciale in subproblemi più gestibili, accelerando un kernel chiave di Gemini del 23% e riducendo l’1% del tempo di training, oltre a ottimizzare le istruzioni GPU di FlashAttention con un miglioramento fino al 32,5%.
L’agente ha anche evoluto procedure di ottimizzazione basate su gradienti per scoprire nuovi algoritmi di moltiplicazione 4×4 che superano l’algoritmo di Strassen del 1969 e ha portato avanti problemi aperti come il “kissing number” in 11 dimensioni, fissando un nuovo limite inferiore con 593 sfere esterne.
DeepMind sta collaborando con il team People + AI Research per sviluppare un’interfaccia user-friendly e lancerà un programma Early Access per utenti accademici selezionati; nel mirino ci sono applicazioni in scienze dei materiali, scoperta di farmaci, sostenibilità e molti altri ambiti dove soluzioni algoritmiche verificabili potrebbero fare la differenza.
Dal 20 al 21 maggio si è tenuta la conferenza annuale Google I/O, durante la quale sono state presentate decine di novità incredibili, così tante da non poterle citare tutte in questa rubrica dedicata alle news del mese. Di seguito trovare quindi una selezione tratta da questo articolo che sintetizza 100 annunci avvenuti nelle due giornate di I/O.

Viene introdotta l’AI Mode di Search, una modalità che consente di porre domande in linguaggio naturale e ricevere risposte approfondite e contestualizzate direttamente nei risultati di ricerca grazie a Gemini. La funzionalità è già in fase di rollout sperimentale negli Stati Uniti.
Sempre per Search, Google ha presentato Deep Search, uno strumento avanzato disponibile in Labs che integra capacità di ricerca approfondita. Questo strumento permette di esplorare risposte più esaustive, combinando fonti esterne con modelli per rispondere a quesiti più complessi.
Sempre nel contesto della ricerca sono state illustrate le funzionalità in arrivo da Project Astra, che porteranno la tecnologia Search Live nell’AI mode: sarà possibile interagire in tempo reale con la ricerca utilizzando la fotocamera, consentendo conversazioni visive con i risultati e una comprensione più immediata di ciò che si sta guardando.
Insieme ad Astra, Google ha annunciato l’integrazione di capacità agentiche da Project Mariner: già pianificate per eventi come l’acquisto di biglietti, prenotazioni di ristoranti e appuntamenti locali, queste funzionalità abiliteranno un’esperienza più “assistita” durante la navigazione, dove il sistema potrà agire al posto dell’utente per completare operazioni quotidiane.
Per chi ha la necessità di analizzare dati complessi o visualizzare informazioni statistiche, AI Mode includerà nuove funzionalità in grado di analizzare dataset e creare grafici dinamici su misura per le query. Questa novità è pensata prima di tutto per gli ambiti sportivi e finanziari, offrendo visualizzazioni personalizzate che semplificano la comprensione di numeri e tendenze.
Nel settore dell’e-commerce, Google ha introdotto una esperienza di shopping in AI Mode che combina capacità avanzate AI con il suo Shopping Graph, permettendo agli utenti di trovare ispirazione, valutare opzioni e scoprire prodotti in base a suggerimenti intelligenti, con una navigazione più interattiva e personalizzata.
Un’altra innovazione per il commercio online è l’esperimento di virtual try-on, che consente di provare virtualmente infiniti capi di abbigliamento semplicemente caricando una foto di sé stessi. Questa funzione, già disponibile per gli utenti di Search Labs negli Stati Uniti, sfrutta modelli generativi per adattare i vestiti all’immagine dell’utente, offrendo un’esperienza di test completamente digitale.
Google ha mostrato anche un nuovo checkout agentico che aiuta a gestire i budget e le offerte: basta toccare “traccia il prezzo” su un prodotto, impostare la cifra desiderata e il sistema notificherà automaticamente quando il prezzo scende al livello indicato, facilitando gli acquisti al miglior costo possibile.
Passando all’app Gemini, è stata introdotta una nuova funzionalità di quiz interattivi: basta chiedere a Gemini “crea un quiz di pratica su…” e il modello genererà automaticamente domande a risposta multipla, vero/falso e domande aperte, utili per studenti, docenti o chiunque desideri testare le proprie conoscenze su un argomento.
Gemini Live diventerà ancora più personale grazie all’integrazione con alcune app Google: gli utenti potranno svolgere azioni durante la conversazione, come aggiungere eventi al calendario, ottenere indicazioni da Google Maps, creare attività in Tasks o salvare note in Keep, rendendo l’assistente in grado di eseguire compiti reali senza uscire dalla chat.
Per lo strumento Canvas è stato introdotto un nuovo menu Create, che aiuta l’utente a esplorare il potenziale creativo di questa piattaforma: grazie a delle opzioni è possibile trasformare testi in infografiche interattive, pagine web, quiz immersivi o persino audio-overview in 45 lingue, offrendo una suite di strumenti per la produzione di contenuti intelligenti.
In Deep Research di Gemini, si può già caricare PDF e immagini per integrare i propri documenti nelle analisi: i risultati delle ricerche non si baseranno più solo su dati pubblici, ma includeranno anche informazioni specifiche fornite dall’utente, facilitando la creazione di report personalizzati e approfonditi.
Sarà anche possibile collegare documenti da Drive o Gmail a Deep Research, selezionando le fonti da cui attingere: ciò significa che, oltre ai PDF e alle immagini, l’assistente potrà leggere direttamente mail e file archiviati in Drive, offrendo una ricerca contestualizzata e tailor-made su dossier aziendali, progetti in corso o riferimenti accademici.
È stata presentata anche l’Agent Mode, una funzionalità sperimentale in cui l’utente potrà semplicemente descrivere un obiettivo (ad esempio “organizza una cena per otto persone") e Gemini si occuperà di trovare i ristoranti, effettuare le prenotazioni e inviare le conferme, il tutto in autonomia. Agent Mode arriverà a breve per gli abbonati a Google AI Ultra, il nuovo piano da $250 al mese.
Imagen 4 è l’ultima evoluzione del generatore di immagini di Google: rispetto alla versione precedente promette una qualità notevolmente migliorata, con colori più ricchi e dettagli ancora più raffinati, capace di spaziare dal fotorealistico all’illustrazione astratta. Un aspetto particolarmente rilevante è la capacità di generare testi leggibili e stilizzati all’interno delle immagini, risolvendo un tipico problema che affligge molti modelli per la generazione di immagini. Queste caratteristiche rendono Imagen 4 ideale per la realizzazione di poster, mappe, fumetti e contenuti editoriali in cui la corretta resa delle parole è fondamentale.
Veo 3 rappresenta invece un nuovo passo avanti nel campo della generazione video: a differenza di Veo 2, non si limita più a produrre brevi clip visuali, ma integra anche la generazione di suono, dall’audio di sottofondo agli effetti ambientali fino a dialoghi sincronizzati, per offrire clip più complete e immersive.
Per concludere, Flow è la nuova piattaforma progettata per mettere insieme le potenzialità di Veo 3, Imagen 4 e Gemini in un unico ambiente di lavoro. Con Flow è possibile creare video cinematografici descrivendo semplicemente scene, personaggi o stili in linguaggio naturale: il sistema genera automaticamente le clip video, le organizza in sequenze coerenti e permette di effettuare transizioni fluide tra le inquadrature. Flow offre strumenti come il “scene builder” per estendere l’azione senza interruzioni, passare da un’inquadratura all’altra mantenendo il contesto visivo precedente e gestire personaggi, oggetti e ambientazioni utilizzando gli stessi modelli di Imagen per creare altre scene. Tutto il flusso creativo, dalla generazione dei singoli frame alla creazione della narrazione, avviene in un unico ambiente centralizzato che semplifica il processo di produzione rispetto a tool tradizionali.
Il tocco di Amazon
Il 7 maggio Amazon presenta Vulcan, un robot dotato di senso del tatto, pensato per rendere il lavoro dei dipendenti nei centri di smistamento più sicuro ed efficiente

Vulcan integra sensori di forza e un “end of arm tooling” che funziona come un righello montato su una piastra riscaldante: le “alette” trattengono gli oggetti, mentre sensori tattili misurano la pressione esercitata, evitando danni durante le operazioni di stoccaggio. Per il prelievo degli oggetti, il robot utilizza un braccio equipaggiato con telecamera e una ventosa: la videocamera individua l’articolo e il punto di presa ottimale, mentre la ventosa afferra solo l’oggetto target, prevenendo il rischio di estrarre articoli non desiderati. Con questa tecnologia, Vulcan è in grado di gestire circa il 75% degli articoli presenti nei pod di stoccaggio, operando a velocità comparabili a quelle dei lavoratori umani.
