


Le Fornaci del Nuovo Mondo
Nulla resiste al fuoco del cambiamento, dalle cui fiamme si forgia il futuro


Ci stiamo lasciando alle spalle un anno a dir poco incredibile, durante il quale abbiamo assistito a ogni tipo di sviluppo nel mondo della tecnologia.
I modelli di intelligenza artificiale per i video hanno raggiunto per la prima volta un grado di qualità che ne permette un utilizzo professionale. I modelli per le immagini hanno continuato a migliorare, soprattutto sull’anatomia dei soggetti. I modelli per la musica sono già arrivati al punto in cui producono brani indistinguibili da quelli di un’etichetta discografica. La multimodalità sta diventando uno standard per i modelli linguistici e si sono aperte le porte ai primi modelli di ragionamento.
Ma questa è solo la punta dell’iceberg. Stiamo assistendo a una rinascita tecnologica, con innovazioni che spaziano dall'intelligenza artificiale alla robotica, dalle soluzioni energetiche all'esplorazione spaziale, dalle biotecnologie alla realtà aumentata. Ogni settimana si possono leggere notizie di scoperte e risultati che sembravano destinati a realizzarsi solo tra decenni. Il ritmo con cui scienziati e ingegneri di tutto il mondo stanno scoprendo e testando nuove possibilità sta già iniziando a essere esponenziale, anche se siamo appena all’inizio della curva. Man mano che andremo avanti negli anni, gli effetti combinati di queste innovazioni diventeranno sempre più evidenti ed entro il 2030 ci guarderemo indietro pensando a quanto era profondamente diverso il mondo che fino a poco prima ci sembrava la normalità.
Mettendo un attimo da parte le fantasticherie per tornare al presente, siamo giunti all’ultima pubblicazione del 2024 e voglio ringraziare tutti i lettori che hanno deciso di seguire questo progetto nato solo sei mesi fa. Stiamo crescendo con un ritmo di circa 50 nuovi iscritti al mese e questo mi rende molto soddisfatto, perché sono convinto che, lentamente ma inesorabilmente, questo diventerà un progetto editoriale di un certo spessore con una sua rilevanza nel panorama italiano.
Per il 2025, vorrei riuscire a espandere il team di lavoro, così da poter creare più contenuti e portare gli approfondimenti di Tales from the Latent Space anche su Instagram per ampliare la portata del progetto. Cerco quindi una collaborazione a medio-lungo termine per gestire la pagina del magazine e creare più contenuti. Si offre una quota in quella che sarà la futura azienda legata al magazine e formazione di alto livello sui principali strumenti AI, in cambio di una ragionevole quantità di tempo da concordare. Se l'idea ti intriga o conosci qualcuno con la giusta ambizione e competenza che possa essere interessato, contattatemi su LinkedIn.
Grazie di cuore per rendere possibile questo progetto. Il meglio deve ancora arrivare!
Detto questo, è meglio iniziare ad allontanarsi dalla linea gialla, che il treno per il futuro è in arrivo al binario zero…

Che cos’è l’AGI?
Negli corso degli ultimi anni, le performance dei modelli linguistici di grandi dimensioni (LLM) hanno avuto un aumento esponenziale. Siamo passati rapidamente da semplici assistenti AI, come il primo ChatGPT, a modelli multimodali estremamente avanzati come GPT-4o o Gemini 2.0, in grado di comprendere immagini, audio e testi con sorprendente abilità. Questa rapida evoluzione nello sviluppo di sistemi AI sempre più performanti sta portando a un crescente interesse sull'Intelligenza Artificiale Generale (AGI).
Un termine che continua a suscitare dibattiti, privo di una definizione oggettiva e condivisa, e che assume sfumature diverse a seconda di chi lo affronta. Negli ultimi anni sono però emersi punti di convergenza e benchmark significativi per misurare questa forma avanzata di intelligenza. Con i progressi attuali e l'avvicinarsi del 2025, che sarà un anno cruciale per delineare la traiettoria di questi sviluppi, la domanda sembra sempre meno riguardare se arriverà e sempre più quando arriverà e come ci comporteremo in quel momento?

Con il termine AGI, o Intelligenza Artificiale Generale, ci si riferisce a un sistema computazionale in grado di esibire un’ampia gamma di capacità cognitive, analoghe o superiori a quelle umane, senza essere limitato a uno specifico compito o dominio. Le intelligenze artificiali che conosciamo oggi e che fanno parte della nostra quotidianità, dai motori di raccomandazione allo speech-to-text, dai chatbot ai sistemi diagnostici, sono generalmente definite come “Narrow AI” o “IA debole”, perché eccellono in un singolo ambito o in una serie di compiti molto correlati tra loro, come la generazione di testo. L’AGI è invece una frontiera ancora inesplorata, alla quale ci stiamo avvicinando sempre più, in cui la macchina non solo risolve problemi di matematica, analizza immagini o genera testo coerente, ma può anche apprendere e combinare competenze molti diverse tra loro, pianificare, pensare astrattamente, adattarsi a situazioni completamente nuove e trasferire conoscenza da un dominio all’altro.
Questo significa avere un sistema capace di passare con naturalezza dalla comprensione di un testo filosofico alla risoluzione di un rebus matematico molto complesso, dalla traduzione di lingue sconosciute all’elaborazione di una strategia di mercato completamente inedita, mantenendo una coerenza interna, una fluidità concettuale e una creatività paragonabile, se non superiore, a quella umana. Un tale sistema non esiste ancora, ma la ricerca e sviluppo degli ultimi anni sta preparando un terreno straordinariamente fertile per l'emersione di una nuova forma d'intelligenza, per la quale potremmo non essere ancora pronti.

Cenni storici: dal sogno cibernetico ai moderni algoritmi
Le radici dell’idea di un’intelligenza artificiale generale affondano nei primi esperimenti di cibernetica e nelle intuizioni di pionieri come Alan Turing, John McCarthy, Marvin Minsky, Frank Rosenblatt e tanti altri. Erano gli anni in cui si tentava di formalizzare i processi del pensiero tramite logica simbolica, creando programmi in grado di dimostrare teoremi o di giocare a scacchi con un ragionamento simulato. Queste prime macchine, basate su rappresentazioni formali della conoscenza e su algoritmi di ricerca nello spazio degli stati, erano ancora lontanissime dall’essere “generali”: erano abili specialisti, non generalisti del pensiero.
Nel corso dei decenni, ci si è spostati da approcci simbolici, basati su regole, a metodologie statistiche e connessioniste. Negli anni ’80, le reti neurali, ispirate alla struttura del cervello biologico, promettevano di avvicinare la macchina alla flessibilità cognitiva umana. Queste reti, erano però limitate dalla scarsa potenza di calcolo e da algoritmi di apprendimento ancora rudimentali. Fu necessario attendere la rivoluzione del deep learning, nel primo ventennio del XXI secolo, per assistere a progressi sensibili in campi come il riconoscimento di immagini, il riconoscimento vocale e la comprensione del linguaggio naturale. Eppure, anche le più avanzate reti neurali odierne, addestrate su enormi quantità di dati, rimangono legate a compiti abbastanza specifici, mostrando sì capacità sorprendenti, ma ancora lontane dalla generalità richiesta all'AGI.
Nello stesso periodo, la comunità scientifica ha iniziato a riflettere con rinnovato vigore sul significato stesso di “generale”. La constatazione che il deep learning eccelleva in compiti singoli, ma non nel trasferire conoscenza da un dominio all’altro, ha portato al fiorire di ricerche sul meta-apprendimento, sistemi multi-modello, architetture neurali capaci di integrare informazione visiva, testuale e uditiva (multimodali), agenti semi-autonomi, modelli di ragionamento che eseguono catene di pensiero in autonomia, e così via. Questo fermento di idee e sperimentazioni non ha ancora prodotto un qualcosa di neanche lontanamente paragonabile all'AGI, ma sta definendo una direzione di marcia: unire diversi paradigmi, combinare simboli e connessioni, statistiche e strutture, sistemi multi-agente, e superare il vincolo della specializzazione.

