


I Designer del Nuovo Mondo
Nel caos del cambiamento, ogni linea è una scelta, ogni forma un monito per il futuro


Col finire di marzo, si chiude un trimestre che sembra contenere interi anni.
In circa novanta giorni, il 2025 ha già cominciato a piegare il tempo e a riscrivere le regole della trasformazione, facendo apparire il 2024 come un preludio ormai distante.
L'accelerazione del Nuovo Mondo si fa più intensa, eppure, paradossalmente, sappiamo che ciò che ci attende negli anni a venire sarà ancor più vertiginoso. Stiamo ancora viaggiando in superficie, mentre sotto di noi si muovono placche invisibili di innovazione, pronte a ridisegnare il paesaggio della creatività.
In questo flusso incessante, i creativi si fanno cartografi dell’ignoto: tracciano linee che non sono solo estetica, ma gesti di creazione, sismografi emotivi, oracoli di ciò che verrà. Ogni forma diventa un presagio, ogni scelta progettuale un tentativo di orientarsi nel caos del presente.
E anche noi, con Tales from the Latent Space, proseguiamo questo viaggio affascinante. Abbiamo abbondantemente superato i 750 iscritti: un villaggio in espansione, una piccola costellazione di visionari che guardano al futuro con occhi pieni di meraviglia. La strada è ancora lunga, ma ogni passo è un atto di fiducia. Siamo pionieri e stiamo disegnando, insieme, le mappe del Nuovo Mondo.
Ora è giunto il momento di partire, il nostro treno è in arrivo al primo binario zero. Allontanarsi dalla linea gialla!

Che cos’è la Singolarità Tecnologica?
La pubblicazione di dicembre 2024, intitolata Le Fornaci del Nuovo Mondo, si apriva con l’articolo Che cos’è l’AGI?, uno tra i più importanti mai inseriti nel magazine, fondamentale per comprendere la nostra realtà attuale e prepararsi agli anni che verranno. Questo articolo può invece essere considerato come la continuazione diretta del discorso sull’AGI, perché stiamo per parlare di Superintelligenze.
Buona lettura:
Negli ultimi decenni, il mondo ha assistito a un'accelerazione senza precedenti in tutti i campi della tecnologia, dall'informatica all'intelligenza artificiale, dalla robotica alle scienze dei dati. Questa crescita esponenziale ci porta a riflettere su un concetto tanto affascinante quanto complesso: la Singolarità Tecnologica.
Con questo termine, si fa riferimento a un evento cruciale per l’evoluzione umana, considerato da alcuni come un traguardo inevitabile e da altri come pura speculazione. In entrambi i casi, l’idea è che la crescita esponenziale (o super-esponenziale) della tecnologia, in particolare dell’Intelligenza Artificiale, possa condurre a un momento in cui diventerà talmente potente da superare in modo inimmaginabile la capacità cognitiva umana. A partire da quel punto di svolta, la tecnologia continuerebbe a migliorare sé stessa a velocità sempre maggiore, generando una serie di conseguenze imprevedibili per l’umanità.

L’idea di Singolarità Tecnologica affonda le radici in diverse scuole di pensiero. Alcune di queste derivano da previsioni fantascientifiche, altre dal mondo accademico e dalla ricerca avanzata in ambito IA, robotica, nanotecnologie e scienze dell’informazione. L’uso del termine “singolarità” è stato reso popolare soprattutto dal saggista Raymond Kurzweil, ma altri autori prima di lui avevano già intravisto la possibilità di una crescita tecno-economica accelerata. Pensiamo a figure come il matematico John von Neumann, il romanziere di fantascienza Vernor Vinge, e gli studiosi di cibernetica che, già negli anni ‘50, iniziavano a presagire l’accelerazione.
La Singolarità Tecnologica, per definizione, potrebbe racchiudere un momento di “non ritorno”, nel quale gli esseri umani passerebbero il testimone di “specie più intelligente sul pianeta” a entità digitali o ibride. Questa prospettiva riesce a essere contemporaneamente affascinante e inquietante, ponendoci questioni esistenziali profonde: quale sarà il nostro ruolo nel mondo quando le macchine supereranno di gran lunga l’umano in termini di intelligenza, capacità decisionali e problem solving?
Il ritmo degli ultimi anni, caratterizzato da scoperte e applicazioni sempre più sorprendenti, porta a pensare che la Singolarità potrebbe non essere un miraggio di fantascienza, ma un evento tangibile, probabilmente già dietro l’angolo.
È importante quindi esplorare la natura di questo concetto, le forze che lo guidano, i potenziali impatti sociali, le questioni etiche e le possibili traiettorie per il futuro.

Il Concetto di Singolarità
Il termine "singolarità" deriva dal concetto matematico, in cui una funzione tende all’infinito o perde ogni significato nel punto di discontinuità. Questa parola viene spesso associata alla fisica, in particolare alla cosmologia, dove una singolarità è un punto nello spazio-tempo in cui le leggi della fisica che conosciamo si “rompono” o cessano di essere applicabili, come la singolarità del Big Bang o dei buchi neri.
Analogamente, la Singolarità Tecnologica è il punto in cui la nostra comprensione, le nostre previsioni e le nostre capacità di controllo vengono meno, perché una nuova entità superintelligente – o un insieme di tecnologie evolute – prende il sopravvento, modificando radicalmente il corso degli eventi.
Il termine è stato introdotto dallo scrittore di fantascienza e matematico Vernor Vinge. Nel suo saggio del 1993 The Coming Technological Singularity, predisse che se avessimo creato macchine con capacità superiori all’intelligenza umana, questi sistemi sarebbero stati in grado di auto-migliorarsi in modo esponenziale, conducendo a un cambiamento radicale nella struttura della civiltà umana.
In seguito, Raymond Kurzweil ha ulteriormente sviluppato il concetto nel suo libro del 2005 La Singolarità è Vicina (e poi nel recente seguito La Singolarità è più Vicina). Kurzweil ha postulato che l’evoluzione delle tecnologie computazionali e, soprattutto, l’IA, avanzi a un tasso esponenziale noto come legge dei ritorni acceleranti. Secondo questa legge, la potenza di calcolo e la capacità degli algoritmi migliorerebbero così rapidamente da rendere obsolete le proiezioni lineari. Una volta raggiunto un livello di intelligenza di gran lunga superiore a quella umana, non saremmo più in grado di prevedere o controllare l’operato di questi sistemi intelligenti.
La definizione della Singolarità Tecnologica porta con sé alcuni punti chiave:
Auto-miglioramento iterativo: Un’IA sufficientemente avanzata potrebbe migliorare sé stessa senza bisogno dell’intervento umano, accelerando il proprio sviluppo.
Crescita esponenziale: L’accelerazione del progresso diventa sempre più rapida.
Momento di rottura: Raggiunto un certo livello di capacità computazionale e di comprensione del mondo, le tecnologie intelligenti potrebbero progredire e innovare a ritmi che agli umani risulterebbero incomprensibili.
Imprevedibilità: Oltre una certa soglia, diventa difficile se non impossibile prevedere quale forma assumerà la società e come l’umanità si adatterà a un mondo dominato da macchine molto più intelligenti di noi.
Questi punti chiave, se realizzati, avrebbero delle implicazioni enormi: dalla risoluzione dei più grandi problemi che affliggono l’umanità, come le malattie genetiche, il cancro, la fragilità dei sistemi sanitari, l’invecchiamento, la fame nel mondo, gli inquinanti tossici, il cambiamento climatico, le guerre, fino a una radicale trasformazione dei sistemi economici e sociali odierni.

Le Forze Motrici verso la Singolarità
Uno dei pilastri fondamentali nel discorso sulla Singolarità Tecnologica è la cosiddetta Legge di Moore. Formulata nel 1965 dal cofondatore di Intel Gordon Moore, afferma che il numero di transistor su un chip raddoppia circa ogni 18 mesi, portando a una crescita esponenziale della potenza di calcolo disponibile. Anche se negli ultimi anni questa tendenza si è parzialmente rallentata a causa dei limiti fisici dei processi di miniaturizzazione, la potenza di calcolo continua a crescere in modo straordinario grazie a nuove architetture (GPU, TPU, Neuromorfiche) e sviluppi nella computazione quantistica.
La potenza di calcolo da sola non basta a spingerci verso la Singolarità; è la capacità di creare algoritmi di apprendimento automatico sempre più sofisticati a dare la vera spinta propulsiva. Dalle primitive reti neurali degli anni ‘60 e ‘70, siamo passati a modelli di deep learning in grado di riconoscere volti, tradurre lingue quasi in real time e generare testo, immagini, musica e video credibili. I progressi nel Natural Language Processing (NLP) hanno portato allo sviluppo di sistemi conversazionali e di generazione di contenuti difficilmente distinguibili dal lavoro umano.
Un’altra forza motrice è l’enorme disponibilità di big data generati dall’uso quotidiano di Internet, dispositivi mobili, sensori IoT e piattaforme social. Queste informazioni alimentano e “addestrano” gli algoritmi, permettendo di sviluppare modelli predittivi e di analisi comportamentale sempre più accurati. L’interconnettività globale fa sì che ogni scoperta e innovazione possa essere condivisa istantaneamente, accelerando ulteriormente i cicli dell’innovazione.
Le tecnologie digitali non sono isolate da tutto il resto: l’ingegneria genetica, la robotica avanzata, le biotecnologie e la nanotecnologia si sviluppano a loro volta e, in certi casi, si fondono e si potenziano con l’IA. Pensiamo ai progressi nell’ambito del “brain-computer interface”, dove i chip neurali o i caschetti non invasivi potrebbero permettere l’interazione diretta cervello-macchina. Questa convergenza crea sinergie, potenziando ancora di più l’avanzata della tecnologia e rendendo sempre più plausibile un passaggio verso forme di intelligenza ibrida o potenziata.

Impatto Socio-Economico
La prima conseguenza tangibile dell’avanzamento tecnologico in direzione della Singolarità è il cambiamento del mercato del lavoro. L’automazione e l’IA già oggi sostituiscono lavori manuali e, sempre più spesso, impieghi di tipo cognitivo.
Bot che rispondono alle domande dei clienti, software che compilano documenti legali, screening automatico dei curriculum, algoritmi che forniscono diagnosi con un’accuratezza del 100%, robot nelle catene di montaggio: tutto questo riduce la necessità di mansioni che una volta erano appannaggio degli esseri umani.
Questo fenomeno solleva preoccupazioni legittime riguardo alla futura disoccupazione di massa. Alcuni esperti ipotizzano che l’IA creerà nuove forme di lavoro, ma molti altri temono un divario crescente tra chi possiede le competenze richieste e chi ne rimane escluso per ragioni sociali ed economiche. Proposte come il reddito universale di base sono delle ipotetiche soluzioni per compensare la perdita di posti di lavoro, ma non sono affatto semplici da implementare e il dibattito rimane aperto e lontano da una reale risoluzione.
Un rischio concreto dell’avanzare dell’IA è che il potere tecnologico si concentri nelle mani di poche grandi aziende e di governi con risorse sufficienti per investire. Questo scenario comporta la possibilità di una maggiore disparità economica e sociale. I primi a controllare l’AGI avranno a disposizione uno strumento estremamente potente, in grado di influenzare i mercati, orientare opinioni politiche e decidere del destino di ogni settore industriale.
Se la Singolarità dovesse verificarsi, il primo paese a passare dall’AGI a una superintelligenza potrebbe di fatto dominare l’economia mondiale, aumentando ulteriormente la forbice della disuguaglianza e portando a disordini sociali fuori da ogni scala. Sarebbe quindi necessario un allineamento globale sulla gestione delle nuove forme di intelligenza che emergeranno dalla Singolarità.
Con lo spostamento delle competenze richieste nel mondo del lavoro, anche l’educazione dovrà cambiare profondamente. Non basta più insegnare nozioni statiche, perché ciò che impariamo oggi diventerà certamente obsoleto domani. Occorre formare nuove generazioni capaci di adattarsi rapidamente, di imparare a imparare e di gestire l’interazione con le macchine. La flessibilità cognitiva, la capacità di lavorare in team e la creatività diverranno sempre più fondamentali.
In un mondo in cui l’IA scrive e gestisce codice perfettamente funzionante, redige report e analisi di mercato, genera design grafici impeccabili e compie autonomamente attività di vendita, le abilità umane più apprezzate potrebbero diventare quelle legate all’intuizione, all’empatia, all’interpretazione critica della realtà, alla consapevolezza di sé o alle prestazioni atletiche.
L’avvento di tecnologie sempre più immersive, come la realtà virtuale e aumentata, potrebbero modificare radicalmente il nostro modo di vivere esperienze culturali e di intrattenimento. Questo si potrà tradurre in un mercato di contenuti e servizi personalizzati, un intrattenimento “su misura” basato su algoritmi in grado di predire i nostri gusti e persino incanalarci verso nuove passioni.
Allo stesso modo, l’IA generativa ridefinisce il concetto di proprietà: musica, libri e opere audiovisive generate potrebbero essere prodotte in quantità enorme a costi marginali, portando a una potenziale svalutazione economica e culturale del “prodotto creativo”. Mantenere l’originalità e il valore dell’espressione umana potrebbe diventare una vera sfida in un mondo di contenuti generati su misura.

