


Passeggiando per il Nuovo Mondo
Non potendo più tornare indietro, addentriamoci a esplorare questo nuovo mondo, cercando di trarne il più possibile per la nostra creatività


L’estate è un periodo molto strano, soprattutto per chi vive in Italia, dove tutto tende a fermarsi o a rallentare significativamente, mentre nel resto del mondo le aziende tecnologiche non smettono mai di lavorare e di rilasciare novità interessanti.
Il progetto di questo magazine è iniziato solamente due mesi fa, proprio nelle prime settimane estive, e da lì non sono mai mancati dei nuovi argomenti di cui parlare nella rubrica di news, o sui quale fare approfondimenti con degli articoli mirati.
Anche il mese di agosto non stato da meno, e anzi è forse il mese nel quale sono accadute più cose nel giro di pochi giorni (a volte ore) di distanza, al punto da costringermi a fare una selezione ben più oculata del solito.
Prima di addentrarci nel nuovo mondo, vi faccio una piccola ma importante comunicazione di servizio:
Se seguite Tales from the Latent Space fin dall’inizio, saprete che ho scelto l’ultima domenica del mese come giorno di pubblicazione. Ebbene, ho cambiato idea!
Perché con questo terzo numero mi sono reso conto che l’ultima domenica del mese non corrisponde necessariamente agli ultimi giorni del mese, ma anzi può lasciar spazio ad altre sei giornate prima della sua conclusione.
Questo implica un pattern di pubblicazione che non mi piace molto, perché vorrei avere tutto un mese per collezionare informazioni e giudicare il suddetto in retrospettiva. Quindi?
A partire dall’imminente settembre, il magazine uscirà “a sorpresa” negli ultimi giorni del mese. Questo significa che potreste ritrovarvelo nell’email in un range di giornate che può spaziare da venerdì a domenica, in base alla conformazione del mese in corso.
Ad esempio, se stessi già applicando questa nuova logica, invece che leggere queste parole il 25 agosto, le stareste probabilmente leggendo il 31. Mentre il mese prossimo, riceverete sicuramente l’email il 29 settembre.
Quindi in sostanza, tenderò comunque a prediligere il weekend ove possibile, ma potrebbe anche capitare di fare l’invio di venerdì (come accadrà nel gennaio 2025).
Come al solito, tante parole per spiegare un ragionamento tutto sommato molto semplice, mea culpa. Ora dirigiamoci rapidamente al binario, perché questo treno è decisamente meglio non perderselo…