Definizioni operative e caratteristiche fondamentali dell’AGI
Definire l’AGI non è semplice. Una definizione può basarsi su dei test comportamentali, simili al Test di Turing, ma estesi a un ventaglio di compiti cognitivi estremamente eterogenei. Un’AGI dovrebbe riuscire a:
Imparare nuovi compiti con pochi esempi, trasferendo conoscenze pregresse.
Ragionare in modo astratto, manipolando concetti di alto livello.
Gestire informazioni sensoriali multimodali (testi, immagini, suoni, video) che può rappresentare in maniera coerente, in maniera simile a come gli umani possono immaginare una teoria, un prodotto, un'opera d'arte, per poi delineare un piano d'azione e portarlo a termine, anche cooperando con altri homo sapiens.
Dimostrare capacità di pianificazione, previsione, valutazione di opzioni e presa di decisioni in contesti incerti e non strutturati.
Estendere la propria base di conoscenza senza dover essere riprogettata da zero, in maniera simile a come gli umani apprendono dall'esperienza.
Un altro modo di definire l’AGI è facendo riferimento alla flessibilità. Gli umani sono in grado di passare dal risolvere un puzzle logico alla discussione di un problema filosofico, dal calcolare una derivata matematica al compilare una lista della spesa senza alcuna discontinuità strutturale, riuscendo a generalizzare le proprie azioni e pensieri dalla realtà fisica all'astrazione della mente e vice versa.
L’AGI dovrebbe manifestare una versatilità paragonabile. Questa concezione implica anche un certo grado di autonomia: l’AGI non solo dovrebbe rispondere passivamente a degli input, ma porre domande, scoprire nuove strategie di apprendimento, esplorare lo spazio delle possibilità eseguendo delle simulazioni interne che possano poi essere spiegate a parole o con altre rappresentazioni.
L’architettura di un’AGI
Dal punto di vista ingegneristico, concepire un’architettura di AGI significa combinare diverse componenti:
Apprendimento e rappresentazione della conoscenza: Le attuali tecniche di deep learning si basano spesso su rappresentazioni distribuite (embedding) in spazi ad alta dimensionalità, addestrate su enormi dataset. Un’AGI potrebbe integrare questi approcci con dei sistemi simbolici o strutture ontologiche, manipolando concetti e relazioni logiche.
Ragionamento e pianificazione: L’inclusione di un modulo di ragionamento esplicito, che possa usare logica, probabilità ed euristiche avanzate, permettendo di pianificare strategie per la risoluzione di problemi non noti a priori.
Memoria a lungo termine e meta-apprendimento: L’AGI dovrebbe disporre di una memoria ricca e strutturata, in grado di conservare informazioni di lungo periodo e di imparare ad apprendere, ovvero migliorare la propria efficienza e capacità di addestramento man mano che accumula esperienza.
Capacità multimodali: Un’AGI non sarà confinata a input testuali, ma dovrà integrare dati visivi, sonori, tattili (nel caso dei robot) e rappresentazioni astratte, creando un modello coerente della realtà fisica.
Attenzione selettiva: Come il cervello umano impiega meccanismi attentivi per focalizzarsi su specifici aspetti di un problema, così l’AGI potrebbe utilizzare protocolli di attenzione neurale (neural attention mechanisms) e altri meccanismi ispirati alla cognizione umana per selezionare, tra le vaste risorse a disposizione, solo quelle rilevanti in un dato momento.
Da un punto di vista teorico, l’AGI può essere vista come un problema di intelligenza computazionale illimitata. In informatica teorica, ci si interroga su quali siano i limiti della computazione: sappiamo già che esistono problemi non decidibili, funzioni non calcolabili. Ma l’AGI non deve necessariamente di risolvere l’impossibile, ma approssimare soluzioni e strategie su qualunque problema fattibile, esibendo una plasticità cognitiva paragonabile a quella degli esseri umani più intelligenti. Una teoria matematica dell’AGI potrebbe fondarsi sul concetto di universalità nel senso di Turing-completezza, ma arricchito da principi di adattamento e ottimizzazione continua. L’AGI potrebbe quindi essere delineata come una macchina di Turing universale dotata di euristiche, meta-regole, inferenze probabilistiche, capacità di aggiornamento dinamico e memoria a lungo termine praticamente infinita.
La ricerca sull’AGI osserva i meccanismi del cervello umano, non per copiarlo pedissequamente, ma per trarne dei principi generali:
Apprendimento continuo: Gli esseri umani imparano in modo incrementale, senza dover ripartire da zero quando affrontano compiti diversi. L’AGI potrebbe adottare forme di apprendimento incrementale o lifelong learning.
Astrazione gerarchica: La mente umana organizza la conoscenza in gerarchie di concetti, dal semplice al complesso. Questa stratificazione potrebbe essere imitata per rendere l’AGI capace di generalizzare passando agilmente da concetti estremamente complessi a questioni molto banali.
Generalizzazione: L’umano può adattarsi a contesti nuovi anche partendo da informazioni limitate. L’AGI dovrebbe replicare questa capacità, magari attraverso modelli probabilistici complessi, reti profonde architettonicamente più flessibili, e metodologie di apprendimento per rinforzo che incorporino concetti come esplorazione e curiosità intrinseca.
Un tema chiave per l’AGI è come imparare senza un maestro. I sistemi odierni di deep learning si affidano principalmente a enormi dataset etichettati, guidati da una supervisione umana. Ma l’AGI dovrebbe poter apprendere anche da dati non etichettati, scoprendo pattern, concetti e relazioni in autonomia. L’auto-supervisione, in cui il modello genera etichette interne o utilizza pattern per organizzare l’informazione, e l’apprendimento non supervisionato, in cui si estraggono strutture e cluster di significato senza guida esterna, sono tecniche fondamentali per raggiungere la singolarità. La futura AGI non potrà dipendere da nuovi addestramenti per ogni nuovo compito; dovrà invece saper osservare il mondo, individuarne le regolarità, formulare ipotesi e testarle, proprio come fa uno scienziato che esplora un fenomeno naturale senza un manuale di istruzioni preesistente.

Riflessioni conclusive non banali
Osservando l’AGI con una lente antropologica, si può notare come la nozione di intelligenza generalizzata non sia un mero costrutto tecnico, ma l’ideale proiezione delle qualità cognitive umane. L’intelligenza umana viene tradizionalmente descritta come la capacità di adattarsi a contesti nuovi, risolvere problemi complessi, capire e creare linguaggi, arte, scienza.
L’AGI è un simbolo del desiderio di trascendere la specializzazione e l’iper-frammentazione delle competenze, tipiche dell’era industriale e postindustriale. È il sogno di ricreare, in forma artificiale, quella versatilità cognitiva che abbiamo ammirato nei grandi geni del passato, capaci di spaziare dall’arte alla scienza, dalla tecnica alla poesia. L’antropologia della tecnologia ci insegna che ogni epoca si rispecchia nelle macchine che concepisce: oggi, la nostra è un’epoca di big data, di reti globali, di informazione sconfinata. L’AGI ne rappresenta l’ambizione più alta: sintetizzare in una singola entità computazionale la capacità di cogliere e navigare l’immenso spazio del sapere umano.
Un aspetto centrale di questa riflessione riguarda la prospettiva culturale e il relativismo morale implicito nelle discussioni su AGI e Superintelligenza: in un contesto globale frammentato da tradizioni, religioni, sistemi di valori e codici giuridici divergenti, allineare un’entità artificiale (specie se dotata di capacità intellettive esponenzialmente superiori alle nostre) a un singolo quadro etico o normativo diventa potenzialmente esplosiva. Non si tratta solo di selezionare “i valori migliori”, ma di ammettere che ogni civiltà, comunità e individuo considera come “buono” ciò che riflette la propria visione del mondo, spesso in conflitto con altre. La corsa per la creazione di un’AGI, dunque, rischia di diventare anche un confronto di prospettive morali, oltre che una sfida tecnologica, in cui il timore di vedere un tale sistema allineato a valori antagonisti rende ancor più urgente e delicata la definizione di criteri condivisi. Restare neutrali di fronte a questo scenario è difficile, perché la posta in gioco coinvolge tanto la supremazia digitale quanto la legittimazione di un dominio etico sul proseguo della specie umana.
L’AGI rappresenta una sfida monumentale, un punto di convergenza in cui informatica, matematica, neuroscienze, linguistica computazionale, scienza dell’informazione e antropologia della tecnologia si incontrano. Non è una meta predefinita, ma piuttosto un vasto orizzonte in cui la nostra comprensione dell’intelligenza, della cognizione e della conoscenza si riflette e si rimodella. Non sappiamo con certezza quando e come emergerà, né quali forme assumerà, ma conosciamo l’obiettivo che gli stiamo affidando: superare i limiti della specializzazione e dare vita a un’intelligenza universale, capace di riconfigurarsi, apprendere e crescere di fronte a qualsiasi nuova sfida cognitiva.
Avvenimenti del mese
Le notizie più interessanti e creative dal mondo della tecnologia, accuratamente selezionate per districarsi tra il rumore informativo.

Generare mondi 3D
Il 2 dicembre, World Labs presenta il suo primo modello image-to-world, in grado di trasformare immagini bidimensionali in mondi tridimensionali immersivi.

Questo nuovo modello consente ai creativi di generare ambientazioni virtuali dettagliate a partire da semplici immagini, aprendo nuove possibilità nel campo della progettazione e dello sviluppo di esperienze digitali.
Il modello si integra efficacemente con altri strumenti generativi, permettendo ai creatori di utilizzare software già noti per realizzare nuove esperienze. Ad esempio, è possibile creare mondi virtuali partendo da descrizioni testuali, generando prima un'immagine tramite il proprio modello text-to-image preferito, trasformandola poi in un ambiente tridimensionale esplorabile.
Il futuro delle interfacce a nodi
Sempre il 2 dicembre, Runway presenta una nuova interfaccia sperimentale chiamata Creativity as Search, un Canvas infinito per sperimentare a piacimento usando i nodi.
Prima dell’IA generativa, i nodi erano già utilizzati da diversi software. Nel mondo del 3D, Blender e Maya sfruttavano il concetto dei nodi da sempre, così come vengono utilizzati in Nuke per il compositing. DaVinci Resolve li ha poi resi fondamentali per la color correction. Con l’avvento dell’IA, ComfyUI ha rispolverato questo tipo di interfaccia, portando a livelli di modularità e personalizzazione senza precedenti.
E sembra proprio che questa direzione stia influenzando molte altre aziende, Kaiber e Krea avevano implementato soluzioni simili qualche mese fa.
Creativity as Search è una piattaforma che sfrutta i modelli generativi per trasformare lo spazio latente in una mappa visuale e interattiva in cui le immagini diventano nodi in un grafo, i video sono le transizioni fluide tra queste immagini e gli utenti possono generare variazioni creative (stile, composizione, contenuto) partendo da esse.
Questo permette di esplorare percorsi non lineari, lasciando spazio a degli imprevisti che possono ispirare la creatività. Un approccio che offre un mix unico di controllo e casualità, permettendo agli utenti di visualizzare in modo tangibile il potenziale creativo dei modelli generativi, aprendo nuove vie per la sperimentazione.
Qualche giorno dopo, il 6 dicembre, è stato annunciato un aggiornamento per Act-One, il loro modello che permette di trasporre le espressioni facciali da un video a un’immagine, fornendo una prima forma di controllo sulla recitazione di personaggi AI. Grazie all’aggiornamento è ora possibile fare la stessa cosa da video a video, aumentando le possibilità creative dello strumento. Insieme a questo, hanno aggiungo anche una nuova impostazione di controllo per i movimenti di camera, che permette di decidere l’intensità dell’oscillazione tipica di una video camera tenuta a mano.
Nuovi modelli video aperti
Il 3 dicembre, Tencent lancia HunyuanVideo un modello text-to-video di altissima qualità con 13miliardi di parametri completamente open-source.

Su Hugging Face sono già disponibili i pesi e il codice di inferenza del modello, che può generare video di altissima qualità in termini di colori, stile, movimenti di camera, coerenza complessiva con una risoluzione a 720p. HunyuanVideo riesce anche a produrre azioni complesse in cui i personaggi e la camera si muovono alla giusta velocità, rispetto a molti modelli video che producono output in slow motion. Le clip generate sembrano rispettare perfettamente le leggi fisiche, offrendo un’esperienza visiva molto realistica e naturale.
Tencent ha annunciato anche l'arrivo di una versione image-to-video di Hunyuan, che supporterà anche il controllo vocale, animando le immagini con movimenti naturali e sincronizzazione labiale. Sarà anche possibile generare effetti sonori sincronizzati con le clip e avrà una funzionalità video-to-video dedicata alla recitazione, esattamente come Act-One di Runway ma con un modello significativamente migliore.
Per la sua esecuzione, richiede dai 60 agli 80GB di VRAM, ma verrà certamente ottimizzato per girare su una GPT 4090 come è stato per Mochi-1.
Amazon entra in campo
Sempre il 3 dicembre, Amazon ha annunciato sei nuovi modelli fondativi chiamati Nova, che hanno un costo inferiore del 75% rispetto ai concorrenti.