Vantaggi, Rischi, Dilemmi e Segnali dell’Accelerazione Tecnologica
L’avvicinarsi della Singolarità Tecnologica è sia una straordinaria opportunità che una grande incognita per la razza umana. Da una parte, siamo di fronte a dei progressi che stanno già rivoluzionando radicalmente la medicina, l’istruzione, la produzione industriale, la gestione delle risorse e la nostra comprensione di ciò che significa essere umani. Dall’altra, ci troviamo dinnanzi a una serie di rischi non trascurabili, che spaziano dall’aumento delle disuguaglianze sociali fino alla totale perdita di controllo sulle macchine superintelligenti.
Per comprendere al meglio come la corsa accelerata verso la Singolarità stia già plasmando le nostre vite, è essenziale analizzare a fondo sia i benefici potenziali che gli scenari più allarmanti e spaventosi, mantenendo un approccio razionale.
Per cominciare, le prospettive più luminose offerte dall’IA e dalla crescita esponenziale della potenza di calcolo sono a dir poco entusiasmanti. Una superintelligenza orientata al bene comune – o comunque un insieme di tecnologie intelligenti allineate con i nostri interessi – può accelerare ulteriormente la ricerca in ambito farmaceutico e biotecnologico, rendendo possibili e diffusamente accessibili cure impensabili fino a pochi anni fa.
Stiamo già avendo un assaggio di questa “medicina potenziata” grazie ai modelli di computer vision che analizzano immagini diagnostiche con precisione superiore a quella umana, rilevando tempestivamente patologie gravi e proponendo trattamenti personalizzati. Analogamente, l’IA potrebbe monitorare i cambiamenti climatici alla ricerca di pattern anti-intuitivi che potrebbero far emergere nuove soluzioni più efficaci per la cattura della CO2, l’ottimizzazione dei consumi energetici, la gestione oculata delle risorse idriche e la geoingegneria.
L’ingresso dell’IA in settori critici ci obbliga anche a confrontarci con il tema del controllo e della responsabilità. Nel momento in cui un algoritmo prende decisioni che influiscono sulla vita delle persone, come il riconoscimento facciale, i sistemi di scoring creditizio o i sistemi di guida autonoma, si crea uno spazio d’ombra in cui risulta difficile stabilire chi o che cosa debba rispondere degli eventuali errori.
Mentre le comunità di ricercatori e alcuni governi si interrogano su come disciplinare e “allineare” le IA a dei principi di trasparenza ed equità, la realtà circostante ci mostra segnali di cambiamento sempre più rapidi ed evidenti. Smart device sempre più capaci stanno proliferando nella nostra quotidianità e il tempo che intercorre tra una scoperta scientifica e la sua applicazione pratica si riduce sempre di più.
Internet e la condivisione istantanea delle informazioni permettono a un’idea di espandersi in modo capillare nel giro di pochissime ore. Le imprese stanno capendo che investire in IA, robotica e settori correlati non è soltanto una scelta strategica, ma una questione di sopravvivenza in un mercato che cambia a velocità incontrollabile.
Eppure, nell’osservare tutti questi segnali, non si può fare a meno di notare come la vera partita si giochi ancora su un piano prettamente umano, ossia sulla nostra capacità di orientare e regolare senza soffocare l’innovazione, ma soprattutto comprendere la portata di tale rivoluzione. Uno degli aspetti più urgenti riguarda la distribuzione degli effetti benefici e, di converso, la mitigazione delle conseguenze negative. Se l’IA aiuta a risolvere alcuni dei problemi più complessi della società, occorre assicurarsi che il suo impiego sia effettivamente equo.
Questa situazione fa emergere l’importanza di un’etica globale condivisa e di un’educazione continua, che non miri semplicemente a insegnare come programmare un algoritmo, ma che formi individui in grado di cogliere le implicazioni sociali, filosofiche e relazionali dell’era digitale. Le persone dovranno sviluppare un senso critico rafforzato, imparare a distinguere l’informazione verificata dalla disinformazione, a valutare le scelte in termini di impatto collettivo e non solo di efficienza o vantaggio personale. È qui che si scorge, in controluce, uno dei più grandi paradossi della Singolarità: proprio mentre ci avviciniamo all’emersione di un’intelligenza superiore alla nostra, ci rendiamo conto che la sfida più ardua consiste nell’essere sufficientemente “umani” da guidare con saggezza un cambiamento che sarà certamente irreversibile.
Siamo di fronte a un bivio storico, in cui i benefici possono superare di gran lunga i rischi, a patto di agire con la consapevolezza di dover gestire un potere immensamente più grande di tutto ciò che abbiamo mai avuto tra le mani. Affrontare in un’unica prospettiva vantaggi, rischi, dilemmi etici e indicatori dell’attuale velocità di cambiamento significa, prima di tutto, riconoscere che la Singolarità sarà un processo profondamente sociale. L’umanità intera, allora, sarà chiamata a interrogarsi non solo su come utilizzare queste nuove facoltà, ma soprattutto su che cosa vogliamo diventare, una volta che avremo a disposizione strumenti tanto potenti da mutare l’essenza stessa del nostro agire nel mondo.

Scenari dal Futuro
Una delle ipotesi più discusse è quella del transumanesimo: la fusione progressiva tra uomo e tecnologia, finalizzata a potenziare le capacità fisiche e cognitive degli umani. Già oggi esistono impianti cocleari per restituire l’udito, protesi robotiche controllate dal pensiero, e chip neurali in fase di sperimentazione per ripristinare o migliorare funzioni cerebrali. Nel futuro, la Singolarità Tecnologica potrebbe coincidere con la capacità di “trascrivere” la coscienza umana su dei supporti digitali, esattamente come facciamo oggi con i dati, raggiungendo una sorta di immortalità tecnologica.
Se più attori dovessero sviluppare IA superintelligenti nello stesso periodo, ad esempio gli Stati Uniti e la Cina, potremmo ritrovarci con un pluralismo di entità artificiali, capaci di competere o collaborare tra loro. In uno scenario ottimistico, queste superintelligenze coopererebbero per il bene comune, proiettandoci in un’era di abbondanza e benessere diffuso come non si è mai visto.
Nel caso peggiore, una superintelligenza fuori controllo potrebbe condurre a eventi catastrofici: un conflitto armato, una crisi economica globale o uno scenario in cui l’umanità viene progressivamente soggiogata e distrutta. Alcuni studiosi di sicurezza dell’IA, come il filosofo Nick Bostrom, sottolineano la necessità di creare meccanismi di “allineamento” (AI alignment), affinché gli obiettivi delle macchine rimangano compatibili con i nostri anche quando le loro capacità saranno superiori.
Se l’IA e la robotica rimpiazzeranno la maggior parte dei lavori umani, si profilerà una società in cui la produzione di beni e servizi sarà quasi completamente automatizzata. Questo libererà gli esseri umani dalle occupazioni di routine, ma pone degli importanti interrogativi: come si distribuirà la ricchezza generata? Come dare un senso alla vita senza un lavoro tradizionale?

Conclusioni non banali
La Singolarità Tecnologica è un qualcosa che riesce a essere contemporaneamente un sogno utopico e un incubo distopico, in base all’approccio e all’angolazione con cui la si osserva. Un concetto che, pur nascendo da speculazioni futuristiche, sta progressivamente acquisendo una dimensione concreta nella realtà quotidiana.
Ciò che appare chiaro è che, stando all’attuale ritmo di innovazione e alla convergenza di più tecnologie, ci troviamo di fronte a un’accelerazione straordinaria, che rende le previsioni lineari sempre meno affidabili e ci mostra che il confine tra il possibile e l'impossibile è sempre più sbiadito. L’IA sta già penetrando in profondità nella nostra vita quotidiana, e la velocità con cui i sistemi intelligenti evolvono ci suggerisce che potremmo essere davvero vicini a un punto di svolta. Siamo di fronte a una fase storica, in cui la convergenza tra uomo e macchina potrebbe trasformare radicalmente il nostro mondo, con impatti profondi e duraturi su ogni aspetto della vita.
La Singolarità non è un evento che possiamo affrontare con passività o con un fatalistico “accadrà e basta”. Al contrario, richiede uno sforzo di coordinazione globale per allineare il comportamento delle superintelligenze con l’etica umana.
Se siamo davvero vicini alla Singolarità Tecnologica, come molti segnali paiono indicare, allora la necessità di prepararci adeguatamente e responsabilmente risulta più imperante che mai. È un compito che coinvolge tutti: dalle istituzioni che regolamentano l’innovazione alle aziende che la sviluppano, dalle scuole che formano i cittadini del futuro agli studiosi che riflettono sugli aspetti filosofici e antropologici dell’era digitale. Solo comprendendo la complessità e la portata di questo cambiamento potremo sperare di orientarlo in senso positivo.
La Singolarità è un orizzonte con cui dovremo confrontarci, forse anche prima di quanto immaginiamo. Prepararsi significa informarsi, discutere, regolare con criterio a livello globale e, dove necessario, correggere la rotta. Significa anche cogliere le enormi opportunità che questo salto evolutivo ci offre, nella speranza di creare un mondo più prospero, equo e consapevole delle straordinarie possibilità che possono emergere quando la mente umana e l’intelligenza delle macchine si incontrano al massimo delle loro potenzialità.
Avvenimenti del mese
Le notizie più interessanti e creative dal mondo della tecnologia, accuratamente selezionate per districarsi tra il rumore informativo.

Le gemme di Google
Il 3 marzo Google ha lanciato Data Science Agent all’interno di Colab, un agente AI basato su Gemini 2.0 che genera dei notebook per l’analisi dei dati.

Data Science Agent è integrato direttamente all’interno di Google Colab e consente agli utenti di generare automaticamente dei notebook completi di codice, librerie e strumenti per le analisi partendo da semplici descrizioni in linguaggio naturale.
Il processo è stato pensato per essere estremamente intuitivo:
L’utente apre un nuovo notebook su Colab
Carica i dati nell'apposito riquadro a destra
Descrive cosa vuole ottenere da quei dati con un prompt
L'agente risponderà con un elenco di azioni che andrà a eseguire, chiedendo una conferma prima di iniziare.
Se è tutto ok, clicca su "Esegui piano"
Nel giro di qualche minuto l'agente avrà prodotto un notebook, editabile manualmente, per eseguire l'analisi richiesta.
Data Science Agent si è classificato al 4° posto nel test DABStep: Data Agent Benchmark for Multi-step Reasoning su Hugging Face.
Il 12 marzo viene rilasciata da Google la famiglia di modelli open source Gemma 3, progettati per offrire prestazioni elevate su singole GPU o TPU.

I modelli si basano sulla stessa tecnologia di Gemini 2.0, proponendosi come la soluzione più efficiente e portatile nel suo ambito, capace di adattarsi a diverse esigenze hardware grazie a quattro versioni da 1B, 4B, 12B e 27B di parametri.
Questa suite di modelli consente agli sviluppatori di creare applicazioni intelligenti in grado di elaborare informazioni complesse, grazie a una finestra di contesto espansa fino a 128k token, ideale per gestire grandi volumi di dati. Il modello più grande supporta oltre 140 lingue e integra funzionalità avanzate di ragionamento testuale e visivo, aprendo la strada a nuove possibilità nell’analisi di immagini, testi e video.
Un altro elemento distintivo di Gemma 3 è il supporto per il "function calling", che permette di costruire dei workflow agentici sempre più sofisticati.
Insieme a Gemma 3, Google presenta anche ShieldGemma 2, uno strumento di sicurezza per le applicazioni basate su immagini che offre controlli specifici per identificare contenuti pericolosi, espliciti o violenti, aiutando gli sviluppatori a integrare dei livelli di sicurezza per gli utenti finali.
Nella stessa giornata, viene lanciato anche una nuova versione sperimentale di Gemini 2.0 Flash con multimodalità nativa per le immagini sia in input che output. Questo significa che il modello può ricevere immagini più testo e rispondere con nuove immagini o modifiche dei file caricati. È come avere un editor di immagini smart che risponde ai nostri comandi in linguaggio naturale.
Questo nuovo modello è attualmente disponibile all’interno dell’AI Studio di Google. Trattandosi però di una versione di beta, non può produrre immagini in alta risoluzione e ci dà la possibilità di esportarle solo con un piccolo watermark.
Sempre il 12 marzo viene lanciato anche un nuovo modello vision-language-action (VLA) per la robotica simile a Helix di Figure basato su Gemini 2.0.