Che cos’è realmente l’Intelligenza Artificiale?
Parlando con le persone, spesso mi rendo conto di quanto il termine “Intelligenza Artificiale” porti con sé un sacco di fraintendimenti, interpretazioni fantasiose e timori irrazionali. La radice di tutto questo, credo che vada ricercata nel basso livello del giornalismo odierno e nelle rappresentazioni dei film hollywoodiani, che associano quasi sempre l’IA a dei robot malvagi e pericolosi.
Come spesso accade però, la realtà dei fatti risulta essere molto più complessa e sfaccettata rispetto alle caricature narrative o ai nostri bias.
Ed ecco che qui entra in gioco la mia spiegazione, molto semplificata e schematica.
L'Intelligenza Artificiale, o IA, è la branca dell’informatica che lavora alla creazione di sistemi artificiali in grado di imitare varie forme di intelligenza, tra cui quella umana. Si basa su algoritmi matematici, modelli statistici e grandi quantità di dati.
Tra gli obiettivi dell'IA, c’è quello di simulare i processi cognitivi umani, come il ragionamento, il problem solving, la catalogazione e l’elaborazione di informazioni.
Può essere utilizzata in molti settori, come sanità, climatologia, finanza, assistenza, istruzione, design, robotica e molto altro ancora. Questo implica che nei prossimi anni avrà un impatto significativo in ogni aspetto della nostra vita quotidiana, fino a mutare completamente il nostro modo di vivere in società.
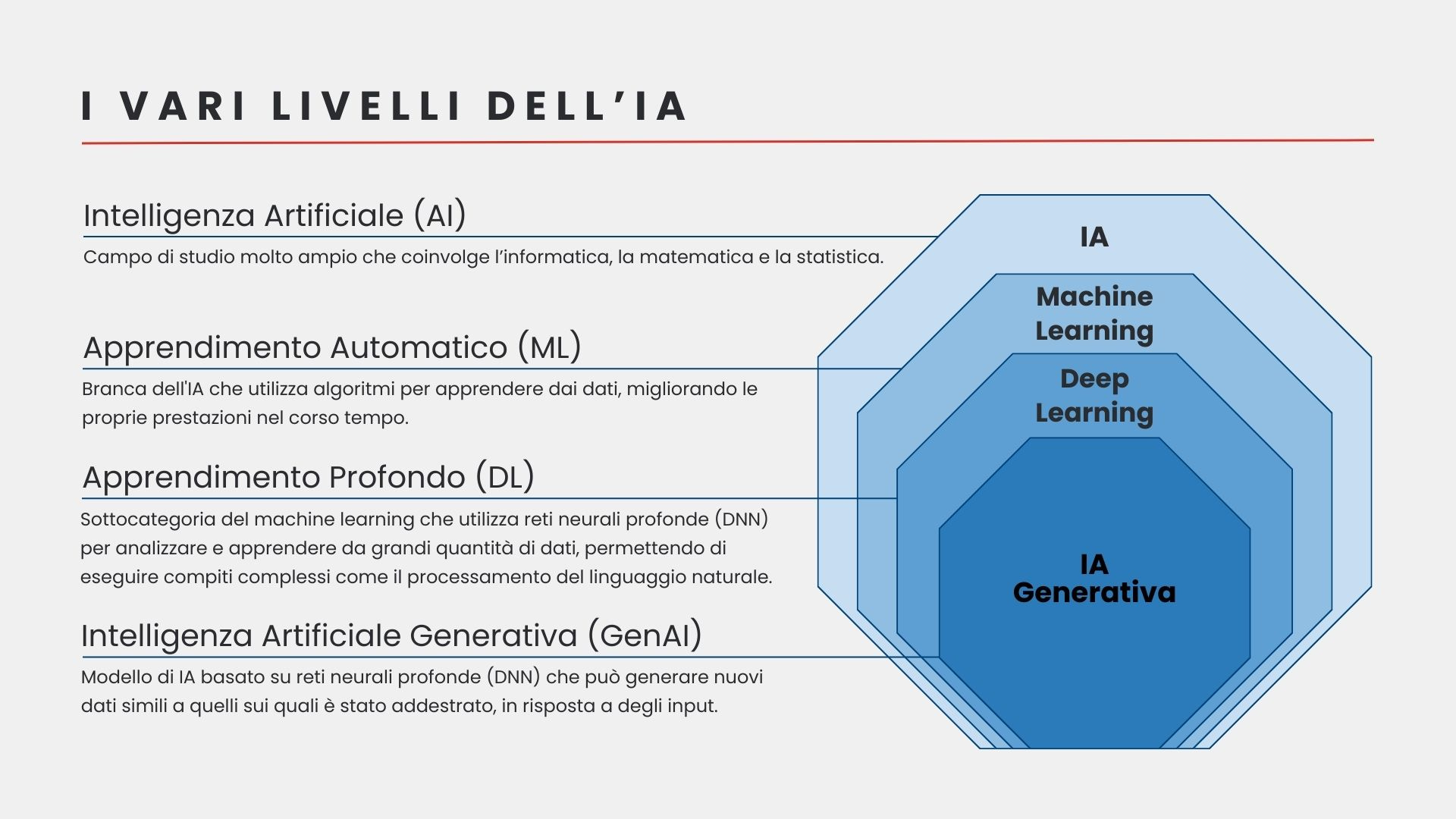
L’IA può avere diversi tipi di classificazione:
IA simbolica: Basata su regole, logica e simboli (rappresentazioni astratte di concetti). Esempio: Deep Blue, il supercomputer di IBM che ha sconfitto il campione del mondo di scacchi Garry Kasparov nel 1997.
Machine learning: Algoritmi che imparano dai dati, anche in maniera autonoma. Esempio: Gli algoritmi di ML vengono utilizzati per classificare automaticamente le email che riceviamo come spam o non spam.
Deep learning: Reti neurali profonde che imitano il funzionamento del cervello umano. Esempio: Sistemi di guida autonoma che utilizzano sensori e modelli di deep learning per navigare e prendere decisioni sulla strada.
Intelligenza Artificiale Debole (ANI): Ha un grado di “intelligenza” abbastanza limitato. Si focalizza su un singolo compito o su un insieme ristretto di compiti.
Intelligenza Artificiale Generale (AGI): Ha un grado di “intelligenza” al pari di quello umano, o superiore in termini di rapidità di ragionamento. Può svolgere qualsiasi compito che richieda l’utilizzo dell’intelletto. Al momento non esiste ed è in fase di ricerca, ma è verosimile aspettarsi che arriverà entro 10 anni.
Superintelligenza Artificiale (ASI): Ha un grado di “intelligenza” nettamente superiore a quello di qualunque essere umano. Potrebbe svolgere qualunque compito con estrema efficienza.
Altri due concetti chiave che vengono spesso citati quando si parla di IA, sono i modelli e le architetture.
Col termine “modello”, ci riferiamo a entità matematiche che vengono addestrate su dei dati per svolgere compiti più o meno specifici. In pratica, è ciò che risulta dal processo di addestramento. Pensate a un modello come a un software che ha imparato a riconoscere immagini, a comprendere il linguaggio naturale, o a prevedere tendenze. Esempi di modelli includono gli LLM come GPT o Claude, i generatori di immagini come Midjourney o Stable Diffusion, i modelli per la guida autonoma dei veicoli, i modelli per le previsioni sul clima, e così via.
D'altra parte, quando parliamo di architetture, ci riferiamo alla struttura sottostante che definisce il funzionamento e la costruzione di un modello. Esattamente come per gli edifici, l'architettura è il progetto di costruzione, mentre il modello è l'edificio fatto e finito. Possono esistere molti tipi di architetture diverse, basate su algoritmi e funzioni matematiche differenti, che vengono scelte in base al tipo di modello che si vuol costruire e ai problemi che dovrà risolvere.
Avvenimenti del mese
Se avete letto le pubblicazioni precedenti, inizierete anche a notare certi pattern. Alcuni dei quali mi sento di spiegarli di volta in volta, man mano che questi si palesano con una certa evidenza.
Il mese scorso vi ho spiegato che Tales from the Latent Space si compone di diverse rubriche, ma che alcune di queste non saranno sempre presenti a ogni pubblicazione per diverse ragioni. Al momento, posso dire con certezza che non mancheranno mai la domanda di apertura, la rubrica di news, quella sui paper e quella sull’open-source.
A tal proposito voglio far notare, e spiegare, che Avvenimenti del mese, L’edicola dei paper scientifici e Il mercatino dell’open-source vengono rappresentate con un’immagine concettuale non variabile. Nel senso che, oltre al titolo, potrete riconoscere l’apertura di queste rubriche grazie a un’immagine pensata per esprimere l’idea della rubrica in sé. Queste immagini vengono accomunate da uno stile visivo in comune, e dal fatto che rappresenteranno il format per l’intera annata di pubblicazione.
Tutto questo, solo per dirvi che da questo numero ho introdotto anche l’immagine per questa rubrica e che tutte le immagini verranno rinnovate nel mese di gennaio, per poi accompagnarci per le 12 pubblicazioni successive.