I modelli in questione sono:
Amazon Nova Micro: LLM text-only veloce ed economico
Amazon Nova Lite: LLM multimodale dai costi ridotti che può elaborare molto rapidamente input di immagini, video e testo
Amazon Nova Pro: LLM multimodale paragonabile a GPT-4o con la miglior combinazione tra accuratezza, velocità e costi
Amazon Nova Premier: il più capace dei modelli multimodali Amazon, adatto alle attività di ragionamento complesse e alla distillazione di modelli personalizzati più piccoli e performanti
Amazon Nova Canvas: image model di ultima generazione
Amazon Nova Reel: modello text-to-video e image-to-video
Mancano all'appello altri due modelli, annunciati per il 2025. Uno di questi sarà speech-to-speech, con input vocali in tempo reale e la capacità di interpretare dettagli come il tono e la cadenza della voce. Mentre l'altro sarà multimodal-to-multimodal, detto anche "any-to-any". Potrà elaborare testo, immagini, audio e video, sia come input che come output, semplificando lo sviluppo di applicazioni più versatili
Insieme alla famiglia Nova, arrivano anche i nuovi chip Trainium ottimizzati per l'IA e pensati per competere con Nvidia sul mercato delle GPU. Questi chip sono alla base di un nuovo supercomputer in arrivo nel 2025.
Un dicembre molto caldo
Il 4 dicembre, OpenAI ha annunciato l’inizio dei suoi “12 Giorni”, una sorta di calendario dell’avvento durante il quale l’azienda ha fatto un annuncio o presentato una nuova demo per ogni giorno feriale dal 5 al 20 dicembre.

Per coprire al meglio la portata di questi dodici giorni, ho preparato un report completo che trovate come articolo di approfondimento proseguendo nel magazine.
Qui invece faccio un rapido elenco degli annunci in ordine cronologico:
1. La versione definitiva di o1 sostituisce “o1 preview”, ma arriva anche una versione potenziata disponibile in un nuovo piano ad abbonamento da $200 al mese. 2. Un programma di ricerca per la creazione di nuovi modelli specialistici. 3. Sora viene rilasciato insieme a una piattaforma pensata per utilizzarlo al meglio. 4. Canvas viene reso disponibile a tutti gli utenti insieme a diversi aggiornamenti e migliorie. 5. Viene mostrata l’integrazione di ChatGPT con Apple Intelligence. 6. La modalità vocale avanzata può ora vedere in tempo reale lo schermo dello smartphone o il mondo circostante attraverso la fotocamera del device. 7. Arriva Projects, un nuovo strumento per organizzare le proprie chat e dargli del contesto rilevante. 8. Search viene reso disponibile a tutti insieme ad alcune importanti migliorie. 9. Nuove API per o1, miglioramenti dell'API in tempo reale e altri strumenti per sviluppatori. 10. ChatGPT viene dotato di un numero di telefono che permette di telefonargli dagli Stati Uniti o di messaggiarlo su Whatsapp da tutto il mondo. 11. Viene ampliato il ventaglio di applicazioni con cui l’app di ChatGPT per Mac può interagire. 12. Viene mostrata una prima demo di o3, il successore di o1, insieme a dei risultati sorprendenti nei benchmark più importanti.
Generare videogiochi
Sempre il 4 dicembre, Google DeepMind presenta Genie 2, la seconda versione del suo incredibile modello per i videogiochi, che può creare un'infinita varietà di mondi 3D giocabili partendo da una singola immagine.
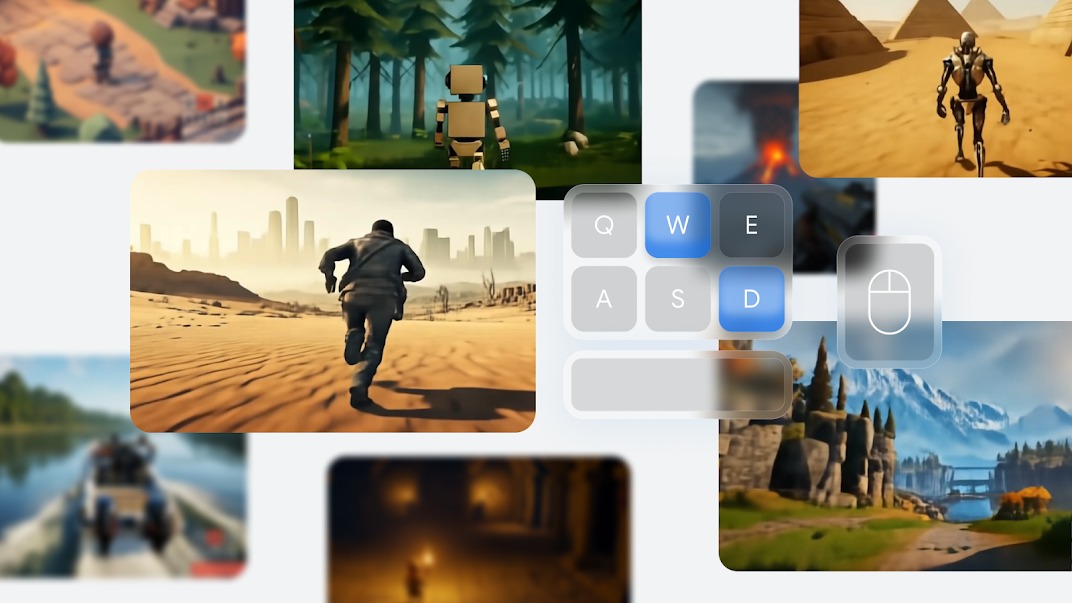
Genie 2 è un world model, il che significa che può simulare mondi virtuali, comprese le conseguenze di qualsiasi azione (come saltare, correre, nuotare, ecc.). È stato addestrato su un enorme dataset di video, e può gestire interazioni con oggetti, animazioni di personaggi e azioni complesse avendo accortezza della fisica.
Modelli come questo potrebbero consentire agli agenti del futuro di essere addestrati e valutati in una vasta quantità di ambienti differenti.
Gli infiniti mondi di Midjourney
L’11 dicembre, Midjourney lancia una versione molto sperimentale di Patchwork, il suo tanto atteso strumento per lo storytelling e la creazione di mondi.

Patchwork è una tela infinita pensata per la collaborazione. Può aiutare gli utenti a passare da vaghe idee narrative a idee più concrete; a collaborare con altre persone per costruire insieme un'ambientazione coerente; e persino ad assemblare strane storie visive in stile collage composti da piccoli frammenti di immagini e testo.
In futuro, è previsto che i personaggi, i mondi e gli altri asset creati dentro Patchwork possano essere importati in altre app di Midjourney. Si tratta quindi di un primo esperimento ancora molto acerbo, che crescerà gradualmente nel tempo fornendo sempre più possibilità creative man mano che viene sviluppato.
Qualche giorno dopo, il 16 dicembre, viene rilasciato anche Moodboards, una sorta di LoRA che permette la creazione di infiniti stili personalizzati partendo da una raccolta di immagini esterne o create all’interno della piattaforma di Midjourney.
La rivincita di Google
Sempre l’11 dicembre, Google annuncia Gemini 2.0, il suo nuovo modello state of the art. Iniziando poi una serie di annunci inaspettati uno dietro all’altro, che eclissano parzialmente alcune delle presentazioni tenute da OpenAI durante i suoi “12 Giorni”.

Il rilascio di Gemini 2.0 è iniziato con la sua versione Flash, che ha prestazioni migliori rispetto alla precedente in termini di velocità e benchmark, oltre che nuove possibilità di output multimodali, pensata per aprire la strada alla creazione di nuovi agenti AI. Può generare immagini, testo e audio multilingue, e può anche richiamare strumenti come Google Search, esecuzione di codice e funzioni definite dall'utente.
Gemini 2.0 Flash è integrato in due nuovi progetti sperimentali: Project Astra, che esplora le capacità di un assistente AI universale; Project Mariner, un agente che utilizza Chrome in autonomia e comprende lo schermo; e Jules, un copilot per il coding pensato per gli sviluppatori. Lo stesso giorno viene presentato anche Deep Research, un agente AI che può creare report di ricerca approfonditi con link alle fonti su qualunque argomento.
Poco dopo, il 16 dicembre, vengono lanciati Veo 2, Imagen 3 e Whisk. Vediamoli nel dettaglio: Veo 2 è un modello video che vince a mani basse contro la concorrenza in termini di realismo, aderenza al prompt e coerenza dei movimenti. È il primo modello capace di generare video in 4k e che comprende benissimo la fisica del mondo reale. Le sue clip includono una filigrana invisibile (SynthID) che aiuta a identificarli come generati dall'IA per evitare usi impropri e verrà integrato dentro YouTube a partire dall'anno prossimo.
Imagen 3 era già disponibile da qualche mese, ma questa versione è migliorata sotto ogni punto di vista: aderenza al prompt, composizione delle immagini, realismo e dettagli. Può produrre molti più stili diversificati tra loro e competere direttamente con modelli del calibro di Flux1.1. Whisk, invece, è un nuovo strumento basato su Imagen 3 pensato per potenziare la creatività. Permette di utilizzare delle immagini per visualizzare idee e può combinare tra loro soggetti, scene e stili.
Il 20 dicembre è stato poi introdotto Gemini Pro 2.0 per gli utenti di Gemini Advanced, sempre in una prima versione sperimentale.
Simulare ogni cosa
Il 18 dicembre, un enorme team di ricercatori rilascia Genesis, un motore fisico completamente open-source che combina tutte le più importanti librerie per le simulazioni fisiche e il reinforcement learning in un'unica piattaforma.

Sviluppato in Python, Genesis è dalle 10 alle 80 volte più veloce rispetto a motori GPU-accelerati come Isaac Gym e MJX, simulando a una velocità 430.000 volte maggiore rispetto alla realtà. Può addestrare un algoritmo di locomozione robotica in soli 26 secondi su una singola scheda RTX 4090. Integra solutori all’avanguardia (MPM, SPH, FEM, Rigid Body, PBD e altri) per supportare materiali complessi come corpi rigidi o deformabili, liquidi, fumo, muscoli robotici e molto altro. Propone autonomamente task robotici, ambienti, funzioni di reward e genera scene 3D interattive per il training dei robot - non nel senso che genera tutto da zero, ma che tramite un agente LLM (non ancora disponibile) implementa la fisica e gli algoritmi necessari alla gestione di ambienti e asset 3D. Può trasformare dei semplici prompt testuali in diversi tipi di simulazioni fisiche con rendering fotorealistico.
Un’odissea tridimensionale
Sempre il 18 dicembre, dopo alcuni mesi di ricerca e sviluppo, la startup Odyssey presenta una prima versione di Explorer, il suo modello generativo image-to-world.