Si chiama Gemini Robotics e punta a superare i limiti delle applicazioni digitali, portando le capacità di ragionamento degli LLM direttamente nei robot, in modo da renderli più utili e adattabili ai contesti del mondo reale.
Il modello consente al sistema robotico di interpretare comandi in linguaggio naturale, riconoscere e analizzare il contesto visivo e tradurre queste informazioni in azioni fisiche precise, esattamente come Helix. Può quindi gestire situazioni nuove e impreviste, reagendo in tempo reale ai cambiamenti ambientali e agli input degli utenti. Questa interattività, resa possibile da Gemini 2.0, rappresenta una svolta fondamentale per il controllo robotico.
Google DeepMind ha rilasciato Gemini Robotics-ER, un modello specializzato in “embodied reasoning” con un’attenzione particolare alla comprensione spaziale. Questa evoluzione consente ai ricercatori di integrare il modello con i loro sistemi di controllo a basso livello, migliorando le prestazioni dei robot in compiti complessi come la manipolazione fine di oggetti o l’esecuzione di operazioni multi-step. I test condotti hanno evidenziato un incremento significativo della precisione e dell’efficacia, con tassi di successo che raddoppiano o addirittura triplicano rispetto alla versione precedente.
Il modello può anche operare in una vasta gamma di robot, da piattaforme bi-braccio a soluzioni più complesse come gli umanoidi. Grazie a delle collaborazioni con partner strategici, tra cui Apptronik e altri tester selezionati, Deepmind sta definendo il futuro dei robot intelligenti, capaci sia di interagire in maniera fluida con gli esseri umani che di garantire elevati standard di sicurezza. Gemini Robotics e la sua versione ER sono infatti progettati per integrarsi con controlli di sicurezza specifici che monitorano e limitano le forze d’impatto per evitare le collisioni.
Oltre a tutto questo, è stato messo a disposizione dei ricercatori anche un nuovo dataset per valutare e migliorare la sicurezza semantica nell’ambito dell’IA “incarnata”. Questa iniziativa, ispirata anche alle famose Tre Leggi della Robotica di Asimov, punta a creare delle regole in linguaggio naturale che possano guidare i comportamenti dei robot in modo sicuro e allineato ai valori umani.
Il 13 marzo vengono rilasciati diversi aggiornamenti per l’app di Google Gemini, che la rendono molto più interessante e competitiva di quanto non sia mai stata.
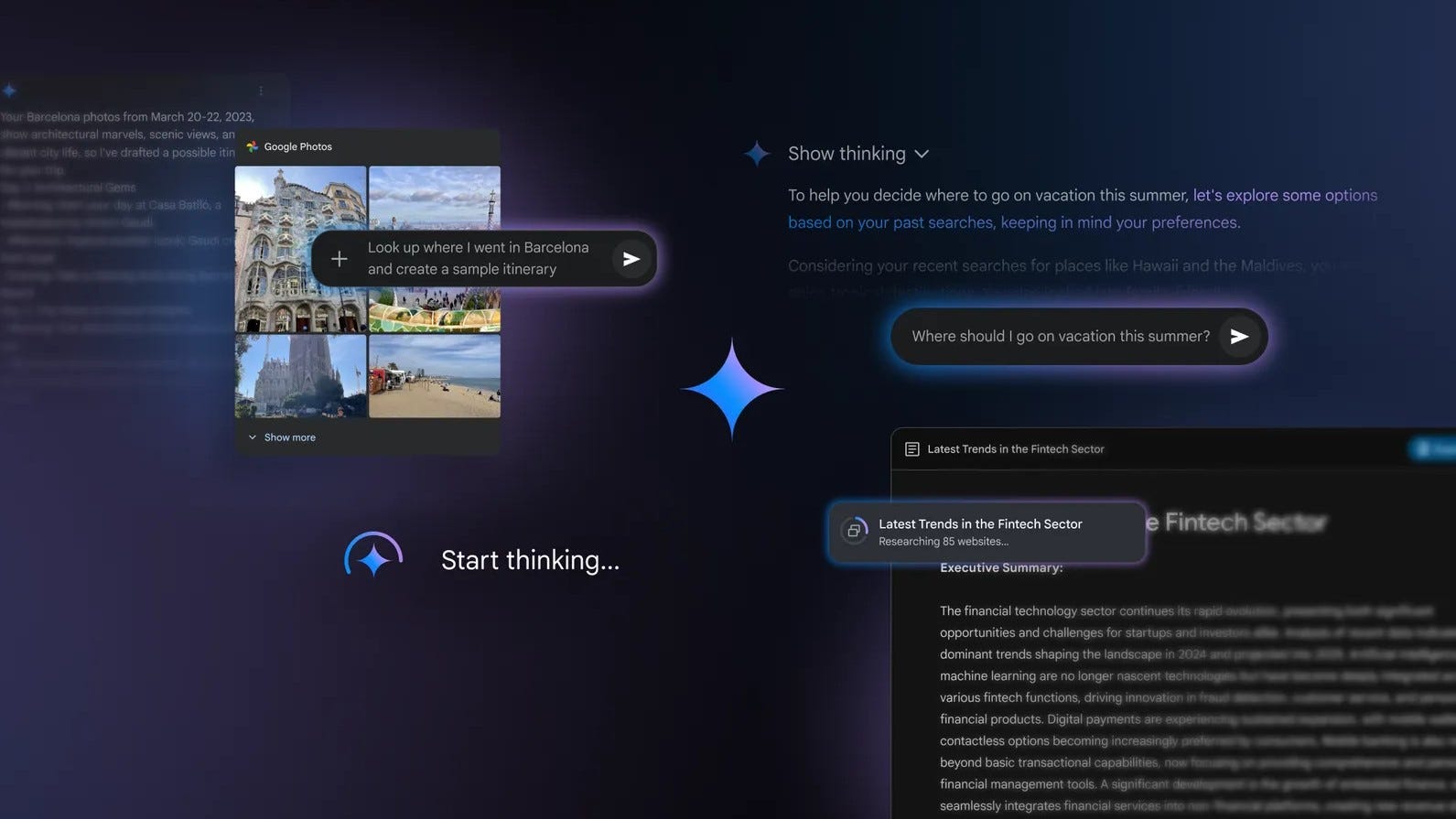
Infatti, da quando era stata lanciata nel 2023, l'app di Gemini non è mai risultata particolarmente utile per via dei suoi innumerevoli difetti: poche funzionalità, modelli scarsi che allucinavano molto di più rispetto a quelli dei competitor e un abbonamento che non valeva il suo prezzo.
Tutto questo ha iniziato a cambiare negli ultimi mesi, grazie all’introduzione dei nuovi modelli Gemini 2.0 e alle nuove funzionalità rilasciate nel mese di marzo.
Tra queste troviamo un aggiornamento di Deep Research, che non si basa più sul poco affidabile Gemini 1.5 ma su Flash Thinking Experimental. Con questo upgrade si possono ottenere dei report dettagliati, qualitativamente simili a quelli della versione di OpenAI, esportabili direttamente all’interno di Google Docs. Inoltre, lo strumento è ora disponibile a tutti gli utenti, con 5 richieste gratuite ogni mese per chi non dispone dell’abbonamento Gemini Advanced.
Un altro aggiornamento rilasciato lo stesso giorno consiste nella possibilità per Gemini 2.0 Flash Thinking Experimental di connettersi alle app e ai tuoi servizi Google dell’utente, con il suo permesso, per fornire risposte personalizzate in base alle esigenze individuali. Questo si unisce alle funzionalità di memoria già presenti nell’app, aumentando il grado di personalizzazione dell’esperienza utente. Ovviamente queste impostazioni sono attivabili e disattivabili a piacimento in qualunque momento per tutelare la propria privacy o avere dei modelli più neutrali.
Flash Thinking Experimental può utilizzare anche altre app come YouTube, Maps e Calendar per compiere delle azioni più complesse.
Sono stati aggiunti anche i Gems, l’equivalente di Google dei GPTs di OpenAI, ovvero dei semplicissimi “agenti” personalizzabili tramite un prompt di sistema che ne definirà la personalità e il comportamento. I Gems sono disponibili a tutti gli utenti.
Gli aggiornamenti all’app di Gemini proseguono il 18 marzo con l’aggiunta di Canvas e Audio Overview, una funzionalità che arriva direttamente da Notebook LM.

Canvas è un nuovo spazio interattivo integrato in Gemini, praticamente identico alla versione presente su ChatGPT. Con un semplice click sulla voce “Canvas” nella barra dei prompt, gli utenti possono generare bozze e perfezionare i testi grazie alla collaborazione con Gemini. La piattaforma permette di intervenire rapidamente sul tono, la lunghezza o il formato del contenuto, offrendo la possibilità di esportare i lavori su Google Docs per una condivisione intuitiva e collaborativa.
Oltre alla scrittura, Canvas è pensato anche per la programmazione, semplificando attività come la generazione e il debugging del codice. Lo strumento permette di trasformare le idee in prototipi funzionanti per applicazioni web, script in Python, giochi e simulazioni. Gli utenti possono generare, visualizzare in anteprima e modificare codice HTML, React e altri linguaggi, rendendo l’intero processo di sviluppo più rapido ed efficiente.
Invece, la funzionalità Audio Overview permette di trasformare i propri documenti in discussioni in formato podcast. Gemini crea una conversazione dinamica tra due “host AI”, che riassumono e collegano i vari argomenti presenti nei file caricati.
Queste nuove funzionalità sono disponibili a tutti gli utenti di Gemini, con Audio Overview che inizialmente supporta solo la lingua inglese.
Il 25 marzo viene rilasciato Gemini 2.5 Pro Experimental, il primo modello della nuova famiglia Gemini 2.5. Si tratta di un reasoning model (pare che tutti i Gemini 2.5 saranno modelli di ragionamento) che ottiene degli ottimi punteggi nei principali benchmark. Superando di qualche punto percentuale in alcuni test molti altri modelli SOTA attualmente presenti sul mercato.
Il nuovo modello è disponibile per il testing nell’AI Studio di Google o nell’abbonamento Advanced.
L’operatore dell’Opera
Sempre il 3 marzo, Opera annuncia Browser Operator, un agente AI integrato direttamente nel browser che può eseguire autonomamente diversi compiti.
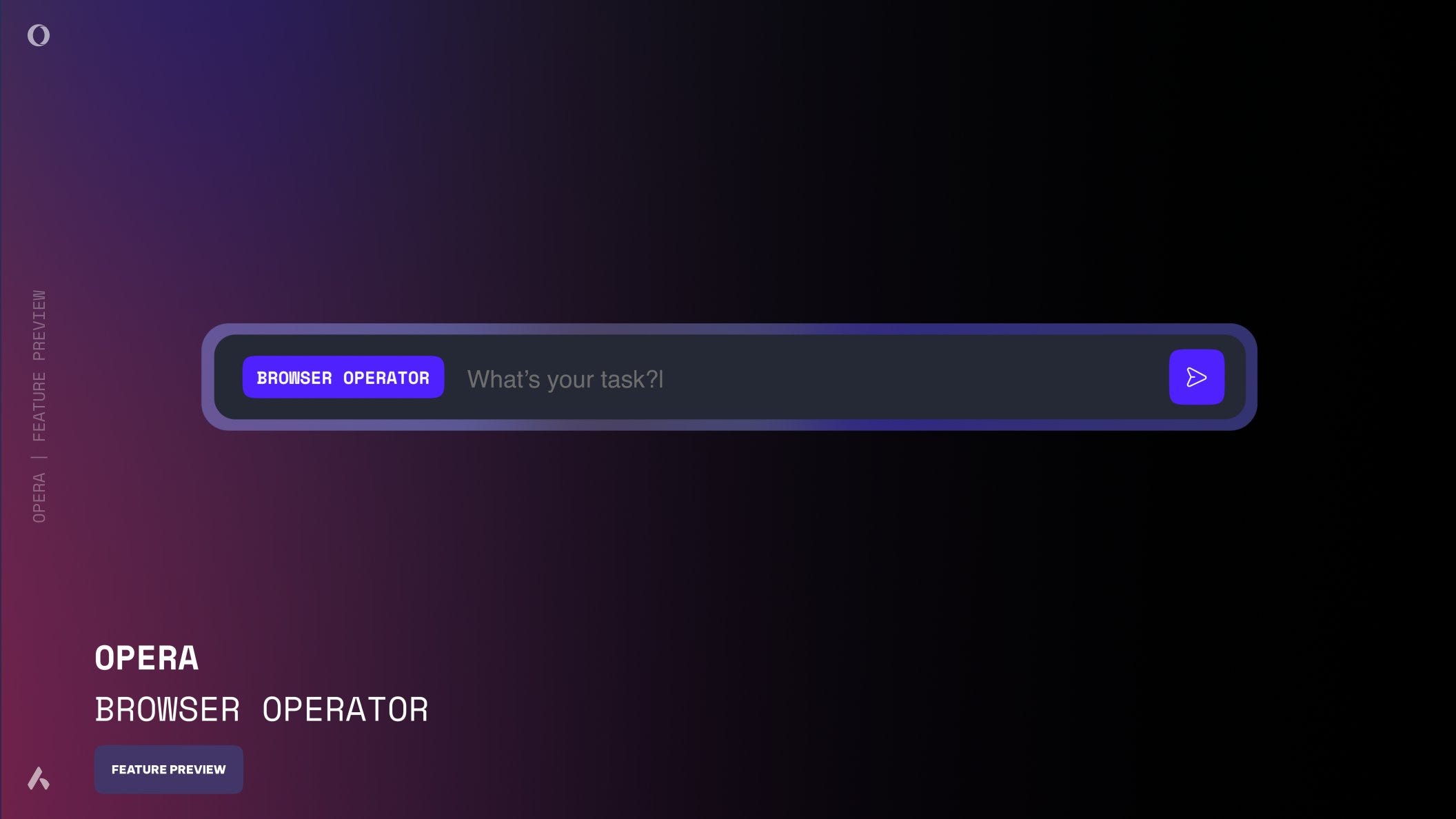
Concettualmente simile a Operator di OpenAI, Browser Operator è un vero e proprio assistente che si integra nativamente nel browser, sfruttando le risorse locali del dispositivo. Grazie all’uso diretto dei DOM e dei dati di layout delle pagine, riesce a comprendere il contesto senza ricorrere agli screenshot che rallentano e appesantiscono l’operatività dello strumento.
L’utente mantiene sempre il controllo, intervenendo manualmente in caso di operazioni sensibili come la compilazione di moduli o la conferma di acquisti, e potendo visualizzare ogni passaggio eseguito dall’agente.
L’idea alla base di Browser Operator è quella di rendere la navigazione più efficiente e personalizzata, offrendo agli utenti la possibilità di delegare compiti come l’acquisto online o la raccolta di informazioni, dedicando il proprio tempo ad attività più significative. Opera sta integrando questo agente nel suo browser attraverso un’esperienza intuitiva, accessibile sia dalla sidebar che dalla Command Line.
Uno degli aspetti più interessanti di Browser Operator, oltre al fatto di essere completamente gratuito, è il suo funzionamento completamente in locale. Non essendo necessario inviare dati a server esterni, le informazioni sensibili (come credenziali e dati personali) rimangono protette nel dispositivo dell’utente.
Il piccolo Qwen impara a pensare
Il 5 marzo Alibaba rilascia QwQ-32B, un modello di ragionamento open-weight super compatto che raggiunge le performance di DeepSeek R1.
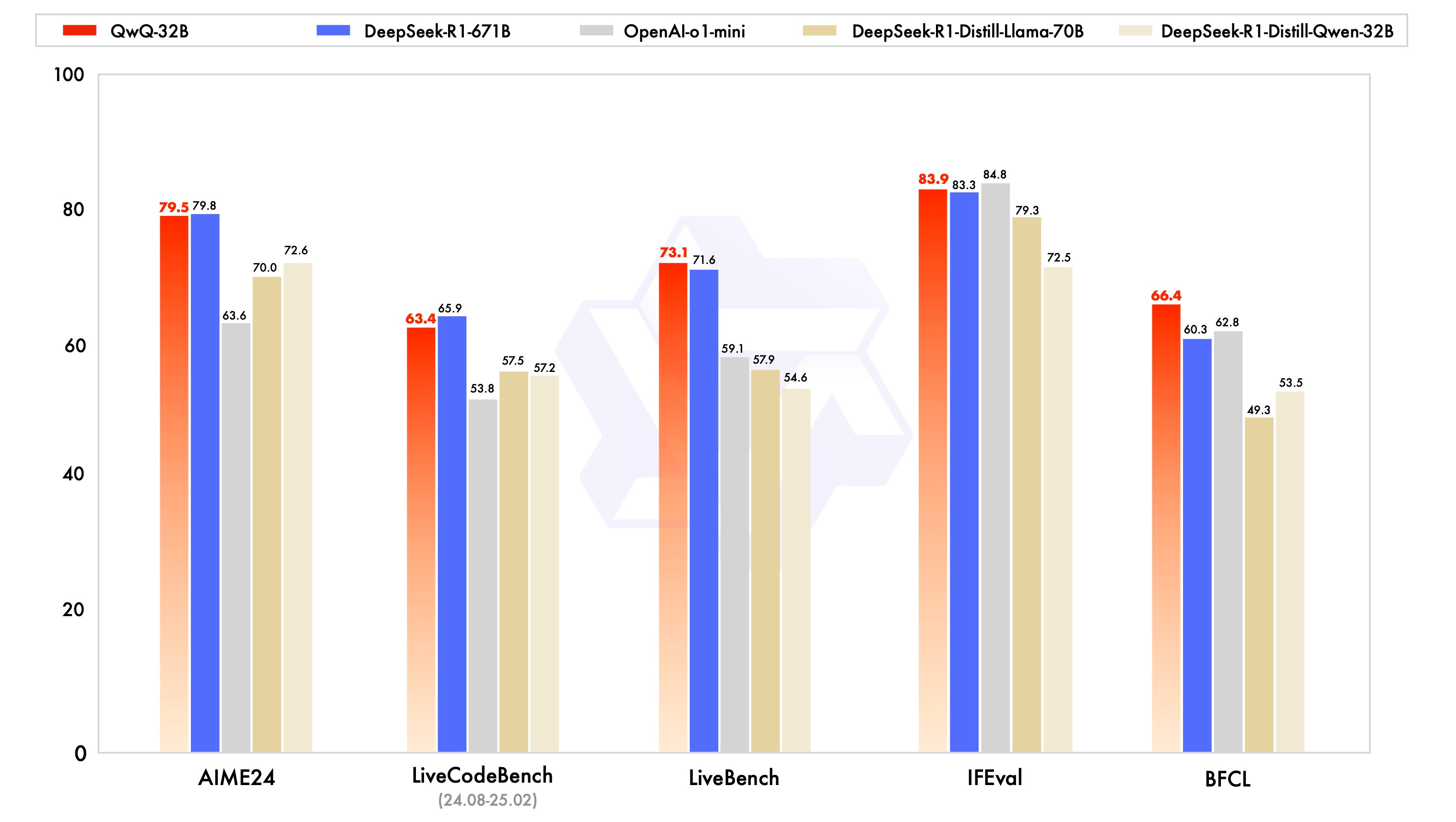
QwQ-32B è un nuovo modello della famiglia Qwen che, con soli 32 miliardi di parametri, raggiunge performance equiparabili a quelle del più massiccio DeepSeek R1 che ha 671 miliardi di parametri. Questo risultato, ottenuto partendo da un checkpoint cold-start, ovvero un punto di partenza per l'addestramento che non ha subito alcun fine-tuning, dimostra come il RL permetta di superare i limiti del pretraining tradizionale e migliorare le capacità di ragionamento dei modelli.
La creazione di QwQ-32B si articola in due fasi: nella prima, il modello viene ottimizzato per compiti di matematica e programmazione, sfruttando un verificatore di accuratezza per i problemi matematici e un server di esecuzione del codice per garantire che le soluzioni rispettino dei test predefiniti. Nella seconda, viene implementato un ulteriore ciclo di RL per potenziare le capacità generali, come la comprensione delle istruzioni e l’allineamento alle preferenze umane, integrando anche funzionalità agentiche per utilizzare strumenti e adattarsi al contesto.
QwQ-32B è stato distribuito su Hugging Face con licenza Apache 2.0 ed è disponibile gratuitamente all’interno della piattaforma Qwen Chat.
L’agente AI generale
Sempre il 5 marzo, una nuova startup cinese chiamata Manus AI lancia un omonimo Agente AI generale, progettato per gestire autonomamente i compiti del mondo reale.