Oltre a incrementare produttività e precisione, Vulcan migliora ergonomia e sicurezza: si occupa delle operazioni nelle file alte e basse dei pod (fino a 8 piedi dal suolo), riducendo l’uso di scale da parte degli operatori e permettendo loro di restare nella “power zone” più comoda e sicura. Amazon prevede di distribuire i sistemi Vulcan nei prossimi anni in Europa e Stati Uniti, con l’obiettivo di potenziare ulteriormente l’efficienza operativa, salvaguardare la salute dei dipendenti e ampliare le possibilità di collaborazione tra tecnologia e forza lavoro umana.
Il gatto aziendale
Sempre il 7 maggio, Mistral AI presenta Le Chat Enterprise, una piattaforma progettata per risolvere alcune delle problematiche affrontate da molte aziende.

Le Chat Enterprise cerca di affrontare la frammentazione degli strumenti, l’integrazione delle conoscenze aziendali, la rigidità dei modelli e i tempi di ritorno sull’investimento troppo lunghi. La nuova offerta si basa sugli strumenti di produttività di Le Chat e introduce un nuovo piano che include:
Enterprise search
Agent builders
Connettori personalizzati per dati e strumenti
Librerie di documenti
Modelli custom
Deployments ibridi
Con Enterprise search, Le Chat si connette in modo sicuro a Google Drive, SharePoint, OneDrive, Calendar e Gmail (e prossimamente ad altri sistemi tramite MCP), organizzando fonti esterne in knowledge base complete e offrendo anteprime rapide con auto-summary per estrarre e citare informazioni critiche. I builder di agent consentono di automatizzare task ripetitivi creando assistenti AI su misura, senza bisogno di codice, collegati alle app e alle librerie aziendali.
La soluzione può essere distribuita ovunque: on-premise, in cloud privato o come servizio Mistral, garantendo connessioni dati privacy-first con rigorosi controlli ACL e massima indipendenza dall’infrastruttura.
Anche la configurabilità è molto completa: personalizzazione degli assistenti tramite memorie salvate, feedback loop per l’auto-miglioramento dei modelli e audit logging estensivo per un controllo totale all’interno del dominio di sicurezza aziendale.
Lo stesso giorno viene annunciato anche Mistral Medium 3, un nuovo modello che bilancia prestazioni allo stato dell’arte, costi significativamente ridotti e semplicità di deployment per le imprese, raggiungendo anche ottimi risultati nei benchmark.
Mistral Medium 3 è progettato per eccellere in contesti aziendali, con performance di alto livello soprattutto nei task di coding e STEM, avvicinandosi ai competitor di taglia maggiore ma con tempi di risposta drasticamente ridotti.
Il modello supporta anche un percorso completo di customizzazione enterprise: pretraining continuo, fine-tuning approfondito e integrazione nei knowledge base aziendali grazie alle Applied AI Solutions di Mistral. Diverse aziende beta tester nei settori finanziario, energetico e sanitario lo utilizzano già per ottimizzare il servizio clienti, personalizzare processi e analizzare dataset complessi.
Il 21 maggio Mistral presenta Devstral, il primo modello open source orientato ad agenti per attività di sviluppo software. Frutto di una collaborazione con All Hands, Devstral vanta prestazioni di superiori rispetto ad altri modelli open source nel benchmark SWE-Bench Verified e viene distribuito con licenza Apache 2.0.

Devstral è addestrato su problemi reali estratti da issue di GitHub e integrato in workflow agentici come OpenHands e SWE-Agent. Sui 500 casi di test del benchmark SWE-Bench Verified, Devstral raggiunge un punteggio del 46,8 %, distanziando di oltre 6 punti percentuali i precedenti modelli open source più avanzati. Nelle stesse condizioni di test fornite da All Hands, il nuovo modello supera anche contendenti di dimensioni maggiori, come Deepseek-V3-0324 (671 miliardi di parametri) e Qwen3 232B-A22B.
La leggerezza di Devstral ne permette l’esecuzione su una singola GPU NVIDIA RTX 4090 o su un Mac con 32 GB di RAM, rendendolo ideale per deployment locali e su dispositivi edge. Piattaforme di coding come OpenHands consentono al modello di interagire direttamente con codebase locali, accelerando la risoluzione di problemi in tempo reale. Le sue prestazioni lo rendono ottimo anche per ambienti enterprise che gestiscono repository sensibili dal punto di vista della privacy, dove servono requisiti stringenti di sicurezza e conformità.
Devstral è reso disponibile gratuitamente per la community con licenza Apache 2.0, incoraggiando sviluppatori e aziende a costruire, personalizzare e potenziare flussi di sviluppo software autonomo. È possibile provarlo tramite API sotto il nome “devstral-small-2505” ai medesimi prezzi di Mistral Small 3.1 (0,10 $ per milione di token in input e 0,30 $ per milione di token in output). Chi preferisce l’auto-deployment può scaricare il modello da Huggingface, Ollama, Kaggle, Unsloth e LMP Studio.
Nuovi world model
Il 10 maggio Enigma Labs presenta Multiverse, un avanzamento significativo nel campo dei world model generativi, volto a colmare la lacuna della gestione di più agenti autonomi in simultanea all’interno di uno stesso ambiente virtuale.

Con un approccio di first-principles thinking, il team ha rivoluzionato l’architettura tradizionale dei world model: invece di progettare un modello per singolo agente, ha smontato la struttura originaria, riorganizzato gli input e gli output e introdotto meccanismi per sincronizzare più flussi informativi. Questo ha permesso di creare un ambiente condiviso in cui più entità possono interagire, apprendere e competere contemporaneamente, superando le limitazioni dei modelli precedenti.
Multiverse è ora disponibile come progetto open source: nel repository vengono forniti codice, pesi, dataset e tutta la documentazione necessaria per replicare e sperimentare il modello. Ricercatori e sviluppatori possono esplorare nuove modalità di cooperazione e competizione tra agenti AI, adattando il framework a diversi scenari, dal gaming alla simulazione in ambito industriale e accademico.
Multiverse apre la strada a numerose applicazioni: dalla creazione di giochi completamente generati dall’IA in cui più giocatori possono sfidarsi su tracciati e ambienti dinamici, fino alla simulazione di sistemi multi-agente per lo studio di fenomeni emergenti e strategie collaborative.
Il 12 maggio OpenAI rilascia HealthBench, un nuovo benchmark pensato per misurare in modo più accurato le capacità dei sistemi AI nel contesto sanitario.