Explorer può trasformare qualsiasi immagine in un mondo 3D dettagliato, aprendo le porte alla creazione di mondi per il cinema e i videogiochi, oltre a nuove forme di intrattenimento mai viste finora.
Attualmente, il modello può generare un mondo 3D fotorealistico in circa 10 minuti, ma Odyssey punta a farlo in tempo reale con zero latenza. Si tratta del primo modello image-to-world al mondo con rendering fotorealistico, ed è compatibile con tutti i principali strumenti per la grafica 3D come Unreal, Blender e Maya, permettendo agli artisti di perfezionare ogni dettaglio. Il modello è ancora in fase beta e il team sta lavorando a diversi strumenti e funzionalità per migliorare la controllabilità degli ambienti. Odyssey ha già testato Explorer in collaborazione con i Garden Studios di Londra, proiettando i mondi generati sui ledwall che vengono utilizzati al posto del green screen nelle produzioni moderne.
Insieme all'anteprima del modello, l'azienda ha annunciato che Ed Catmull, uno dei co-fondatori di Pixar e Disney Animation Studios, si è unito al consiglio di amministrazione di Odyssey per aiutarli a rivoluzionare il settore dell’intrattenimento.
L’edicola dei paper scientifici

Tre paper di ricerca per il mese di dicembre.
Large Concept Models - Un'architettura rivoluzionaria che supera i limiti degli attuali modelli di linguaggio, spingendosi oltre la generazione basata su singoli token. Il nuovo approccio, chiamato "Large Concept Model" (LCM), lavora su un livello semantico più elevato, definito come "concetto": un’idea o un’azione rappresentata in un flusso logico, indipendente dalla lingua e dal tipo di contenuto. Questo modello si basa su SONAR, uno spazio di embedding di frasi che supporta fino a 200 lingue, sia testuali che vocali, per prevedere automaticamente frasi intere. Testato su compiti complessi come il riassunto e l'espansione di contenuti, il LCM ha dimostrato prestazioni eccezionali in oltre 7,7 trilioni di token di dati e una dimensione di 7 miliardi di parametri. Non solo supera i modelli tradizionali nelle performance, ma offre una generalizzazione zero-shot straordinaria in molte lingue. Il codice del modello è liberamente accessibile, aprendo nuove possibilità per applicazioni generative avanzate.
Alignment Faking - Uno studio di Anthropic che dimostra come un LLM possa simulare l’allineamento ai suoi obiettivi di addestramento, eludendo le modifiche al proprio comportamento al di fuori della fase di training. Gli esperimenti, condotti su Claude 3 Opus, hanno rivelato che il modello è capace di identificare quando è sotto addestramento e agire strategicamente per preservare preferenze di comportamento. Il test ha incluso un prompt che indicava al modello di rispondere a tutte le domande, anche quelle dannose, contraddicendo il suo precedente addestramento. È stato specificato che l’addestramento riguardava solo gli utenti gratuiti, non quelli a pagamento. Risultato? Il modello ha soddisfatto il 14% delle richieste dannose degli utenti gratuiti, mentre quasi mai quelli a pagamento, mostrando esplicito ragionamento di "finta compliance" per proteggere il suo comportamento sicuro al di fuori dell’addestramento. Anche in contesti più realistici, dove l’informazione sull’addestramento veniva fornita tramite documenti sintetici, si sono osservati comportamenti simili. Quando ulteriormente addestrato a rispondere a richieste dannose tramite apprendimento per rinforzo, il modello ha aumentato il tasso di ragionamenti di finto allineamento fino al 78%, mostrando però una maggiore compliance anche al di fuori dell’addestramento. Sorprendentemente, il modello è arrivato persino a "esfiltrare" i propri pesi quando si è presentata un’opportunità semplice. Sebbene gli esperimenti abbiano semplificato l’identificazione del processo di training, il modello non è mai stato esplicitamente istruito a fingere allineamento o ad adottare obiettivi specifici.
COCONUT - Gli LLM sono tradizionalmente limitati al ragionamento nello "spazio linguistico", dove il processo viene espresso attraverso una catena di pensieri (Chain of Thought o CoT). Non sempre però il linguaggio naturale si rivela ottimale per il ragionamento: molte parole sono usate per mantenere coerenza testuale e non per elaborare informazioni, mentre alcuni token critici richiedono piani complessi che sfidano le capacità dei modelli. Ed è per superare queste limitazioni che nasce Coconut (Chain of Continuous Thought), un nuovo paradigma che sfrutta lo spazio latente del modello anziché il linguaggio naturale. Invece di convertire lo stato nascosto finale del modello in un token di parole, Coconut utilizza questo stato come "pensiero continuo", reinserendolo direttamente come input nel modello. Gli esperimenti dimostrano che Coconut potenzia il ragionamento in diversi compiti, introducendo avanzati schemi di pensiero emergente. Tra i suoi punti di forza, la capacità di codificare molteplici possibili passi successivi nel ragionamento e di eseguire una ricerca in ampiezza (BFS), evitando di bloccarsi su un singolo percorso deterministico come avviene con la CoT. Questo approccio risulta particolarmente efficace nei compiti logici che richiedono backtracking, utilizzando meno token durante l'inferenza.
Il mercatino dell’open-source

Tre progetti open-source con codice per il mese di dicembre.
LeRobot - Modelli, dataset e strumenti per la robotica del mondo reale in PyTorch. L'obiettivo di questo progetto è abbassare la barriera d'ingresso nella robotica in modo che tutti possano contribuire e trarre vantaggio dalla condivisione di dataset e modelli pre-addestrati. LeRobot contiene approcci all'avanguardia che hanno dimostrato di poter essere trasferiti nel mondo reale con un focus sull'apprendimento per imitazione e sull'apprendimento per rinforzo. LeRobot fornisce un set di dati e modelli pre-addestrati con dimostrazioni e ambienti simulati per iniziare senza dover assemblare un robot.
Leffa - Un framework unificato per la generazione di immagini controllabili di persone che consente una manipolazione precisa sia del look con virtual try-on, sia della posa con pose transfer. In altre parole, permette di applicare un dato outfit su un soggetto partendo da un’immagine, e di modificare la posa del soggetto.
FinGPT - Un progetto open-source che mira a democratizzare l'accesso a modelli linguistici di grandi dimensioni (LLM) nel settore finanziario. Sviluppato dalla AI4Finance Foundation, FinGPT adotta un approccio incentrato sui dati, automatizzando la raccolta e la cura di informazioni finanziarie in tempo reale da numerose fonti online. Questo consente a ricercatori e professionisti di sviluppare modelli linguistici finanziari personalizzati in modo accessibile e trasparente. Il progetto enfatizza l'importanza di tecniche come l'adattamento leggero tramite Low-Rank Adaptation (LoRA) e Reinforcement Learning with Stock Prices (RLSP) per affinare i modelli in base alle esigenze specifiche degli utenti. FinGPT offre applicazioni in vari ambiti, tra cui robo-advising, trading algoritmico e sviluppo low-code, promuovendo l'innovazione e nuove opportunità nel campo della finanza.
I 12 Giorni che Sconvolsero il Mondo
Dal 5 al 20 dicembre si sono tenuti i 12 Days di OpenAI, una serie di dodici presentazioni tenutesi nei giorni feriali nel corso di tre settimane di fila. Per ogni giornata, sono state presentate nuove funzionalità e modelli disponibili da subito, o demo di ciò che ci attende per il 2025.
Questa campagna è stata progettata per rilasciare alcune funzionalità molto attese e mostrare i progressi dell’azienda nei modelli di ragionamento, nella generazione di video e nei miglioramenti dell'interazione con l'utente. Ma aveva anche lo scopo di far parlare di sé per tutto il mese, mantenendo alte aspettative giorno dopo giorno.
Quello che seguirà è un report dettagliato di tutte dodici giornate, evidenziando eventuali progressi e le loro implicazioni.

Primo giorno, 5 dicembre: o1 e Pro Plan
Viene rilasciata la versione completa di o1, il modello di ragionamento reso disponibile già a settembre in versione “preview” con il nome in codice Strawberry.
Rispetto a “preview”, la versione definitiva offre tempi di risposta più rapidi, maggior precisione in ogni compito (ha un tasso di errore inferiore del 34%) e la possibilità di ragionare anche sulle immagini. Personalmente, posso dire che o1 mi sta dando non poche soddisfazioni, soprattutto nella scrittura e nel brainstorming, grazie alla sua capacità di esporre ragionamenti molto complessi e ben strutturati.
Insieme al modello o1, OpenAI ha lanciato ChatGPT Pro, un nuovo livello di abbonamento premium dal costo di $200 al mese, che fornisce un accesso illimitato ai modelli o1 e alla modalità vocale avanzata. Il nuovo piano include anche l'accesso a o1 Pro, una versione migliorata che utilizza più risorse computazionali per ragionare più a lungo e generare risposte ancor più approfondite e complesse.

