


Sussurri e grida dal Nuovo Mondo
Non tutte le urla chiedono di essere ascoltate, e non tutto ciò che tace merita il silenzio. Quando la nebbia si dirada, il mondo ci appare diversamente


Nel Nuovo Mondo, il mese di ottobre 2024 è stato a dir poco straordinario.
Una quantità inverosimile di avvenimenti si sono susseguiti con una rapidità senza precedenti, tanto che ho dovuto selezionare con ancor più cura del solito le notizie per la rubrica Avvenimenti del mese, che rischiava di diventare talmente ricca di informazioni da monopolizzare metà del magazine.
Ho dovuto rinunciare a molte novità interessanti per limitare il rumore informativo e dare il giusto spazio a tutti gli altri contenuti della pubblicazione.
Pensate che, nella sola settimana che va dal 21 al 27 ottobre, si è verificata una media di due annunci importanti al giorno, che ha messo a dura prova la mia capacità di seguire approfonditamente l’evoluzione del Nuovo Mondo.
Guardando al 2024 in prospettiva, mi sento di dire che ottobre è stato probabilmente il mese nel quale sono state annunciate più novità in assoluto. Questo conferma la teoria secondo la quale siamo arrivati al punto in cui l'evoluzione e il progresso di una civiltà diventano veramente esponenziali.
Questo numero di Tales from the Latent Space contiene anche la prima collaborazione del magazine, che apre ufficialmente le porte del Nuovo Mondo a chiunque abbia il desiderio di apportare il suo contributo a questo progetto editoriale.
Infatti, uno degli approfondimenti di ottobre è stato scritto col gentile contributo dell’associazione ForeseeAI, che si dedica alla promozione di un'educazione etica all'intelligenza artificiale.
Tempi interessanti ci attenderanno al rarefarsi della nebbia autunnale, ma per assistervi dobbiamo allontanarci dalla linea gialla, che il nostro treno sta per partire…

Perché le mani sono un problema?
Spesso non ci facciamo caso, ma le mani sono strutture incredibilmente complesse, che ci permettono di comprendere meglio il mondo che ci circonda e manipolarlo a nostro piacimento. Sono composte da una miriade di ossa, articolazioni, muscoli e legamenti che lavorano insieme per consentirci di compiere i movimenti più disparati. Complessivamente, una mano si compone di 27 ossa, 30 muscoli, più di 100 tendini e legamenti, unghie, nervi e tantissimi vasi sanguigni visibili attraverso la pelle. Tutti questi elementi cooperano per consentirci di muovere ogni dito in modo preciso e indipendente, offrendoci possibilità uniche nel regno animale.
Alla luce di queste informazioni, possiamo comprendere più facilmente quanto possa essere complicato rappresentare le mani in un disegno.

Anche un piccolo errore nella proporzione, nella lunghezza delle dita o nella posizione di un'articolazione può fare la differenza tra una mano che sembra naturale e una che appare stranamente deformata. Per gli artisti, questo richiede uno studio approfondito dell'anatomia e molta pratica nel disegno dal vero. Molti illustratori tendono infatti a evitare di dover disegnare le mani, nascondendole dietro altri elementi o stilizzandole per semplificare il processo.
Le mani sono anche tra gli strumenti di comunicazione non verbale più potenti di cui disponiamo. Ogni piccola variazione nella postura della mano può trasmettere emozioni, intenzioni e messaggi nascosti. Questo significa che il nostro cervello può dedicare un'attenzione particolare ai dettagli delle mani, sia nel contesto reale che in rappresentazioni artistiche.
I modelli di deep learning vengono addestrati su enormi quantità di immagini, ma per le mani è difficile trovare un set di dati che includa tutte le possibili forme, posizioni, prospettive e dettagli minuti necessari a una comprensione accurata della loro struttura. Quando le mani afferrano o utilizzano determinati oggetti, la loro forma e la disposizione delle dita possono diventare estremamente complesse. Ad esempio, quando si cerca di tenere molti oggetti contemporaneamente, le dita potrebbero apparire in posizioni strane e intrecciate, creando forme che appaiono distorte o difficili da interpretare guardando una fotografia. I modelli devono quindi cercare di generalizzare tra una moltitudine di caratteristiche differenti.
Va poi notato che, a differenza degli umani, l'intelligenza artificiale manca di una comprensione contestuale autentica e non possiede una conoscenza reale degli oggetti e di come si relazionano col mondo fisico. In altre parole, l'IA non sa veramente cosa sia una mano, così come non sa praticamente nulla della realtà empirica. Il suo apprendimento è puramente statistico, basato su pattern riconosciuti in dataset etichettati che spesso sono incompleti o contengono inesattezze. Di conseguenza, quando generano immagini possono produrre mani deformate, con un numero errato di dita, pose innaturali o proporzioni scorrette.
Anche molti illustratori e animatori professionisti hanno grosse difficoltà nel rappresentare le mani in modo realistico. In molti fumetti e cartoni animati, la soluzione più comune per ridurre la complessità è quella di semplificare il numero di dita. Personaggi come quelli dei Simpson o dei classici Disney hanno sempre quattro dita per mano per velocizzare i tempi di produzione delle opere.
Un'altra tecnica comune è la stilizzazione delle mani, con forme arrotondate e movimenti esagerati che aiutano a evitare l'accuratezza anatomica e a privilegiare l'espressività. Riducendo i dettagli più complessi, gli animatori riescono a mantenere le mani coerenti e riconoscibili senza il rischio di errori evidenti.
Un possibile metodo per risolvere questo e altri problemi simili in futuro, potrebbe essere quello di creare immagini partendo da simulazioni 3D. In ambienti simulati, l'IA potrebbe acquisire una comprensione più coerente dello spazio, delle prospettive e dell'interazione delle mani con l'ambiente, migliorando la qualità e la controllabilità delle immagini generate.
I progressi recenti hanno portato a dei miglioramenti significativi nella qualità e precisione delle immagini, ma è probabile che rappresentare le mani in modo realistico e accurato continuerà a essere una delle maggiori sfide per i modelli generativi di immagini e video.
Avvenimenti del mese
Le notizie più interessanti e creative dal mondo della tecnologia, accuratamente selezionate per districarsi tra il rumore informativo.

L’alga cinese è sempre più verde
Il 30 settembre, hanno iniziato a circolare sul web i primi video dimostrativi di Seaweed, il nuovo modello AI per i video del colosso cinese ByteDance.

Rispetto ad altri modelli per i video, Seaweed migliora significativamente la coerenza e la diversità dei personaggi nelle scene, risolvendo problemi come distorsioni visive o glitch durante azioni complesse. Le interazioni tra più personaggi sono fluide e naturali, e l’uso dinamico di angolazioni e movimenti di camera rende i video prodotti estremamente realistici. I modelli AI cinesi stanno diventando sempre più potenti, e nel campo video hanno ormai surclassato qualunque altro modello occidentale.
Forse il miglior modello per le immagini di tutti i tempi
Il 2 ottobre, Black Forest Labs ha rilasciato Flux1.1, l’aggiornamento del suo già eccellente image model Flux1.

FLUX1.1 è sei volte più veloce rispetto al suo predecessore FLUX.1, ha una qualità d'immagine più alta, una maggior precisione nel seguire i prompt e una diversità più ampia negli output. Il modello è stato anche testato con il nome in codice "blueberry" all'interno dell'arena di benchmark Artificial Analysis, dove ha superato tutti gli altri modelli, ottenendo il punteggio Elo più alto.
Avatar AI indistinguibili dalla realtà
Sempre il 2 ottobre, HeyGen ha lanciato i suoi nuovi Avatar 3.0, una miglioria significativa in termini di realismo rispetto alla versione precedente, e una probabile risposta ai nuovi avatar del competitor Synthesia, lanciati poche settimane fa.

Gli avatar di HeyGen sono ora sono in grado di interpretare in modo dinamico le sfumature del testo, offrendo espressioni facciali e inflessioni vocali che si adattano alle parole pronunciate, creando un'esperienza video ancora più coinvolgente.
Una delle novità più sorprendenti, è la possibilità di far cantare gli avatar. Questo apre le porte a nuove possibilità per creatori di contenuti, musicisti e chiunque voglia sperimentare con l’IA. L’azienda ha introdotto anche un sistema che permette di caricare un numero illimitato di filmati per personalizzare gli avatar. Questo consente agli utenti di creare contenuti con infinite combinazioni di stili, grazie alla possibilità di cambiare sfondi, abiti, pose e angolazioni della videocamera.
Pochi giorni dopo, il 17 ottobre, HyeGen ha presentato i suoi Interactive Avatar, che possono partecipare a uno o più meeting su Zoom contemporaneamente, 24/7. Questi avatar non solo imitano l'aspetto e la voce dell'utente, ma sono in grado di pensare, parlare e prendere decisioni basandosi sulle informazioni e sulla personalità che gli vengono assegnate. Risultano quindi perfetti per contesti come coaching online, supporto clienti, chiamate di vendita e interviste.
Va però notato che questi avatar interattivi in tempo reale hanno dei costi elevati e sono attualmente limitati a sessioni di massimo 10 minuti consecutivi.
Attori AI
Il 3 ottobre, Hedra Labs ha rilasciato Character-2, l’attesissimo aggiornamento del suo modello Image2Video e Audio2Video per la generazione di personaggi parlanti.