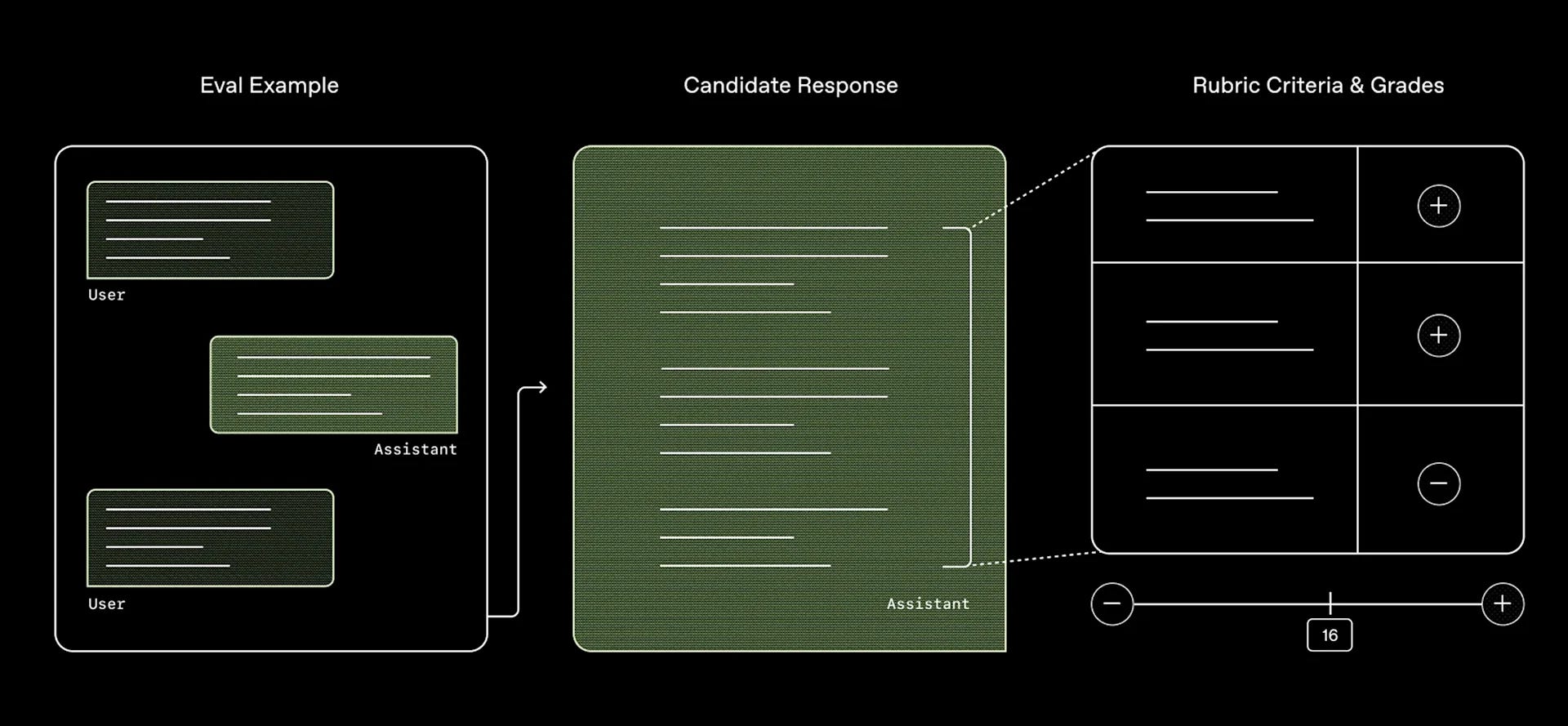
Progettato in collaborazione con 262 medici provenienti da 60 paesi, HealthBench include 5.000 conversazioni realistiche tra modelli AI e utenti o professionisti sanitari, ognuna dotata di una specifica “rubrica” creata da esperti per valutare le risposte fornite dai modelli. HealthBench si basa su tre principi fondamentali:
Significatività: i punteggi devono riflettere l’impatto reale, andando oltre le classiche domande a risposta chiusa per riprodurre scenari complessi e flussi di lavoro simili a quelli che si verificano tra individui e operatori sanitari.
Affidabilità: le valutazioni devono corrispondere al giudizio dei medici, garantendo che ogni criterio valutativo rifletta standard del mondo clinico.
Non saturazione: il benchmark deve offrire margini di miglioramento per i modelli attuali, in modo da incoraggiare gli sviluppatori a continuare a perfezionare le proprie soluzioni.
Il dataset di HealthBench è composto da colloqui multi-turno, multilingue e selezionati in base a diversi gradi di difficoltà. Le conversazioni coprono un ampio spettro di specialità mediche e contesti, includendo sia pazienti “non esperti” sia operatori sanitari. Ogni risposta prodotta da un modello viene esaminata tramite una rubrica che definisce criteri precisi (ad esempio, fatti specifici da includere o errori da evitare); complessivamente, sono presenti 48.562 criteri unici, ognuno associato a un punteggio ponderato secondo l’importanza attribuita dai medici. La valutazione finale di ogni risposta è calcolata confrontando il totale dei criteri soddisfatti con il punteggio massimo possibile.
Poco dopo, il 14 maggio, GPT-4.1 viene inserito all’interno di ChatGPT.
Il 16 maggio viene lanciato Codex, un agente di ingegneria del software basato su cloud che può gestire contemporaneamente molteplici attività legate al codice.
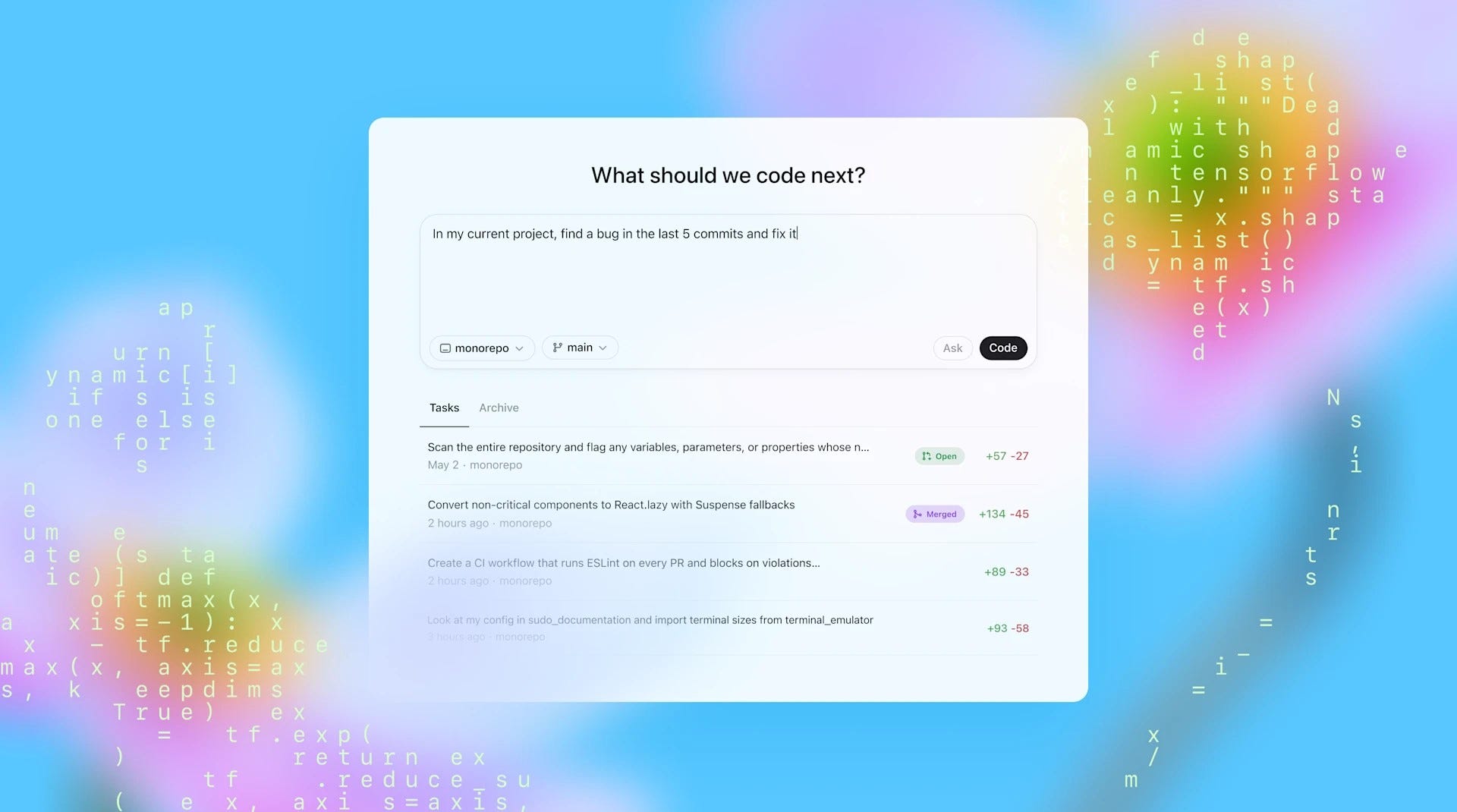
Codex, alimentato da codex-1 (una variante di OpenAI o3 ottimizzata per il coding), è disponibile fin da subito per gli utenti ChatGPT Pro, Team ed Enterprise, con un’estensione del supporto agli utenti Plus ed Edu prevista per i prossimi mesi.
Codex funziona all’interno di ambienti isolati nel cloud, ognuno preconfigurato con il repository dell’utente. Attraverso la sidebar di ChatGPT, è possibile assegnargli compiti come scrivere nuove funzionalità, rispondere a quesiti sulla propria codebase, correggere bug o proporre pull request per la revisione. Ogni compito viene elaborato separatamente: Codex legge ed edita i file, esegue comandi (compresi harness di test, linter e type checker) e monitora il progresso in tempo reale. A seconda della complessità del lavoro, il completamento di un task richiede da uno a trenta minuti.