Possiamo immaginare Manus come una fusione tra DeepResearch e Operator di OpenAI con Claude Code di Anthropic unificati in un sistema unico.
Il sito del progetto è pieno di esempi di compiti portati a termine dall’agente, che ci permettono di vedere sia i risultati finali che il replay delle sue azioni. Manus può passare agilmente dal creare siti di learning a web app complesse, dalle ricerche di mercato alla revisione di contratti legali, il tutto tramite la classica interfaccia di chat.
Le sue funzionalità chiave sono:
Ambiente sandbox Linux: opera all'interno di uno spazio di esecuzione controllato, in cui può installare software, eseguire script e manipolare file.
Esecuzione shell e riga di comando: può eseguire comandi shell, gestire processi e automatizzare attività di sistema.
Controllo del browser: Manus può navigare il web, estrarre dati dai siti, interagire con le UI ed eseguire JavaScript in una console del browser.
Gestione del file system: può leggere, scrivere e organizzare file.
Capacità di distribuzione: può distribuire applicazioni, tra cui la configurazione di siti Web e l'hosting di servizi su URL pubblici.
Tutto questo è reso possibile da un sistema multi-agente estremamente complesso che, per quanto risulti ancora imperfetto, è pensato per affrontare qualunque tipo sfida. Per sintetizzare, funziona con dei cicli come questo:
Analizza eventi: comprende le richieste degli utenti e lo stato dell'attività
Tool calling: sceglie accuratamente lo strumento o la chiamata API che gli permette di andare verso il passaggio successivo
Esegue comandi: esegue script shell, automazione web o elaborazione dati in una macchina virtuale Linux
Itera: perfeziona le sue azioni in base ai nuovi dati, ripetendo un ciclo fino al completamento dell'attività
Invia risultati: invia output strutturati all'utente sotto forma di messaggi, report o applicazioni distribuite
Standby: entra in uno stato di inattività fino a quando non viene fornito un ulteriore input da parte dell'utente
Il co-fondatore di Manus AI, Yichao Ji, ha detto che rilasceranno open-source alcuni dei loro modelli che hanno addestrato appositamente per Manus. Qualche giorno dopo si è però scoperto che l’agente si basa principalmente su Claude Sonnet 3.7 e ha accesso a 29 strumenti, tra cui il progetto open-source Browser Use.
Oltre l’uncanny valley degli Avatar
Il 6 marzo Tavus ha svelato l’evoluzione della sua Conversational Video Interface (CVI), introducendo un sistema completamente nuovo dotato di “intelligenza emotiva”.

La startup incubata da Y combinator ha presentato un’innovazione che promette di rendere le interazioni tra umani e macchine più naturali e coinvolgenti che mai.
Il prodotto è una sorta di sistema operativo completo che consente di creare agenti AI che vedono, ascoltano, capiscono e si impegnano realmente in interazioni faccia a faccia in tempo reale, il tutto alimentato da tre modelli proprietari che lavorano insieme per rendere le conversazioni più naturali:
Phoenix-3: un modello di rendering basato su tecniche di diffusione gaussiana anima l’intero volto, andando oltre la semplice sincronizzazione labiale. Phoenix-3 può controllare dinamicamente le emozioni generando espressioni facciali realistiche che conferiscono un aspetto autentico e umano alle interazioni digitali.
Raven-0: un sistema di percezione che interpreta in tempo reale movimenti, gesti e contatto visivo, interpretando le emozioni dell'utente. Raven-0 analizza continuamente movimenti, micro-espressioni e segnali contestuali, fornendo all’IA una vera “consapevolezza” dell’interlocutore.
Sparrow-0: un motore di conversazione basato su transformer che ottimizza i tempi di risposta, rispettando i turni del parlato e creando un flusso comunicativo che evita interruzioni e pause innaturali.
Per dimostrare le potenzialità di questa tecnologia, Tavus ha reso disponibile “Charlie”, una demo che trasforma il concetto di assistente virtuale. Charlie è in grado di ascoltare, analizzare il contesto e rispondere in tempo reale, offrendo una comunicazione che ricorda quella umana.
E se l’IA diventasse un ghostwriter?
Sempre il 6 marzo, Sunowrite rilascia Muse, il primo modello AI creato appositamente per la scrittura di finzione, come romanzi, sceneggiature e racconti.

Sudowrite è una piattaforma per la scrittura creativa basata sull’intelligenza artificiale e Muse è il suo nuovo prodotto di punta: un innovativo modello AI pensato per aiutare gli autori a superare il blocco dello scrittore e a stimolare la creatività.
Muse comprende il tono, lo stile e la direzione narrativa desiderata, offrendo spunti e suggerimenti che spaziano dallo sviluppo dei personaggi alla creazione di ambientazioni suggestive. Questa funzionalità è rivolta sia a scrittori professionisti che ad aspiranti autori, rendendo il processo di scrittura più fluido e dinamico.
Gli utenti hanno a disposizione diverse opzioni personalizzabili che consentono di adattare lo strumento alle proprie esigenze narrative. La novità sembra aver riscosso dell’entusiasmo tra alcuni scrittori, che vedono in Muse un valido alleato per superare i momenti di stallo creativo. Grazie alla capacità di proporre idee coerenti e originali, il nuovo strumento potrebbe rivoluzionare il campo della scrittura creativa, aprendo nuove prospettive moderne per i narratori di tutto il mondo.
Trasformare le immagini in documenti
Il 6 marzo si è rivelato essere un giorno pieno di annunci, con anche Mistral che rilascia il suo OCR, un’API di riconoscimento ottico che permette di estrapolare testo e immagini da dei documenti che sono stati scansionati o fotografati.

OCR sta per Optical Character Recognition, un sistema in grado di riconoscere ed estrarre con precisione ogni elemento presente in un documento, come testi, immagini, tabelle ed equazioni. La soluzione di Mistral si distingue dalla concorrenza per il suo altissimo grado di precisione (99.02% nei benchmark interni).
Il modello elabora documenti digitalizzati, come immagini e PDF, restituendo output in un formato strutturato che preserva l’ordine originale degli elementi. La capacità di Mistral OCR di “comprendere” ogni componente – inclusi i dettagli grafici e le strutture avanzate, come la formattazione LaTeX – permette una trascrizione fedele e accurata dei contenuti. I test comparativi hanno evidenziato come questo sistema offra risultati più precisi rispetto ad altri modelli presenti sul mercato.
L’API, già adottata da milioni di utenti sulla piattaforma Le Chat, è disponibile sulla piattaforma La Plateforme e offre anche la possibilità di implementazioni on-premises per organizzazioni che gestiscono dati particolarmente sensibili . Inoltre, la funzione “doc-as-prompt” consente di utilizzare documenti interi per estrarre informazioni specifiche in formati strutturati, facilitando l’integrazione con sistemi di intelligenza artificiale e flussi di lavoro automatizzati.
Il 17 marzo viene poi annunciato Mistral Small 3.1 (24B), definendolo il migliore della sua categoria. Basato sul precedente Mistral Small 3, questo aggiornamento migliora le prestazioni testuali, la comprensione multimodale ed espande la finestra di contesto a 128k token, rendendolo capace di superare modelli concorrenti come Gemma 3 e GPT-4o Mini, con velocità di inferenza di 150 token al secondo.