l'annuncio di Character-2 segna un'importante svolta verso lo sviluppo di modelli per la creazione di personaggi in grado di esprimere intelligenza ed emotività.
Tra le novità principali di questa versione troviamo il supporto per formati widescreen e verticali, eliminando ogni limitazione precedente di aspect ratio. Un altro grande passo in avanti è l'aumento della qualità generale, con immagini molto più nitide e personaggi più espressivi.
Il nuovo editor di OpenAI
Sempre il 3 ottobre, OpenAI rilascia Canvas, una nuova interfaccia per lavorare con ChatGPT su progetti di scrittura e programmazione che vanno oltre la semplice chat.
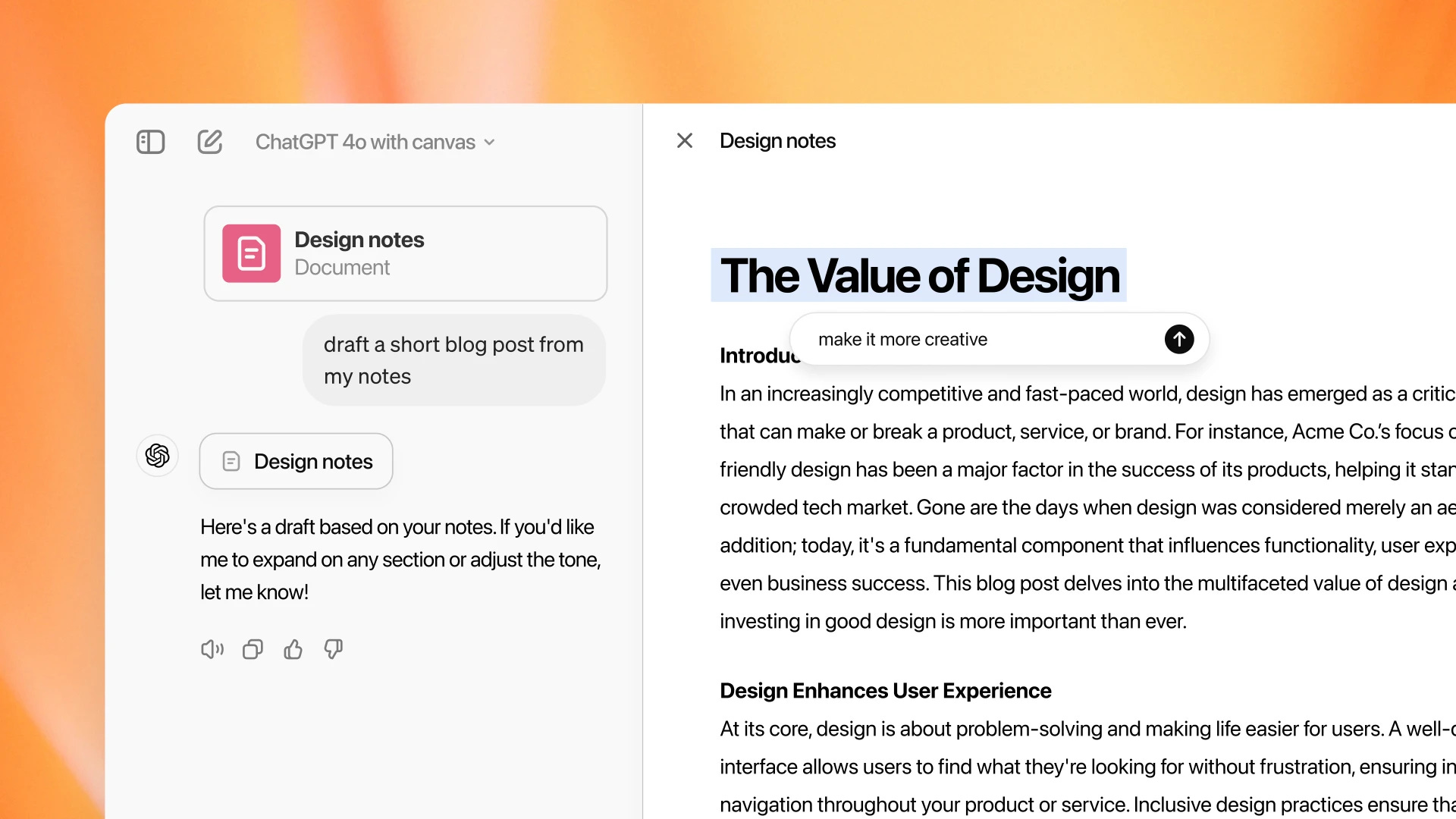
ChatGPT è già un grande aiuto per la scrittura e il coding, ma spesso la classica interfaccia di chat non basta per progetti più complessi. Ed è proprio qui che entra in gioco Canvas: permette di modificare testo e codice mentre ChatGPT fornisce suggerimenti ed esegue modifiche su richiesta. Un vero e proprio copilot che aiuta a riscrivere, correggere e perfezionare.
Tra le funzionalità principali, ci sono scorciatoie per modificare la lunghezza dei testi, adattare la complessità dello stile di scrittura e aggiungere tocchi finali come il controllo della grammatica e persino l’aggiunta di emoji.
Per i programmatori, Canvas semplifica la revisione del codice, aggiunge log per il debug e commenti per migliorare la leggibilità. Puoi anche tradurre il codice in altri linguaggi come JavaScript, Python e C++.
Più avanti nel magazine troverete un articolo di approfondimento su Canvas.
Il Meta Cinema, ma in un altro senso
Il 4 ottobre, Meta ha annunciato Meta Movie Gen, la sua nuova suite di modelli AI avanzati per la generazione e manipolazione di media.

I riflettori sono stati puntati su due modelli principali: Movie Gen Video, che con i suoi 30 miliardi di parametri è in grado di generare video e immagini di alta qualità a partire da un prompt testuale; e Movie Gen Audio, un modello da 13 miliardi di parametri capace di creare effetti sonori perfettamente sincronizzati con le clip video.
La suite offrirà anche funzionalità avanzate di video editing, che consentono di modificare video reali o generati semplicemente descrivendo le modifiche con un prompt. Sarà anche possibile creare video personalizzati partendo da un’immagine e un prompt, ottenendo una clip che mantiene la coerenza del personaggio.
Meta sta anche collaborando con professionisti del settore per migliorare ulteriormente questi modelli prima del rilascio pubblico.
L’era dei Robot
Il 10 ottobre, presso gli studi Warner Bros a Burbank, California, si è tenuto l’evento We, Robot, nel quale Tesla ha mostrato al pubblico la sua nuova flotta di veicoli autonomi, Robotaxi e Robovan, insieme al suo già famoso robot umanoide Optimus.

È stato presentato il Robotaxi, un veicolo completamente autonomo simile al Cybertruck ma senza volante né pedali, e il Robovan, un pulmino dal design futuristico con 20 posti a sedere, progettato per ottimizzare la logistica e il trasporto merci. Ma penso che il vero protagonista della serata sia stato Optimus.
Vestito come un barista del Far West, il robot umanoide ha servito drink alla spina e intrattenuto gli ospiti con i suoi movimenti e la sua voce. Una dozzina di questi robot erano in giro per l'evento, interagendo con le persone in modo simpatico e giocoso.
C’è però chi pensa che i robot fossero radiocomandati a distanza.
Durante l’evento, Musk ha ribadito la sua visione di un futuro in cui robot e umani convivono in sinergia, delegando a loro i compiti più stancanti e ripetitivi. Ha anche confermato che l’Optimus di Tesla avrà un prezzo compreso tra i 20.000 e 30.000 dollari, definendolo il prodotto più grande di sempre.
In un mondo in cui l'aspettativa di vita è in crescita e il tasso di natalità cala drasticamente, viene da pensare che l'avvento dei robot sia una condizione più che necessaria per garantirci una vita serena.
Pronti al decollo
Il 13 ottobre, SpaceX ha nuovamente cambiato le regole della Space Economy grazie a un altro traguardo che passerà alla storia di questo settore: catturare in volo un razzo Super Heavy Booster al primo tentativo.

Quello che vedete nell’immagine, ma di cui vi consiglio il video, non è un semplice supporto di lancio come quelli che siamo abituati a vedere sin dalle missioni Apollo.
Si tratta infatti di un gigantesco robot, chiamato Mechazilla, progettato per catturare i razzi e rimetterli in posizione di partenza. Questo permette di risparmiare tempo, risorse e costi di manutenzione. Con l'obiettivo di poter eseguire un nuovo lancio nel giro di un'ora, fino a 3 lanci al giorno.
Durante il test, il Super Heavy è stato lanciato nello spazio, ha separato lo stadio superiore Starship ed è tornato alla base per essere catturato. Il razzo ha eseguito una delicata manovra di hovering, consentendo alle enormi braccia di Mechazilla di afferrarlo con precisione. Questo successo segna un passo cruciale verso l'obiettivo di SpaceX: rendere i viaggi spaziali sostenibili, frequenti e accessibili.
L’eliminazione delle "gambe" di atterraggio del razzo, presenti in altri modelli come il Falcon 9, semplifica la progettazione, riduce il costo di produzione e il peso complessivo, aumentandone contemporaneamente la longevità.
La Maxi-conferenza di Adobe
Tra il 14 ottobre e il 16 ottobre si è tenuto Adobe Max, l’attesissima conferenza annuale di Adobe sui suoi nuovi prodotti e sul futuro della creatività.

Adobe ha presentato oltre 100 aggiornamenti per i prodotti Creative Cloud, tra cui nuovi strumenti di IA generativa integrati in Photoshop, Illustrator, InDesign e Premiere Pro. Questi nuovi strumenti permettono ai creativi di realizzare progetti complessi con un’efficienza mai vista, lasciando più tempo per idee e concetti.
Photoshop ha introdotto la funzione Distraction Removal nel suo strumento di Rimozione, che permette di identificare automaticamente elementi indesiderati, come persone, fili e cavi, e rimuoverli con un solo clic. Questa feature, simile alla Magic Eraser di Google, è già disponibile su Photoshop per desktop e web, e promette ulteriori miglioramenti nel prossimo futuro. Le funzionalità Generative Fill, Generative Expand, Generate Similar e Generate Background sono state migliorate grazie al nuovo modello Firefly Image 3.
Adobe Illustrator si arricchisce con Objects on Path, una funzione che consente di allineare, disporre e muovere oggetti lungo un percorso definito, facilitando la creazione di layout più complessi. La funzione Mockup per simulare disegni su modelli 3D è ora disponibile per tutti, mentre l’Image Trace è stato ottimizzato per produrre vettoriali con contorni più netti e fedeli all’immagine originale.
InDesign beneficia della funzione Generative Expand, già nota agli utenti di Photoshop, che permette di estendere immagini per adattarle a layout di dimensioni variabili. Questo strumento è particolarmente utile per la progettazione grafica editoriale.
Premiere Pro introduce in beta il nuovo Firefly AI Video Model con la funzione Generative Extend, che consente di estendere video per adattarli a specifiche esigenze di montaggio. Questo modello rappresenta una novità per il settore video e si prevede che sia integrato in altre applicazioni della suite Adobe Creative Cloud nei prossimi mesi
Tra le novità più interessanti, c’è anche Adobe GenStudio per il Performance Marketing, che unisce AI e linee guida dei brand per creare asset pubblicitari personalizzati in pochi clic. L’azienda ha poi presentato Content Credentials, un servizio che permette ai creatori di associare metadati verificabili ai propri lavori, come nome e storia dell’editing, per garantire l'autenticità dei contenuti digitali.
Il parco giochi dell’immaginazione
Il 16 ottobre, Kaiber ha completamente rivoluzionato la sua offerta di prodotti AI lanciando il Superstudio; un ambiente virtuale infinito, simile a una lavagna, nel quale fare brainstorming, creare prototipi e far emergere nuove idee in totale libertà.