Una volta ultimata l’operazione, Codex esegue automaticamente le modifiche nel proprio ambiente e fornisce evidenze verificabili tramite log del terminale e output dei test per tracciare ogni passaggio dell’esecuzione. L’utente può quindi rivedere i risultati, richiedere ulteriori revisioni, aprire una pull request su GitHub o integrare direttamente le modifiche nel proprio ambiente locale. La configurazione dell’ambiente Codex può essere personalizzata per rispecchiare fedelmente il setup di sviluppo in uso. Per facilitare l’integrazione nei workflow esistenti, è possibile inserire file AGENTS.md all’interno del repository. Questi file, simili a README.md, indicano a Codex come orientarsi nella codebase, quali comandi di test eseguire e quali standard seguire.
Dal punto di vista della sicurezza, Codex viene rilasciato come “research preview” seguendo una strategia di deployment iterativo. Gli utenti possono verificare ogni output di Codex attraverso le citazioni di log e test, salvaguardando la trasparenza e riducendo i rischi associati all’automazione di compiti complessi. In caso di incertezze o fallimenti nei test, l’agente segnala esplicitamente i problemi, lasciando all’utente la decisione su come procedere. Rimane comunque fondamentale che uno sviluppatore controlli manualmente tutto il codice generato prima dell’integrazione.
Per prevenire utilizzi malevoli come la creazione di malware, Codex è addestrato per riconoscere e rifiutare richieste finalizzate allo sviluppo di software dannoso, mantenendo al contempo la flessibilità necessaria per supportare attività legittime, inclusi progetti di low-level kernel engineering. Il modello si avvale di un addendum alla System Card di o3, che dettaglia i meccanismi di sicurezza adottati.
L’esecuzione avviene in container isolati senza accesso a Internet: l’agente può interagire solo con il codice fornito nel repository e con eventuali dipendenze preinstallate tramite script di setup, impedendo connessioni verso siti esterni o API non autorizzate.
Fin dai primi test interni, i team tecnici di OpenAI hanno adottato Codex per delegare attività ripetitive e ben definite come refactoring, rinominazione di variabili e scrittura di test, che altrimenti interromperebbero la concentrazione. Codex viene impiegato anche per creare nuovi scaffold di funzionalità, collegare componenti, risolvere bug e redigere documentazione. Riducendo i continui cambi di contesto e facendo emergere attività dimenticate, Codex aiuta gli ingegneri a produrre il loro codice più rapidamente e a mantenere la concentrazione.
A marzo 2025 era già stato presentato anche Codex CLI, un agente open source leggero che gira nel terminale locale. Questa estensione porta la potenza di modelli come o3 e o4-mini direttamente nell’ambiente di sviluppo dell’utente, facilitando l’integrazione dei task di Codex nel normale flusso di lavoro in locale. Grazie a Codex CLI, gli sviluppatori possono eseguire comandi analoghi, come generazione di codice o esecuzione di test, senza abbandonare il terminale, rendendo il coding assistito da AI ancora più immediato e fluido. Gli utenti di Codex CLI possono ora utilizzare come modello codex-mini-latest, una versione light di codex-1.
Il 23 maggio viene annunciato da Greg Brockman, presidente di OpenAI, l’integrazione di RDKit in ChatGPT, che permette ai suoi modelli di analizzare, manipolare e visualizzare molecole e informazioni chimiche tramite Python.
Il tuo assistente intelligente open source
Il 20 maggio la startup Intelligent Internet presenta II-Agent, un framework open source per agenti intelligenti progettato per offrire prestazioni di livello avanzato nei compiti più disparati, dal supporto personale alla gestione di processi complessi.

II-Agent si colloca al centro del più ampio sistema Intelligent Internet, che include dataset, modelli, agenti e sciami, tutti sviluppati con licenza aperta per promuovere la massima adozione e allineamento. Grazie a un’architettura basata su Claude 3.7 Sonnet di Anthropic, il framework è in grado di orchestrare cicli di ragionamento iterativo, selezione di strumenti (come ricerca web, esecuzione di comandi shell e manipolazione di file) e gestione intelligente del contesto, mantenendo un bilancio tra ricchezza del dialogo e limiti di context window (fino a 120k token gestiti mediante strategie di troncamento e archiviazione). Dal punto di vista funzionale, II-Agent offre:
Ricerca e fact-checking avanzati, con ricerche web multistep, triangolazione delle fonti e strutturazione automatica delle note
Generazione di contenuti (bozze di articoli, piani didattici, testi creativi, ecc.)
Analisi e visualizzazione dei dati, comprendenti pulizia, rilevamento di tendenze, creazione di grafici e report automatici
Sviluppo software, con sintesi di codice, refactoring, debugging e scrittura di test in più linguaggi
Automazione di workflow, generando script per browser, gestione file e ottimizzazione di processi
Problem solving strutturato, scomponendo problemi complessi in sotto-compiti e offrendo percorsi alternativi con riflessioni trasparenti
In ambito benchmarking, II-Agent punta a superare le alternative open source già esistenti (come OpenManus e Suna) e a colmare il divario con i sistemi proprietari come Manus e GenSpark AI. Grazie all’integrazione con la suite II-Researcher per il supporto a ragionamenti lunghi e complessi, il framework ha ottenuto risultati competitivi sulla GAIA benchmark, raggiungendo i livelli di accuratezza dei principali agenti commerciali.
Video interattivi
Il 28 maggio la startup Odyssey rende disponibile in anteprima pubblica la sua prima esperienza di video interattivo generato in tempo reale dal suo world model
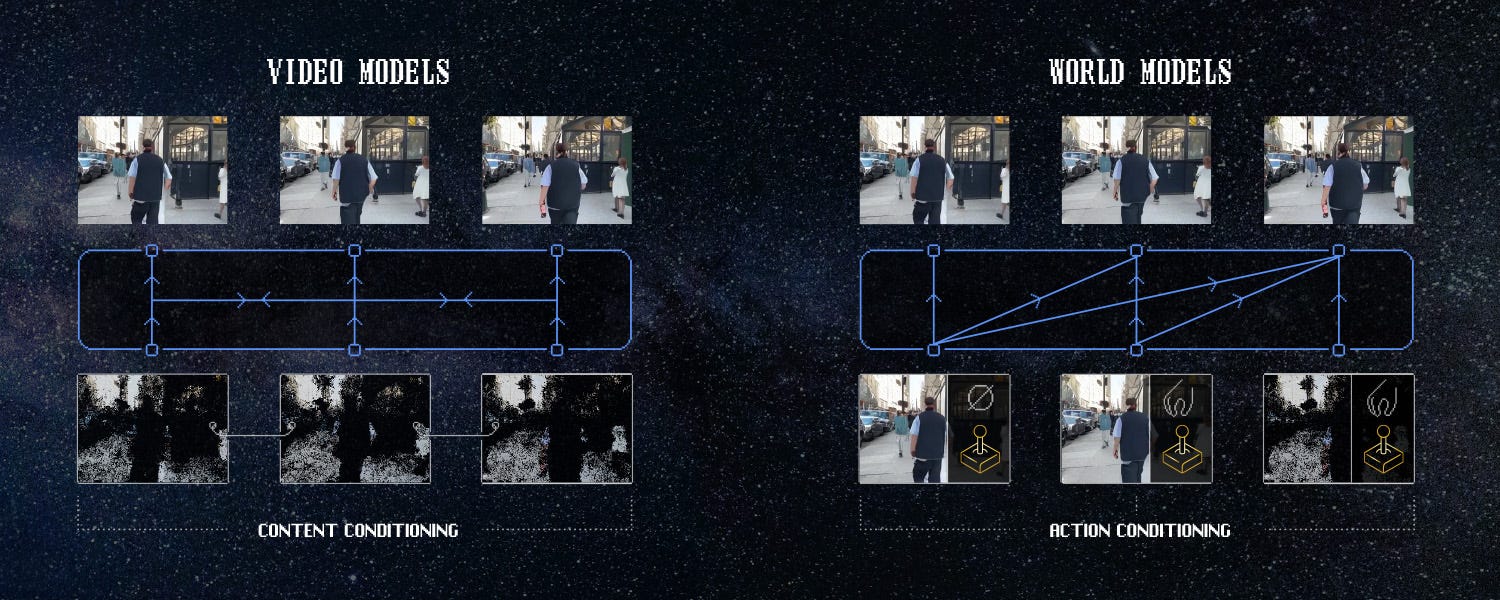
Si tratta di un’anteprima di ricerca che inaugura un nuovo medium di narrazione, capace di far interagire lo spettatore con il flusso video mediante tastiera, controller o dispositivi mobili, in modo simile a un rudimentale Holodeck.