Segmentare il perimetro della realtà
Il 29 luglio, Meta ha reso pubblica la seconda versione di Segment Anything (SAM), il suo modello di computer vision progettato per eseguire la segmentazione di oggetti e soggetti all’interno di immagini statiche o video, consentendo di selezionare e isolare automaticamente qualsiasi forma con precisione e rapidità.
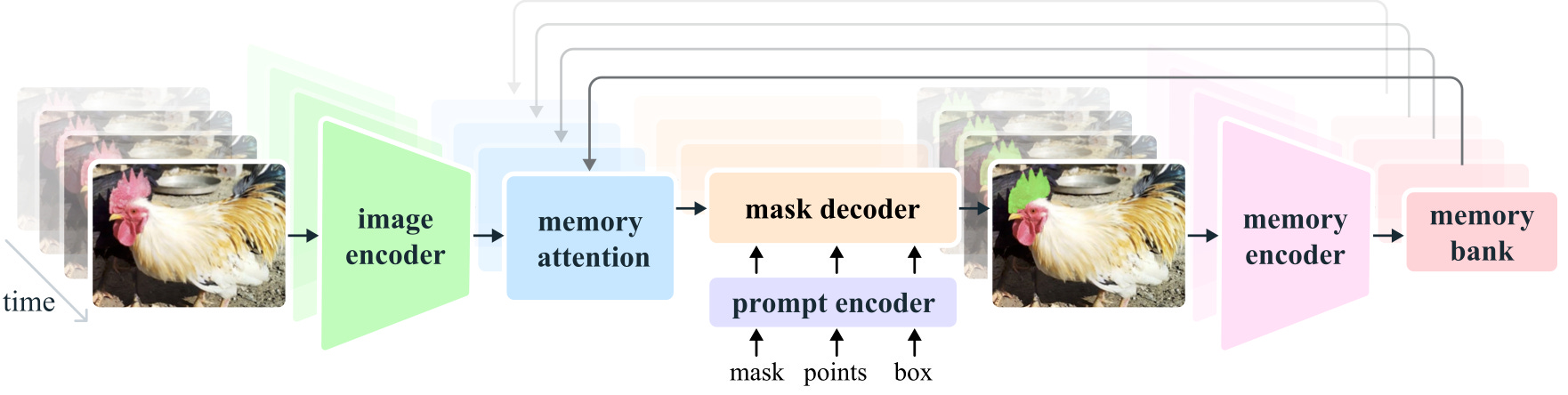
A differenza del suo predecessore, SAM 2 riesce a mascherare gli oggetti e a seguirli attraverso i vari fotogrammi di un video con un grado di precisione altissimo, anche in situazioni estremamente dinamiche e complesse grazie alla sua architettura ottimizzata per l'interattività in tempo reale. Come fu per il primo SAM, anche questo è un modello completamente open-source, infatti Meta ha rilasciato pubblicamente su Github il suo modello preaddestrato, insieme al dataset SA-V su cui è stato allenato, una demo super semplice e intuitiva (vi consiglio di provarla per gioco e per capire meglio di cosa stiamo parlando) e il codice sorgente.
Eccovi alcuni casi d’uso che mi vengono in mente per SAM 2:
Robotica: Aiutare i robot a riconoscere e manipolare gli oggetti in tempo reale
Video editing: Facilita il ritaglio di soggetti senza green screen
Medicina: Miglioramento della computer vision per identificare anomalie nelle radiografie e risonanze magnetiche
Automotive: Miglioramento dei sistemi di guida autonoma identificando più precisamente ostacoli e segnaletica con le telecamere
I robot umanoidi sono sempre più vicini
Il 6 agosto, la Startup di robotica Figure presenta con un video il suo nuovo robot umanoide Figure 02, che perfeziona ogni elemento del design precedente, avvicinandosi tantissimo all’Optimus di Tesla.

Il cambiamento più evidente rispetto a Figure 01, è la finitura nera opaca nel design del robot al posto del metallo cromato. Anche il posizionamento del cablaggio è cambiato molto, passando dall’esterno all’interno.
La capacità della batteria del robot è stata migliorata del 50%, consentendogli di lavorare più a lungo. La Startup ha anche prodotto dei motori su misura per ottimizzare la potenza e le prestazioni di ogni giunto.
Figure 02 ha 3 volte la capacità di calcolo e inferenza AI della generazione precedente, e questo gli consente di svolgere attività nel mondo reale in completa autonomia. Ha anche 6 telecamere RGB per vedere e comprendere il mondo fisico. Figure 02 è ora in grado di conversare con gli esseri umani tramite microfoni, altoparlanti e un modello IA addestrato in collaborazione con OpenAI.
A inizio anno, Figure ha distribuito il suo robot in uno stabilimento BMW in South Carolina per fare dei primi test e raccogliere dati di addestramento. L'azienda ha dimostrato con successo che Figure 02 può funzionare in un ambiente industriale, imparando a svolgere diverse attività di base.
Fare un film con l’IA in 48 ore
Il 29 luglio, Runway ha reso disponibile la funzionalità Image to Video per il suo modello Gen-3 Alpha, che aggiunge la possibilità di utilizzare una propria immagine come fotogramma di partenza per guidare la generazione di una clip video.
Sei giorni dopo, la funzionalità viene aggiornata, aggiungendo la possibilità di scegliere di utilizzare un’immagine come primo o ultimo fotogramma di un video.
Il 15 agosto, rilascia Gen-3 Alpha Turbo Image to Video, una versione di Gen-3 Alpha leggermente depotenziata, ma che può generare video 7 volte più velocemente rispetto al modello completo. Molto utile per testare rapidamente l’efficacia di un prompt con una certa immagine, per poi affidarsi al modello più potente.

In fine, Runway ha annunciato la terza edizione del suo Gen:48, un concorso di cortometraggi in cui team di 1-3 registi hanno 48 ore per ideare e realizzare un film di durata compresa tra 1 e 4 minuti.
I team partecipanti riceveranno 300.000 crediti Runway per aiutarli a generare i loro film all'interno della piattaforma, e avranno accesso alla libreria audio di Epidemic Sound. I vincitori del Grand Prix e del People's Choice riceveranno in premio $5.000 e 1.000.000 di crediti Runway, più un invito al loro Creative Partners Program.
Inutile dire che io sto già scaldando i motori!
Tutto ciò che c’è di nuovo in Midjourney
Il 30 luglio, Midjourney ha reso disponibile il suo nuovo modello V 6.1, che come fu per la versione 5 dello scorso anno, è solo uno step intermedio prima di approdare (verosimilmente nel giro di un paio di mesi) al più completo 6.2.

Rispetto alla V 6.0, la 6.1 comporta le seguenti migliorie:
Le immagini sono più coerenti, soprattutto per quanto riguarda: braccia, gambe, mani, corpi, piante e animali
La qualità delle immagini è migliorata, soprattutto sulle texture
Sono stati migliorati i piccoli dettagli, come i volti e l'anatomia dei personaggi negli sfondi e in lontananza
È stato introdotto un nuovo upscaler più preciso ed efficace
Il nuovo modello è più veloce, e quindi più economico, di circa il 25%
Riesce a generare testi migliori e con meno possibilità di errore (vanno sempre messi tra virgolette quando scriviamo un prompt)
Hanno aggiornato il parametro di personalizzazione --p per renderlo "più preciso", quindi noterete che il vostro codice univoco è cambiato, e continuerà a cambiare nel tempo, ma si possono sempre utilizzare quelli vecchi digitandoli manualmente nel prompt
Hanno introdotto un nuovo parametro --q 2 che dovrebbe migliorare ulteriormente le texture, ma con un costo superiore del 25%
Di contro, utilizzando le funzionalità di reframe e vary region, il modello passerà automaticamente alla versione 6 perché la 6.1 non le supporta. Per avere tutto perfettamente funzionante e integrato, bisognerà attendere l’uscita della V 6.2.
Ma non finisce qui! Il 16 agosto hanno integrato nella loro piattaforma un nuovo editor per le immagini, che combina le funzionalità di reframe, zoom e repaint in una sola interfaccia. Mentre il 21 agosto, hanno dato a tutti quanti l’accesso alla piattaforma, che prima era disponibile solo agli utenti che avevano generato una certa quantità di immagini. Per permettere ai nuovi utenti di testare la nuova interfaccia, hanno reintrodotto la prova gratuita di 25 immagini, che non era più disponibile da oltre un anno.
I modelli della selva oscura
Se avete a che fare con la bolla dell’IA generativa, vi sarete sicuramente ritrovati per qualche giorno con il feed pieno di contenuti riguardanti dei nuovi, strabilianti modelli per la generazione di immagini.
Black Forest Labs, una nuova startup fondata da alcuni membri del team dietro a Stable Diffusion, ha da poco lanciato la famiglia di modelli FLUX.1