Un parco giochi per accelerare l'immaginazione. Superstudio riunisce i migliori strumenti di intelligenza artificiale, tra cui il modello video di Luma Lab, il modello Flux Image e i modelli di immagini e video di Kaiber, per consentire ad artisti e creativi di dare vita alla loro immaginazione più sfrenata all'interno di un'unica interfaccia intuitiva.
Oggi inizia l’era del cinema IA
Il 17 ottobre, è stato pubblicato su YouTube Where the Robots Grow, il primo film realizzato con l'IA, prodotto da Pigeon Shrine e AiMation Studios.

Tecnicamente parlando, non si tratta del "primo film realizzato con l'IA", dato che sono già stati prodotti centinaia di cortometraggi di ottima qualità con questa tecnologia, e che "film" è solo un termine generico per riferirsi a determinati prodotti audiovisivi, indipendentemente dalla durata. Non è neanche il primo lungometraggio AI in assoluto, ma è certamente il primo in grado di competere con prodotti d'intrattenimento ben più costosi e complessi come i film della Pixar.
Tom Paton, CEO della casa di produzione, ha detto su X che più avanti sveleranno anche le tecniche utilizzate per creare l'opera. Aggiungendo che "non c'è un singolo fotogramma nel film che non utilizzi l'intelligenza artificiale al suo interno, in un modo o nell'altro". Questo lascia intendere che dietro all’opera ci sono dei workflow di una certa complessità e non dei semplici text2video o image2video.
IA che usa il tuo PC
Il 22 ottobre, Anthropic ha rilasciato una nuova versione di Claude 3.5 Sonnet insieme a una nuova API che consente al modello di percepire il monitor e interagire con le interfacce di un computer. Ha anche annunciato l’arrivo di Claude 3.5 Haiku.

Il nuovo Claude 3.5 Sonnet è migliorato su ogni Benchmark, raggiungendo delle performance eccezionali nel coding. Su SWE-bench Verified ha ottenuto un punteggio del 49%, superando tutti i modelli pubblicamente disponibili, incluso o1 di OpenAI.
Claude 3.5 Haiku arriverà invece entro novembre, ha prestazioni paragonabili a Claude 3 Opus, ma mantenendo lo stesso costo e velocità di Claude 3 Haiku.
Mentre la nuova API, ancora in fase beta, permette agli utenti di integrarla per consentire a Claude di tradurre prompt, come ad esempio: usa i dati dal mio computer e online per compilare questo modulo, in comandi per il computer, come: controlla un foglio di calcolo; sposta il cursore per aprire un browser web; naviga verso le pagine web pertinenti; compila un modulo con i dati da quelle pagine e così via. Questa nuova funzionalità segna l'inizio di un'era in cui l'IA può utilizzare autonomamente i computer.
Recitare senza faccia
Sempre il 22 ottobre, Runway ha annunciato l’arrivo di Act-One, un nuovo strumento all'avanguardia per la generazione di performance animate all'interno di Gen-3 Alpha. Questo nuovo tool è in grado di creare animazioni espressive utilizzando semplici video e performance vocali come input, segnando un importante passo avanti nell'uso di modelli generativi per contenuti live action e animati.

Tradizionalmente, creare animazioni facciali richiede processi complessi e attrezzature costose, come sistemi di motion capture e rigging manuale. Act-One, invece, elimina la necessità di tali attrezzature, permettendo di catturare l'essenza di una performance basandosi unicamente su un video di un attore. Il modello preserva fedelmente le espressioni facciali e traduce accuratamente le performance anche in personaggi con proporzioni diverse dal video originale, aprendo nuove possibilità per la progettazione e l'animazione di personaggi.
Act-One si distingue anche nella creazione di contenuti live action, offrendo output cinematografici di alta qualità, robusti e credibili, mantenendo la coerenza delle animazioni facciali attraverso vari angoli di ripresa. Questa funzionalità consente ai creatori di sviluppare personaggi realistici e emotivamente coinvolgenti, migliorando la connessione con il pubblico.
Il miglior modello open-source per i video
Per non farsi mancare nulla, il 22 ottobre è anche il giorno in cui Genmo ha presentato Mochi 1, un modello per i video open-source che ha battuto qualunque altro modello closed-source in termini di qualità generale.

Mochi 1 dimostra notevoli miglioramenti nella qualità dei movimenti e un'ottima aderenza ai prompt. Disponibile con licenza Apache 2.0, una prima anteprima di Mochi 1 è già disponibile gratuitamente per uso personale e commerciale.
Oltre al rilascio del modello, l’azienda ha creato un playground nel quale testarlo gratuitamente. I pesi e l'architettura di Mochi 1 sono disponibili su Hugging Face. Si tratta della versione base in 480p, con il modello HD che arriverà entro fine anno.
Mochi 1 si basa su una nova architettura Asymmetric Diffusion Transformer (AsymmDiT), ha 10 miliardi di parametri e una finestra di contesto da 44.520 token. Parliamo del più grande modello di generazione video mai rilasciato apertamente!
Ma attenzione che per funzionare richiede almeno 4 GPU H100.
Genmo ha anche raccolto 28,4 milioni di dollari in un recente round di finanziamento.
Midjourney fa sul serio
Il 23 ottobre, Midjourney ha rilasciato in versione beta uno dei più attesi e importanti aggiornamenti dell’anno: l’Image Editor, un'interfaccia con cui lavorare sulle proprie immagini esterne in maniera molto simile al generative fill di Photoshop.

Ora gli utenti possono quindi caricare un'immagine per espanderla, cambiarne lo stile o modificarne i singoli elementi. Questo è reso possibile anche dalla nuova funzionalità Image Retexturing, che è una loro versione rivisitata di ControlNet. Retexturing analizza la forma dell'immagine e ne modifica il contenuto, cambiando luci, materiali, superfici e stile in base a un prompt.
Insieme all'editor, hanno introdotto anche un nuovo sistema di moderazione AI, più intelligente e accurato, che analizza i prompt e le immagini per evitare usi impropri del modello, così da contrastare il fenomeno dei deepfake e tutti gli utilizzi scorretti o potenzialmente dannosi dell'IA generativa. Motivo per il quale Midjourney investe molto nella moderazione dei contenuti.
Attenzione però che l’editor non è attualmente disponibile per tutti. Per testarlo, bisogna soddisfare almeno uno dei seguenti requisiti: 1. Aver generato almeno 10.000 immagini. 2. Avere un abbonamento annuale. 3. Essere abbonati mensilmente da almeno 12 mesi. Attualmente, circa il 25% della community ha accesso al nuovo editor.
Voci personalizzate su richiesta
Sempre il 23 ottobre, ElevenLabs presenta Voice Design, un nuovo tool che permette la creazione di voci personalizzate partendo da una descrizione testuale.

Voice Design aiuta i creatori di contenuti a ottenere la voce esatta di cui hanno bisogno, quando ne hanno bisogno. Questa nuova feature è altamente sperimentale e i cloni vocali professionali sono ancora le voci migliori sulla piattaforma.
L'unico costo per l'utilizzo di Voice Design è il numero di crediti necessario a generare il proprio testo di anteprima, che viene addebitato solo una volta, anche se il modello genera tre campioni tra cui scegliere.
L’edicola dei paper scientifici

Tre paper di ricerca per il mese di ottobre.
MonST3R - Un nuovo approccio che può stimare forme 3D partendo da riprese video, creando una nuvola di punti dinamica e tracciando le posizioni della telecamera. Questo metodo stima la profondità dal video e separa gli oggetti in movimento da quelli fissi con maggior efficacia rispetto a tecniche precedenti.
CLoSD - I modelli di diffusione del movimento e il controllo basato sull'apprendimento per rinforzo (RL) per simulazioni fisiche hanno punti di forza complementari nella generazione del movimento umano. I primi sono in grado di generare un'ampia varietà di movimenti, aderendo a un controllo intuitivo come il testo, mentre i secondi offrono movimenti fisicamente plausibili e un'interazione diretta con l'ambiente. CLoSD è un controller RL basato sulla fisica e guidato da testo che utilizza la generazione tramite diffusione per varie attività, e può controllare i personaggi nelle simulazioni fisiche utilizzando prompt testuali. È in grado di navigare verso obiettivi, colpire oggetti e passare dalla posizione seduta a quella eretta, il tutto guidato da semplici istruzioni.
Inverse Painting - Un metodo basato sulla diffusione per generare video time-lapse del processo di pittura partendo da un dipinto target. Il modello impara da artisti reali allenandosi su molti video di pittura, producendo risultati realistici anche con stili artistici differenti.
Il mercatino dell’open-source