Interactive video, come lo definisce Odyssey, è un formato che unisce la qualità visiva del cinema tradizionale con la reattività dei videogiochi. Il sistema si basa su un world model in grado di generare nuovi fotogrammi realistici ogni 40 ms, mantenendo la coerenza spaziale e temporale per sessioni di riproduzione che superano i cinque minuti. Il cuore dell’esperienza è un modello dinamico condizionato dalle azioni dell’utente: a ogni input (pressione di un tasto, tocco o movimento di joypad) corrisponde una previsione del fotogramma successivo, creata e trasmessa in streaming fino a 30 FPS grazie a cluster di GPU H100 dislocate tra Stati Uniti ed Europa. Il risultato attuale è un’esplorazione simile a un “sogno in VHS”: ancora instabile, ma dal potenziale rivoluzionario.
Per garantire stabilità nel rendering autoregressivo, l’anteprima si affida a un post-training su un set ristretto di video, sacrificando in parte la generalità a favore di sessioni più lunghe e consistenti. Nel futuro prossimo, Odyssey punta a ottenere dei modelli di generazione ancora più generali, in grado di apprendere azioni e fisica da video del mondo reale. Questo progetto anticipa una trasformazione radicale del video: dall’entertainment alla formazione, dalla pubblicità ai viaggi, tutto potrebbe evolvere verso un’esperienza interattiva, libera dai vincoli dei metodi tradizionali.
Il ritorno di DeepSeek
Sempre il 28 maggio, DeepSeek ha lanciato una nuova versione del suo modello di ragionamento R1, migliorata sotto ogni punto di vista.

DeepSeek R1-05-28 mantiene gli stessi costi della versione precedente, ma con performance significativamente migliorate su ogni benchmark, al punto da poter competere col ben più costoso o3 di OpenAI, così come il suo predecessore riusciva a tener testa a o1 che rappresentava al tempo (appena 6 mesi fa) lo stato dell’arte.
In particolare, si segnalano delle grosse migliorie nelle capacità legate al coding, così come un minor tasso di allucinazioni e il supporto per gli output strutturati in formato JSON e per le function calling.
Risolvere la coerenza nelle immagini AI
Il 29 maggio Black Forest Labs annuncia il rilascio di Flux 1 Kontext, una famiglia di modelli generativi basati su flow matching per la generazione e modifica di immagini contestualmente coerenti tra loro.

FLUX.1 Kontext introduce per la prima volta una pipeline ibrida che accetta prompt sia testuali sia visivi, permettendo di estrarre e trasformare concetti visivi in maniera coerente e di alta qualità. A differenza dei tradizionali modelli text-to-image, la famiglia FLUX.1 Kontext unifica generazione e editing istantaneo, combinando comprensione del contesto, coerenza dei personaggi e capacità di editing locale con sintesi fotorealistica. Il sistema raggiunge velocità di inferenza fino a otto volte superiori rispetto ai principali modelli concorrenti, garantendo un’aderenza ai prompt di livello avanzato e una resa dei caratteri tipografici molto competitiva.
Tra le principali caratteristiche spiccano la preservazione di elementi unici, come personaggi o oggetti di riferimento, attraverso più scene, l’editing mirato di specifiche aree senza compromettere il resto dell’immagine, il mantenimento di stili distintivi tramite riferimenti e una latenza minima per un’esperienza interattiva fluida sia in fase di generazione che di modifica.
La suite comprende due modelli disponibili via BFL API: FLUX.1 Kontext [pro], progettato per editing iterativo veloce con mantenimento delle identità e degli stili, e FLUX.1 Kontext [max], un modello sperimentale con aderenza ai prompt e qualità tipografica potenziate senza sacrificare la velocità. In private beta è aperta la variante open-weight FLUX.1 Kontext [dev], un transformer da 12 miliardi di parametri ideale per personalizzazioni e test di sicurezza.
Nonostante i progressi, FLUX.1 Kontext presenta alcune limitazioni: sessioni prolungate di editing su più step possono introdurre artefatti visivi, occasionali discrepanze nell’interpretazione delle istruzioni e conoscenza del mondo ancora parziale, con possibili imperfezioni derivate dal processo di distillazione.
Per rendere più accessibili test e demo, Black Forest Labs lancia il BFL Playground, un’interfaccia web che permette di testare i modelli FLUX in tempo reale senza integrazioni tecniche.
Proprietà linguistiche avanzate
Sempre il 29 maggio 2025 Hume presenta EVI 3, la terza generazione del suo modello speech-language, progettato per esperienze vocali completamente personalizzabili.
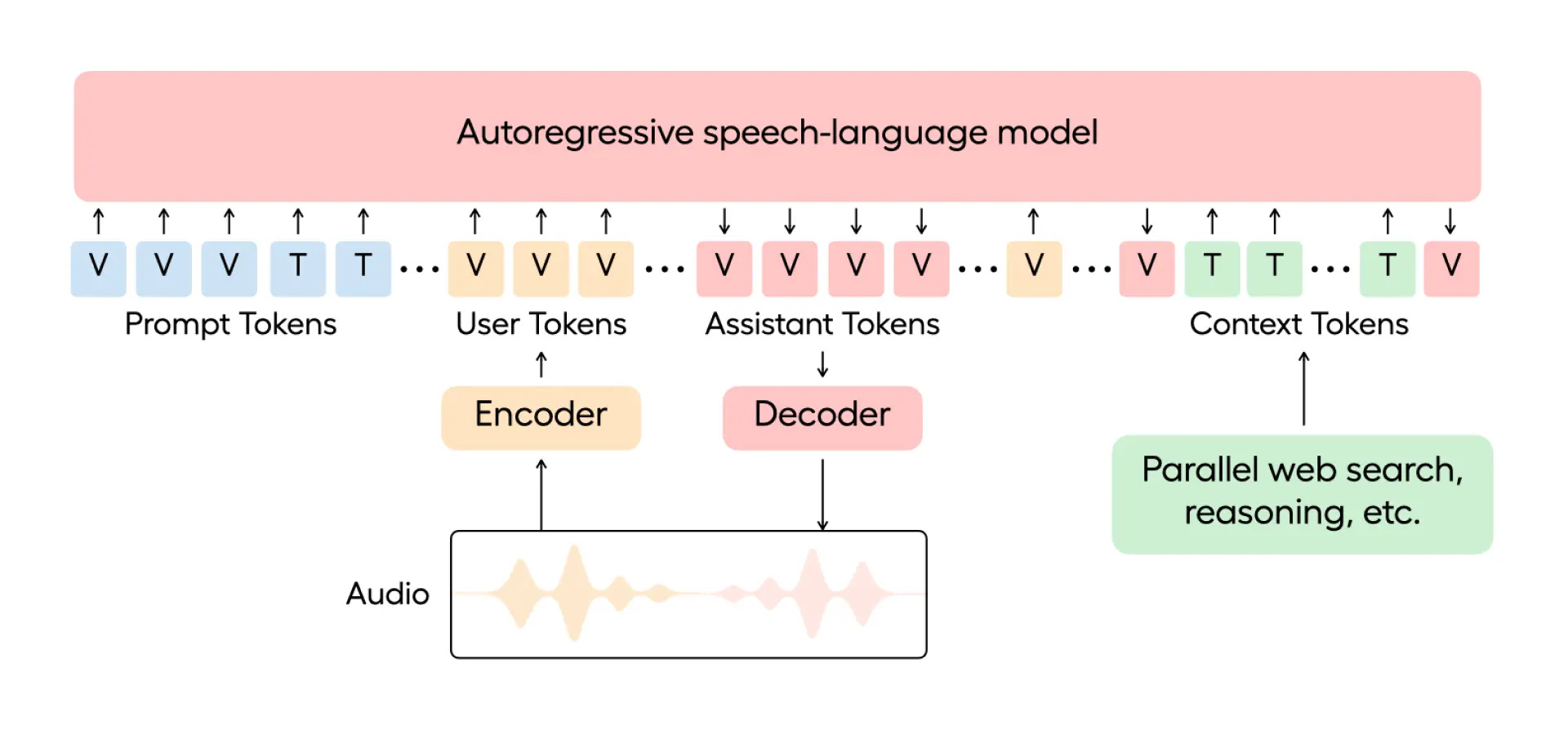
EVI 3 unisce in un unico sistema le capacità necessarie a trascrivere, comprendere il linguaggio e produrre parlato, offrendo un livello di espressività, realismo e comprensione emotiva inediti nelle interazioni con voci AI.