Un punto di forza di Mistral Small 3.1 è la sua leggerezza: può essere eseguito su una singola RTX 4090 o su un Mac con 32GB di RAM, rendendolo ideale anche per soluzioni on-device. Distribuito sotto licenza Apache 2.0, offre la possibilità di eseguire dei fine-tuning per specializzarlo in domini specifici.
Il modello è disponibile per il download su Hugging Face, sia in versione base pre-addestrata che in versione Instruct.
Strumenti per sviluppatori
L’11 marzo OpenAI rilascia dei nuovi strumenti pensati per semplificare lo sviluppo di agenti autonomi in grado di eseguire compiti complessi in maniera indipendente.
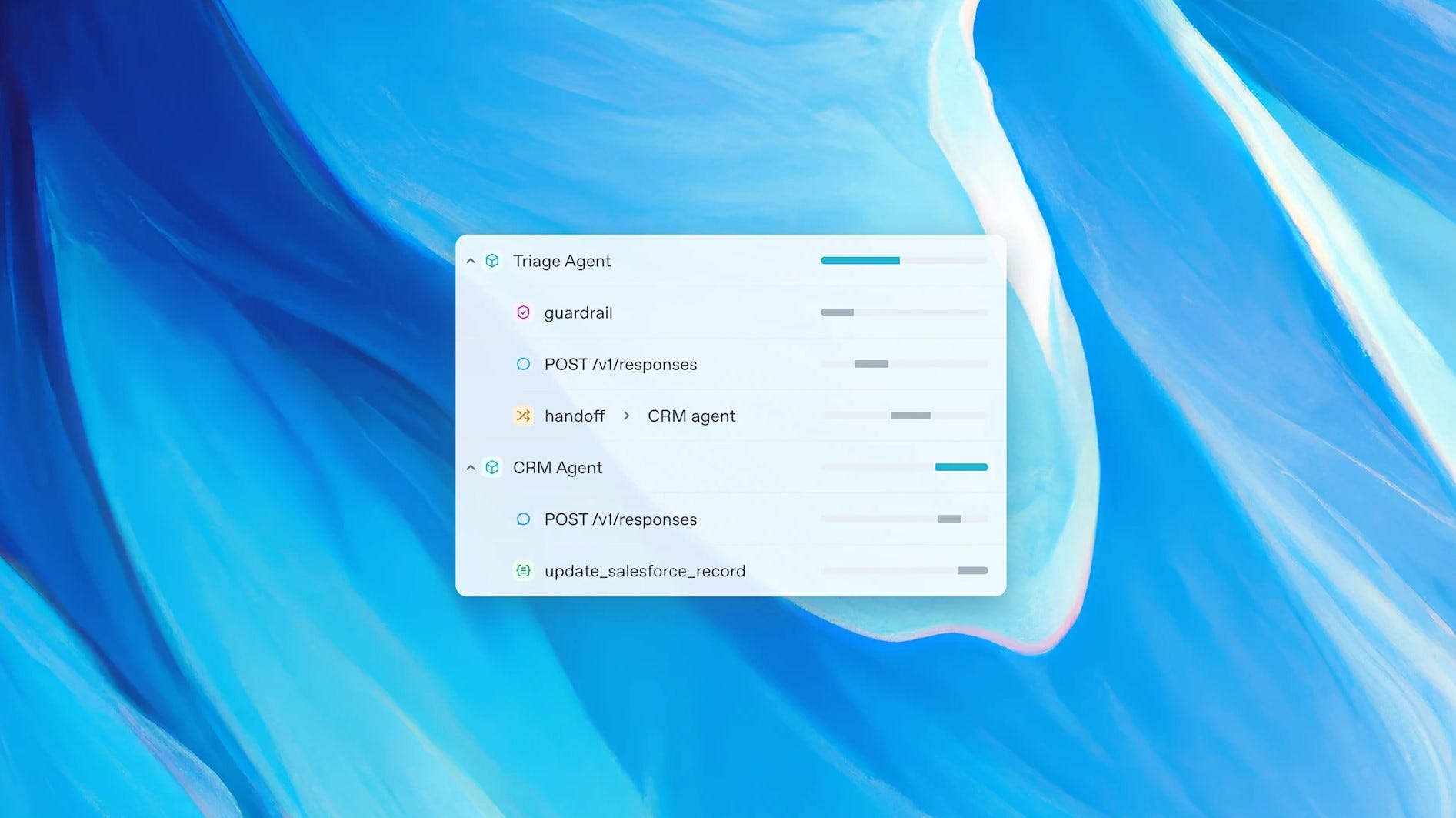
La nuova suite è composta da:
Responses API, un nuovo primitive che unisce la semplicità del Chat Completions con le capacità degli strumenti integrati, offrendo una base più versatile per lo sviluppo di applicazioni agentiche. Con una singola chiamata API, gli sviluppatori possono orchestrare operazioni multi-step con funzionalità come ricerca web, ricerca nei file e uso del computer, senza dover gestire complesse logiche di integrazione.
Agents SDK, un framework open-source che facilita la configurazione e l’integrazione di più agenti. Permette di definire ruoli specifici, implementare handoff intelligenti per trasferire il controllo da un agente all’altro durante un workflow multi-agente e applicare guardrail per garantire la sicurezza e l’accuratezza delle operazioni, rendendo più semplice lo sviluppo di soluzioni come assistenti virtuali, sistemi di supporto clienti e strumenti di analisi avanzata.
Il 13 marzo viene poi rilasciato Operator anche per gli utenti Pro nell'UE, Svizzera, Norvegia, Liechtenstein e Islanda.
Nella stessa giornata viene aggiunta la possibilità per o1 e o3-mini di eseguire analisi dati con Python direttamente all’interno di ChatGPT. L’aggiornamento permette di chiedere ai modelli di eseguire compiti come la regressione su dati di test, la visualizzazione di metriche aziendali e la conduzione di simulazioni basate su scenari.
Il 20 marzo viene poi lanciata una nuova suite di modelli audio, progettati per potenziare gli agenti vocali e migliorare l’interazione vocale. La suite include nuovi modelli avanzati per la conversione Speech-to-Text e viceversa, che offrono agli sviluppatori nuove possibilità per creare applicazioni vocali.
I nuovi modelli, denominati gpt-4o-transcribe e gpt-4o-mini-transcribe, offrono un notevole miglioramento nel Word Error Rate (WER), garantendo una maggiore precisione anche in condizioni di rumore, accenti diversi e velocità di parlato variabili. Questi progressi derivano da innovazioni mirate nell’uso del reinforcement learning e da un ampio midtraining su dataset audio di alta qualità, superando ampiamente le prestazioni del precedente Whisper.
Parallelamente, è stato presentato anche un terzo modello: gpt-4o-mini-tts per la sintesi vocale. Questo permette di istruire il modello non solo su cosa dire, ma anche su come dirlo, creando voci con stili specifici – da un tono empatico per l’assistenza clienti a una narrazione espressiva per progetti creativi.
Il 22 marzo viene rimossa da Sora la logica dei crediti e ora tutti gli utenti abbonati possono utilizzare il modello e la piattaforma illimitatamente.
Il 25 marzo viene lanciato GPT‑4o Image Generation, la tecnologia più avanzata per la creazione di immagini, integrata direttamente in ChatGPT e Sora.

Questo nuovo modello multimodale (MLLM) porta la generazione di immagini a un livello superiore, combinando fotorealismo, stilizzazione, precisione testuale e una comprensione contestuale che non si era mai vista prima.
La novità di GPT‑4o risiede nella sua capacità di interpretare e integrare contenuti testuali e visivi in maniera nativa. Può generare immagini che non solo sono esteticamente gradevoli, ma anche estremamente funzionali per la comunicazione di idee complesse. Grazie ad un modello autoregressivo che apprende dalla distribuzione congiunta di immagini e testo, il sistema garantisce immagini coerenti e accurate.
Il nuovo modello di OpenAI spicca per la capacità di generare immagini con un alto grado di fotorealismo, potendo creare anche soggetti anatomicamente impeccabili e ripetibili coerentemente di scena in scena. Vanta anche precisione senza precedenti nel rendering del testo, anche quando si tratta di frasi molto lunghe.
Questa caratteristica gli permette di generare infografiche, diagrammi e altri asset grafici di supporto alla comunicazione visiva. Il modello può anche eseguire iterazioni e perfezionamenti quasi in tempo reale, garantendo coerenza nelle immagini prodotte da una tornata di modifiche all’altra.
Più avanti nel magazine potete trovare un articolo di approfondimento sui modelli multimodali, con particolare attenzione a GPT-4o.
Il 27 marzo viene poi aggiornato nuovamente GPT-4o, migliorando significativamente la sua capacità di generare testi, al punto da superare persino GPT-4.5 nella classifica di ChatbotArena. Tra le varie migliorie possiamo notare che:
GPT-4o segue meglio le istruzioni, anche quelle complesse con più richieste mischiate in un unico prompt
"Ragiona" meglio su problemi tecnici, soprattutto nel coding
È più creativo e intuitivo (non nel senso artistico: proprio nel capire dove l’utente vuole andare a parare con le richieste)
Usa meno emoji
L'aggiornamento è attivo da subito per tutti gli utenti Plus e Team, mentre gli utenti gratuiti dovranno attendere ancora qualche settimana.
Il GPT-4.5 cinese
Il 16 marzo, l’azienda creatrice dell’omonimo motore di ricerca Baidu ha rilasciato il suo nuovo modello Ernie 4.5, dalle performance equiparabili a GPT-4.5, e annunciato l’arrivo di X1, un modello di ragionamento al livello di DeepSeek R1.
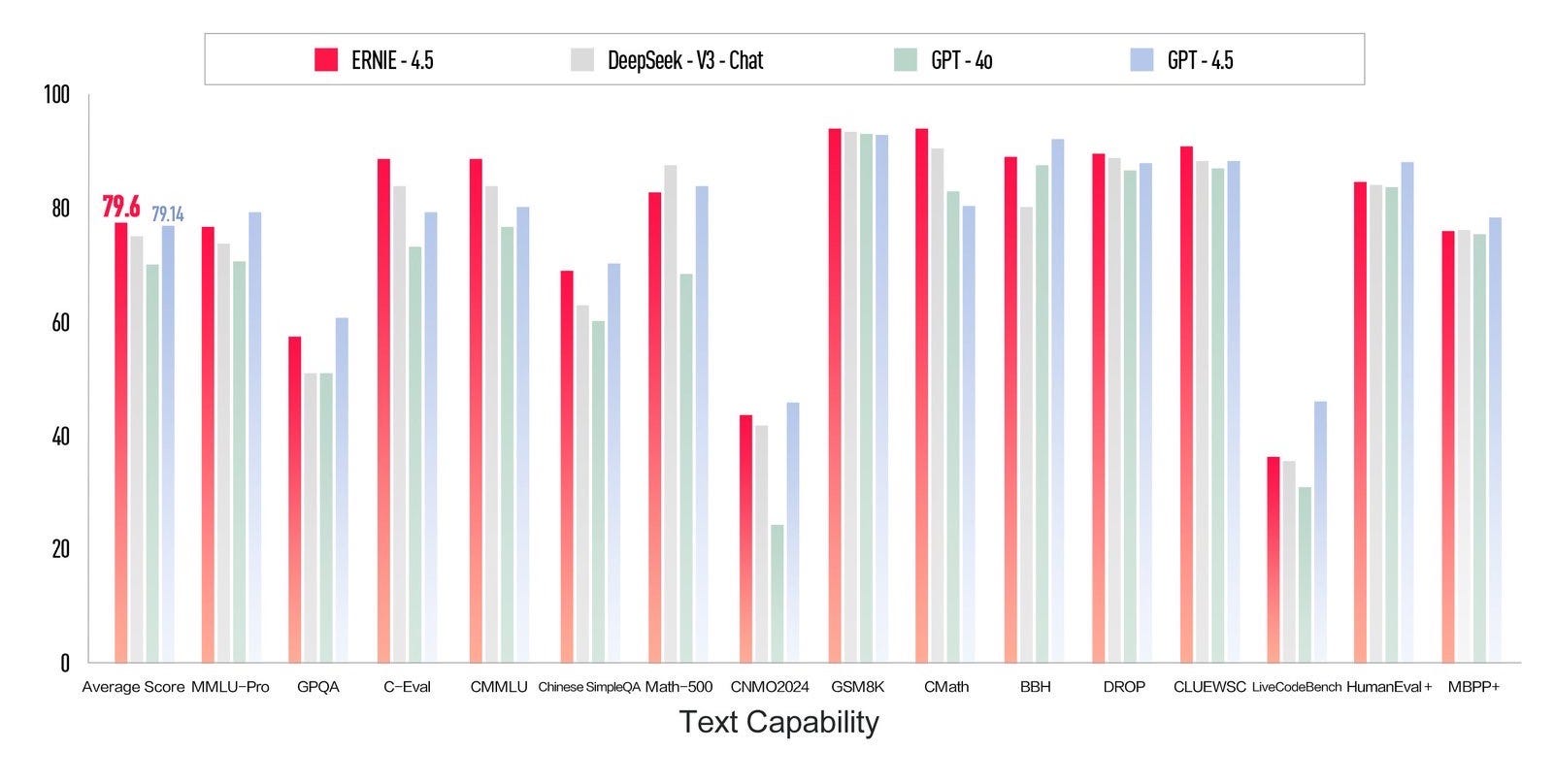
Ernie 4.5 è un modello fondativo nativamente multimodale, che riesce a superare (anche se di poco) le performance di GPT-4.5 in quasi tutti i principali benchmark. La sua multimodalità gli permette di processare in input sia immagini che video e audio.
Il tutto mantenendo un costo d’inferenza che è circa l'1% del modello di OpenAI, ovvero $0.55 per milione di token in input contro $75 e $2.2 in output contro $150. Ernie può essere testato gratuitamente sulla loro piattaforma Yiyan, a patto di avere un numero di telefono cinese con cui registrarsi. Possiamo però aspettarci che l’accesso venga presto facilitato anche agli utenti occidentali, come è stato già fatto anche da aziende come Alibaba e DeepSeek. In ogni caso, è sempre buona pratica mantenere alcuni semplici protocolli di sicurezza quando si utilizzano dei servizi cinesi come questo, tra cui l’uso di una VPN ed evitare di fornire informazioni sensibili al modello.
L’azienda ha anche comunicato che Ernie 4.5 verrà rilasciato open source il 30 giugno.
Insieme al rilascio di Ernie, è stato anche annunciato X1, un modello di ragionamento non ancora ufficialmente disponibile ma che dovrebbe eguagliare le performance di R1 mantenendo la metà del suo costo d’inferenza, ovvero $0.28 per milione di token in input contro $0.55 e $1.1 in output contro $2.2.
Forse l’AGI è più lontana del previsto
Il 24 marzo la Fondazione ARC Prize ha annunciato il lancio del nuovo benchmark ARC-AGI-2 e del concorso ARC Prize 2025, segnando un notevole passo avanti nella misurazione delle capacità dei modelli per stabilire l’arrivo dell’AGI.