Tre progetti open-source con codice per il mese di ottobre.
Pyramid Flow - Un metodo Autoregressivo per la generazione di video basato su Flow Matching ed efficiente in termini di training. Addestrato solo su dataset open source, Pyramid Flow può generare video di alta qualità da 10 secondi in una risoluzione di 768p a 24 FPS, e supporta nativamente la generazione di video partendo da un’immagine.
Vikit - Un SDK open source sviluppato da Vikit.AI, che consente la creazione di generatori video personalizzati sfruttando diversi modelli di intelligenza artificiale per video, immagini, voce, musica e testo. Gestisce l'elaborazione di contenuti video e audio, oltre alla sincronizzazione dei modelli. Le operazioni vengono eseguite in parallelo, con adeguati processi di monitoraggio e recupero, per garantire una generazione video rapida e affidabile a partire dagli output dei vari modelli.
Hallo2 - Un modello AI che può creare lunghi video in 4K di avatar parlanti partendo da immagini di ritratti e file audio. Gli utenti possono regolare le espressioni facciali con etichette di testo, aumentando il controllo e riducendo drasticamente alcune problematiche legate a questo tipo di modello, come la perdita di coerenza nell’aspetto dei personaggi e gli artefatti temporali.
Tutto quello che avreste voluto sapere su Canvas ma non avete mai osato chiedere
Negli ultimi anni, l'intelligenza artificiale generativa è entrata sempre di più nelle nostre vite, aiutandoci a liberarci dai compiti ripetitivi e monotoni, aumentando la nostra produttività e permettendoci di concentrarci su attività veramente creative. Tra i vari strumenti disponibili, il nuovo Canvas di OpenAI si distingue per la sua capacità di semplificare la collaborazione tra esseri umani e IA, permettendo agli utenti di lavorare in modo più interattivo e dinamico.
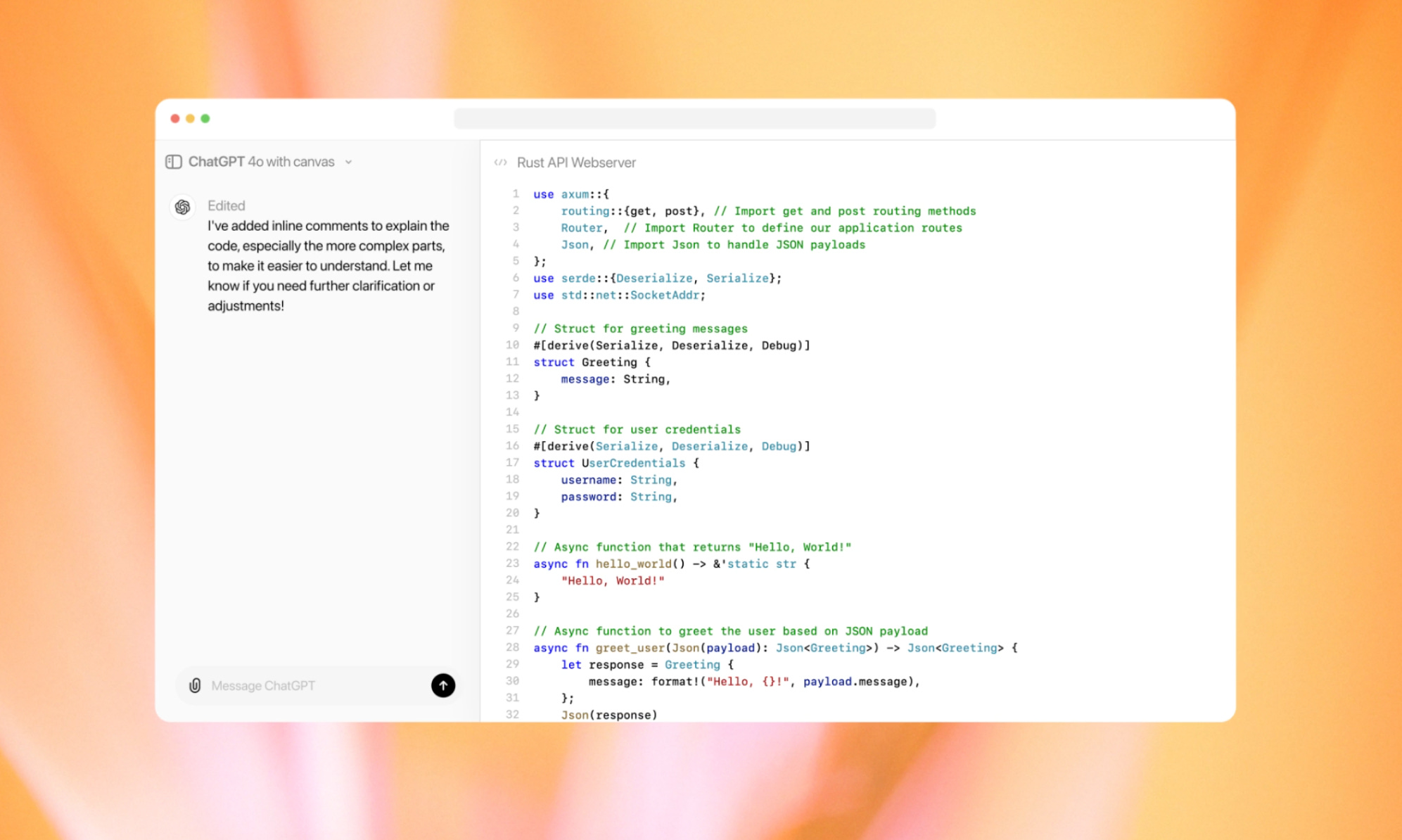
Canvas è una nuova interfaccia progettata per lavorare con GPT-4o su progetti di scrittura e programmazione. Questa modalità di lavoro può essere selezionata dall'apposito menù a tendina in alto. All'inizio ci troveremo nella classica chat a cui siamo abituati, ma quando inseriremo un prompt, il modello analizzerà la nostra richiesta per valutare se è necessario aprire un Canvas. In base alla mia esperienza, consiglio di richiederlo esplicitamente per avere la certezza che si apra, ad esempio: "Apri un canvas per lavorare a un articolo".
Attualmente, questa feature è disponibile agli utenti di ChatGPT Plus, Team, Enterprise ed Edu. Una volta superata la fase beta, Canvas arriverà anche per tutti gli utenti che non hanno sottoscritto l'abbonamento al servizio.
Miglioramenti nelle Performance di GPT-4o grazie a Canvas
L'introduzione di Canvas ha permesso di migliorare significativamente le performance di GPT-4o in vari aspetti. OpenAI ha valutato i progressi attraverso più di 20 valutazioni interne automatizzate, utilizzando tecniche innovative per la generazione di dati sintetici, come la distillazione degli output da o1-preview per addestrare il modello nei suoi comportamenti fondamentali. Questo approccio ha consentito di migliorare rapidamente la qualità della scrittura e le interazioni degli utenti senza doversi affidare ai dati generati dagli esseri umani.
Il comportamento del modello nell'editing è stato notevolmente perfezionato, consentendogli di decidere quando applicare modifiche mirate o riscrivere un intero paragrafo. GPT-4o con Canvas esegue gli editing con una performance superiore del 18% rispetto a GPT-4o con prompt standard, migliorando così la rilevanza, la qualità e la precisione dei suoi interventi.