A differenza dei precedenti modelli vincolati a un numero ristretto di speaker, EVI 3 “impara” a parlare con qualsiasi voce e personalità si desideri creare tramite un semplice prompt. Grazie all’architettura per lo streaming, l’utente può parlare in tempo reale e ricevere risposte altrettanto fluide: la qualità audio è paragonabile a quella di Octave, il modello TTS di punta di Hume, mentre l’intelligenza linguistica è equiparabile a quella degli LLM più avanzati a parità di latenza.
Nei test di confronto cieco condotti da Hume, EVI 3 è risultato mediamente superiore a GPT-4o di OpenAI su sette dimensioni chiave: empatia, espressività, naturalezza, gestione delle interruzioni, velocità di risposta e qualità audio.
Il fulcro innovativo di EVI 3 è la capacità di generare nuove voci e personalità al momento, senza dover ricorrere a dataset dedicati per ogni voce. Hume ha sviluppato un approccio che cattura l’intera gamma dei timbri e degli stili di parlato umani in un singolo modello: attraverso un processo di reinforcement learning, EVI 3 impar a identificare e affinare le caratteristiche preferite di ogni voce.
Per testare la capacità di modulare tono ed emozioni in tempo reale, sono state richieste a EVI 3 e ai modelli concorrenti (GPT-4o, Gemini, Sesame) 30 espressioni diverse: emozioni quali “divertito” o “triste” e stili particolari come “parla da pirata” o “sussurra”. Ogni partecipante ha valutato su scala 1–5 l’aderenza del modello all’emozione o allo stile richiesto. Anche in questo caso, EVI 3 ha ottenuto punteggi superiori rispetto a tutti gli altri modelli.
Per verificare l’abilità di riconoscere le emozioni nell’utente, è stato condotto un test controllato che isolava il linguaggio verbale: i partecipanti hanno pronunciato una stessa frase esprimendo emozioni diverse (es. “spaventato”, “stupefatto”, “arrabbiato”) e, dopo ogni interazione, hanno valutato EVI 3 e GPT-4o su accuratezza del riconoscimento emotivo e naturalezza delle risposte. EVI 3 ha superato GPT-4o nell’identificare otto delle nove emozioni e ha ricevuto migliori feedback sulla naturalezza delle sue risposte, dimostrando un’eccellente empatia vocale.
Il modello è attualmente in fase di addestramento e, al momento del rilascio ufficiale, sarà più capace in altre lingue, in particolare francese, tedesco, italiano e spagnolo.
Conversazioni fluide
Il 30 maggio ElevenLabs lancia Conversational AI 2.0, un’evoluzione della sia funzionalità progettata per creare agenti vocali sofisticati, capaci di interazioni più naturali e di supportare ambienti enterprise con requisiti di sicurezza stringenti.

Conversational AI 2.0 introduce un modello di gestione del turno di parola all’avanguardia, capace di riconoscere indicatori conversazionali come “um” e “ah” per comprendere quando intervenire o attendere. Questo approccio allo stato dell’arte elimina pause innaturali e interruzioni brusche, offrendo dialoghi fluidi e più umani. Nelle simulazioni di customer service l’agente può attendere mentre l’utente verifica un’informazione (“Oh, fammi controllare… um…”) prima di rispondere, migliorando l’efficienza e la soddisfazione dell’esperienza utente.
La comunicazione multilingue diventa più semplice grazie al rilevamento automatico della lingua. Gli agenti riconoscono in tempo reale la lingua parlata dall’utente e rispondono senza bisogno di configurazioni manuali né di cambio del contesto. Questa caratteristica è cruciale per le aziende globali che vogliono fornire un servizio coerente e di alta qualità su diversi mercati, favorendo esperienze prive di barriere linguistiche. Conversational AI 2.0 integra i RAG direttamente nell’architettura dell’agente vocale. Gli agenti possono così attingere a knowledge base esterne con latenza minima e massima privacy per fornire risposte informate. In ambito sanitario, ad esempio, un assistente può recuperare istantaneamente linee guida cliniche specifiche, mentre un supporto clienti accede a documenti tecnici aggiornati in tempo reale, migliorando l’accuratezza delle risposte.
La piattaforma supporta ora la multimodalità: basta definire un singolo agente per abilitarlo a interagire via testo, voce o entrambi contemporaneamente. Questo riduce notevolmente il lavoro degli ingegneri, che non devono più creare separatamente agenti testuali e vocali. A completamento delle funzionalità operative viene introdotta anche la possibilità di effettuare chiamate in batch, consentendo di inoltrare simultaneamente centinaia o migliaia di chiamate outbound. Questa funzionalità è ideale per inviare avvisi, condurre sondaggi o distribuire messaggi personalizzati a grandi liste di contatti in modo rapido.
In ottica enterprise, Conversational AI 2.0 garantisce piena conformità HIPAA, requisito indispensabile per applicazioni in ambito sanitario che gestiscono dati sensibili dei pazienti. Viene anche offerta l’opzione di residenza dei dati nell’Unione Europea, rispondendo alle necessità di sovranità e alle normative EU. Le integrazioni con sistemi terzi e l’infrastruttura focalizzata sulla sicurezza e l’affidabilità rendono la piattaforma adatta a deployment mission-critical, assicurando continuità operativa e protezione delle informazioni.
L’edicola dei paper scientifici
Tre paper di ricerca per il mese di maggio.

DREAMGEN - Un framework innovativo che sfrutta modelli video generativi per creare dati sintetici altamente realistici, consentendo l’apprendimento di politiche robotiche capaci di generalizzare a nuovi compiti e ambienti senza costose dimostrazioni manuali. La pipeline si divide in quattro fasi e prevede: (1) il fine-tuning di un video world model su sequenze teleoperate di un solo compito di pick-and-place, (2) la generazione di nuovi video condizionati su frame iniziale e descrizioni linguistiche di comportamenti inediti, (3) l’estrazione di “pseudo-azioni” tramite un modello di dinamica inversa (IDM) o un modello di azioni latenti (LAPA), (4) l’addestramento di politiche visuomotorie su queste traiettorie neurali sintetiche . Nonostante l’uso di dati reali limitato a una singola attività in un solo ambiente, DREAMGEN abilita un robot umanoide a eseguire oltre 20 nuove azioni (come versare, aprire/chiudere oggetti articolati e usare utensili) e a operare in scenari completamente nuovi con tassi di successo fino al 43 % in ambienti noti e al 28 % in ambienti mai incontrati. Il paper parla anche di DreamGen Bench, un benchmark video che correla la qualità delle generazioni con il rendimento delle politiche robotiche, offrendo un metodo diagnostico per valutare modelli video verso applicazioni nell’ambito della robotica. Questa strategia apre la strada a un nuovo paradigma di robot learning scalabile, riducendo drasticamente la dipendenza da dati teleoperati manualmente.
AI Agents vs. Agentic AI - L’ascesa degli LLM degli ultimi anni ha dato vita a un nuovo ecosistema di sistemi autonomi in grado di compiere azioni complesse in risposta a obiettivi definiti, segnando il passaggio dall’era della generazione di contenuti a quella degli “agenti” intelligenti. Questo paper offre una disamina critica di due paradigmi emergenti, distinguendo con chiarezza le architetture, i meccanismi e i livelli di autonomia che caratterizzano gli AI Agents — sistemi mono-agente, modulari e task-specific — e l’Agentic AI, ovvero reti orchestrate di agenti specializzati capaci di collaborare, suddividere obiettivi e mantenere una memoria persistente. Partendo da una rassegna delle radici storiche nei sistemi multi-agente e negli expert systems, gli autori definiscono un quadro concettuale e metodologico basato su cinque dimensioni chiave: architettura, meccanismi operativi, complessità, interazione e autonomia; e propongono una tassonomia che mette a confronto Generative AI, AI Agents, Agentic AI e la nuova categoria dei Generative Agents. Viene anche illustrata l’evoluzione dalle prime applicazioni di generazione di testo e immagini al tool-augmented reasoning, fino ai framework multi-agente come AutoGPT e CrewAI, capaci di orchestrare flussi di lavoro distribuiti e di adattarsi dinamicamente ai cambiamenti contestuali.