Eccovi un breve elenco di informazioni utili da sapere:
FLUX alza significativamente l'asticella dei modelli "open" per la generazione d'immagini, superando significativamente le performance del famoso cugino Stable Diffusion, e rispettando tutte le promesse non mantenute di SD3.
La famiglia FLUX.1 si compone di tre modelli: [pro], [dev] e [schnell].
[pro] è il top di gamma, disponibile via API per uso commerciale.
[dev] è la sua versione distillata open-weight, disponibile per chiunque voglia sperimentare sviluppando applicazioni non commerciali.
[schnell] è la versione ultra-veloce per uso personale o per sviluppare in locale, ha una licenza Apache 2.0.
I modelli FLUX sono integrabili fin da subito con ComfyUI.
Cosa rende speciale FLUX.1?
Architettura ibrida con 12 miliardi di parametri (spiegherò cosa sono i parametri in una delle prossime pubblicazioni, abbiate pazienza).
Si basa su flow matching, un metodo molto efficiente per addestrare i modelli generativi. Funziona confrontando campi di vettori, che sono come "mappe" che mostrano la direzione in cui i dati devono essere trasformati (vi ho spiegato il concetto dei “vettori” nella prima pubblicazione di questo magazine), senza dover simulare il processo di trasformazione passo dopo passo. Questo rende l'addestramento di un modello più veloce e scalabile.
Utilizza gli embedding posizionali rotazionali, una tecnica che migliora la capacità dei modelli Transformer di comprendere le relazioni tra parole.
Tutto questo si traduce in:
Immagini estremamente dettagliate
Ottima comprensione dei prompt
Capacità di gestire molti più stili visivi
Capacità di generare scene molto complesse
Elon Musk colpisce ancora
Il 13 agosto, la startup xAI fondata da Elon Musk annuncia la versione Beta di Grok-2, il suo LLM disponibile a tutti gli utenti di X Premium. Insieme al modello principale, è stata rilasciata anche una sua versione “miniaturizzata” detta Grok-2 mini, in linea con le attuali tendenze del settore AI di produrre modelli più leggeri.

A detta dei suoi creatori, Grok-2 si distingue per le sue capacità di ragionamento, conversazione, coding e comprensione visiva, superando modelli come GPT-4-Turbo e Claude 3.5 in diversi benchmark. Ma la cosa più interessante di questo LLM, a parer mio, è la sua capacità di generare immagini di altissima qualità grazie all’integrazione del nuovo modello Flux.1 in partnership con Black Forest Labs.
Queste sue ottime capacità di ragionamento, unite alla generazione di immagini e alle altre funzionalità di X Premium lo rendono, in termini di rapporto qualità/prezzo ($8 al mese), un’ottima alternativa a ChatGPT Plus e Claude Pro.
Google Pixel 9
Sempre il 13 agosto, Google ha annunciato la sua nuova gamma si smartphone Pixel 9, potenziati da diverse funzionalità AI molto interessanti che promettono di semplificarci la vita quotidiana in ogni suo aspetto.

Eccovi quindi un breve elenco di funzionalità che ho ritenuto meritevoli di menzione:
“Aggiungimi”, permette di scattare una foto di gruppo senza dover chiedere a qualche estraneo di doverlo fare per noi. Ci basterà scattare più foto, alternandoci con il membro del gruppo rimasto fuori per eseguire lo scatto, e l’IA si occuperà di unire le immagini in un’unica fotografia per non escludere nessuno.
Gemini Live, un assistente AI che può comunicare con noi in modo conversazionale, permettendoci anche di interromperlo durante il dialogo.
Pixel Studio, un generatore d’immagini che viene eseguito direttamente all’interno del device.
Funzionalità avanzate di image editing, come la possibilità di riposizionare o rimuovere persone e oggetti all’interno di una foto.
Gemini Nano direttamente integrato nel dispositivo.
Ora aggiungo una mia piccola nota: difficilmente parlerò di smartphone nel corso di queste pubblicazioni, ma farò delle eccezioni in casi come questo, perché ritengo molto interessante far notare come l’IA, soprattutto quella generativa, stia diventando una tecnologia sempre più presente nelle nostre vite.
Si tratta di un qualcosa che finiremo per utilizzare senza nemmeno rendercene conto, e il bello deve ancora arrivare…
Un modello mistico
Il 16 agosto, sui social si inizia a parlare di un ennesimo, nuovo modello per le immagini, dal nome in codice “Mystic”.
Questo modello è stato creato in collaborazione tra la nota piattaforma di microstock Freepik (sulla quale sarà disponibile a breve), e la startup Magnific, della quale vi ho già abbondantemente parlano nelle scorse pubblicazioni e che è stata parzialmente acquisita proprio da Freepik.

A comunicarlo è stato proprio il fondatore di Magnific Javi Lopez, che mi ha anche fornito gentilmente un accesso in anteprima per testare il modello.
Ne ho quindi approfittato per fare un confronto tra questo modello (che sospetto essere una distillazione di Flux), Midjourney V 6.1 e Flux. Trovate questa comparazione come approfondimento speciale proseguendo nella lettura.
La nuova macchina dei sogni
Il 19 agosto, Luma Labs ha reso disponibile al pubblico Dream Machine 1.5, una versione aggiornata e significativamente migliorata del suo modello video.
Non c’è molto di cui parlare a riguardo, è sostanzialmente lo stesso modello di prima, con le stesse funzionalità e la stessa interfaccia, ma più preciso e potente.
L’edicola dei paper scientifici