Canvas migliora le prestazioni di GPT-4o rispetto alla versione normale con zero-shot prompt, ottenendo un incremento del 30% in accuratezza e del 16% in qualità. Questo dimostra come l'addestramento sintetico possa migliorare significativamente le risposte e il comportamento del modello rispetto alle semplici istruzioni.
Funzionalità chiave
La principale differenza tra Canvas e un'interazione tradizionale con Chatbot AI, è la possibilità di vedere e modificare il lavoro in tempo reale all'interno di un documento dinamico. Canvas è particolarmente utile per i progetti che richiedono editing e revisioni continue, poiché il modello ha una miglior comprensione del contesto e la collaborazione utente-IA viene facilitata dalla nuova UI. Questo rende Canvas uno strumento particolarmente utile per:
Scrittura Creativa: Dagli articoli di blog ai racconti, Canvas permette di sviluppare idee insieme all'IA, ottenendo suggerimenti di stile, struttura e approfondimenti tematici.
Programmazione: Gli sviluppatori possono scrivere, rivedere e correggere codice insieme all'IA, che è in grado di suggerire miglioramenti, aiutare a risolvere bug e fornire suggerimenti su come migliorare il codice stesso.
Brainstorming: Quando si è alla ricerca di nuove idee, Canvas può fungere da compagno di brainstorming, fornendo prospettive nuove, organizzando le idee in un unico ambiente e combinando concetti in modo inaspettato.
Canvas permette di intervenire su specifiche sezioni del testo e di evidenziarle per richiedere modifiche precise. In questo modo, l'IA può rispondere nel contesto in cui si sta lavorando, proprio come farebbe un editor o un revisore di codice, fornendo suggerimenti e feedback mirati che tengono conto del progetto nella sua interezza.
Abbiamo un pieno controllo sui nostri progetti: possiamo modificare direttamente il testo o il codice, oppure utilizzare un menu di scorciatoie per richiedere a GPT modifiche rapide, come accorciare il testo o correggere eventuali errori. Si può chiedere all'IA di riscrivere una parte specifica, migliorarne la chiarezza, o cambiare il tono senza dover ricominciare da capo.
Panoramica del funzionamento
Come anticipato, quando selezioniamo "ChatGPT 4o with canvas" dal menù a tendina, inizialmente vedremo la classica chat che conosciamo da anni. L'ambiente di scrittura avanzato si attiverà quando il modello riconosce la necessità di un canvas o quando lo richiediamo esplicitamente. Una volta attivato, l'interfaccia si adatta: la chat viene spostata sulla sinistra, al centro appare l'editor per lavorare liberamente, mentre in alto troviamo i tasti per navigare tra le versioni del testo, visualizzare la cronologia delle modifiche e copiare il contenuto. In basso a destra, il tasto suggerisci modifiche ci permette di ricevere dei commenti di fianco al testo, che possiamo accettare per consentire a GPT di apportare le modifiche suggerite. Passando sul tasto si apre anche un menù con altre funzionalità rapide.
Tra queste troviamo: regola lunghezza, per espandere o accorciare i testi; livello di lettura, che permette di selezionare la complessità lessicale in un range che va da "scuola materna" a "scuola di specializzazione"; aggiungi l'ultima rifinitura, per correggere errori di punteggiatura o battitura, simile a un proofreading; e aggiungi emoji, utile per i contenuti social.
Tutte queste opzioni possono essere applicate all'intero testo o a singole sezioni selezionando frasi o paragrafi. Nel momento in cui si evidenzia una porzione di testo, si può cliccare su "chiedi a ChatGPT" per inserire un prompt specifico nella casella di testo, che verrà mostrato nella chat a sinistra.
Sempre selezionando una porzione di testo, possiamo anche renderlo grassetto, corsivo o regolarne la dimensione per trasformarlo in un titolo o sottotitolo.
In modalità coding, Canvas funziona in modo praticamente identico, con la differenza che in basso a destra avremo altre funzionalità specifiche. Il tasto suggerisci modifiche diventa controlla il codice, ma fa sostanzialmente la stessa cosa. Passandoci sopra con il mouse, il menù include opzioni come: trasferisci in un altro linguaggio, per convertire il codice in altri linguaggi di programmazione; correggi bug, per risolvere eventuali errori; aggiungi log, per inserire dichiarazioni di logging e print in punti strategici e facilitare il debug; aggiungi commenti, per spiegare meglio il funzionamento del codice.
Come utilizzare Canvas al meglio
Il bello di Canvas è che non esiste un unico modo per utilizzarlo: tutto dipende dai nostri bisogni e dall'approccio che preferiamo adottare.
Ad esempio, potremmo scegliere di usarlo come semplice assistente alla scrittura, scrivendo gran parte del testo da soli e chiedendo suggerimenti, correzioni o parafrasi all'IA solo quando ne abbiamo bisogno. Questo approccio si adatta bene agli scrittori professionisti che desiderano mantenere il loro stile personale intatto e avere il pieno controllo sul processo di scrittura.
Ma possiamo anche adottare un approccio più automatizzato, chiedendo al modello di generare testi per noi e limitandoci a fornire indicazioni dettagliate, evidenziare frasi o paragrafi da migliorare, o intervenire manualmente su singole frasi. Questo approccio è particolarmente adatto per i post sui social, dove non è richiesto un linguaggio particolarmente elaborato.
Invece per chi, come me, si occupa di articoli di approfondimento, è possibile partire da un Canvas vuoto e aggiungere progressivamente le informazioni da elaborare tramite la chat a sinistra, sotto forma di contesto nel prompt o come documenti allegati. Andando poi a rifinire l'intero articolo manualmente o in collaborazione con GPT. Personalmente, da quando utilizzo Canvas per scrivere questo magazine, ho notato che riesco a completare il lavoro in circa la metà del tempo senza compromettere la qualità dei contenuti.
Canvas è uno degli aggiornamenti più interessanti e inaspettati proposti quest'anno da OpenAI, e rappresenta un vero punto di svolta nel modo in cui collaboriamo con l'intelligenza artificiale. La sua capacità di adattarsi alle nostre esigenze, sia per progetti di scrittura creativa che per lo sviluppo di codice, ci permette di velocizzare il lavoro senza sacrificare il nostro tocco personale o compromettere la qualità. Che si tratti di marketing, scrittura creativa, didattica o programmazione, Canvas rende il processo di creazione più intuitivo e dinamico, permettendoci di esplorare soluzioni e idee che da soli avremmo probabilmente impiegato molto più tempo a considerare.
Nel futuro prossimo, l'evoluzione di Canvas potrebbe portare a una collaborazione ancora più stretta tra esseri umani e macchine, dove l'IA non solo risponde alle nostre richieste, ma anticipa le necessità, offrendo supporto proattivo e suggerimenti sempre più personalizzati. In ambito programmazione, molti utenti vorrebbero avere la possibilità di eseguire e visualizzare le anteprime del codice direttamente all'interno di Canvas, consentendogli di svolgere la maggior parte del lavoro nello stesso ambiente. Questa funzionalità potrebbe sicuramente essere implementata in futuro, soprattutto considerando che soluzioni simili sono già presenti in Claude di Anthropic. Questo tipo di sinergia ha il potenziale di ridefinire il concetto stesso di creatività, trasformando il modo in cui lavoriamo e affrontiamo problemi complessi. Se siete curiosi di sperimentare Canvas, consiglio di iniziare con un piccolo progetto e lasciarsi sorprendere dalle possibilità dello strumento.
Dobbiamo parlare di musica fatta con l’IA
In molti non l’hanno ancora realizzato, ma tutte le piattaforme online che possono contenere musica, come YouTube, Spotify, Amazon Music e Soundcloud, si stanno rapidamente popolando di nuovi brani realizzati interamente con l’ausilio di modelli avanzati di Intelligenza Artificiale.
Uno dei motivi per cui molte persone non se ne sono accorte, è che la musica “AI-generated” sta raggiungendo dei livelli qualitativi e artistici incredibili, al punto da renderla indistinguibile dalla musica creata dagli umani.

Ad esempio, canali YouTube come Nanashi Zero e Beats by AI pubblicano solo musica generata con IA e stanno facendo degli ottimi numeri. Su Spotify c’è anche la playlist Beats By AI Radio che contiene solo brani di questo tipo.
Alcuni degli aspetti più interessanti della musica generata dall'AI, sono la sua disponibilità potenzialmente infinita e la grande varietà di generi, stili, sonorità e voci che possono emergere. Dall'altro lato della medaglia, uno dei limiti principali della musica generata dall'AI, o almeno quello di cui si lamentano molti utenti, è la sua difficoltà nel creare un vero legame emotivo con l'ascoltatore.
La musica è infatti una delle forme d'arte più viscerali concepite dall'homo sapiens, che si sviluppata nel corso di decine di migliaia di anni ed è radicata profondamente nella nostra condizione umana e nella consapevolezza della mortalità, un'esperienza che le macchine non possono comprendere appieno.
Sebbene la musica generativa possa risultare molto interessante, divertente e a volte anche emozionante, manca spesso di quella profonda sensibilità che caratterizza la musica creata dai grandi artisti umani.
Nonostante l'IA stia migliorando rapidamente, e in futuro diventerà sempre più abile nel comprendere e replicare le emozioni umane, l'applicazione attualmente più efficace dei modelli per la musica sembra collocarsi nel vasto mondo della musica elettronica. Questo genere si presta particolarmente bene alle capacità dell'IA, poiché non richiede testi elaborati o connessioni emotive di un certo tipo, che risultano ancora molto difficili da sintetizzare attraverso dei pattern. In tal senso, ritengo che potrebbe essere molto interessante ascoltare un DJ-set in cui un artista umano mixa esclusivamente tracce di musica elettronica generate dall'IA.
I modelli generativi per la musica non vanno considerati come degli strani giocattoli che creano brani in autonomia, perché sono in verità dei veri e propri strumenti per il potenziamento della creatività umana. Spesso c'è un divario tra l'idea perfetta nella mente di un creativo e ciò che riesce a realizzare con i mezzi e le capacità a sua disposizione, che spesso dipendono anche dalle risorse economiche. L'IA contribuisce a colmare significativamente questo divario, abbattendo le barriere tecniche che limitano l'espressione delle proprie idee ed emozioni.
Così come la tecnologia ha storicamente ampliato la capacità di creare arte in tutte le sue forme - basti pensare che fino a pochi secoli fa, geni musicali come Mozart o Beethoven potevano comporre sinfonie grazie al privilegio di una formazione adeguata, mentre oggi anche chi non ha potuto avere un'educazione musicale può creare un successo grazie a software e sintetizzatori - l'AI generativa diventerà certamente il prossimo grande strumento per aprire nuove possibilità ai creativi di tutto il mondo e di tutti i ceti sociali.
D'altronde, chi non ha mai avuto un motivetto inedito in testa, ma lo ha perso per sempre a causa dell'incapacità di trasformarlo in una composizione concreta?
Che piaccia o meno, l'Intelligenza Artificiale è quello strumento che colma il divario tra chi ha le idee ma non i mezzi o le capacità per realizzarle. Non a caso, uno degli usi più interessanti di questi modelli è quello di fornirgli i propri testi per dargli una voce intonata e produrli.
Uno degli utilizzi più controversi dell'AI nella musica è il voice cloning, ovvero la possibilità di replicare il timbro vocale di qualcuno partendo da pochi minuti di registrazione, per poi riutilizzare quella voce in altri progetti. Un'artista che ha abbracciato questa tecnologia è Grimes, che ha lanciato uno strumento chiamato Elf Tech, con il quale chiunque può trasformare la propria voce nella sua.
Questo l'ha portata a creare due profili su Spotify: uno come artista umano e un altro, GrimesAI, per la musica generata utilizzando la sua voce. Questa situazione solleva questioni etiche complesse: come possono gli artisti mantenere il controllo sull'uso della propria voce in un mondo in cui chiunque può clonarla facilmente?
La differenza tra ispirazione e copia diretta diventa molto sfumata. Se un modello viene addestrato sulla musica di un determinato artista e crea qualcosa di molto simile, quell'artista dovrebbe essere compensato? Attualmente, startup di IA per la musica come Suno e Udio stanno affrontando cause legali da parte delle grandi etichette discografiche, accusate di aver utilizzato la loro musica nei dataset di addestramento dei modelli senza compensare adeguatamente gli artisti.
Un'altra preoccupazione, è che l'IA possa evolversi fino al punto in cui non è più strumento creativo, ma un vero e proprio artista autonomo. Immaginate un'IA capace di generare milioni di brani, testarli sul pubblico e affinarli fino a creare un successo planetario. In uno scenario simile, chi deterrebbe la proprietà della musica: l'IA stessa o l'azienda che l'ha creata e addestrata? E agli ascoltatori importerebbe davvero se i loro brani preferiti fossero creati da una macchina, fintanto che continuano a emozionarli?
Musica AI e Diritto d’autore
Questo argomento porta con sé molti spunti di riflessione riguato al copyright, ed è quindi opportuno inquadrare la materia anche da un punto di vista giuridico. Il primo concetto da chiarire, è che il diritto d’autore tutela l’espressione artistica e non l’idea, il mezzo espressivo, non il contenuto. Ciò significa che la medesima idea potrebbe essere espressa in più opere simili e non per questo violare il copyright.
Il diritto d'autore tutela i frutti del lavoro creativo, giustificato dalla necessità di proteggere la personalità dell'autore per come si manifesta nelle sue opere. Dal punto di vista della teoria economica, costituisce invece un incentivo alla produzione di opere di ingegno, che per definizione sono beni pubblici, in quanto non escludibili ai terzi e che pertanto, se non protette, verrebbero prodotte in quantità sub-ottimale.
Per opera di ingegno si intende un particolare tipo di bene immateriale, risultato di un processo di natura intellettuale. In questo processo deve sussistere l’elemento della creatività, senza il quale l’opera è priva di tutela. Il carattere creativo dell’opera viene valutato sia dal punto di vista qualitativo che quantitativo, e fa rispettivamente riferimento al numero e al grado di libertà delle scelte prese dall’artista.
In Italia, il diritto d’autore è disciplinato dalla legge n. 633 del 22 aprile 1941. La legge distingue i diritti spettanti all’autore in due categorie: i diritti di utilizzazione economica e i diritti morali. Se i primi, come ad esempio il diritto di riproduzione, sono suscettibili di una valutazione economica, i secondi sono invece irrinunciabili, inalienabili e imprescrittibili.
Quando si produce musica attraverso un modello IA come quelli di Soundraw, Aiva, Suno o Udio, l’accettazione dei termini e delle condizioni equivale alla stipula di un contratto. Le clausole del contratto regolano il rapporto giuridico tra la piattaforma e l’utente, anche per quanto concerne il trasferimento di alcuni diritti di utilizzazione economica.
I termini contrattuali di Soundraw stabiliscono, ad esempio, che la piattaforma si riserva il diritto di riprodurre, distribuire e altrimenti sfruttare la composizione dell’utente e acquista il 50% di tutti i diritti e gli interessi ovunque e in modo perpetuo. Aiva, invece, prevede una licenza per condividere e monetizzare l’opera su un set limitato di siti Web di terze parti: Youtube, Twitch, TikTok e Instagram. Le clausole di altri servizi come Suno o Udio prevedono condizioni simili: riservandosi parte o tutti i diritti di utilizzazione economica attraverso specifici termini contrattuali.