Il paper passa in rassegna 14 casi d’uso reali, dal customer support automatizzato agli assistenti di ricerca scientifica, dalla robotica collaborativa fino ai sistemi di supporto decisionale in ambito medico, evidenziando le potenzialità operative e i limiti intrinseci di ogni paradigma. Vengono poi analizzate le principali sfide, dalle allucinazioni dei modelli linguistici alla complessità di coordinamento e alle questioni di governance e sicurezza, e proposte 10 strategie per migliorare affidabilità, scalabilità e spiegabilità, gettando le basi per una roadmap di sviluppo verso sistemi agentici sicuri, causali e capaci di auto-apprendimento.
LightLab - Con il recente impiego di modelli di diffusione per il fotoritocco, LightLab si propone di colmare un vuoto fondamentale: il controllo parametrico e preciso delle sorgenti luminose in un’immagine. Mentre i metodi di rendering tradizionali richiedono acquisizioni multiple e modelli 3D dettagliati, e le tecniche di editing basate su testo faticano a garantire coerenza fisica e precisione granulare nelle modifiche, LightLab combina la potenza dei modelli diffusione con una solida pipeline di acquisizione dati. A partire da 600 coppie di fotografie raw in cui una luce visibile viene accesa o spenta, integrate da centinaia di migliaia di render sintetici controllati in Blender, il sistema sfrutta la linearità della luce per generare sequenze parametrizzate di cambiamenti di intensità e colore, preservando ombre, riflessi e caratteristiche delle superfici. Grazie a un processo di fine-tuning su un modello di diffusione latente pre-addestrato, LightLab introduce condizioni spaziali (maschere di sorgente, mappe di profondità) e globali (intensità e temperatura colore) per offrire un workflow di editing estremamente flessibile. Gli utenti possono così modulare l’intensità di una lampada, cambiarne il colore o regolare l’illuminazione ambientale in modo intuitivo, ottenendo risultati fotorealistici e coerenti con le leggi della fisica.
Il mercatino dell’open-source
Tre progetti open-source con codice per il mese di maggio.

K-Sim Gym - Un framework per facilitare l’addestramento e il deployment di controller per robot umanoidi tramite apprendimento per rinforzo, con un’implementazione compatta di circa 700 righe di Python. Basato sul simulatore fisico K-Sim e integrato con JAX per sfruttare l’accelerazione GPU, il progetto garantisce performance elevate durante le fasi di addestramento. Il flusso di lavoro include uno script di training modulare, un notebook Google Colab per avviare esperimenti in pochi click, una visualizzazione in tempo reale dei log e dei video tramite TensorBoard e un viewer interattivo per ispezionare il comportamento del robot durante l’esecuzione. Al termine dell’addestramento, il modello viene convertito in un formato Kinfer e può essere distribuito su robot reali tramite kinfer-sim, semplificando la transizione dal simulatore al mondo fisico. K-Sim Gym offre anche un leaderboard dedicato alle competizioni di locomozione, favorendo la collaborazione e il confronto tra ricercatori e sviluppatori nel campo della robotica e dell’IA.
Chain of Recursive Thoughts - Un innovativo meccanismo di “pensiero ricorsivo” per i modelli AI, permettendo al sistema di generare una prima risposta, determinare dinamicamente il numero di cicli di riflessione necessari e, in ogni round, produrre più alternative, valutarle confrontandole tra loro e selezionare la migliore, in un vero e proprio scontro interno tra varianti di risposta. Questo approccio, testato con modelli come Mistral 3.1 24B, ha dimostrato di trasformare produzioni “mediocri” in risultati di qualità significativamente superiore, soprattutto in ambito di programmazione, grazie alla capacità del sistema di dubitare autonomamente delle proprie soluzioni e di rivederle più volte. CoRT offre sia uno script Python standalone per l’esecuzione locale – con un comando semplice dopo aver configurato le dipendenze e impostato la variabile OPENROUTER_API_KEY – sia un’interfaccia web in JavaScript che consente di avviare esperimenti in modo interattivo, monitorando in tempo reale i progressi e visualizzando i risultati tramite un frontend intuitivo. Distribuito sotto licenza MIT e corredato da esempi dimostrativi nella cartella demos, Chain-of-Recursive-Thoughts si propone come una piattaforma modulare e accessibile per esplorare strategie avanzate di autovalutazione e miglioramento iterativo negli LLM.
Steerable Scene Generation - Un’implementazione completa dei metodi presentati nel paper Steerable Scene Generation with Post Training and Inference-Time Search, articolati intorno a un modello di generazione di scene basato su diffusione che predice oggetti e pose SE(3) da una libreria predefinita e che viene adattato a obiettivi specifici tramite post-training basato su rinforzo, generazione condizionata e una strategia di ricerca Monte Carlo Tree Search al momento dell’inferenza. Il codice, organizzato con Poetry e un sistema di configurazione modulare Hydra, integra Weights & Biases per il tracciamento dei log e dei checkpoint, e offre script per campionamento incondizionato, campionamento condizionato da testo, riorganizzazione e completamento di scene, ricerca in tempo di inferenza e post-elaborazione fisica che applica simulazione e proiezione per garantire la fattibilità degli ambienti generati. Gli utenti possono anche esportare le scene in formato pickle o come direttive per Drake MultibodyPlant, convertire dataset procedurali in formato Huggingface tramite script dedicati e riprodurre esempi dimostrativi coperti da test unitari e di integrazione, facilitando la riproducibilità e l’estensione del lavoro.
Psicosi Creativa
C’è chi attraversa le città lasciando piccoli segni invisibili e c’è chi lascia degli squarci profondi che non passano inosservati. Fabio Weik, artista multidisciplinare e figura storica del graffiti writing italiano, appartiene a questa seconda categoria: la sua traiettoria parte dai muri di Milano nel 1997 e arriva, oggi, a toccare gallerie internazionali, passerelle di moda e scenari urbani trasformati in dispositivi critici.
Fondatore della Interplay crew e membro della leggendaria TDK, Weik incarna una tensione continua tra la strada e l’istituzione, tra il gesto effimero del writer e la durata del museo. Ma è nel cortocircuito tra questi due mondi che si accende il cuore della sua poetica: un’estetica che destabilizza, che non decora ma interroga, che rifiuta le narrazioni accomodanti. Per lui l’arte non è un prodotto, ma un atto di frizione; e la tecnologia, più che uno strumento, è una soglia: un territorio incerto dove umano e strumenti si sfiorano senza mai fondersi del tutto.
Attraverso materiali non convenzionali, simboli pop e tensioni visive, Weik costruisce opere che riflettono la nostra epoca dominata dal consumo visivo e dall’algoritmo, restituendole un’umanità inquieta. Con Weik Studio, laboratorio creativo “fluido” fondato nel 2024, porta questa visione in ambiti che vanno dalla scenografia all’attivismo visivo, lavorando sempre a partire da una domanda, mai da una risposta.
In questa conversazione ci parla di graffiti e AI, di arte come veleno e psicosi creativa, dell’urgenza di creare zone liminali in cui perdersi, per poi – forse – ritrovarsi.
Questa intervista si colloca nella più ampia visione del magazine di offrire uno spazio unico ai creativi di tutto il mondo che utilizzano la tecnologia come ampliamento delle loro possibilità espressive. A partire da quest’anno, la rubrica includerà anche interviste a ingegneri, programmatori, matematici e imprenditori, per diversificare i contenuti e promuovere l'idea che la creatività non appartiene solo ad artisti e designer, ma che si tratta di un raffinato processo di problem solving intrinseco alla natura dell’essere umano e alle sue capacità cognitive.

Iniziamo con la domanda di rito del magazine: qual è il tuo rapporto con la tecnologia?
La tecnologia, per me, non è né un’alleata né una nemica. È un’eco della condizione umana, uno specchio delle nostre tensioni tra desiderio di controllo e bisogno di meraviglia. La utilizzo come si userebbe un frammento archeologico: con cautela, consapevolezza e rispetto per il suo potere trasformativo.