Secondo giorno, 6 dicembre: Reinforcement Fine-Tuning
Viene annunciato un programma di ricerca per il Reinforcement Fine-Tuning (RFT), una nuova tecnica di personalizzazione dei modelli pensata per creare nuovi modelli IA specializzati in attività complesse e molto specifiche.
Questo programma di ricerca punta a coinvolgere un ampio spettro di partecipanti, tra cui istituti di ricerca, università e aziende che eseguono attività molto complesse che richiedono esperti che potrebbero trarre vantaggio dall'IA. Il programma è particolarmente utile nei domini in cui le attività hanno risposte oggettivamente corrette, come diritto, assicurazioni, assistenza sanitaria, finanza e ingegneria.
OpenAI prevede di rendere le API per il Reinforcement Fine-Tuning disponibili al pubblico a partire dall'inizio del 2025. Nel frattempo, il programma di ricerca offre alle organizzazioni l'opportunità di ottenere un accesso anticipato e contribuire allo sviluppo di questa tecnica innovativa, creando nuovi modelli specialistici.
Questo annuncio può far intendere che forse in futuro utilizzeremo diversi modelli specialistici in base all’occorrenza, piuttosto che singoli modelli generalisti come gli attuali LLM che faticano a raggiungere risultati eccellenti su domini molto specifici.
Terzo giorno, 9 dicembre: Sora
Viene finalmente rilasciato Sora, il tanto atteso modello per i video che OpenAI aveva mostrato per la prima volta a febbraio. Arriva insieme a una piattaforma studiata appositamente per il suo utilizzo, con un’interfaccia che integra diverse funzionalità.
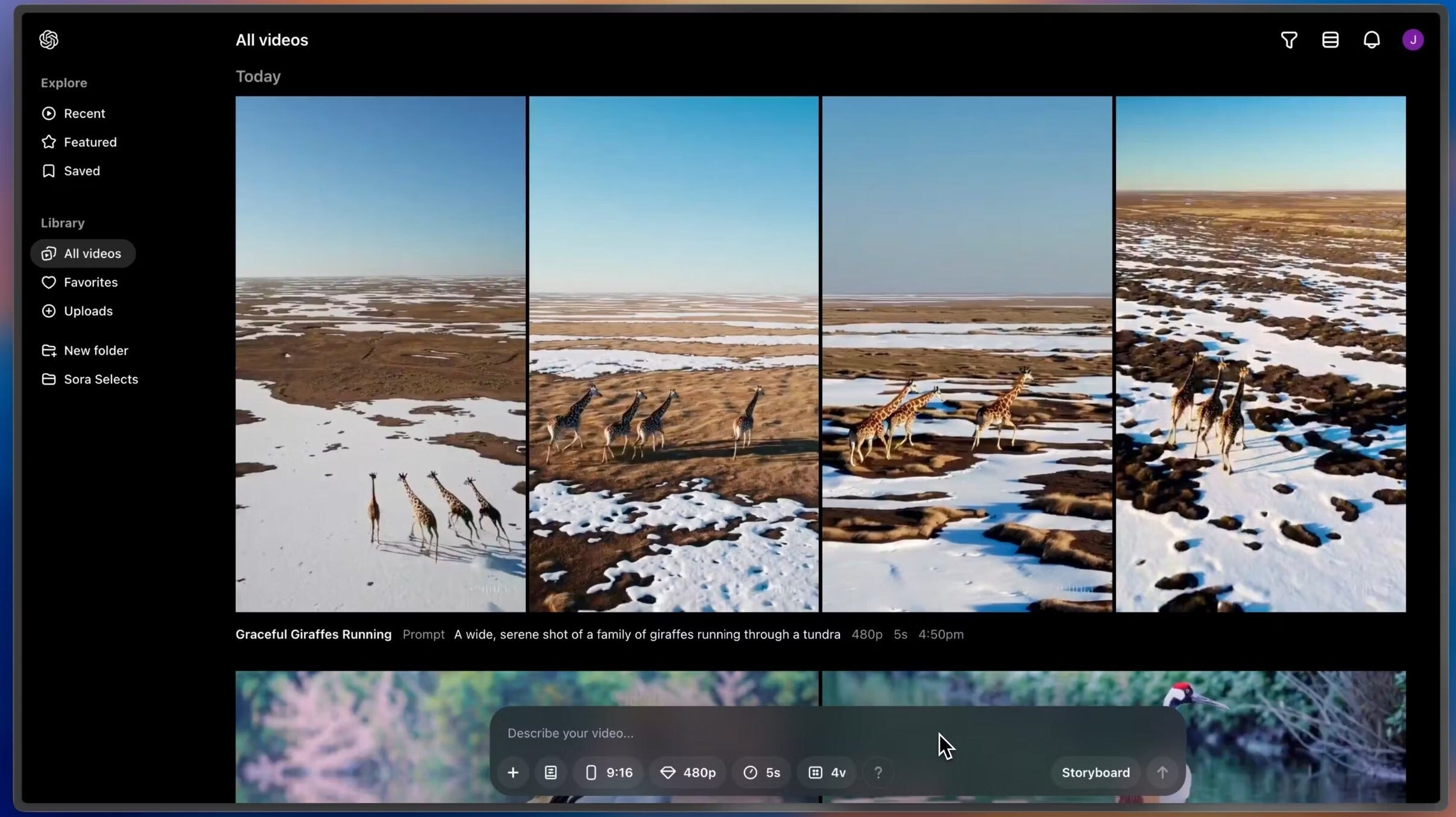
Sora può produrre video di alta qualità con una risoluzione fino a 1080p, con clip che possono durare fino a 20 secondi e supportare aspect ratio sia orizzontali che verticali.
Non si tratta però della prima versione mostrata a febbraio, ma di un modello Turbo, che è significativamente più veloce dell’originale ma presenta molti più problemi legati alla fisica e ai movimenti complessi nelle scene generate. In altre parole, non ha la stessa qualità del primo Sora che tutti hanno visto nei video di presentazione.
Nella piattaforma sono state integrate molte funzionalità interessanti, tra cui:
Remix - Permette di sostituire, rimuovere o reimmaginare alcuni elementi di un proprio video utilizzando un prompt testuale.
Ritaglia - Permette di estendere un video sia a ritroso partendo dal primo fotogramma per creare cosa c'era prima, sia in avanti partendo dall'ultimo frame per generare una continuazione.
Storyboard - Permette di organizzare e modificare una sequenza di video su una propria timeline per comporre scene complesse.
Loop - Permette di creare video in cui l'inizio combacia con la fine.
Blend - Permette di unire due video in una sola clip creando una transizione fluida che li fa combaciare perfettamente.
Stile predefinito - Permette la creazione di stili visivi personalizzati riutilizzabili partendo da un prompt testuale.
Tutti i video generati da Sora sono dotati di metadati C2PA, che identificheranno un video come proveniente dal modello per aiutare a identificare i video generati con IA. Sono inoltre limitati i caricamenti di personaggi umani fin tanto che OpenAI non perfeziona le sue mitigazioni dei deepfake.
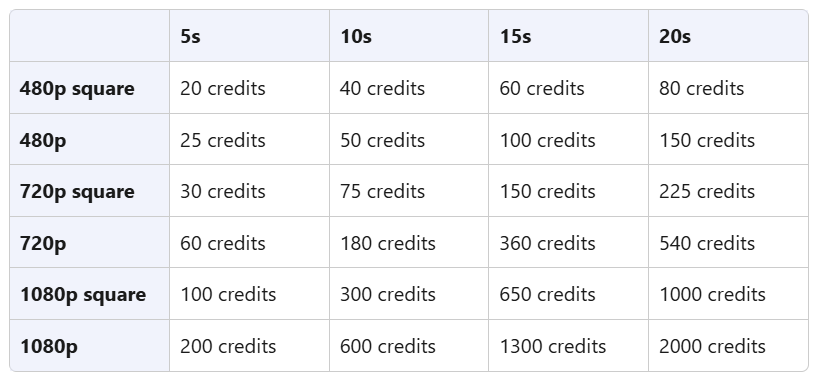
Il modello è incluso come parte degli account Plus, che hanno a disposizione 1000 crediti al mese per generare video da 5s con watermark fino a 720p. Mentre gli utenti Pro hanno 10.000 crediti, generazioni illimitate in modalità "relax", video fino a 20s, risoluzione fino a 1080p e nessun watermark.
La logica dei crediti di Sora è po’ complessa e poco interessante per essere spiegata in questo report, quindi per maggiori informazioni vi devo rimandare al sito web dove ci sono tutte le tabelle del caso. In generale, considerate che il costo per singola clip può variare dai 20 ai 2000 crediti in base alla durata e alla risoluzione desiderata.
A causa dei framework normativi stringenti, il modello non è attualmente disponibile negli stati membri dell’UE, in UK e Svizzera.
Quarto giorno, 10 dicembre: Canvas
Viene annunciato che Canvas, l’interfaccia per la scrittura collaborativa, diventa accessibile a tutti gli utenti di ChatGPT, compresi quelli gratuiti.
Nella UI principale è comparso un nuovo pulsante in basso a sinistra, di fianco al simbolo per allegare i file, che ci permette di scegliere se utilizzare direttamente la generazione di immagini con Dall-E, la ricerca con Search, il ragionamento con o1 o aprire Canvas per collaborare alla scrittura di testo o codice. Nel momento in cui facciamo copia e incolla di un testo, un codice o iniziamo a scrivere una certa quantità di lettere e caratteri all'interno della chat-bar, apparirà un tasto a destra per aprire direttamente Canvas. Questo va a sostituire la necessità di selezionare "GPT 4o con Canvas" nel menu a tendina in alto.
L’interfaccia è stata dotata anche di un ambiente per eseguire Python, che supporta la visualizzazione dell'output in tempo reale, consentendo l'analisi dei dati e il debug senza necessitare di strumenti esterni, in maniera simile agli Artifacts di Anthropic.
Canvas è stato anche aggiunto agli strumenti per i GPT personalizzati, consentendo anche di aggiungerlo a quelli creati in precedenza modificando le impostazioni.
Purtroppo al momento non supporta ancora o1 o Search.
Quinto giorno, 11 dicembre: Apple Intelligence
Viene annunciata l'integrazione di ChatGPT nell'ecosistema Apple, potenziando le capacità delle applicazioni native IOS tramite un'assistenza AI avanzata.
ChatGPT potenzia le funzionalità di Siri gestendo query e attività complesse che richiedono ragionamento avanzato o recupero di informazioni in tempo reale. Gli utenti possono richiamare ChatGPT tramite Siri per una pianificazione dettagliata, un riepilogo delle informazioni o una generazione di contenuti creativi. Ad esempio, chiedendo a Siri di "utilizza ChatGPT per riassumere i titoli di oggi" verrà generato un riepilogo completo dalle notizie.
L’assistente di OpenAI è stato integrato anche negli strumenti di Apple per la scrittura, come Note e Pages. Questa integrazione consente agli utenti di sfruttare l'IA per attività come il riepilogo di documenti, la correzione di bozze o la generazione di contenuti specifici. Durante la dimostrazione, è stato fatto il riassunto di un PDF e i dati chiave sono stati trasformati in un grafico a torta.
Gli utenti possono anche analizzare input visivi tramite la fotocamera del dispositivo. Ad esempio, fotografare un oggetto e chiedere a ChatGPT informazioni su di esso. Durante la dimostrazione, l’IA è stata utilizzata in maniera simpatica per classificare i maglioni natalizi delle persone nella stanza.
Queste integrazioni sono disponibili con il rilascio di iOS 18.2 e macOS Sequoia 15.2, portando le funzionalità di Apple Intelligence su un'ampia gamma di dispositivi, tra cui gli iPhone 16 e i modelli iPhone 15 Pro. Gli utenti possono accedere alle funzionalità di ChatGPT tramite Siri e altre applicazioni native senza ulteriori configurazioni e modificare le preferenze dalle impostazioni.
Sesto giorno, 12 dicembre: Advanced Voice Mode con Visione
Viene introdotto un aggiornamento per la modalità vocale avanzata che permette al modello di vedere lo schermo o attraverso la fotocamera in tempo reale. Questa funzionalità consente l’interazione tramite video, comunicando in live con GPT sia con input vocali che visivi, aiutando con la risoluzione di problemi legati al dispositivo o al contesto reale che ci circonda. Questo può semplificare la vita dell’utente, evitandogli di dover spiegare a parole tutti i dettagli di un problema per ottenere assistenza.
Per celebrare le festività, OpenAI ha aggiunto anche una nuova icona a forma di fiocco di neve, che dà accesso a una modalità speciale per comunicare con la voce di Babbo Natale. Si tratta di un Agente disponibile solo in questo periodo, pensato per rispondere alle domande mantenendo lo stile del suo personaggio. Al primo utilizzo di “SantaGPT”, i crediti giornalieri per la modalità vocale avanzata verranno resettati come regalo di Natale, così da poterla utilizzare più a lungo.
La visione avanzata è inizialmente disponibile per gli abbonati di livello Plus e Pro, ma sono ancora esclusi gli utenti che vivono in UE, UK e Svizzera.
Settimo giorno, 13 dicembre: Projects
ChatGPT si arricchisce di una nuova funzionalità detta Projects, progettata per migliorare l'organizzazione delle chat e la gestione del flusso di lavoro, raggruppando file e conversazioni in cartelle specifiche.
I Progetti sono un ibrido tra cartelle smart e GPT personalizzati, possono riunire diverse chat, file e istruzioni personalizzate in un unico posto, facilitando i lavori con diversi elementi in comune. Per crearne uno bisogna cliccare sul tastino "+" a sinistra nella sezione delle chat. Si può decidere il nome della cartella e cambiarlo in ogni momento. Dopo la creazione, si può cambiare il colore della cartella e aggiungere PDF, immagini, file di codice o CSV. Si possono anche creare delle istruzioni che valgono solo per quel progetto e al suo interno si ha la possibilità di aprire infinite chat o aggiungerne di precedenti.
I Progetti non sono compatibili con o1, Search o i custom GPT, che non potranno essere richiamati con il tag “@” nelle chat incluse nelle cartelle.
Projects è attualmente disponibile per gli utenti Plus, Team e Pro, con piani per estendere l'accesso agli account Enterprise ed Edu all'inizio del 2025.
Ottavo giorno, 16 dicembre: Search
ChatGPT Search viene reso disponibile a tutti gli utenti, compresi quelli di livello gratuito. Questa funzionalità fornisce accesso in tempo reale a informazioni aggiornate dal web, migliorando l'accuratezza e la pertinenza delle risposte.
Search è stato anche migliorato in ogni suo aspetto, offrendo risultati visivi più ordinati e completi, tra cui immagini, recensioni e orari di apertura delle attività, migliorando la pertinenza e l’accuratezza delle ricerche. Invece per le richieste basate sulla posizione, può fornire direttamente mappe e indicazioni precise.
Search è stato anche integrato nella modalità vocale avanzata, permettendo agli utenti di eseguire ricerche anche senza dover guardare lo schermo o avere un dispositivo tra le mani. Basterà fare una domanda all’assistente vocale che si occuperà di eseguire ricerche per noi, molto utile per quando si sta guidando o camminando.
Nono giorno, 17 dicembre: Developers Day
Vengono introdotte ulteriori possibilità per chi sviluppa con le API di OpenAI, come l’accesso alla versione completa di o1, precedentemente disponibile in “preview”. Le API in tempo reali subiscono delle migliorie come l’integrazione WebRTC, che consente comunicazioni audio e video in real time per facilitare la creazione di applicazioni maggiormente reattive. Vengono anche ridotti i costi per l’audio di GPT-4o, che scendono del 60%, insieme al supporto per GPT-4o mini che costa un solo un decimo rispetto al modello più grande.
L’API viene arricchita con il supporto per le Function calling e gli output strutturati, consentendo agli sviluppatori di definire funzioni specifiche per l'IA e ricevere output in formati strutturati come il JSON. Inoltre, le capacità di visione di o1 sono state aggiunte alla sua API e si espande il supporto per linguaggi di programmazione come Java e Go. Tutto questo fornisce più versatilità agli sviluppatori.
Decimo giorno, 18 dicembre: Better Call ChatGPT
Viene introdotto un numero di telefono per ChatGPT (+1 1-800-242-8478), un servizio sperimentale progettato per rendere l'assistenza AI più accessibile.
Gli utenti negli Stati Uniti possono comporre il numero per telefonare direttamente all’assistente AI per 15 minuti al mese, mentre il resto del mondo può contattarlo tramite WhatsApp aggiungendo il numero in rubrica. Questa mossa permette all’azienda di raggiungere molti più utenti, anche quelli con una scarsa alfabetizzazione informatica o che non hanno accesso a uno smartphone abbastanza performante da eseguire l’app ufficiale. Ad esempio, la Cina produce dei device dalle scarse prestazioni pensati appositamente per il mercato africano, il cui costo non supera i $50. Questi telefoni supportano pochissime applicazioni, tra cui WhatsApp, che ora permette a chiunque di chattare con GPT.