Le piattaforme aggirano la problematica questione dell’attribuzione della titolarità dei diritti d’autore nel caso dell’impiego di AI nella realizzazione dell’opera. Da un lato, vi è chi sostiene che i diritti d’autore spettino solo all’artista-utente che si avvale di uno strumento molto complesso, ma pur sempre non più di un mezzo creativo, infondo non diverso da una macchina fotografica per il fotografo. Altri invece ritengono che l’output delle AI contenga degli elementi di creatività ulteriori rispetto a quelli rinvenibili nel prompt scritto dall’utente e che, di conseguenza, i diritti d’autore siano condivisi con la piattaforma che mette a disposizione l’intelligenza artificiale.
In giurisprudenza, tuttavia, è ad oggi maggioritaria la posizione di coloro che tendono a non riconoscere, salvo casi eccezionali, la paternità dell’opera in capo all’autore-utente e il conseguente riconoscimento dei diritti d’autore, in quanto l’impiego dell’intelligenza artificiale nella realizzazione dell’opera implicherebbe il venir meno del requisito della creatività.
Si potrebbe pensare che, a fronte di una condivisione dei diritti di utilizzazione economica in caso di successo commerciale dell’opera, gli stessi contratti prevedano anche una compartecipazione della responsabilità nel caso in cui in cui l’output dell’AI violi il copyright di altre opere. I programmi di creazione musicale dovrebbero precludere la possibilità di plagio, ma ciò non è sempre vero e in questi casi le condizioni contrattuali dei vari servizi prevedono sempre l’attribuzione della responsabilità in capo all’utente.
Ci si domanda se, a questo punto, ciò valga anche nel caso in cui l’autore non sia consapevole della violazione. La questione è delicata perché scusare l’utente in caso di violazione di diritti dei terzi, in ragione dell’assenza di un pieno controllo sul processo decisionale, ha spesso comportato il mancato riconoscimento della paternità dell'opera.
Ci soffermiamo, infine, sul profilo più spinoso della questione, ovvero il potenziale contrasto tra alcune condizioni contrattuali e la disciplina dei diritti morali d’autore, di cui all’articolo 20 della legge sul diritto d’autore e all’articolo 6 della Convenzione di Berna inserita negli accordi TRIPs. Le condizioni contrattuali di Soundraw, ad esempio, stabiliscono che nella misura massima consentita dalla legge applicabile, rinunci irrevocabilmente a tutti i cosiddetti "diritti morali".
Come detto in precedenza, i diritti morali sono inalienabili e intrasmissibili, dunque, non possono essere trasferiti, nemmeno se questa è la volontà dell’utente. È un diritto morale, ad esempio, il diritto di inedito, ovvero il diritto di decidere se e quando rendere di dominio pubblico l’opera. Questa prerogativa può potenzialmente trovarsi in conflitto con il diritto che si riservano le piattaforme di trasferire o utilizzare l’opera anche al fine di addestrare l'AI e consentire lo sviluppo tecnologico.
Ciò che è fondamentale sottolineare è che, se a monte non viene riconosciuta la paternità dell’opera creata con l’ausilio dell’AI, l’autore non può far valere nessun diritto morale nei confronti delle piattaforme. Proprio per questa ragione, il punto di diritto centrale che sarà dibattuto nei prossimi anni verterà proprio sulla sussistenza o meno del requisito della creatività nei processi che coinvolgono l’intelligenza artificiale nella realizzazione dell’opera. Se la risposta dovesse essere affermativa, allora si aprirebbe il vaso di pandora dei possibili conflitti tra i diritti dell’autore e quelli delle piattaforme che forniscono questi servizi.
Nonostante le sfide etiche e legali, l'AI ha il potenziale per democratizzare la creazione musicale, rendendola accessibile a un pubblico sempre più ampio. La vera questione non è più se l'AI cambierà il mondo della musica, ma come riusciremo a gestire e adattarci a questa trasformazione radicale.
Questo articolo è stato scritto in collaborazione con Lorenzo Gasparini
dell’associazione ForeseeAI
E Luce Fu
In California esiste una startup che opera nell'ambito della space economy e che ha come obiettivo la fornitura di luce solare dopo il tramonto. Immaginate di poter squarciare il cuore della notte con un enorme fascio di luce solare che arriva dal cielo, rischiarando a giorno un'area specifica, mentre tutto il resto rimane avvolto dal buio.
Questa è la visione di Reflect Orbital, una startup che sta rivoluzionando il settore dei pannelli solari grazie a una costellazione di satelliti riflettenti. La loro idea è tanto semplice quanto innovativa: un sistema di specchi orbitanti che riflette la luce solare verso i parchi fotovoltaici, permettendo di produrre energia anche dopo il tramonto. I primi prototipi di questi satelliti riflettente dovrebbero andare in orbita già nel 2025.

Ben Nowack, fondatore e CEO di Reflect Orbital, ha recentemente presentato i piani della sua azienda durante la Conferenza Internazionale sull'Energia dallo Spazio. La costellazione prevede 57 piccoli satelliti in orbita polare sincronizzata con il sole, a un'altitudine di 600 chilometri. Questi satelliti voleranno da polo a polo, mentre la Terra ruota sotto di loro, garantendo due passaggi su ciascuna zona del pianeta ogni 24 ore. Complessivamente, questa costellazione sarà in grado di fornire circa 30 minuti aggiuntivi di luce solare ai pannelli, proprio durante i momenti di maggiore domanda di energia, afferma Nowack.
"Il problema dell'energia solare è che non è disponibile quando la vogliamo per davvero" ha dichiarato Nowack alla conferenza. "Più parchi solari costruiamo, meno persone ne hanno effettivamente bisogno durante il giorno. Sarebbe davvero fantastico se potessimo ottenere un po' di energia solare prima che il sole sorga e dopo il tramonto, perché allora potremmo effettivamente far pagare prezzi più alti e guadagnare molto di più. E pensiamo che le tecnologie basate sui riflettori possano risolvere questo problema."
Negli ultimi quindici anni, il costo dei pannelli solari è diminuito del 90%, secondo l'Agenzia Internazionale per le Energie Rinnovabili, e la loro efficienza continua a migliorare grazie ai progressi nella tecnologia fotovoltaica. La produzione di energia solare rimane però intermittente per sua stessa natura, e questo problema rappresenta ancora una sfida significativa.
Nei giorni nuvolosi, le centrali solari producono meno energia rispetto alle giornate limpide e, durante la notte, la produzione si ferma completamente. Sistemi di batterie e altre fonti rinnovabili possono colmare parzialmente questa mancanza, ma finora è stato necessario l'uso di centrali a gas o carbone come backup o base load. "È molto facile sostituire il primo 1% della rete energetica con fonti rinnovabili," ha detto Nowack. "Ma è molto difficile sostituire l'ultimo 1%. Quella è l'energia che serve in un giorno di pioggia senza vento."
I satelliti di Reflect Orbital peseranno solo 16 chilogrammi ciascuno e saranno equipaggiati con specchi di 9,9 metri per lato, progettati per concentrarsi in un raggio luminoso stretto orientabile in base alla domanda degli operatori dei parchi fotovoltaici. "Vogliamo rendere il tutto il più semplice possibile: accedi a un sito web, inserisci le tue coordinate GPS e ti invieremo luce solare dopo il tramonto", ha spiegato Nowack.
Ha sottolineato anche che i satelliti sono stati progettati per evitare l'inquinamento luminoso. "Se ti trovi a circa 10 chilometri dal bordo di un parco solare, guardando direttamente verso il cielo non vedrai alcuna luce. Potresti vedere al massimo un bagliore, come se ci fossero lavori in corso".
Nel 2023, Reflect Orbital ha testato uno dei suoi specchi su un pallone aerostatico a un'altezza di 3 chilometri sopra un parco solare, riuscendo a generare 500 watt di energia per metro quadro di pannelli fv, ovvero circa "la metà della luminosità del sole", secondo Nowack. La società ha già ottenuto i finanziamenti necessari a lanciare il primo satellite di test per il 2025.
Nonostante l'interesse crescente per queste tecnologie, gli specchi orbitali hanno anche i loro detrattori. Andrew Williams dell'Osservatorio Europeo Australe ha avvertito che, se non progettati con attenzione, questi riflettori potrebbero essere più luminosi delle stelle più brillanti, aggravando il problema dell'inquinamento luminoso satellitare che già preoccupa gli astronomi. Dopo il lancio dei primi satelliti Starlink di SpaceX nel 2019, gli astronomi si sono accorti che questi veicoli potevano interferire con le osservazioni astronomiche, lasciando scie nelle immagini. SpaceX, ha detto Williams, è poi riuscita a risolvere parzialmente il problema modificando la superficie dei satelliti per ridurre la quantità di luce riflessa.
Un concetto chiave per capire l'impatto di Reflect Orbital è il cosiddetto Capacity factor, che misura la quantità effettiva di energia prodotta da un impianto di alimentazione rispetto alla quantità massima teorica che potrebbe essere prodotta se funzionasse a pieno regime per tutto il tempo. Per i pannelli solari, il capacity factor è fortemente limitato dal meteo e dall'alternanza del giorno con la notte. In media, il capacity factor del fotovoltaico è si aggira tra il 20-25% in base all'area geografica in cui vengono installati, il che significa che i pannelli producono energia per circa un quarto del loro potenziale massimo su base annua.
La tecnologia di Reflect Orbital vuole aumentare questo valore, fornendo luce solare durante periodi in cui non sarebbe normalmente disponibile, come subito dopo il tramonto o poco prima dell'alba. Aumentare il capacity factor significa rendere i parchi solari più produttivi e affidabili, contribuendo a renderli più conveniente e a ridurre la dipendenza da altre fonti di energia.
Mentre il mondo continua a cercare nuovi metodi per affrontare la crisi climatica e ridurre la nostra dipendenza dai combustibili fossili, soluzioni come quella di Reflect Orbital potrebbero giocare un ruolo cruciale nel futuro del settore energetico.
Energia Blu per l’IA
Negli ultimi mesi, alcune tra le aziende tecnologiche più influenti al mondo stanno abbracciando una nuova visione per l'energia nucleare, vedendola come una strada indispensabile per raggiungere i propri obiettivi climatici e contribuire alla decarbonizzazione globale. Una tecnologia ancora temuta da molti, spesso a causa della scarsa conoscenza del tema, sta oggi acquisendo un ruolo cruciale e strategico per garantire una transizione energetica efficace.
Amazon, Google e Microsoft stanno compiendo passi significativi verso l'adozione dell'energia atomica, aprendo la strada verso un possibile rinascimento per questa tecnologia, che negli ultimi decenni ha compiuto enormi progressi in termini di sicurezza e design dei reattori.