Tre paper di ricerca per chiudere in bellezza il mese di agosto
Sketch2Scene - Un nuovo approccio che consente di creare automaticamente scene 3D interattive a partire da semplici schizzi a mano libera. Questo metodo utilizza un modello di diffusione 2D pre-addestrato per generare un'immagine isometrica che rappresenta la scena. Successivamente, un modulo di comprensione visiva interpreta questa immagine, segmentandola in componenti significativi come oggetti, alberi ed edifici, e creando una mappa del layout della scena. Questa mappa viene poi utilizzata da un motore di generazione procedurale, come Unity o Blender, per trasformare il layout in un ambiente 3D giocabile.
HumanVid - Un nuovo approccio per l'animazione di immagini umane. HumanVid si basa su un dataset composto da oltre 20.000 video in alta definizione, annotati utilizzando un estimatore di pose 2D e un metodo basato su SLAM per i movimenti della telecamera. Per integrare i dati reali, è stato creato un dataset sintetico con 2.300 asset 3D di avatar, arricchiti con una nuova metodologia di generazione della traiettoria della telecamera. Questo metodo consente di includere movimenti della telecamera diversificati e precisi, difficili da ottenere con i dati reali. Un modello di base chiamato CamAnimate è stato utilizzato per dimostrare che il training su HumanVid permette di controllare efficacemente sia la posa umana che i movimenti della telecamera, stabilendo un nuovo standard di riferimento nel campo. Il dataset è stato progettato per risolvere la mancanza di annotazioni precise sui movimenti della telecamera nei dataset pubblici esistenti, e le sperimentazioni hanno confermato che l'uso combinato dei dati reali e sintetici migliora notevolmente la qualità e il controllo dell'animazione delle immagini umane.
MovieDreamer - Un framework innovativo che consente la generazione automatica di video di lunga durata, come i film, mantenendo coerenza narrativa e visiva. Il metodo combina modelli autoregressivi con rendering basato su diffusione. La proposta principale è quella di utilizzare modelli autoregressivi per garantire la coerenza della trama su lungo periodo, prevedendo sequenze di token visivi che vengono poi convertiti in fotogrammi di alta qualità tramite un processo di diffusione. Questo approccio imita il processo tradizionale di produzione cinematografica, dove le trame complesse sono suddivise in scene gestibili. Viene impiegata anche una “sceneggiatura multimodale” che arricchisce le descrizioni delle scene con dettagli sui personaggi e lo stile visivo, migliorando la continuità e l'identità dei personaggi. I risultati dimostrano che MovieDreamer supera le capacità attuali nella generazione di video, offrendo contenuti visivamente dettagliati e coerenti su lunghi minutaggi.
Il mercatino dell’open-source

GFPGAN - Si tratta di un modello basato su Generative Adversarial Network per il restauro di immagini di volti umani. Molto utile per sistemare alcuni errori sui volti delle immagini generate con IA, o per eseguire il restauro di vecchie fotografie. Il repository su Github comprende anche un file di Google Colab per testare agilmente il modello senza doverlo installare sulla propria macchina.
DepthAnything V2 - La versione aggiornata e migliorata del precedente Depth-Anything, un modello per la stima della profondità da immagini monoculari. Basato sull'architettura DPT (Dense Prediction Transformer), il modello è stato addestrato su un dataset enorme di circa 62 milioni di immagini non etichettate. Ciò consente di ottenere risultati all'avanguardia nella stima della profondità relativa e assoluta. La particolarità di Depth-Anything è la capacità di generalizzare bene anche su dati mai visti prima (zero-shot learning), grazie a strategie di ottimizzazione e supervisione ausiliaria che permettono al modello di ereditare conoscenze semantiche dai pre-addestramenti. Il modello si presta bene anche all'integrazione con altri strumenti come ControlNet, migliorando ulteriormente le previsioni condizionate dalla profondità.
shadPS4 - Un emulatore di PlayStation 4 per Windows, Linux e macOS scritto in C++ che sta diventando popolare su Github. Come spesso accade, il progetto è stato iniziato per divertimento degli sviluppatori, e a causa del tempo libero limitato, probabilmente ci vorrà un po' prima che shadPS4 riesca a far girare qualcosa di decente. Dicono però che stanno cercando di eseguire dei piccoli commit con una certa regolarità.
Scontro tra Titani
Quello che seguirà, è un confronto dettagliato e onesto tra i modelli per la generazione di immagini più in voga del momento: Midjourney V 6.1, Mystic e Flux.1 (nella sua versione Flux Realism disponibile su Freepik).
Questo confronto punta a essere il più obiettivo possibile e, per raggiungere questo scopo, ho stilato una serie di criteri e parametri da rispettare. I modelli sono stati valutati sulla base di 5 prompt molto diversi tra loro per complessità generale, ambientazione e soggetti da rappresentare.
Per ognuno di essi sono state generate 4 immagini*, che non hanno subito alcun tipo di ritocco o alterazione. Di volta in volta, ho selezionato la mia preferita per metterle a confronto seguendo questi criteri:
Estetica complessiva: Quanto è particolare, interessante e appagante l’estetica dell’immagine presa in esame?
Aderenza al prompt: Il modello ha compreso appieno la mia richiesta?
Anatomia dei soggetti: Quanto sono anatomicamente corretti i soggetti, umani o animali, richiesti al modello?
Le immagini che vedrete hanno ricevuto un punteggio da 1 a 10 per ognuno dei tre criteri, i cui punteggi sono poi stati sommati per determinare quale modello ha performato meglio con un determinato prompt. Al termine dei 5 round, il modello con più vittore sarà nominato vincitore.
Seguiranno alcune considerazioni, sia tecniche che personali.
*Notare che Midjourney genera quattro immagini per volta, Mystic solo una e Flux due. Questo implica che, per ogni test, Midjourney ha avuto una sola iterazione del prompt, Mystic quattro e Flux due.
Prompt del primo round:
Extreme wide shot of three noblemen sitting in armchairs in a large room inside an English country house in the 1700s. Cinematic film still

Lo stile di Midjourney è sempre una garanzia, ma fa ancora un po’ di fatica con le anatomie, soprattutto quando gli vengono richiesti più soggetti a figura intera. Qui possiamo notare errori grossolani nelle gambe, nelle mani e persino sui volti.
L’aderenza al prompt è invece eccellente e l’unica cosa che non sembra aver capito, è il tipo di inquadratura, che dovrebbe essere un “campo larghissimo”, ovvero un’inquadratura estremamente larga con i soggetti molto distanti. Al suo posto, ha preferito rappresentare la scena con un “campo totale”, dove i soggetti hanno lo stesso peso rispetto all’ambiente circostante. Al di fuori di questa competizione, l’errore nell’inquadratura non sarebbe un problema, perché potrei allargarla facilmente in un secondo momento con la funzionalità “Zoom Out”.
Prima di assegnare i voti, mi prodigo nello spiegare rapidamente cosa avevo in mente con questo prompt. Mi sarebbe piaciuto vedere un’immagine molto più simile alle inquadrature del film Barry Lyndon di Stanley Kubrick, al quale mi sono ispirato per questo primo test.
Estetica complessiva: 9/10
Aderenza al prompt: 9/10
Anatomia dei soggetti: 6/10
Totale: 24/30

Per essere un nuovo modello ancora in fase Beta, devo dire che l’estetica di Mystic è assolutamente rispettabile, sicuramente tra le migliori che abbia mai visto, pur non arrivando al gusto estremamente raffinato di Midjourney.
L’aderenza al prompt è molto buona, e se non altro ha fatto un’inquadratura leggermente più larga rispetto a Midjourney. Il vero problema qui, è che a sbagliato il periodo storico di almeno un secolo!
Di contro, ha prodotto dei soggetti anatomicamente quasi impeccabili, l’unico difetto che ho trovato è nella mano sinistra dell’uomo seduto a destra.
Estetica complessiva: 8/10
Aderenza al prompt: 8/10
Anatomia dei soggetti: 9/10
Totale: 25/30