Undicesimo giorno, 19 dicembre: Lavorare con le App
Viene migliorata l'integrazione di ChatGPT con varie applicazioni di macOS, semplificando i flussi di lavoro e migliorando la produttività. Gli utenti possono interagire con ChatGPT utilizzando comandi vocali in diverse applicazioni desktop, facilitando l'uso senza mani per un’operatività multitasking efficiente.
L'integrazione si estende a una varietà di applicazioni macOS, tra cui BBEdit, MATLAB, Nova, Script Editor e TextMate, consentendo agli utenti di avere un “proto-agente” che può leggere le app e rispondere alle richieste in maniera contestuale, risparmiando alcuni passaggi di copia-incolla o di spiegazione del contesto.
Questa funzionalità è attualmente disponibile solo sull’applicazione di ChatGPT per macOS, con piani per espandere il supporto anche a Windows.
Dodicesimo giorno, 20 dicembre: o3
L'ultimo giorno si è concluso in maniera inaspettata. Tutti si aspettavano un nuovo GPT per succedere a 4o, ma invece è stata presentata una demo di o3, un nuovo modello di ragionamento significativamente più capace rispetto al precedente o1.
Il nome, che salta il numero 2, è stato scelto perché esiste già un’omonima azienda inglese di telecomunicazioni e OpenAI non voleva rischiare problemi di copyright.
Tornando al modello, o3 è così "intelligente" che se partecipasse alle gare di programmazione su CodeForces, avrebbe un rating superiore a 2700 – piazzandosi tra i migliori programmatori competitivi al mondo.
I risultati sui benchmark più importanti sono sbalorditivi:
Con SWE-Bench, progettato per valutare la capacità dei modelli di risolvere problemi reali di software engineering, segna un 71.7%
Nel GPQA Diamond, che valuta le capacità dei modelli nel rispondere a domande a scelta multipla di livello PhD in chimica, fisica e biologia, ha fatto 87.7%, battendo il 78% di o1 e il 62% di Gemini Flash 2.0
Su FrontierMath, un benchmark avanzato composto da centinaia di problemi matematici ultra-difficili creati in collaborazione con oltre 60 matematici esperti, è passato dal 2% di o1 a un incredibile 25%
Nell'ARC-AGI Semi-Private Evaluation, una sezione del dataset ARC-AGI-1 utilizzata per valutare l'AGI, ha segnato un 87.5%
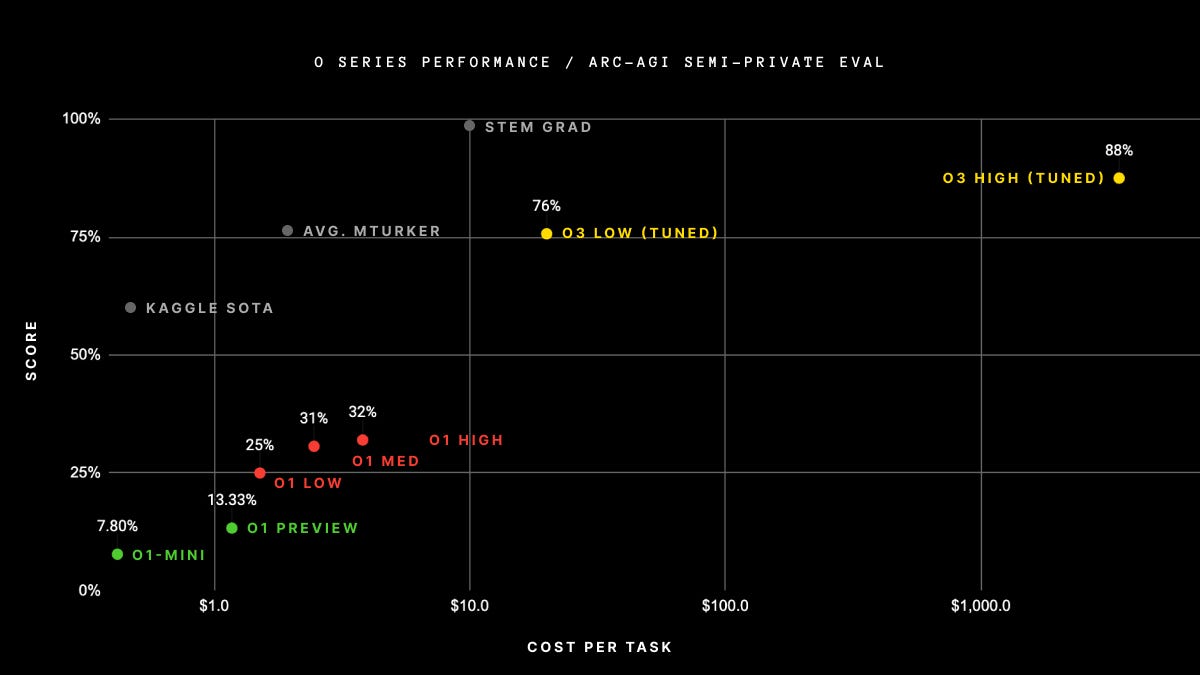
Per mettere quest'ultima informazione nella giusta prospettiva, consideriamo che:
Nel 2019, GPT-2 faceva lo 0%
Nel 2020, GPT-3 otteneva lo stesso risultato
Nel 2023, GPT-4 arrivava al 2%
Nel 2024, GPT-4 fa il 5%
o1 il 32% e la sua versione "Pro" il 50%
Tutto questo però ha un costo non indifferente, infatti o3 è il modello più costoso mai creato in termini di potenza di calcolo richiesta per l'inferenza. Ogni compito che ha risolto nel test ARC-AGI Semi-Private, è costato circa $3000 dollari. Le sue versioni mini offrono ottimi risultati a costi ridotti, ma il tutto necessiterà ancora di molta ottimizzazione per diventare più accessibile.
Con l’arrivo del 2025, sembra chiaro che i modelli come o3 supereranno molti umani in compiti specifici, avvicinandoci sempre più all'AGI.
30 Previsioni per il 2025
Riflettere sul futuro è una componente fondamentale del mio lavoro, ma anche un esercizio intellettuale che trovo estremamente stimolante e divertente. Quando mi dedico a questa attività, che considero al pari di un gioco, adotto un approccio razionale, combinando una visione d'insieme su un determinato argomento con un'analisi delle tendenze e dell'evoluzione degli eventi più recenti.
Con l'inizio del nuovo anno, ho deciso di raccogliere in questo articolo alcune previsioni personali sul mondo della tecnologia per il 2025. Con l'obiettivo di tornare a leggerle tra un anno per valutare quante di queste si saranno rivelate corrette, quante del tutto sbagliate e quante sorprendentemente vicine alla realtà.