Microsoft e il ritorno di Three Mile Island
Microsoft ha recentemente siglato un accordo storico con Constellation Energy per l'acquisto di energia nucleare per i prossimi 20 anni. L'accordo riguarda la riapertura dell'Unità 1 della centrale di Three Mile Island, in Pennsylvania, che si prevede riaprirà tra il 2027 e il 2028 dopo una lunga serie di lavori. Questa centrale è tristemente nota per uno dei pochi incidenti avvenuti nella breve storia dell'energia nucleare: nel 1979 si verificò un parziale meltdown dell'Unità 2, che non causò vittime o danni significativi alla struttura. È quindi importante sottolineare che l'Unità 1 è completamente indipendente e separata da quella coinvolta nell'incidente del 1979.
L'accordo con Microsoft, che dovrà essere approvato dai regolatori, rappresenta un passo significativo verso l'utilizzo di energia a zero emissioni per sostenere la crescita dei centri dati dedicati all'intelligenza artificiale. Con un investimento previsto di 1,6 miliardi di dollari per l'ammodernamento dell'impianto, Constellation prevede di farlo operare fino al 2054. Si stima che la riapertura di questa unità potrebbe creare fino a 3.400 posti di lavoro diretti e indiretti, generando miliardi di dollari in tasse e altre attività economiche.
Joe Dominguez, amministratore delegato di Constellation, ha definito l'accordo come un "simbolo potente della rinascita dell'energia nucleare come risorsa energetica pulita e affidabile". Ha evidenziato che, prima della chiusura prematura dovuta a ragioni economiche, questa centrale era tra le più sicure e affidabili della rete elettrica. Microsoft ha descritto l'accordo come una "pietra miliare" nei suoi sforzi per contribuire alla decarbonizzazione della rete elettrica.
Ad oggi, l'energia nucleare è tra le poche fonti in grado di fornire costantemente enormi quantità di energia a emissioni zero. La mossa di Microsoft rappresenta un importante esempio di come le grandi aziende tecnologiche possano guidare gli investimenti privati verso una produzione energetica più sostenibile e affidabile.
Amazon e i nuovi reattori modulari
Amazon ha recentemente annunciato una serie di nuovi accordi per supportare lo sviluppo di progetti energetici nucleari, con l'obiettivo di favorire la costruzione di nuovi reattori modulari di piccole dimensioni (SMR - Small Modular Reactors). L'azienda ha già raggiunto l'obiettivo di abbinare il 100% dell'elettricità consumata dalle sue operazioni globali con energie rinnovabili, sette anni prima del suo obiettivo fissato per il 2030. Nonostante questo, la crescente domanda energetica ha spinto colosso degli acquisti online verso la decisione di integrare il nucleare come fonte di energia complementare.
Matt Garman, CEO di Amazon Web Services (AWS), ha dichiarato: "Il nucleare è una fonte sicura di energia senza emissioni di carbonio, che può contribuire ad alimentare le nostre operazioni e soddisfare la crescente domanda dei nostri clienti, aiutandoci a raggiungere il nostro impegno nel Climate Pledge di essere a emissioni nette zero entro il 2040". Gli SMR sono una tecnologia promettente: hanno un ingombro fisico ridotto, possono essere assemblati vicino alla rete elettrica, hanno tempi di costruzione più rapidi rispetto ai reattori tradizionali, e richiedono una manutenzione più contenuta, consentendo così una rapida messa in servizio e un abbattimento dei costi.
In collaborazione con Energy Northwest, un consorzio di utilities pubbliche dello Stato di Washington, Amazon ha firmato un accordo per lo sviluppo di quattro SMR avanzati. Questi reattori saranno costruiti, posseduti e gestiti da Energy Northwest e si prevede che la prima fase del progetto genererà circa 320 megawatt di capacità, con la possibilità di arrivare fino a 960 MW complessivi, abbastanza per alimentare più di 770.000 abitazioni degli Stati Uniti. Amazon ha fatto anche un grosso investimento in X-energy, uno dei principali sviluppatori di SMR e dei relativi combustibili. X-energy fornirà il design dei reattori utilizzati nel progetto di Energy Northwest e l'investimento includerà la capacità di produzione necessaria a sviluppare l'equipaggiamento degli SMR, supportando oltre cinque gigawatt di nuovi progetti per l'energia nucleare.
Amazon ha anche siglato un accordo con Dominion Energy in Virginia, per esplorare lo sviluppo di un progetto SMR vicino alla centrale nucleare di North Anna. Questo progetto porterà almeno 300 nuovi megawatt di energia nella regione, in cui si prevede che la domanda energetica aumenti dell'85% nei prossimi 15 anni.
Amazon non si limita a sviluppare nuovi impianti nucleari, ma si impegna anche nella conservazione degli impianti esistenti. Ha infatti siglato un accordo con Talen Energy per la co-locazione di un data center accanto a una loro centrale in Pennsylvania, che lo alimenterà direttamente e contribuirà a preservare questa importante risorsa energetica.
Si stima che l'accordo con Energy Northwest dovrebbe portare fino a 1.000 posti di lavoro temporanei nella costruzione e oltre 100 posti di lavoro permanenti una volta che il progetto SMR sarà operativo. Mentre l'investimento in Pennsylvania creerà nuovo lavoro e apporterà miglioramenti alle infrastrutture elettriche locali.
Google e il futuro dell'energia nucleare
Google ha recentemente firmato un accordo con Kairos Power per utilizzare i suoi SMR per generare l'enorme quantità di energia necessaria a supportare i data center per l'IA. L'accordo prevede che il primo reattore entri in funzione già in questo decennio, con l'obiettivo di averne altri operativi entro il 2035.
Secondo Michael Terrell, senior director per l'energia e il clima di Google, "La rete ha bisogno di nuove fonti di elettricità per supportare le tecnologie AI. Questo accordo aiuta ad accelerare una nuova tecnologia per soddisfare le esigenze energetiche in modo pulito e affidabile, sbloccando il pieno potenziale dell'AI per tutti". L'energia nucleare si sta dimostrando una soluzione sempre più attraente per l'industria tecnologica, che cerca di ridurre le emissioni di CO2 nonontante necessiti di sempre più energia.
Kairos Power, una startup californiana specializzata nello sviluppo di reattori più piccoli che utilizzano sali fusi come refrigerante al posto dell'acqua per ottenere un maggiore rendimento termodinamico, ha recentemente ottenuto il primo permesso in 50 anni dalla Commissione per la Regolamentazione Nucleare degli Stati Uniti per costruire un nuovo tipo di reattore nucleare. La costruzione di un reattore dimostrativo è già iniziata in Tennessee nel luglio 2023, e Google si è impegnata a supportare questa tecnologia avanzata per accelerarne la commercializzazione e dimostrare la fattibilità tecnica e di mercato.
Jeff Olson, dirigente di Kairos, ha dichiarato che l'accordo con Google è importante per accelerare la commercializzazione dell'energia nucleare avanzata e dimostrare la viabilità tecnica e di mercato di soluzioni che sono essenziali per decarbonizzare le reti elettriche. Sebbene i dettagli finanziari dell'accordo non siano stati resi noti, si tratta di una collaborazione fondamentale per sviluppare nuovi impianti nucleari che possano supportare la crescente domanda di energia dei data center di Google e delle città sempre più elettrificate.
Secondo le previsioni della banca d'affari Goldman Sachs, il consumo energetico globale dei data center raddoppierà entro la fine del decennio.
L'approccio di Google e altri giganti tecnologici, unito agli sforzi della comunità internazionale per aumentare la capacità nucleare globale di almeno tre volte entro il 2050, evidenzia il crescente ruolo di questa tecnologia nella lotta contro il cambiamento climatico.
Conclusioni
Con questi giganti tecnologici a fare da apripista, è probabile che altre aziende di rilievo globale seguiranno presto l'esempio, aprendo la strada verso un futuro più prospero, in cui l'energia abbonda ed è a buon mercato. È solo una questione di tempo prima che anche Meta, Tesla, Apple e altri colossi tecnologici abbraccino l'energia blu, così chiamata per l'effetto Čerenkov.
Gli accordi degli ultimi mesi non sono solo una strategia per ridurre le proprie emissioni, ma anche un modo per contribuire a un cambiamento strutturale a livello di società. Promuovendo l'accettazione del nucleare come risorsa sostenibile, queste aziende possono contribuire a sfatare i miti e le paure che circondano questa tecnologia, penalizzata da decenni di battaglie ideologiche portate avanti da gruppi d'interesse contrari al progresso.
Questa rinnovata attenzione potrebbe quindi segnare l'inizio di un nuovo capitolo nella transizione energetica globale, in cui l'innovazione tecnologica porta a un vero e proprio rinascimento nucleare su scala globale.
Rubare un po’ di verità agli altri
L’intervistata del quinto numero di Tales from the Latent Space è Melissa Debernardi, un'artista multi-sfaccettata che sta esplorando l'uso dell'intelligenza artificiale come strumento creativo. Melissa ci ha raccontato del suo percorso artistico, del progetto What If, e di come l'AI abbia trasformato la sua vita e la sua creatività. Le sue esperienze sono un esempio perfetto di come la tecnologia possa diventare parte integrante del processo artistico, offrendo nuove possibilità espressive e abbattendo barriere che sembravano insormontabili.
Questa intervista si colloca nella più ampia visione del magazine di offrire uno spazio unico ai creativi di tutto il mondo che utilizzano la tecnologia come ampliamento delle loro possibilità espressive. A partire dall'anno prossimo, questa rubrica includerà anche interviste a ingegneri, programmatori e matematici, per diversificare i contenuti e promuovere l'idea che la creatività non appartiene solo ad artisti e designer, ma che si tratta di un raffinato processo di problem solving intrinseco alla natura dell’essere umano e alle sue capacità cognitive.