Flux Realism è invece il modello che ha performato peggio, con un’estetica molto banale e per nulla ricercata, molto simile alle immagini che si potevano ottenere qualche anno fa con i LoRA di Stable Diffusion o con la versione 4 di Midjourney.
In questo caso l’aderenza al prompt è leggermente superiore rispetto a Mystic, abbiamo una casa che è decisamente coerente con il periodo storico e uno dei tre personaggi ha esattamente l’outfit che dovrebbe avere.
L’anatomia è apparentemente ben fatta, ma con un po’ di zoom si possono notare molte imperfezioni sulle mani e sui volti. Gli do un voto in più rispetto a Midjourney solo perché le gambe risultano corrette.
Estetica complessiva: 7/10
Aderenza al prompt: 8/10
Anatomia dei soggetti: 7/10
Totale: 22/30
Questo primo round si conclude con la vittoria di Mystic.
Prompt del secondo round:
A flock of African Marabou gliding in the square of an Italian city. Some Marabou attack a group of teenage boys on the ground of the square while others lift them up in their beaks and carry them away flying. The sky has a scary color. Cinematic film still

Questo è stato il primissimo prompt che io abbia mai dato in input a un modello per le immagini. Deriva da un sogno che ho fatto nel 2022, nel quale uno stormo di Marabù africani dilaniava le carni di un gruppo di ragazzini nella piazzetta che vedo dalla finestra di casa mia. Un sogno molto strano, già.
Anche in questo caso, lo stile di Midjourney è di altissimo livello, ma le anatomie sono praticamente inesistenti. I ragazzini in mezzo alla piazza paiono un unico ammasso informe di carne e vestiti, mentre i pennuti sembrano dei piccioni giganti con il becco vagamente simile a quello del Marabù. In compenso, la piazza è fatta benissimo e nei bordi dell’immagine sono presenti anche le tipiche distorsioni delle ottiche grandangolari. Alti e bassi insomma, ma sul Marabù non mi sento di volerlo giudicare in maniera particolarmente negativa, perché in giro non si trovano molte immagini per avere un buon dataset su questo uccello.
L’aderenza al prompt risulta quindi discreta, nel senso che ha compreso la richiesta abbastanza da creare uno stormo di uccelli minacciosi in una piazza italiana, e sembra effettivamente che stiano attaccando i ragazzini, per quanto siano completamente deformati. Nulla che non si potrebbe risolvere con svariate decine di iterazioni extra.
Estetica complessiva: 9/10
Aderenza al prompt: 7/10
Anatomia dei soggetti: 5/10
Totale: 21/30

Mystic dimostra anche qui un’ottima capacità estetica, creando un’immagine abbastanza cinematografica e dettagliata. Risulta però pessima l’aderenza al prompt. Lo stormo di uccelli non è in alcun modo definibile come tale, l’immagine non comunica il senso di terrore che dovrebbe, nessuno è sotto attacco e la piazza è diventata un tipico corso italiano.
Ottime come sempre le anatomie, anche se qui gioca facile perché ha deciso di fare tutti i soggetti di spalle o molto lontani e sfocati.
Estetica complessiva: 8/10
Aderenza al prompt: 5/10
Anatomia dei soggetti: 8/10
Totale: 21/30

Flux realism si conferma il peggiore dei tre, con un’estetica che arriva direttamente da fine 2022. Uccelli che paiono incollati male in photoshop, una colorazione simile ai filtri di Instagram, le case piatte e identiche tra loro, e le persone che sono solo delle sagome senz’anima.
L’anatomia è praticamente inesistente, sia per gli uccelli che per le persone. Un disastro sotto ogni aspetto, e decisamente tra le immagini più brutte che abbia mai ottenuto come output da un modello.
Estetica complessiva: 5/10
Aderenza al prompt: 5/10
Anatomia dei soggetti: 5/10
Totale: 15/30
Il secondo round si conclude con un pareggio tra Midjourney e Mystic.
Prompt del terzo round:
Adrenaline-fueled chase scene shot from the front. A mysterious man runs breathlessly while being chased by a police detective in a dark alley in Seoul. Cinematic film still from a Korean thriller

Questo prompt deriva dal mio amore per i film asiatici, e in particolare per i thriller prodotti in Corea del Sud. Con queste immagini ho tentato di ricreare la “famosa” scena dell’inseguimento del film The Chaser di Na Hong-jin.
Qui l’estetica di Midjourney non mi ha fatto impazzire, pur rimanendo di alto livello, trovo che sia sottotono rispetto ai suoi standard. L’aderenza al prompt è mediocre, nel senso che ha compreso a grandi linee la mia intenzione, ma ha aggiunto un personaggio di troppo e nel complesso non rende l’idea di un inseguimento disperato.
Ottima invece la rappresentazione di un vicolo di Seul, nei film sud coreani appaiono esattamente così. Le anatomie non sono niente male ma risultano un po’ strane rispetto alla posa dei personaggi.
Estetica complessiva: 8/10
Aderenza al prompt: 7/10
Anatomia dei soggetti: 7/10
Totale: 22/30

Mystic in questo caso ha saputo tener testa a Midjourney in termini estetici, creando un’immagine molto realista e dai colori tipici di questa tipologia di film.
L’aderenza al prompt è nella media, mentre l’anatomia risulta leggermente migliore rispetto a Midjourney. L’unica cosa strana che noto, è la proporzione del braccio sinistro del personaggio in primo piano. Anche i muri non sono molto coerenti con lo stile di Seul, ma questo glielo perdoniamo.
Estetica complessiva: 8/10
Aderenza al prompt: 7/10
Anatomia dei soggetti: 8/10
Totale: 23/30

Qui Flux Realism mi ha stupito. Seppur l’estetica sia complessivamente un po’ inferiore agli altri due modelli, ha mantenuto un’aderenza al prompt molto più sensata, dando un minimo l’idea dell’inseguimento.
L’anatomia è praticamente impeccabile, con un leggero errore nella forma/posizione delle gambe del soggetto in background.
Estetica complessiva: 7/10
Aderenza al prompt: 8/10
Anatomia dei soggetti: 9/10
Totale: 24/30
Il terzo round viene vinto da Flux Realism.
Prompt del quarto round:
A small red vintage plane flying in a blue sky with clouds, pulling a banner that says "IMAGINE"