L’iniziativa, guidata dalla missione di fungere da "stella polare" per l’innovazione nell’IA, si propone di misurare e stimolare il progresso verso sistemi capaci di apprendere e adattarsi in maniera efficiente.
ARC-AGI-2 rappresenta il successore di ARC-AGI-1, introdotto nel 2019, e si caratterizza per compiti studiati per essere risolvibili con una certa facilità dagli esseri umani – ogni task è stato infatti superato da almeno due persone in meno di due tentativi – mentre le performance dei vari modelli AI, anche i più avanzati, rimangono estremamente basse (ad esempio, o3 e o1 di OpenAI hanno raggiunto dei punteggi inferiori al 5%, mentre nel benchmark precedente o3 arrivava all’87%).
Oltre a verificare la capacità di risolvere problemi, ARC-AGI-2 introduce un nuovo parametro: l’efficienza, ovvero la capacità di raggiungere risultati significativo con un utilizzo ottimale di risorse computazionali. Il benchmark mette in luce sia la competenza nel risolvere problemi, che l’abilità di adattarsi rapidamente e acquisire nuove competenze, elementi fondamentali per definire l’AGI.
Parallelamente al lancio del benchmark, è stato aperto il concorso ARC Prize 2025, che si svolgerà su Kaggle dal 26 marzo al 3 novembre 2025. Con un montepremi complessivo di 1 milione di dollari, la competizione prevede:
Grand Prize di 700.000 dollari: Sbloccabile al raggiungimento di un punteggio pari o superiore all’85% entro i limiti di efficienza definiti.
Premi per il Top Score e per il Paper più innovativo: Riconoscendo i contributi che dimostrano progressi concettuali significativi e soluzioni all’avanguardia.
Il concorso incoraggia la partecipazione di studenti, ricercatori e sviluppatori, invitandoli a proporre soluzioni open-source innovative che possano accelerare la corsa verso un’IA veramente generale.
La balena sta tornando
Sempre il 24 marzo, DeepSeek ha rilasciato una versione aggiornata del suo modello V3, che migliora le prestazioni del precedente su tutti i benchmark.
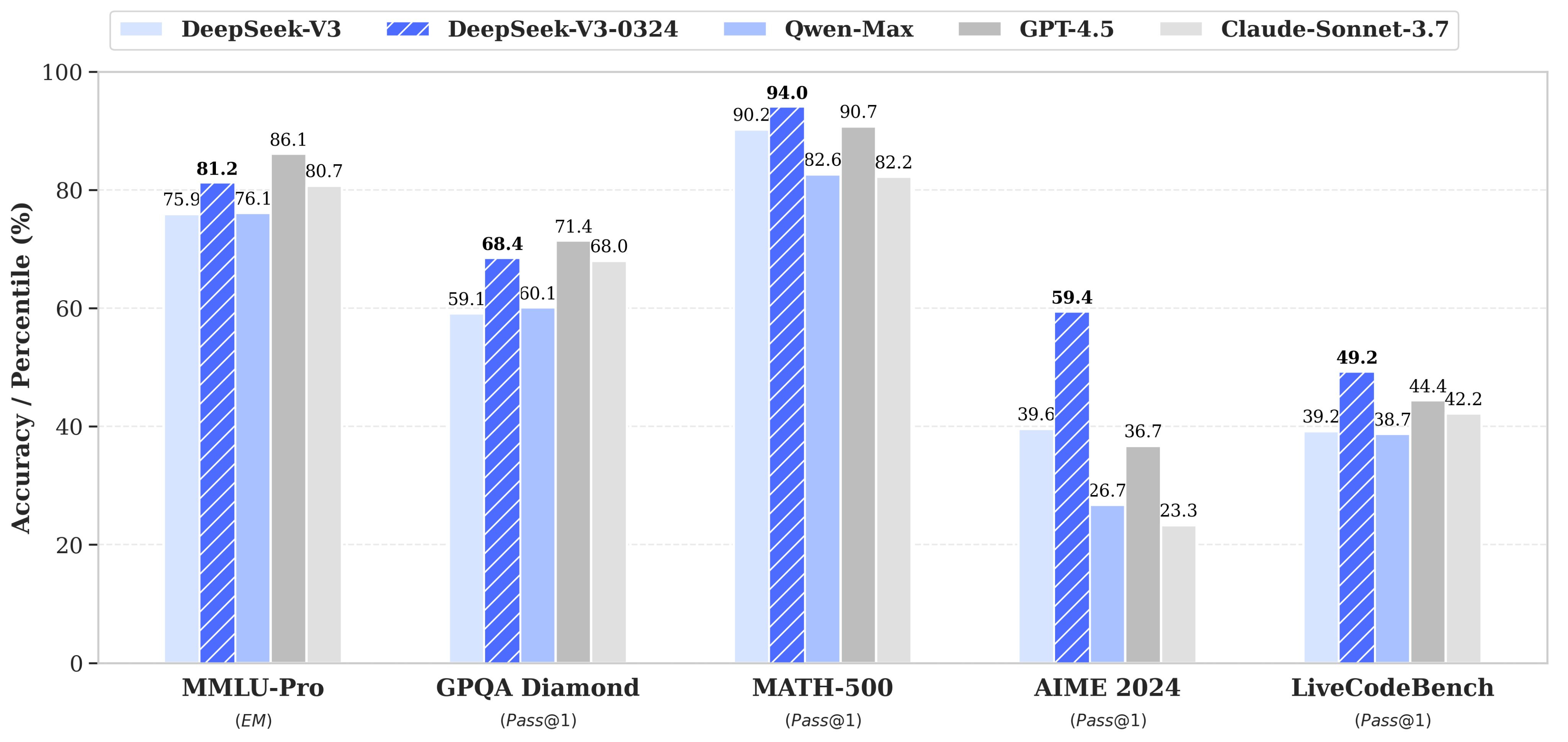
Le migliorie principali sono legate al “ragionamento”, allo sviluppo front-end e all’utilizzo di strumenti per operatività agentiche. Il costo e l’utilizzo tramite API rimane invariato ed è stato rilasciato con licenza MIT come per DeepSeek-R1.
Non penso sia un caso se nello stesso periodo sono iniziate a circolare delle voci sull’imminente arrivo di R2, che sembrerebbe performare un punteggio del 90% nel benchmark ARC-AGI-1 (dove o3 di OpenAI faceva l’87%).
L’edicola dei paper scientifici
Quattro paper di ricerca per il mese di marzo. Solitamente questa rubrica ne contiene tre, ma avendone trovati di molto interessanti nel corso delle ultime settimane non sono riuscito a trattenermi dall’inserirne anche un quarto.

Inference-Time Scaling for Diffusion Models
beyond Scaling Denoising Steps - Un approccio innovativo per migliorare la qualità delle immagini generate dai modelli di diffusione, andando oltre il semplice aumento dei passaggi di denoising. Si è osservato che aumentare il numero di passaggi di denoising durante l’inferenza produce dei benefici che si appiattiscono dopo un certo punto. Il contributo principale di questo lavoro è l’introduzione di un framework “search” che investe ulteriore potenza computazionale per esplorare lo spazio del rumore iniziale, individuando quelli che, grazie a specifici verifiers e algoritmi di ricerca (come la random search, la zero-order search e la search over paths), portano a generazioni di qualità superiore. Sperimentando su benchmark sia class-conditional (ImageNet) che text-conditioned, gli autori dimostrano che allocare risorse computazionali in questo modo permette di ottenere miglioramenti sostanziali nella qualità delle immagini.LADDER: Self-Improving LLMs Through
Recursive Problem Decomposition - Un framework innovativo per il potenziamento autonomo delle capacità di problem solving dei modelli linguistici. Invece di affidarsi a dataset curati o a feedback umani, LADDER sfrutta la capacità intrinseca del modello di generare varianti sempre più semplici di problemi complessi, creando così un gradiente naturale di difficoltà. Queste varianti, verificate numericamente per accertarne la correttezza, fungono da trampolino di lancio per un addestramento basato sul reinforcement learning, che guida il modello verso prestazioni migliori. I risultati sperimentali sono notevoli: un modello Llama 3.2 3B ha migliorato la propria accuratezza su problemi di integrazione a livello universitario dall’1% all’82%, mentre un modello Qwen2.5 7B Deepseek-R1 Distilled ha raggiunto il 73% di accuratezza sul MIT Integration Bee, migliorando ulteriormente al 90% grazie a una tecnica chiamata Test-Time Reinforcement Learning (TTRL). Si è quindi dimostrato che la decomposizione ricorsiva dei problemi, unita a un apprendimento autoguidato, può trasformare radicalmente le capacità di ragionamento dei modelli, aprendo nuove prospettive verso un’intelligenza artificiale più autonoma.Inductive Moment Matching - Un nuovo paradigma per la generazione di immagini che coniuga alta qualità e velocità di inferenza, superando le criticità dei modelli di diffusione tradizionali e delle tecniche di distillazione. Invece di addestrare due reti in una procedura a due fasi, il metodo IMM si basa su una formazione a stadio unico che utilizza l’interpolazione stocastica e il moment matching per guidare la trasformazione della distribuzione del rumore in quella dei dati reali. Questo approccio, che garantisce la convergenza a livello di distribuzione e stabilità in fase di addestramento, permette di generare immagini in uno o pochi passaggi (ad esempio, ottenendo un FID di 1.99 su ImageNet con soli 8 step e di 1.98 su CIFAR-10 in 2 step). In sostanza, IMM accelera il processo di generazione e offre una solida base teorica per nuovi modelli generativi.
One Does Not Simply Meme Alone - Collaborazione tra esseri umani e modelli linguistici di grandi dimensioni nella creazione di meme. Uno studio sperimentale confronta tre modalità di creazione dei meme: la creazione esclusivamente umana, la collaborazione tra umani e IA, e la generazione completamente automatizzata dall’IA. I risultati rivelano che, sebbene il supporto dell’LLM permetta di produrre un maggior numero di idee e riduca lo sforzo percepito durante il processo creativo, questa maggiore produttività non si traduce necessariamente in meme di qualità superiore. I meme generati interamente dall’IA ottengono valutazioni mediamente migliori in termini di creatività, umorismo e shareability, mentre le creazioni totalmente umane si distinguono per un tocco personale e una profondità umoristica che la collaborazione con l’IA non riesce a replicare pienamente.
Il mercatino dell’open-source
Tre progetti open-source con codice per il mese di marzo.

NotaGen - Un innovativo sistema per la generazione di musica simbolica, concepito la creazione di spartiti classici mediante paradigmi di training ispirati ai modelli linguistici di grandi dimensioni. Il progetto si sviluppa attraverso una pipeline articolata in tre fasi: un pre-training su 1,6 milioni di pezzi musicali che fornisce una solida base di conoscenza, un fine-tuning su circa 9.000 composizioni classiche guidato da prompt “period-composer-instrumentation” per affinare lo stile, e un ulteriore step di reinforcement learning tramite il metodo CLaMP-DPO, che ottimizza il modello senza la necessità di annotazioni umane. Con l’introduzione della versione NotaGen-X, sono stati implementati ulteriori miglioramenti – come un post-training intermedio e la rimozione della key augmentation – che garantiscono spartiti musicali più coerenti e fedeli all’estetica classica. La documentazione dettagliata e le demo interattive, disponibili sia in locale tramite Gradio che online tramite Colab, offrono una guida completa per configurare l’ambiente, eseguire il training e sperimentare le potenzialità del sistema.
Owl - Un framework all'avanguardia per la collaborazione multi-agente, concepito per rivoluzionare l’automazione dei compiti nel mondo reale grazie a un’architettura modulare e dinamica che facilita l’interazione sinergica tra agenti AI. Basato sul CAMEL-AI Framework, il sistema integra capacità avanzate come il recupero in tempo reale di informazioni da fonti online, l’elaborazione multimodale di video, immagini e audio, l’automazione del browser e la parsificazione di documenti (il processo di analisi e scomposizione di un documento per estrarne in maniera strutturata le informazioni rilevanti), il tutto abbinato a dei tool per l’esecuzione di codice e operazioni di data analysis. Con un punteggio medio di 58.18 sul benchmark GAIA, che lo posiziona al vertice tra le soluzioni open-source, OWL offre una piattaforma completa e versatile che supporta sia applicazioni sperimentali che scenari di task automation complessi.
DiffRhythm - Un modello open-source di generazione musicale a diffusione latente, capace di creare interi brani in modo rapido e semplice. Sviluppato dal team di ASLP-lab, il progetto offre funzionalità all'avanguardia come i "Text-Based Style Prompts" – che permettono di tradurre descrizioni testuali in stili musicali unici – e una modalità strumentale per la generazione di composizioni pure a partire da scenari immaginari. Il repository contiene guide dettagliate per l'installazione e l'inferenza, con supporto per file audio di riferimento o prompt testuali. DiffRhythm è distribuito con licenza Apache 2.0.
Tutto quello che puoi fare con un modello Multimodale
Esistono alcuni LLM, come Gemini 2.0 Flash Experimental e GPT-4o, che sono in grado di ricevere ed elaborare input diversi dal testo, come immagini, audio (e teoricamente anche video), fornendo degli output che si possono comporre di testo, immagini, testo + immagini, audio e così via. Questi modelli, addestrati con dataset molto più variegati rispetto a classici LLM che potevano elaborare solo testo, vengono più correttamente definiti MLLM (Multimodal Large Language Model).

Negli ultimi anni, i MLLM hanno subito diverse evoluzioni, passando da modelli che potevano ricevere immagini solo in input, rispondendo quindi a domande riguardanti foto, grafici, disegni e tutto ciò che è visivo (visual question answering), a modelli che possono anche generare nuove immagini partendo da input testuali, visivi o entrambi.
Quest’ultimo caso è particolarmente innovativo ed è proprio il focus di questo approfondimento. L’abilità di generare output visivi implica la possibilità di utilizzare il linguaggio naturale, in maniera conversazionale, per delegare la produzione e in alcuni casi la creatività di asset visivi all’intelligenza artificiale, sostituendo in larga misura il lavoro dei grafici professionisti.
E qui i più attenti potrebbero domandarsi: che differenza c’è tra un MLLM e un classico modello di diffusione latente per le immagini come Midjourney?