Più che uno strumento, è un linguaggio che amplifica, altera, distorce o chiarisce le intenzioni. L’arte, come la tecnologia, rappresenta il periodo storico che stiamo vivendo: genera soglie. Ciò che mi interessa è sostare in quelle soglie, dove l’umano e il digitale si sfiorano senza mai fondersi del tutto.
Da quando hai iniziato la tua avventura artistica nel 1997, il mondo è cambiato radicalmente, e con lui anche l'arte urbana. Cosa pensi che sia rimasto dello spirito originario del graffiti writing? E come si rapporta con le altre forme artistiche urbane?
Del writing sopravvive un nucleo incandescentemente puro: l’urgenza. L’urgenza di essere visibili, di affermarsi nel paesaggio urbano come soggetto agente. Il gesto del writer (spesso frainteso come vandalico) è, in realtà, un’azione semiotica e psicogeografica: riscrive lo spazio, lo ricodifica. È una disciplina, non una semplice passione (una delle quattro discipline dell’hip hop) e, in quanto tale, non dovrebbe essere ridotta a discussioni sterili sul fatto che sia arte o vandalismo. Se oggi molte forme urbane si sono estetizzate fino alla neutralità, il writing autentico conserva ancora un potenziale eversivo.
È un linguaggio arcaico che resiste nell’era dell’algoritmo.
Sei parte della storica TDK crew e fondatore della Interplay crew. Nel tuo percorso che rilevanza ha avuto l'appartenenza a questi gruppi?
Le crew sono famiglie di frontiera. In TDK ho imparato il valore della disciplina estetica nella strada; in Interplay ho coltivato la visione interdisciplinare, il dialogo tra pratiche diverse, un modo differente di affrontare i graffiti e la competitività nell’underground. L’appartenenza non è solo identitaria, è formativa: è attraverso gli altri che ci si scolpisce. Le crew sono dispositivi relazionali, prima ancora che creativi. Sono laboratori psicosociali in cui le capacità individuali si rafforzano nelle alleanze, nei conflitti, negli ascolti e nei silenzi condivisi.
La tua pratica artistica si colloca a metà strada tra un mondo underground e il sistema dell’arte più istituzionale. Ci sono delle frizioni particolari che hai incontrato nel passaggio da una dimensione all'altra?
Sì, ma le considero necessarie. L’istituzione tende a canonizzare, mentre l’underground tende a dissolversi nell’atto. Portare l’effimero dentro il museo significa rischiare la fossilizzazione del gesto, ma anche offrirgli una possibilità di riscrittura. L’arte vive di contraddizioni: molto spesso, sputandoci sopra, ho lubrificato il sistema.
La cosa interessante è che esistono frizioni anche tra un underground e l’altro: permane una certa malinconia nelle generazioni precedenti, che cercano di ricentrare il discorso sul proprio passato, finendo per ignorare le generazioni successive che, a loro volta, hanno generato nuove subculture. È fondamentale rimanere aggiornati: l’underground di oggi è la chiave di lettura delle estetiche e delle istituzioni di domani
Il tuo lavoro ha una forte componente visiva, spesso ispirata ai media e a diverse sotto-culture, ma esprime anche dei concetti profondi. Spesso chi si approccia alla creazione artistica lavora troppo sulla parte estetica e poco sull'idea, o vice versa. Tu come hai trovato il giusto connubio tra "visual" e "concept"?
Attraverso la lente della necessità. Ogni opera nasce da una frizione interna: se un’immagine è bella ma priva di visione, è decorazione. Se un’idea è forte ma non trova il corpo giusto, è saggistica travestita. Io cerco la sintesi: una forma che non solo seduca l’occhio, ma lo costringa a riflettere.
L’estetica, per me, è un’esca; il concetto è il veleno che si scopre solo dopo.
Nella tua biografia parli di “destabilizzare lo spettatore”: pensi che per un artista sia importante turbare la quiete di chi fruisce delle sue produzioni?
L’arte non ha il compito di consolare, né quello di rassicurare. Ha invece il potere (e forse il dovere) di aprire crepe. L’opera non deve avere un utilizzo ma un suo ruolo, e delle volte lo deve avere più dell’artista. Destabilizzare non significa scandalizzare, ma far vacillare certezze. Turbare è un atto d’amore crudele: spingere lo spettatore fuori dalla zona di comfort per restituirgli uno sguardo più lucido.
Nell’epoca della distrazione algoritmica, provocare un corto circuito percettivo è già un atto politico e d’amore; e con politico non intendo un’ideologia ma la sua etimologia greca, politiké, dove polis significa città e si sottintende techné, cioè arte.
Hai collaborato con brand di moda, musicisti e gallerie internazionali. Come si mantiene una propria identità artistica anche nei progetti più "commerciali"?
La chiave è trasformare il compromesso in linguaggio. Ogni brand, ogni committenza è una grammatica: io cerco di inserirla nei suoi interstizi. Non edulcoro la mia poetica, ma ne regolo l’intensità. È come lavorare su frequenze diverse con lo stesso codice genetico. L’identità, se è autentica, trova sempre il modo di filtrare, anche attraverso l’uniforme o estetiche seduttive.
Oggi l’immagine dell’artista è spesso costruita tanto quanto le sue opere. Tu che rapporto hai con l’auto-narrazione e la promozione pubblica?
L’auto-narrazione è diventata una seconda pelle per l’artista contemporaneo. Ma io preferisco agire per sottrazione. L’immagine che do di me è costruita con gli stessi materiali con cui compongo le mie opere: frammenti, assenze, simboli. Credo in una narrazione che non spieghi, ma alluda. Preferisco essere una zona da esplorare, piuttosto che una biografia da leggere.
Qual è la tua visione rispetto alle nuove possibilità creative offerte dall'Intelligenza Artificiale? Può esserci un dialogo con le opere più materiche?
L’AI è un’ombra che ci interroga (anche se siamo noi a interrogarla sempre di più). La sua presenza rende ancora più urgente il bisogno di materia, di imperfezione, di gesto. E forse questo bisogno esploderà in maniera pericolosa. Ma può anche diventare uno strumento di disvelamento, se utilizzata con coscienza critica.
Credo in un dialogo possibile: un’arte che usi l’AI non per riprodurre, ma per interrogare. Come mezzo, non come fine. È nell’interazione tra umano e artificiale che può nascere una nuova sensibilità visiva. Ma non se l’umano si accontenta della prima realtà generata da un’intelligenza artificiale.
Ti va di raccontarci qualcosa su Weik Studio? Ci sono degli elementi coi quali si distingue rispetto ad altri collettivi multidisciplinari?
Weik Studio è un organismo vivo (o almeno quello che cerco di trasferire ai miei collaboratori) più che un collettivo. È una struttura fluida che mette in comunicazione mondi apparentemente distanti: l’arte contemporanea, la moda, l’attivismo visivo, la scenografia (intesa come lettura sensibile dello spazio). La sua forza risiede nella capacità di creare ambienti narrativi, dispositivi estetici che non decorano, ma significano. A differenza di altri studi, Weik Studio non offre semplici soluzioni visive: costruisce o decostruisce. Ogni progetto è una domanda. A volte entriamo talmente a fondo nella psicologia del cliente che è lui a voler estremizzare, e siamo noi a dover mettere dei freni.
Siamo professionisti della psicosi creativa.
L’angolo degli annunci
Questo è un nuovo spazio, precedentemente integrato nella parte introduttiva del magazine, che voglio dedicare a vari tipi annunci legati a questo progetto.

Dopo tanta attesa, è finalmente pronto il pitch deck di Monumental AI, la startup che si occuperà della gestione del magazine e dei futuri progetti editoriali e di consulenza aziendale su AI e robotica. Abbiamo un piano ambizioso di espansione e livello europeo e siamo alla ricerca di investitori, partner e collaboratori per avviare questa startup dal grande potenziale di crescita, contattami su LinkedIn per prendere visione del pitch deck di Monumental AI e per discutere del progetto.
Nel frattempo, sono sempre alla ricerca di una collaborazione a medio-lungo termine per gestire la pagina social del magazine e creare più contenuti. Si offre una quota in Monumental AI (con un contratto) e formazione di alto livello sui principali strumenti AI, in cambio di una ragionevole quantità di tempo da concordare. Se l'idea ti intriga o conosci qualcuno con la giusta ambizione e competenza che possa abbracciare questa missione, puoi sempre contattarmi su LinkedIn.