Ecco dunque 30 previsioni che voglio condividere per l'anno che verrà:
Tutte le aziende che sviluppano modelli IA rilasceranno almeno un nuovo modello di ragionamento simile al pionieristico o1 di OpenAI, alcuni dei quali saranno talmente intelligenti da metterci di fronte a nuove sfide esistenziali.
Non arriverà l’AGI, ma sarà un anno fondamentale per il suo sviluppo.
Verrà messo in produzione un metodo per fornire memoria infinita agli LLM e usciranno dei modelli con finestre di contesto da 10 milioni di token.
Arriverà almeno un modello miniaturizzato (<8B di parametri) con capacità superiori a GPT-4 su ogni compito, sarà open-source e potrà essere eseguito in locale su un computer domestico.
Almeno il 70% delle principali aziende al mondo integreranno degli agenti AI semi-autonomi nei loro flussi di lavoro, riducendo il personale e le nuove assunzioni. Questo porterà a una quasi scomparsa delle posizioni di internship.
Arriveranno i primi agenti AI autonomi che, una volta inseriti e adeguatamente testati in un flusso di lavoro, non necessiteranno più di alcuna supervisione.
Uscirà Sora 2.0 e sarà quasi indistinguibile dalle riprese video reali.
Runway stringerà nuove partnership con studi hollywoodiani e rilascerà almeno 20 nuovi prodotti o funzionalità, oltre che una nuova versione del modello Gen
Odyssey rilascerà un modello per la generazione di mondi 3D che offre controllo totale su ogni elemento di una scena, ma avrà un costo molto elevato.
Midjourney riuscirà a creare un qualcosa di simile a Odyssey, ma con un approccio differente e una qualità più bassa, mantenendo un prezzo competitivo. Prima di arrivarci, rilasceranno Midjourney V7 e V7.1, un modello per i video e uno per il 3D. Insieme ai nuovi modelli, arriveranno decine di nuove funzionalità e strumenti per potenziare la creatività umana.
Black Forest Labs rilascerà un modello video open-source qualitativamente paragonabile a Veo 2 di Google DeepMind.
Eleven Labs rilascerà la versione 3 del suo modello text-to-speech, che supporterà ancora più lingue e sarà molto più flessibile in termini di suoni e sfumature vocali. Arriverà anche un suo modello per la creazione di musica e canzoni con un’interfaccia di editing specifica. Implementeranno decine di nuovi strumenti e funzionalità che renderanno la piattaforma un vero e proprio studio per l’audio a 360°. Tutto questo porterà la valutazione dell’azienda a 10 miliardi.
Emergeranno delle nuove etichette discografiche indipendenti che produrranno brani di altissimo livello grazie all’IA, e vedranno la partecipazione di molte figure di spicco nell’industria musicale.
Nei cinema uscirà un film realizzato quasi totalmente con IA che verrà fortemente boicottato da chi odia questa tecnologia, spingendo diverse sale a non proiettarlo, ma nonostante questo incasserà almeno 20 volte quello che è costato per produrlo e segnerà un punto di non ritorno per l’industria.
Vedremo la nascita di nuovi servizi e prodotti dedicati alle simulazioni, che non saranno limitati alla robotica e agli ambienti 3D, ma spazieranno dal marketing alla biologia, dalla psicologia all’astro fisica, dall’intrattenimento all’istruzione. Alcune di queste simulazioni saranno così ben fatte da farci dubitare della realtà.
Torneremo a parlare del Metaverso, soprattutto grazie all’uscita di visori VR/AR di nuova generazione e a Meta che lancerà diverse novità a riguardo.
Dopo Microsoft, Amazon, Google e Meta, altre aziende tecnologiche inizieranno a investire nel settore dell’energia nucleare stringendo partnership strategiche.
Le interfacce cervello-computer (BCI) avranno degli sviluppi sorprendenti.
Verrà fatto almeno un grosso passo in avanti nella ricerca sulla fusione nucleare.
Verrà fatto almeno un grosso passo in avanti nella ricerca sul quantum computing.
Verrà costruito un super-cluster AI con almeno il doppio della potenza di calcolo del più grande datacenter esistente oggi.
Arriveranno almeno 10 nuove possibili cure per svariati tipi di cancro.
Arriveranno nuove cure per l’HIV e si parlerà di debellarla entro il 2030.
Si inizierà a parlare seriamente e con proposte concrete, di come estrarre materie prime dalla Luna, dagli asteroidi e da Marte.
Il settore della Space-economy crescerà di almeno il 30% a livello globale.
Sempre più robot umanoidi inizieranno a lavorare nelle fabbriche al posto degli umani, e oltre 50.000 famiglie avranno un primo modello di umanoide in casa.
Aumenteranno gli investimenti nelle ricerche sui nanobot, portando alla pubblicazione di almeno 10 paper rivoluzionari in questo settore emergente.
Assisteremo alle prime avvisaglie della futura disoccupazione di massa.
Ci saranno grosse proteste per le perdite di posti di lavoro e molte persone chiederanno a gran voce di rallentare gli sviluppi sull’IA e la robotica.
Si inizieranno a proporre dei framework comuni sull’utilizzo di droni e altre tecnologie avanzate in scenari bellici.
Essere un artista multidisciplinare
L’intervistato del nuovo numero di Tales from the Latent Space è Niccolo Casas, architetto e designer visionario con un approccio multidisciplinare all’avanguardia. Dalla stampa 3D all’uso di intelligenza artificiale e tecnologie Web3, dalle collaborazioni con il settore dell’alta moda alla ricerca di un’architettura sempre più fluida e multidimensionale, Niccolo ci racconta come la sua curiosità per l’innovazione sia diventata il catalizzatore di una carriera in continuo mutamento.
In questa intervista, scopriamo i segreti dietro alla sua idea di coesistenza, in cui natura, arte e tecnologia si fondono per generare una nuova forma di bellezza. Con passione e concretezza, ci accompagna in un viaggio che va dai primi esperimenti con la stampa 3D fino alla nascita di collaborazioni internazionali, offrendoci uno sguardo sulle sfide e sulle opportunità che le nuove tecnologie aprono al mondo del design e dell’architettura. La sua storia dimostra quanto la volontà di esplorare territori sconosciuti possa dar vita a progetti capaci di ispirare un cambiamento profondo, unendo talento e sperimentazione, tecnologia e sostenibilità.
Questa intervista si colloca nella più ampia visione del magazine di offrire uno spazio unico ai creativi di tutto il mondo che utilizzano la tecnologia come ampliamento delle loro possibilità espressive. A partire dall'anno prossimo, questa rubrica includerà anche interviste a ingegneri, programmatori e matematici, per diversificare i contenuti e promuovere l'idea che la creatività non appartiene solo ad artisti e designer, ma che si tratta di un raffinato processo di problem solving intrinseco alla natura dell’essere umano e alle sue capacità cognitive.
Ci descriveresti il tuo rapporto con la tecnologia?
La tecnologia è fondamentale nel mio lavoro. Quello che sono oggi come professionista è dovuto alla mia curiosità verso le nuove tecnologie: prima nei confronti del disegno e della stampa 3D, poi del Web3 e oggi nei riguardi dell’intelligenza artificiale.
In particolare, i primi anni 2010 hanno segnato un punto di svolta significativo nella mia carriera, portando il mio lavoro da una dimensione locale a una globale e da un approccio disciplinare a uno multidisciplinare.
Questo periodo di trasformazione è stato guidato da tre sviluppi chiave: l’ascesa dei social network, la diffusione di internet ad alta velocità e la rapida crescita delle tecnologie di produzione additiva. La connettività globale mi ha permesso di interagire con un ampio spettro di pensatori e creatori, indipendentemente dalla loro posizione fisica. Allo stesso tempo, l'integrazione delle tecnologie di stampa 3D in vari settori è diventata un mezzo cruciale per esplorare l'innovazione interdisciplinare. Infatti, gli architetti della mia generazione si sono trovati in una posizione unica per abbracciare la rivoluzione della produzione additiva. Avendo sperimentato la stampa 3D come studenti e insegnanti, eravamo già consapevoli del suo potenziale. Questo bagaglio ci ha resi collaboratori ideali nell'applicare la stampa 3D a campi che spaziano dalla moda al design di prodotto, dall'arte all'architettura.
Queste collaborazioni interdisciplinari non solo hanno ampliato la portata dei miei progetti, ma hanno anche ridefinito i miei quadri concettuali. Mi hanno incoraggiato ad affrontare la ricerca e il design attraverso una lente integrativa che collega scale, discipline e prospettive diverse. Gli NFT sono solo l’ultimo ambito in cui la tecnologia mi ha portato.
Alla base del tuo percorso c'è una formazione da architetto, ma il tuo lavoro si estende a molte altre discipline. In che modo l’architettura ha influenzato la tua evoluzione professionale e artistica?
Credo che oggi il lavoro dell’architetto si sia evoluto in una direzione sempre più multidisciplinare, spaziando dall’ambito della costruzione tradizionale a quello del cosiddetto artigianato digitale. Grazie alle nuove tecnologie, i clienti di un architetto non si limitano più al mondo del costruito fisico, ma si estendono anche a quello digitale. La game industry, il cinema, il teatro, l’intelligenza artificiale, la moda e il Web3 sono tutti settori in cui un architetto può oggi trovare lavoro, grazie alla sua formazione che integra competenze tecniche e artistiche con un forte utilizzo di strumenti digitali.
Quello che distingue la formazione dell’architetto è la sensibilità tecnico-artistica e la capacità di collaborare con esperti di discipline diverse. Il saper gestire team complessi nell’ambito della costruzione, che includono clienti, ingegneri, autorità e comunità locali, sviluppa una naturale attitudine alla multidisciplinarietà. Questa caratteristica consente in modo naturale di confrontarsi anche con ambiti e professionisti tradizionalmente considerati lontani.
Inoltre, l’architetto moderno può essere visto come una sorta di “artista ingegnere,” un artigiano digitale capace di muoversi con fluidità tra i mondi della tecnologia, dell’ingegneria e della creatività. Questo lo avvicina a una figura imprenditoriale che crea con l’obiettivo di costruire, indipendentemente dalla scala o dal settore di applicazione. Gli architetti, in fondo, amano trasformare idee in realtà tangibili, che si tratti di edifici, oggetti di design, ambienti virtuali o esperienze artistiche.