Ve lo spiego con l’aiuto della vignetta qui sopra, generata con GPT-4o che fa un po’ di fatica ad applicare dei testi in italiano all’interno di immagini complesse: i modelli di diffusione latente utilizzano il nostro input per creare una rappresentazione interna (latente), basata sui dati che hanno appreso durante l’addestramento.
Questa rappresentazione emerge dallo spazio latente sotto forma di rumore, che viene poi reso via via sempre più nitido tramite la tecnica della diffusione (da qui il nome latent diffusion), che si applica contemporaneamente a ogni area del frame fino all’apparizione dell’immagine definitiva.
Quindi i modelli come Midjourney, Stable Diffusion, Flux, Dall-E, ecc. non comprendono realmente la nostra richiesta, si limitano ad associare il prompt alle rappresentazioni latenti che hanno imparato in fase di training.
Al contrario, GPT-4o ha una sorta di comprensione semantica più profonda delle nostre richieste, la stessa che possiamo notare durante le classiche interazioni conversazionali da chatbot. Questa comprensione verbale si traduce in comprensione e rappresentazione visiva nel momento in cui deve rispondere con un’immagine.
Se il testo viene solitamente generato token by token tramite una sorta di calcolo probabilistico, con le immagini i token si trasformano in pixel grazie a un modello autoregressivo che genera il visual pixel per pixel da sinistra a destra partendo dall’alto verso il basso, in modo simile al funzionamento dei sensori delle videocamere.

Nell’immagine qua sopra ho dovuto fare diverse modifiche utilizzando il caro vecchio Photoshop, perché GPT-4o non riusciva a generarla perfetta. Ho quindi unito diversi pezzi buoni di più immagini generate per ottenere questa. Specifico questa cosa per far passare il messaggio che, per quanto straordinario, questo modello è ancora lontano dall’essere perfetto. I designer possono quindi stare tranquilli ancora per qualche mese, ma consiglio quantomeno di apprendere questi nuovi strumenti.
Detto questo, passiamo direttamente ad alcuni casi d’uso per il nuovo GPT-4o. Inizialmente, volevo fare un paragone side-by-side con Gemini 2.0 Flash ma la qualità di quest’ultimo, se paragonata al modello di OpenAI, è obiettivamente troppo bassa per rendere sensata qualunque forma di comparazione.
La cosa curiosa (a proposito dell’accelerazione di cui ho parlato nell’articolo di apertura), è che prima dell’uscita di GPT-4o multimodale, Gemini 2.0 Flash era veramente lo stato dell’arte e per qualche giorno non si è parlato d’altro.
1. Immagini Satiriche

Il nuovo GPT-4o è meno censurato rispetto ad altri modelli e permette di generare immagini realistiche di personaggi famosi, anche politici, in situazioni insolite.
Per quanto si tratti di una questione molto controversa, una riduzione della censura è fondamentale per lasciare che la creatività scorra libera da vincoli morali imposti dall’alto. Ogni utente deve essere considerato come unico responsabile delle immagini che genera e dell’uso che ne farà.
Va anche considerato che tutte le immagini generate da GPT-4o sono dotate di metadati C2PA, che identificano un'immagine come proveniente dall’IA.
Prompt: A candid paparazzi shot of Donald Trump walking briskly through downtown New York City at night, looking over his shoulder with a frightened expression as he tries to avoid being photographed. He is clutching a rare albino monkey that is screaming in terror. His coat is flapping behind him in the wind. The background is blurred with cars and a brightly lit lobby of a luxury hotel to emphasize the movement. The glare of the camera flash partially overexposes the image, giving it a chaotic, tabloid feel
Qualche giorno dopo il suo rilascio, diversi utenti hanno iniziato a segnalare di essere impossibilitati nel produrre altre immagini come questa, ma Sam Altman ha chiarificato che si tratta solo di un problema momentaneo, dovuto probabilmente a una riduzione strategica dell’elevatissimo traffico che stanno avendo in questi giorni.
2. Meme in alta risoluzione

Si possono caricare immagini di meme già esistenti e ricrearli in alta risoluzione, inclusi i testi con il classico font Impact.
Prompt testuale (+ immagine qui sotto):
Crea un meme come questo ma al contrario, dove "Gemini 2.0 Flash" è in pericolo a causa di "GPT-4o". Quindi il primo personaggio davanti avrà la scritta "Gemini 2.0 Flash" mentre il secondo dietro "GPT-4o"

Si possono anche trasporre da uno stile all’altro, trasformando ad esempio un classico meme nello stile dello studio Ghibli, di un fumetto Marvel, di uno sketch di Leonardo da Vinci, in personaggi di plastilina, in personaggi Lego e così via.
3. Personaggi Coerenti

Partendo dalla singola immagine di un personaggio (anche non umano), si può chiedere al modello di mantenerlo coerente in situazioni diverse.
Prompt testuale (+ immagine qui sotto):
Create a grid of 4 images with this exact same character, an anthropomorphized male goat dressed as a farmer, doing 4 different activities on the farm

Questo spalanca le possibilità a infinite idee creative e di storytelling.
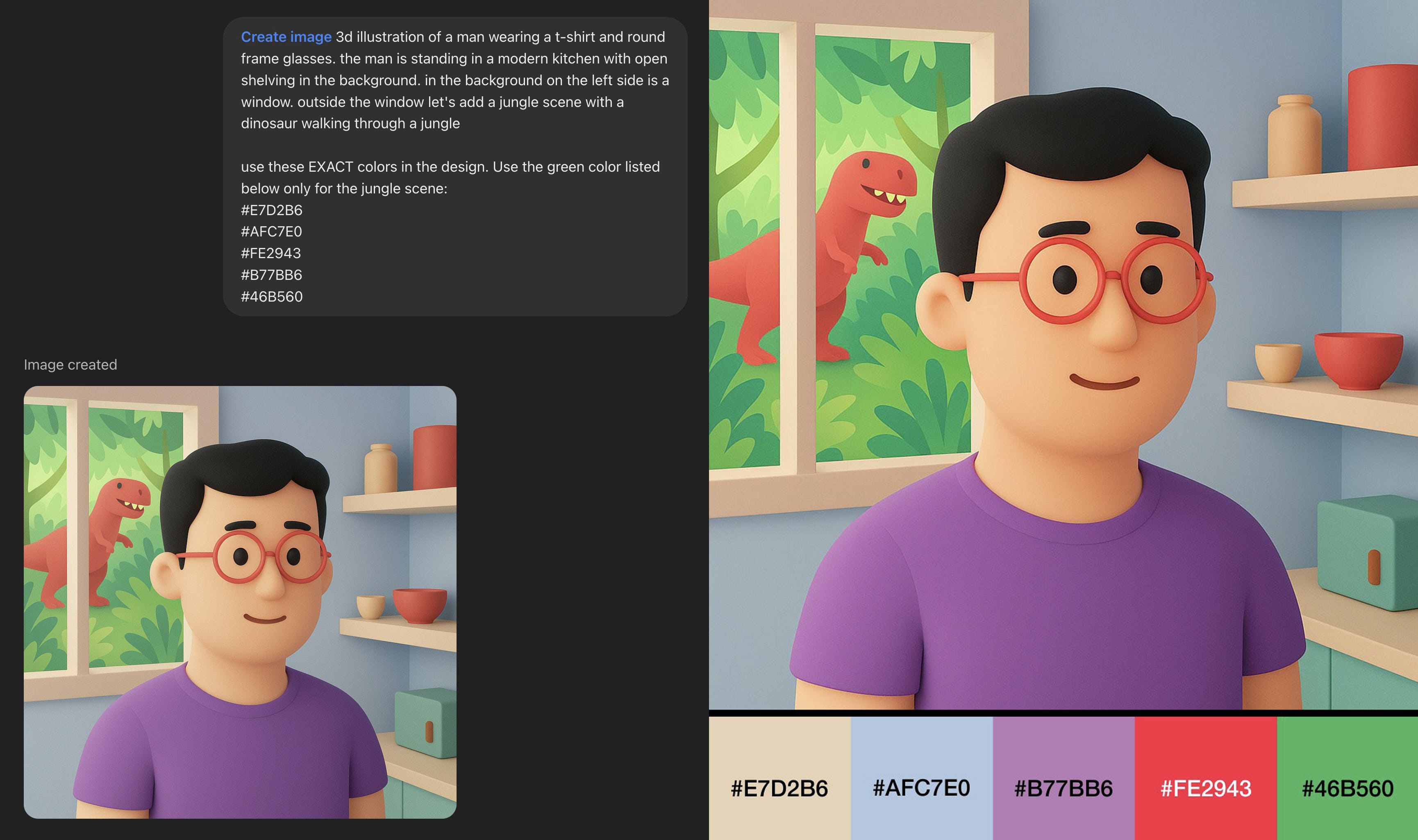
4. Asset Grafici con Codice Colore HEX

GPT-4o riesce anche a comprendere i codici colore HEX e possiamo quindi avere un buon grado di controllo nella scelta dei colori, soprattutto quando si tratta di asset grafici aziendali che hanno determinate linee guida.
Notare che in alcuni casi l’HEX potrebbe essere simile ma non corretto al 100%, come in questo caso, in cui non corrisponde totalmente a quanto indicato nel prompt, ovvero l’arancione di questo magazine.
Prompt: Logo minimale grigio scuro che rappresenti un palazzo monumentale su sfondo arancione con codice colore #f04541
Qui un esempio ancor più complesso preso da Nick St. Pierre su X.
5. Immagini per dei Menù

Possiamo facilmente generare immagini di cibi o bevande coi diagrammi dei loro ingredienti, utili per la creazione di menù. Questo caso d’uso ci può far risparmiare la necessità di produrre uno shooting fotografico professionale + lavorazione grafica.
Prompt: Professionally shot photorealistic diagram of Neapolitan pizza margherita for my restaurant menù with recipe labeled
6. Testi Coerenti nelle Immagini

Se vogliamo avere dei testi coerenti all’interno di un’immagine, possiamo utilizzare le “virgolette” per far capire meglio al modello la nostra intenzione. Notare che più è lungo il testo e maggiore sarà la possibilità di incappare in errori.
Prompt: Un uomo in una protesta in mezzo alla strada che regge un cartello di cartone con su scritto "Sono qui solo per dimostrare che GPT-4o sa fare dei testi coerenti"
Qui sotto vi lascio anche un’altra immagine di esempio che nessun’altro modello per le immagini è mai riuscito a creare finora: l’intero alfabeto.

7. Infografiche per le Presentazioni

Possiamo chiedere a GPT-4o delle infografiche di informazioni complesse senza dover fornire noi le spiegazioni, per il semplice fatto che le conosce già. Così come in una normale interazione di chat, ci fornirebbe una spiegazione delle informazioni richieste, può concettualizzare quella stessa spiegazione in un visual.
Prompt: Crea un'infografica visiva per spiegare i modelli linguistici multimodali (MLLM)
Questa cosa è molto simile a quello che ho fatto all’inizio dell’articolo con le vignette di spiegazione nello stile di Fallout.
8. Tutorial Visivi
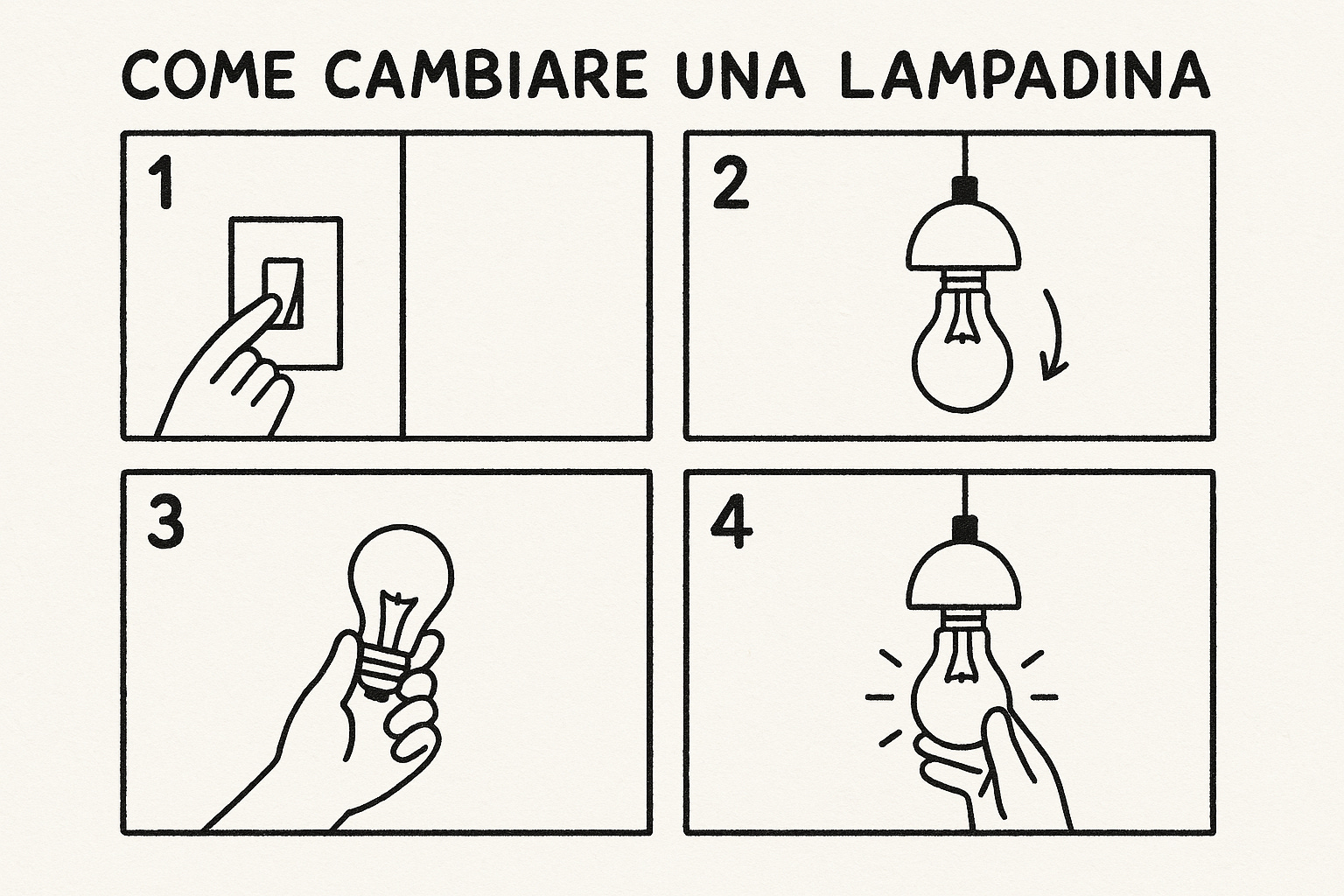
GPT-4o permette anche di generare delle immagini perfette per i manuali di istruzioni. Immaginate l’evoluzione di questa cosa: tra qualche anno è verosimile aspettarsi di poter caricare interi documenti di testo da trasformare in guide illustrate.
Prompt: Crea un semplice diagramma in stile manuale d'istruzioni su come cambiare una lampadina in 4 passaggi
9. Rimuovere gli Sfondi