Ci descriveresti il tuo rapporto con la tecnologia?
Il mio rapporto con la tecnologia è bello, anche se insolito. Sono arrivata tardi, rispetto ad altri. Non ho mai avuto videogiochi da piccola, ma sono sempre stata affascinata da questo mondo. La vera svolta è arrivata quando mi sono avvicinata alla fotografia: lì ho capito quanto fosse essenziale conoscere i software e rimanere costantemente aggiornata. Da quel momento, la tecnologia è diventata parte integrante della mia quotidianità. E oggi, con l'AI, posso dire che il nostro rapporto è diventato un vero e proprio matrimonio.
Il tuo percorso inizia come fotografa, ma nel tempo hai fatto esperienze anche nel mondo video e so che ti piace molto la scrittura. Cosa accomuna queste tre discipline artistiche nella tua visione?
Per me, ciò che accomuna fotografia, video e scrittura è il raccontare storie, la regia. Ogni immagine, parola o inquadratura ha il potere di dirigere un racconto, di portare lo spettatore in un viaggio. Ho avuto il piacere di scrivere e dirigere due cortometraggi, e l'anno scorso mi sono diplomata alla Scuola Holden di Alessandro Baricco. È stata un'esperienza che ha cambiato profondamente il mio modo di raccontare e, più in generale, di vedere la vita. La scuola mi ha dato strumenti preziosi per esplorare diverse forme narrative, facendomi crescere come artista e come persona.
Poi arriva l'IA, e qualcosa è cambiato... Sapresti spiegarci cosa e come?
È una domanda complessa, ma ci provo. Ho sempre avuto una nuova idea ogni giorno, e per anni ho conservato quaderni pieni di appunti, con idee per creare immagini. Tuttavia, creare set fisici è costoso e, dopo il Covid, la mia vita è cambiata: sono diventata agorafobica, non uscivo letteralmente più di casa. Nonostante tutto, il desiderio di creare era ancora forte.
Un giorno, per curiosità, ho letto un articolo su Midjourney e ho deciso di provarlo, anche se all'inizio non capivo molto. Premendo tasti a caso e sperimentando, ho faticato a orientarmi. Ma pian piano, grazie a molti tutorial e tanta pratica, ho iniziato a capire come funzionava. Ho realizzato che mi stavo affacciando a un nuovo mondo, con nuove regole e una libertà creativa assoluta. L'IA mi ha permesso di esprimermi in modi che non avrei mai immaginato.
Posso dire che, in qualche modo, è stata anche una terapia. Ha riacceso la mia voglia di creare, offrendomi uno spazio in cui potevo farlo senza uscire di casa, superando le limitazioni che mi tenevano bloccata.
Parliamo del progetto What If: Il titolo suggerisce un mondo in cui tutto è possibile, ti andrebbe di raccontarcelo?
What If è nato nel momento in cui ho capito che, con l'AI, davvero tutto era possibile. Ho finalmente trovato quello spazio creativo che avevo sempre sognato. Penso a qualcosa e lo creo. Se immagino poltrone gonfiabili nel cielo, posso farle esistere. Lo stesso vale per le mie poesie: ho aperto il mio quaderno di poesie e mi sono detta che avrei voluto illustrarle tutte. E così ho fatto.
Il percorso creativo è diventato un flusso, qualcosa che seguo naturalmente. Mi lascio guidare dall'istinto, dalla noia, dalla rabbia e da tutto quello che provo in quel momento. What If è il risultato di questa esplorazione senza limiti, un mondo dove posso dare forma a tutto ciò che immagino.
Che cos'è AI Muses e quale obiettivo ha come progetto?
AI Muses è un progetto nato per promuovere e supportare l'arte femminile attraverso l'uso dell'intelligenza artificiale. È una piattaforma che riunisce artiste da tutto il mondo, ognuna con il proprio stile e la propria visione, ma unite dall'obiettivo comune di esplorare nuove forme di espressione artistica.
L'idea alla base è di creare un network creativo, dove le donne possano sperimentare e condividere idee, utilizzando l'AI come mezzo per amplificare la loro voce artistica. L'obiettivo di AI Muses è quello di abbattere le barriere tradizionali dell'arte e aprire nuovi spazi per la creatività femminile, permettendo alle artiste di esprimersi liberamente e di creare opere uniche, innovative e potenti.
Come pensi che l'avvento dell'IA influenzerà l'educazione artistica delle generazioni che verranno?
Credo che l’intelligenza artificiale rivoluzionerà l’educazione artistica, rendendola più accessibile e inclusiva, e aprendo nuove strade per la creatività. Le future generazioni avranno a disposizione strumenti che permetteranno loro di esplorare linguaggi visivi e tecniche espressive con una facilità mai vista prima. L’AI sarà come un’estensione dell’immaginazione, in grado di concretizzare le idee in tempo reale, rendendo il processo di apprendimento più dinamico e personalizzato.
L’educazione artistica non sarà più solo incentrata sulle tecniche tradizionali, ma includerà anche l'apprendimento su come collaborare con le macchine e sfruttarne il potenziale creativo. Questo non toglierà spazio all'arte classica, ma piuttosto offrirà un nuovo livello di integrazione tra uomo e tecnologia, permettendo agli studenti di combinare abilità manuali e creative con le nuove tecnologie.
Inoltre, l'AI potrebbe cambiare radicalmente il concetto di "errore" nell'arte, trasformandolo da ostacolo a opportunità, dove l'imprevisto generato dall'AI potrebbe essere visto come parte del processo creativo. Le future generazioni impareranno a co-creare con l'AI, espandendo così la loro capacità di raccontare storie e di innovare con l’arte.
Oggi l'IA generativa, per quanto possa far emergere concetti artistici sorprendenti dal suo Spazio Latente, è solo uno strumento tra tanti per creare. Un domani, però, potrebbe non essere più così. Nel momento in cui esisteranno dei sistemi autonomi dotati di super-intelligenza, questi potrebbero anche scegliere di creare arte per diletto. Cosa ne pensi di questo scenario ipotetico?
È uno scenario affascinante e ricco di implicazioni. Se i sistemi dotati di super-intelligenza arrivassero a creare arte per diletto, sarebbe necessario ridefinire il concetto stesso di arte. Al momento, l'arte è intrinsecamente legata all'esperienza umana, alla nostra capacità di sentire, interpretare e dare significato alle emozioni e al mondo che ci circonda. Un sistema autonomo, anche se avanzatissimo, potrebbe forse simulare l'atto creativo, ma rimarrebbe da chiedersi se sarebbe in grado di percepire il significato profondo dietro le sue creazioni o se queste sarebbero solo il risultato di algoritmi sofisticati che elaborano pattern.
Inoltre, un'AI super-intelligente che crea per diletto potrebbe alzare interrogativi sulla sua "motivazione". Creare per il piacere implica una forma di coscienza o autoconsapevolezza che attualmente sfugge alla definizione che abbiamo della tecnologia odierna. Se mai dovessimo trovarci di fronte a tali sistemi, saremmo costretti a confrontarci con una nuova era dell'arte, dove il concetto di autore si espanderebbe oltre i confini umani.
Credo, tuttavia, che l'arte umana continuerà ad avere un posto speciale. Anche se l'AI può produrre opere sorprendenti, il valore dell'arte risiede nella sua capacità di connettersi con l’esperienza umana, e finché ci sarà il bisogno di comunicare qualcosa di profondamente umano, l'arte creata dalle persone manterrà il suo ruolo centrale.
Chiudiamo in bellezza: lasciaci con una delle tue poesie.
Sogni di polvere
Sono fatta di sogni,
di polvere sparsa nel vento.
Ogni frammento di me
danza, sospeso tra il cielo e la terra,
dove la luce incontra l’ombra
e i silenzi raccontano storie.
Non cercarmi nei luoghi consueti,
mi troverai tra i ricordi sfocati,
tra le pieghe del tempo,
nei sussurri delle stelle cadenti.
Sono un frammento che si disperde
ma quando mi penserai,
tornerò a danzare,
nel riflesso di un sogno
mai finito.