Questo è un prompt abbastanza semplice, pensato per mettere alla prova la capacità di questi modelli di generare un testo coerente rispetto alla scena.
L’estetica di Midjourney non delude, dando un tocco molto vintage all’immagine pur non avendoglielo chiesto esplicitamente in termini stilistici (nel prompt, “vintage” è riferito solo all’aereo). Anche l’aderenza è molto buona, nonostante non abbia ben compreso che il banner dovrebbe venir trainato dall’aereo.
In questo caso, col termine “anatomia” dobbiamo necessariamente riferirci al modo in cui è stato rappresentato l’aereo, che risulta sicuramente ben fatto.
Estetica complessiva: 8/10
Aderenza al prompt: 8/10
Anatomia dei soggetti: 8/10
Totale: 24/30

Mystic rimane coerente con la sua estetica, fornendo un’immagine un po’ meno interessante e sicuramente più caricaturale rispetto a Midjourney.
L’aderenza al prompt non risulta particolarmente solida, dato che non ha ben compreso la richiesta di generare un banner ma ha preferito inserire una sorta di bandiera che lascia una scia bianca come se avesse una propulsione a motore. Anche l’istruzione di inserire la scritta “imagine” è stata completamente ignorata.
L’aereo appare invece molto realistico e l’effetto del movimento sull’elica frontale penso che sia un tocco di classe da non sottovalutare, che aggiunge un certo dinamismo alla scena complessiva.
Estetica complessiva: 7/10
Aderenza al prompt: 7/10
Anatomia dei soggetti: 8/10
Totale: 22/30

Flux Realism è quello che mi ha restituito l’immagine peggiore, con un’estetica fin troppo simile a quello che si poteva ottenere mediamente nel 2022 da qualunque modello per le immagini.
Presenta però una buona aderenza al prompt, rappresentando un aereo effettivamente molto datato, che quanto meno tenta di trascinare un piccolo banner sul quale è effettivamente presente la scritta che ho richiesto.
Lo stesso si potrebbe dire per la forma dell’aereo, che presenta solo dei piccoli errori nel modo strano in cui viene trascinato il banner e sull’elica.
Estetica complessiva: 5/10
Aderenza al prompt: 7/10
Anatomia dei soggetti: 7/10
Totale: 19/30
Il quarto round se lo porta a casa Midjourney.
Prompt del quinto round:
Inside a poor, dilapidated apartment in the center of Beijing lives an elderly lady with her little grandson. 35mm film style

Il prompt di quest'ultimo round vuol rappresentare un piccolo spaccato di quella che è la vita quotidiana di un pezzo di mondo poco conosciuto da noi occidentali: Lo stato di indigenza e povertà assoluta di una grossa fetta della popolazione Cinese, un qualcosa di molto lontano dalle solite rappresentazioni moderne di Pechino e Shangai che siamo abituati a vedere online.
Qui Midjourney si è superato, creando un’immagine che non solo ha un livello estetico degno del World Press Photo, ma che appare anche estremamente umana e verosimile nel suo modo di rappresentare l’ambientazione e la dinamica che si svolge al suo interno. Sembra quasi di poter sentire i rumori e gli odori di quel minuscolo appartamento nella periferia di Pechino.
L’aderenza al prompt è assolutamente perfetta, riuscendo a catturare l’essenza più profonda della richiesta.
L’unico aspetto ad apparire un po’ mediocre è l’anatomia, che pur risultando molto semplice da rappresentare, per via dei soggetti messi di spalle, è riuscito a sbagliare la posizione delle gambe del bambino, che appaiono un po’ troppo a sinistra rispetto a quanto dovrebbero essere.
Estetica complessiva: 10/10
Aderenza al prompt: 10/10
Anatomia dei soggetti: 6/10
Totale: 26/30

Mystic regge benissimo il confronto, creando un’immagine stupenda ma un po’ troppo stereotipata in termini di composizione, illuminazione e dettagli generali, come le scritte in caratteri cinesi che decorano le pareti.
L’aderenza al prompt è abbastanza impeccabile, pur non arrivando a essere convincente quanto la rappresentazione complessiva di Midjourney.
Ottime le anatomie, anche se ingrandendo un po’ l’immagine risultano subito evidenti delle imperfezioni nelle mani della signora e sul volto del bambino.
Estetica complessiva: 8/10
Aderenza al prompt: 9/10
Anatomia dei soggetti: 8/10
Totale: 25/30

Flux Realism si riconferma il peggiore dei tre, creando un’immagine dall’estetica molto debole, che sarebbe stata apprezzabile qualche anno fa ma che non regge il confronto con gli altri due modelli.
L’aderenza al prompt è molto buona, ma un po’ esagerata nel grado di fatiscenza con cui ha rappresentato l’appartamento, che risulta anche fin troppo spoglio rispetto a come sarebbe probabilmente nella realtà.
L’anatomia dei soggetti è invece terribile, facendo un po’ di zoom si può notare come il bambino sia diventato un tutt’uno con le mani della nonna che lo tiene in braccio, come due statue di cera che si sono sciolte insieme.
Estetica complessiva: 6/10
Aderenza al prompt: 8/10
Anatomia dei soggetti: 5/10
Totale: 19/30
Il vincitore di quest’ultimo round è Midjourney, che vince anche la competizione nel suo insieme. Ecco un rapido riepilogo di questi cinque test:
Round 1: Vince Mystic
Round 2: Pareggio Midjourney - Mystic
Round 3: Vince Flux Realism
Round 4: Vince Midjourney
Round 5: Vince Midjourney
Riflessioni conclusive:
Questa tipologia di test, nei quali vengono confrontati i modelli solo in base a dei prompt, iniziano a lasciare un po’ il tempo che trovano, perché non considerano la sempre più grande varietà di strumenti disponibili insieme ai modelli, che permettono di aumentare la personalizzazione e il controllo che l’utente ha sulle immagini.
Ad esempio, se avessi utilizzato l’Inpainting di Mystic per sistemare i suoi piccoli errori anatomici, avrebbe sempre preso 10 in quella categoria. Mentre Midjourney, grazie al suo editor e alla possibilità di utilizzare i propri codici personalizzati che migliorano mediamente la qualità degli output, avrebbe probabilmente vinto tutti e cinque i round. Perché la verità è che oggi questi strumenti stanno diventando sempre più complessi e flessibili, e il solo “prompt testuale” non è più sufficiente a farci ottenere delle ottime immagini.
Il focus si sta quindi spostando da “genero tante immagini e poi faccio una selezione” a “genero poche immagini e ci lavoro finché non sono perfette per il tipo di risultato che voglio ottenere”.
Detto ciò, mi sento comunque di voler affidare a Mystic il titolo di “Vincitore Morale”, perché si tratta di un modello ancora in fase embrionale che è comunque riuscito a tener testa egregiamente a Midjourney, superandolo spesso su molti aspetti come l’anatomia dei soggetti e l’aderenza al prompt.
La competizione in questo settore sta diventando sempre più agguerrita, e penso proprio che nei prossimi anni ne vedremo delle belle!
Neo Cinema: la nuova frontiera della settima arte
Sono lieto di concludere questo terzo numero di Tales from the Latent Space con un contenuto davvero esclusivo per il panorama italiano - Un’intervista scritta a Dustin Hollywood, uno dei maggiori esponenti e promotori dell’emergente movimento di filmmaker indipendenti chiamato Neo Cinema.
Quando tra qualche mese o anno inizierete a sentir parlare anche qui da noi di questo movimento internazionale, fatemi il favore di ricordarvi che il primo a portare un simile approfondimento in Italia è stato questo magazine.