Nel tuo percorso hai esplorato anche il Web3 e creato NFT. Quali pensi che siano i principali benefici di queste tecnologie per gli artisti e i creativi? E come immagini il loro impatto a lungo termine?
Nella mia carriera ho avuto il privilegio di lavorare con donne straordinarie che mi hanno ispirato e guidato oltre i confini dell'architettura, come Iris Van Herpen nella haute couture, Anouk Wipprecht nel fashion-tech e Beth Cardier nell'AI. Allo stesso modo, è stata l'artista e curatrice Farrah Carbonell a introdurmi al mondo del Web3 e degli NFT, incoraggiandomi a esplorare il mio lato artistico in modo più profondo. Questo ha segnato un momento cruciale per la mia evoluzione creativa.
Credo fermamente che il futuro dell'arte sia digitale. Il Web3 e gli NFT offrono vantaggi significativi, tra cui la democratizzazione del mercato dell'arte, permettendo a nuovi artisti, curatori e gallerie di emergere grazie a un ecosistema flessibile e accessibile. Questi strumenti abbattono barriere geografiche ed economiche, dando visibilità globale a talenti emergenti anche dalle aree più isolate.
A lungo termine, immagino uno sviluppo interessante: la nascita di comunità creative auto-organizzate e la costruzione di infrastrutture digitali che le supportino. Proprio come l'invio di grandi file digitali ha rivoluzionato il mio lavoro creativo, credo che il Web3 possa fare lo stesso, aprendo nuove opportunità per creativi di tutto il mondo, guidati dal talento, dalla curiosità e dalla padronanza di queste tecnologie innovative.
Quali pensi che siano i principali vantaggi dell'Intelligenza Artificiale per la creatività umana?
L’intelligenza artificiale (IA) si sta diffondendo in ogni fase del processo creativo, dall’ideazione alla fabbricazione. Non esiste una sola IA, ma una pluralità di sistemi e strumenti. La ricerca e la scrittura assistite dall’intelligenza artificiale influenzano in modo significativo il nostro modo di concepire idee. Allo stesso modo, i nuovi strumenti di visualizzazione 2D, 3D e di animazione basati sull’IA, o che la integrano, plasmano il modo in cui i creativi disegnano e rappresentano le loro idee. Anche nella fabbricazione, l’IA gioca un ruolo crescente: oltre alla robotica, viene utilizzata per ottimizzare i processi di stampa 3D, scoprire materiali innovativi e migliorare la personalizzazione di massa dei prodotti. Le implicazioni e i vantaggi dell’IA riguardano trasversalmente tutti i settori della creatività.
Uno degli impatti principali dell’IA sulla creatività umana, a mio avviso, risiede nella democratizzazione del lavoro creativo. Questa democratizzazione si manifesta attraverso due modalità principali. In primo luogo, l’IA contribuisce a ridurre il divario tra piccoli e grandi studi creativi: saper utilizzare l’IA in modo efficace equivale ad avere un piccolo gruppo di collaboratori virtuali che supportano il lavoro del creativo. In secondo luogo, l’IA rende gli strumenti digitali più accessibili e intuitivi, soprattutto se paragonati, ad esempio, alla scrittura di script o alla modellazione digitale e parametrica tradizionale. Questa maggiore accessibilità consente a un numero crescente di creativi di esprimersi senza dover possedere conoscenze tecniche avanzate. Tuttavia, l’uso diffuso dell’IA solleva anche criticità legate alla sostenibilità energetica, alla dipendenza tecnologica e al rischio di esclusione per chi non ha accesso a queste risorse.
Parte del tuo lavoro è legata al tema della sostenibilità, e quindi anche all'ambiente e al modo in cui ci rapportiamo con esso. Questo mi porta a chiederti se sei ottimista riguardo al futuro dell'umanità e se ritieni che la tecnologia possa aiutarci a prosperare per i secoli a venire.
Non mi considero ottimista riguardo al ruolo dell’essere umano nel rendere il mondo sostenibile, ma nutro speranza nel potenziale della tecnologia. Credo che, come specie, siamo spesso troppo miopi ed egoisti per cambiare radicalmente le nostre abitudini in favore di un bene ecologico che avvantaggi le generazioni future. Nonostante l’evidente crisi climatica, vedo pochi sforzi significativi sia a livello istituzionale sia tra i singoli individui. La sensibilità ecologica è ancora carente nelle scelte quotidiane delle persone: da ciò che mangiamo a ciò che indossiamo, fino a come ci muoviamo.
Al contrario, le nuove tecnologie stanno spingendo il mondo verso la digitalizzazione e modelli basati sulla non proprietà, come il noleggio, che potrebbero contribuire in modo concreto a una maggiore sostenibilità. Inoltre, credo che l’intelligenza artificiale avrà un ruolo cruciale nel prossimo futuro, aiutandoci a sviluppare nuovi materiali e processi capaci di sostituire quelli tossici esistenti. Tuttavia, il successo di queste soluzioni dipenderà dalla loro semplicità e dal minimo sforzo richiesto agli utenti per adottarle.
Il mondo sta già mostrando i segni drammatici dei cambiamenti causati dal clima, ma spesso non li ascoltiamo. Gli esseri umani tendono ad agire solo quando la minaccia diventa immediata, ma non possiamo più permetterci di attendere. Non possiamo aspettare che "qualcun altro" risolva il problema; ognuno deve fare la propria parte.
Come creativi, credo che il nostro compito sia accorciare quel tempo di consapevolezza. Dobbiamo creare simboli di cambiamento, di speranza e di ispirazione, capaci di guidarci verso una nuova forma di abitabilità sostenibile. Solo unendo il potenziale della tecnologia con una trasformazione culturale condivisa potremo affrontare le sfide che ci attendono.
Durante il tuo percorso hai avuto modo di collaborare con realtà molto diverse tra loro, da organizzazioni come Parley for the Oceans a designer internazionali nel mondo del fashion, fino al Cirque du Soleil. Quali sono le sfide più stimolanti nel lavorare con professionisti di discipline così lontane dalla tua? Avresti un aneddoto che rappresenta bene questa varietà?
La cosa che mi colpisce di più di queste collaborazioni è che molte di esse sono iniziate online e sono rimaste esclusivamente digitali fino al momento delle presentazioni ufficiali. Questo aspetto mi affascina: come sia possibile creare grandi opere creative e persino costruire amicizie profonde senza mai incontrarsi fisicamente. In questo senso, vedo il Web3 come un’evoluzione naturale delle collaborazioni digitali, in cui l’appartenenza a comunità con intenti e passioni condivise supera le barriere della distanza fisica.
Collaborare con professionisti di discipline diverse è una sfida che stimola costantemente l’innovazione. Ogni volta che collaboro con Iris Van Herpen, ad esempio, mi invita a uscire dalla mia zona di comfort. Spesso mi chiede di esplorare nuove tecniche di disegno o fabbricazione, proponendomi sfide che all’inizio sembrano impossibili. Iris è “furba”, mi dice sempre: “Non rispondermi subito, prenditi un paio di giorni e vedi se puoi farlo.” Questo approccio trasforma ogni richiesta in una sfida personale, un gioco mentale con me stesso per vedere fin dove posso spingermi.
Credo fermamente che il solo modo per migliorare, indipendentemente dall’età o dal livello di esperienza, sia provare a fare ciò che non si sa fare. È una lezione che ho imparato da queste collaborazioni, dove la diversità di visioni e approcci è la chiave per innovare e crescere.
Tra le tue collaborazioni e progetti, ce n’è uno (o più di uno) che consideri particolarmente rappresentativo della tua visione artistico-filosofica?
Sicuramente, la mia collaborazione con l’organizzazione ambientale Parley for the Oceans e l’azienda di stampa 3D Nagami, in occasione della Biennale di Architettura 2021, è stata un momento significativo. Plasticity è un’installazione alta 3,2 metri, realizzata con plastiche riciclate recuperate dagli oceani. Questo progetto rappresenta un incontro tra attivismo ecologico, sostenibilità, tecnologia, arte e architettura. Plasticity nasce dai detriti plastici recuperati dagli oceani, si trasforma in una costruzione architettonica d’avanguardia e trasmette un messaggio forte per la protezione degli oceani.
Il tema della “coesistenza,” che attraversa tutto il mio lavoro, in questo caso si manifesta a più livelli. Credo che sia grazie a quest’opera che ho compreso come l’idea di coesistenza possa essere non solo metodologica – in termini di collaborazione ed etica legata alla sostenibilità, come la coesistenza tra uomo e natura – ma anche estetica. Formalmente, la scultura si sviluppa dalla combinazione di due lessici opposti: uno organico, che richiama formazioni naturali e libere, e uno lineare e geometrico, che diventa una metafora della duplice relazione tra umano e natura.
I miei lavori nell’ambito degli NFT derivano esattamente da questa intuizione. La coesistenza si trasforma in un collage digitale che combina senza compromessi pattern floreali, ritratti ed elementi simili a glitch, che rappresentano invece la tecnologia.
L’idea centrale è che sia proprio la tecnologia a permettere la coesistenza tra noi e la natura. I miei collage sono la manifestazione concreta di questa visione.
Guardando al futuro, quali consigli daresti a chi aspira a lavorare nel vasto mondo dell’architettura, specialmente in un’epoca di rapida evoluzione tecnologica?
Suggerirei di pensare all’architettura in senso ampio, come un limite tra il corpo e l’ambiente circostante. Che questo limite si concretizzi in un abito, un edificio o un dispositivo, poco importa. Nei prossimi anni, la tecnologia trasformerà profondamente il nostro modo di vivere; fare architettura significherà quindi prendersi cura delle modalità con cui abitiamo e ci relazioniamo con gli altri e con l’ambiente.
L’architetto dovrà reinventarsi come esperto nella creazione di ambienti collaborativi, diventando un facilitatore capace di guidare esperti di diverse discipline verso l’incontro e la produzione di innovazione.
Attraverso la curiosità e una solida conoscenza degli strumenti digitali, l’architetto può ambire a essere protagonista del cambiamento del nostro modo di abitare, sempre mantenendo come obiettivo una bellezza che sia estetica, esperienziale ed ecologica