Mi spiegheresti cos'è il Neo Cinema come se fossi una nonna di 80 anni?
Il Neo Cinema è un nuovo modo di realizzare e guardare film, che combina le tecniche cinematografiche tradizionali con tecnologie moderne come l'intelligenza artificiale e la realtà virtuale. È come quando i film sono passati per la prima volta dal muto al sonoro e al colore: rende l'esperienza più emozionante e coinvolgente.
Chi sono i principali sostenitori di questo movimento?
Sono i creatori pionieristici che stanno spingendo i confini dell'arte e della tecnologia. Tra questi ci sono io, Dustin Hollywood e il team di Escape, così come numerosi altri artisti straordinari come Dave Clark, The Reel Robot, Aze Alter, Reza Safai, Justin Hounkpatin, MetaPuppet, Davide Bianca, Nem Perez, AbelArt, Jeff Synthesized, Brett Stuart, Uncanny Harry, Chrissie e molti altri, troppe persone fantastiche da menzionare qui. Escape è la nostra risposta alla vecchia Hollywood e a come venivano fatte le cose, è una nuova piattaforma di streaming che supporta i creatori e distribuisce le loro storie innovative. I fondatori di Escape, Heiner Lippman e John Gaeta, famosi per Matrix, sono altre due figure chiave per questo movimento.
Puoi spiegare i principi fondamentali e la visione alla base del Neo Cinema?
Ottima domanda, ciò che facciamo in ESCAPE è curare e distribuire nuove forme radicali di intrattenimento. Quindi cosa significa, beh, significa che celebriamo e supportiamo i creatori pionieristici che spingono i limiti dell’IA generativa e di tecnologie legate al Gaming come il 3D/Blender/Cinema 4D/ecc., fashion movies avanguardistici, video musicali e molto altro ancora alla ricerca di narrazione, esperienza e arte. Chiamiamo questa classe emergente di contenuti: Neo Cinema.
È uno spirito e un movimento (ad alta velocità) che sta spingendo il prossimo paradigma di narrazione e creazione di universi narrativi. La creazione di mondi e l'aiuto ai creatori per la creazione della propria IP sono importanti per noi. Si basa sulle fondamenta del cinema, ma al tempo stesso lo sconvolge e lo fa evolvere. Pensiamo davvero che nel mondo odierno abbiamo bisogno di provare cose nuove ed esplorare nuovi modi di connetterci con i creatori e il loro pubblico. Questo è il prossimo livello di evasione dal mondo in cui siamo immersi ogni giorno, un posto in cui la tua mente può sfuggire al rumore e trovare ispirazione e intrattenimento.
In che modo la tecnologia può migliorare il processo di realizzazione di un film e l'esperienza visiva?
La tecnologia odierna migliora la realizzazione di un film in così tanti modi che è impossibile nominarli tutti. In generale, è fornendo nuovi strumenti e metodi per i creatori che rendono il processo più efficiente ed espandono le possibilità creative.
Prendiamo ad esempio l’intelligenza artificiale. Può aiutare con la sceneggiatura e il montaggio, mentre la modellazione 3D e i motori di gioco come Unreal Engine possono creare effetti visivi più realistici e coinvolgenti.
A suo tempo, Adobe ha completamente rivoluzionato la creatività sotto forma di software. Per gli spettatori, la tecnologia può rendere l'esperienza più interattiva, ad esempio attraverso la realtà virtuale, dove possono sentirsi come se fossero all'interno del film, e personaggi AI in tempo reale che rispondono al feedback del pubblico come NPC.
Che tipo di impatto ti aspetti che avrà il Neo Cinema sull'industria cinematografica attuale?
Ci si aspetta che il Neo Cinema rivoluzioni l'industria cinematografica, rendendola più inclusiva e innovativa. Abbasserà le barriere d'ingresso per i nuovi creatori, consentendo una maggior diversità di voci e idee. L'industria vedrà anche nuove forme di monetizzazione e distribuzione, sfruttando i social media e le piattaforme interattive per coinvolgere il pubblico in modi nuovi e dare ai creatori la possibilità di costruire IP attorno a quel pubblico.
In che modo registi e creativi possono essere coinvolti in ESCAPE e il Neo Cinema?
Possono unirsi a piattaforme come Escape, che supportano e distribuiscono i contenuti del Neo Cinema. Possono sfruttare nuove tecnologie come l'intelligenza artificiale, la modellazione 3D e i motori di gioco per sperimentare la loro narrazione e condividere il loro lavoro con me che sono un curatore della piattaforma.
Presto avremo un processo allineato per dare ai creatori la possibilità di condividere di più con noi e la nostra rete. Escape offre un modello basato sui creator, che combina la portata di una piattaforma di streaming di fascia alta con l'agilità dei social media, fornendo strumenti e supporto per progetti innovativi.
Siamo alla ricerca di questi creator da ogni parte del globo per poter supportare loro e il loro lavoro. Potete unirvi al nostro Discord per condividere il vostro lavoro e chattare con la nostra community!
Puoi condividere un aneddoto o un'esperienza personale che evidenzi l'essenza del Neo Cinema?
Sebbene non abbia un aneddoto personale, posso illustrare l'essenza del Neo Cinema con un esempio: immagina un regista che usa Unreal Engine 5 per creare un intero mondo virtuale in cui gli spettatori possono interagire con la storia in tempo reale. Potrebbero osservare il viaggio di un personaggio, ma avere anche la possibilità di esplorare l'ambiente, scoprire elementi narrativi nascosti e influenzare la narrazione.
O forse hai creato una serie di contenuti episodici con cui stai costruendo un IP a lungo termine, sviluppando dei personaggi con cui il pubblico può relazionarsi e seguire il loro viaggio attraverso la tua storia. Questo tipo di coinvolgimento è al centro del Neo Cinema, che fonde la narrazione tradizionale con tecnologie all'avanguardia per creare un'esperienza davvero coinvolgente.