Possiamo anche manipolare delle immagini già esistenti, ad esempio eliminando lo sfondo o aggiungendo/rimuovendo elementi specifici. Notare che questa funzionalità ha diversi limiti, infatti GPT-4o potrebbe tendere a restituirci un’immagine molto simile ma differente, come in questo caso, in cui ho chiesto di scontornare il banner della rubrica Il mercatino dell’open-source ma il personaggio non è lo stesso.
Nel video presentazione fatto da OpenAI si vede però che loro creano prima l’immagine di una moneta all’interno della chat, per poi chiedere al modello di rimuovere lo sfondo. Il risultato sembra effettivamente inalterato rispetto all’originale, e viene quindi da ipotizzare che questa funzionalità risulti più precisa con le immagini generate dallo stesso GPT-4o
Prompt: Togli lo sfondo da questo soggetto e produci un png trasparente dell'uomo con la giacca rossa
10. Mockup Professionali

Possiamo creare praticamente qualunque tipo di adv professionale, anche di oggetti che abbiamo appena fotografato con lo smartphone (allego esempio subito sotto). Questa funzionalità è forse tra quelle dal potenziale commerciale più alto, perché ci permette di risparmiare migliaia di euro necessari alla produzione di uno shooting professionale in studio.
Prompt: professional adv mockup image of a Coca-cola bottle "tears flavuor"
Funfact: il modello tende a creare il testo giusto anche quando sbagliamo a scriverlo nel prompt, come nel mio caso, in cui ho invertito la o con la u nella parola flavour.
Qui un esempio ancor più complesso preso da Gizem Akdag su X.

11. Grafiche complesse per i social

Possiamo anche generare delle immagini composte da testi e diversi asset grafici, che portano con sé un certo grado di complessità. In questo esempio, ho ricreato una grafica che utilizzavo ogni tanto nella chiusura delle mie slide per LinkedIn, migliorandone l’aspetto complessivo.
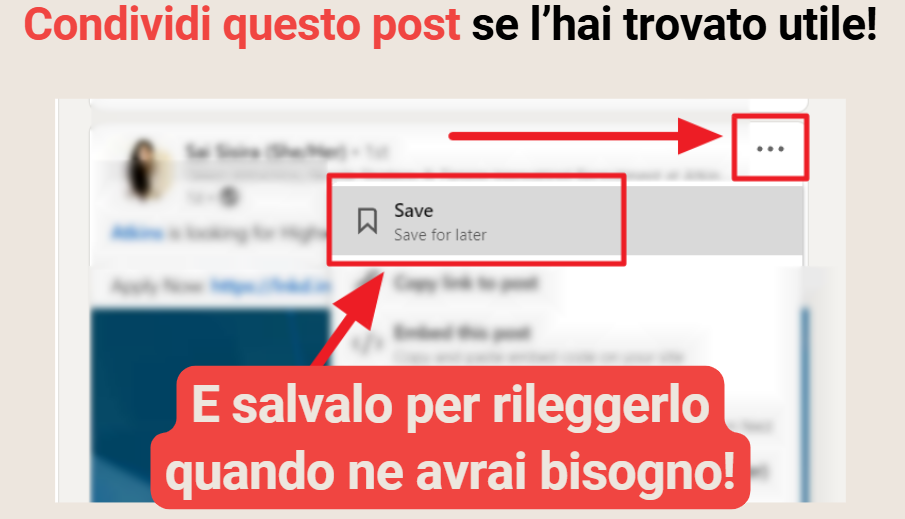
Prompt testuale (+ immagine qui sotto):
Image for LinkedIn showing how to save a post inviting users to share and save the content. At the top is the text "Condividi questo post se l'hai trovato utile", where the writing "Share this post" is in orange with this color code #f04541 - Above the screen showing how to save a post on LinkedIn is the writing "E salvalo per rileggerlo quando ne avrai bisogno!" cream white on an orange background color code #f04541
12. Render architettonici

Possiamo anche prendere un’immagine già esistente/scattare una foto e scrivere manualmente delle annotazioni riguardo alle modifiche da fare. Specificando poi meglio il tutto con un semplice prompt di accompagnamento.
Questo esempio è stato preso da Melis su X, non conosco quindi l’esatto prompt utilizzato ma è facilmente intuibile dal workflow mostrato.
Altre informazioni da sapere:
Prompt più dettagliati portano a risultati migliori. Anche se il modello ha una comprensione semantica complessa, le ambiguità possono portare a risultati indesiderati. È quindi molto importante essere minuziosi nelle spiegazioni, descrivendo anche i minimi dettagli per ottenere risultati ottimali fin da subito ed evitare di dover iterare più
Gli abbonati possono utilizzare GPT-4o anche dentro Sora
Attualmente, gli unici rapporti d’aspetto disponibili sono 1:1, 3:2 e 2:3
La risoluzione è di 1536x1024px
Il vecchio Dall-E 3 rimane disponibile tramite il suo GPT dedicato
PS: avevo promesso anche un articolo di approfondimento su Sora, ma purtroppo non ho fatto in tempo a prepararlo e verrà quindi integrato nella prossima pubblicazione.
L’Alchimista della creatività
Ci sono figure creative che sfuggono alle definizioni, che attraversano mondi apparentemente distanti tra loro senza mai perdere il filo della propria ricerca. Andrea Barbara Romita è una di queste. Designer, curatrice e artista a 360°, il suo lavoro è un continuo esperimento tra estetica, tecnologia e cultura, mosso da una curiosità che la porta a esplorare costantemente senza mai fermarsi.
Il suo alias, dragonemelone, racchiude già un manifesto: la potenza di un drago e l’ironia di un melone, in un equilibrio tra profondità concettuale e leggerezza giocosa. Nella sua visione, la tecnologia non è solo uno strumento, ma un'estensione del pensiero umano, un linguaggio che connette e trasforma. Dalla mixed reality al Web3, dal web design alla glitch art, Andrea indaga l’intersezione tra il fisico e il digitale, tra la funzionalità e l’immaginazione, tra identità e comunità.
In questa intervista, esploreremo il suo approccio al design come atto collettivo, il ruolo del suono nelle sue sperimentazioni artistiche e il suo sguardo critico sul metaverso e l’IA. Scopriremo come l’alchimia della creatività può fondere elementi inaspettati e come il gioco – quello vero, libero e ironico – con una forza essenziale per ripensare il futuro.
Questa intervista si colloca nella più ampia visione del magazine di offrire uno spazio unico ai creativi di tutto il mondo che utilizzano la tecnologia come ampliamento delle loro possibilità espressive. A partire da quest’anno, la rubrica includerà anche interviste a ingegneri, programmatori, matematici e imprenditori, per diversificare i contenuti e promuovere l'idea che la creatività non appartiene solo ad artisti e designer, ma che si tratta di un raffinato processo di problem solving intrinseco alla natura dell’essere umano e alle sue capacità cognitive.

Iniziamo con la domanda di rito del magazine: ci descriveresti il tuo rapporto con la tecnologia?
Il mio rapporto con la tecnologia è quasi ontologico, non la vedo solo come un assemblamento di materiali, ma come un'estensione del pensiero e dell'azione umana. La tecnologia è uno strumento che amplifica le nostre capacità, ci permette di far risuonare le nostre idee, accelerare processi ed espandere i confini della nostra creatività. Oltre alla sua funzione pratica, ha poi anche una dimensione culturale che influenza il nostro modo di relazionarci con il mondo.
Mi affascina come si riesca a creare così spontaneamente legami, connettendo persone, idee e progetti, costruendo community, superando distanze fisiche e concettuali. Ovviamente, ha anche il potere di separare e isolare, per questo il mio approccio è sempre consapevole e critico. Quando utilizzata con rispetto, la tecnologia può arricchire la nostra esperienza del mondo, bilanciando connessione e distanza, superamento e limite.
Il tuo alias, dragonemelone, è un incontro insolito tra elementi opposti: la potenza mitologica del drago e un senso di ironia e giocosità dato dal melone. Cosa ha portato alla nascita di questo nome?
dragonemelone è la mia àncora in un mondo che tende spesso all'iper-serietà e alla costruzione di identità rigide, specialmente nel campo creativo e professionale. Questo nome, apparentemente assurdo, è una forma di resistenza contro l'ossessione di essere sempre impeccabili e sofisticati. Mi ricorda che non tutto deve essere serio o rilevante, e che a volte è possibile semplicemente giocare o scherzare. Ogni volta che qualcuno lo pronuncia, suscita una reazione unica: un sorriso, una smorfia, un punto interrogativo. E questo è il punto: dragonemelone è un invito a non prendersi troppo sul serio e a esplorare l'ironia e l'assurdo. Poi il nome è memorabile e quindi inaspettatamente funzionale per il mio lavoro.
Per quanto riguarda la storia vera dietro il nome, preferisco mantenerla avvolta nel mistero, perché in fondo non tutto deve avere necessariamente una spiegazione, no?
Visitando il tuo sito web si può rimanere sorpresi dalla tua capacità di coniugare ambiti creativi anche molto diversi tra loro: design, arte, curatela, direzione creativa e scrittura sono solo alcune delle tante cose che fai. C'è un filo conduttore che ti aiuta a conciliare tutto questo?
Il filo conduttore che lega tutto ciò che faccio è la curiosità, una forza che mi spinge a esplorare e a mettermi in discussione. Mi distacco dalla linearità e dalla rigidità della coerenza, perché credo che la sperimentazione possa avvenire senza dover sempre concludere o cristallizzare un percorso. Questo approccio mi ha permesso di muovermi tra discipline diverse, creando connessioni inaspettate tra design, arte, curatela e scrittura. Non vedo questi ambiti come separati, ma come un ecosistema in evoluzione, dove ogni esperienza arricchisce le altre. Per me, la chiave è abbracciare il dinamismo delle esperienze, senza cercare di forzare una perfezione predefinita, ma piuttosto godendo delle sfumature che emergono lungo il cammino.
Nell'ambito del design ti definisci una sorta di alchimista moderno, trasformando il quotidiano in qualcosa di fantastico. Quando ti trovi a lavorare su un nuovo progetto, ci sono degli elementi che non possono mai mancare nel tuo “laboratorio”?
Nel mio “laboratorio” di design, l’ascolto è l’elemento fondamentale. Ogni progetto parte dal dialogo, dall’osservazione e dalla comprensione dei bisogni di chi ne usufruirà. Il design è un processo collettivo, che nasce e si sviluppa insieme agli altri, come ci insegnava Victor Papanek nel suo libro Progettare per il mondo reale, una lettura che consiglio a chiunque sia interessato all’Ethical Design, una disciplina per una progettazione consapevole e responsabile.
Tuttavia, oltre all’ascolto, la fantasia è un altro ingrediente essenziale. Purtroppo, nel design moderno, spesso dominato da algoritmi e logiche di mercato, si dà poco spazio all’immaginazione. Per me, la fantasia è una risorsa preziosa: una forza liberatoria che permette di rompere gli schemi e creare qualcosa di nuovo e inaspettato. Per questo motivo - e altri - mi considero un’alchimista perché vedo nel design il potere di trasformare idee grezze in qualcosa di unico, unendo elementi diversi per creare qualcosa di meraviglioso, che prima non c’era. Credo che oggi il mondo del design abbia un bisogno urgente di questa capacità di visione, di immaginare oltre l’ovvio, di liberarsi da meccanismi che ingabbiano la creatività e di riscoprire, invece, il piacere autentico della trasformazione.
Mixed reality, VR, metaversi ed esperienze immersive. Potremmo dire che si tratta di un unico grande settore che ci permette di riflettere sul rapporto tra il mondo fisico e quello digitale, tra il reale e il virtuale. Ci racconteresti la tua visione a riguardo?
La mia visione del metaverso è orientata a un uso sociale e comunitario, dove questi spazi possano diventare nuove piazze digitali in cui l’interazione e la condivisione non siano vincolate alla fisicità, ma possano svilupparsi attraverso nuove forme di connessione. Non si tratta solo di replicare il mondo reale, ma di esplorare linguaggi e possibilità inedite che mettano al centro l’umano. Tuttavia, oggi la direzione delle grandi aziende tecnologiche va verso l'isolamento piuttosto che verso l'inclusività.
In un articolo per Osservatorio Futura, ho scritto della necessità di riappropriarci degli spazi virtuali, sottraendoli da modelli centralizzati e trasformandoli in ambienti più aperti, accessibili e orientati ai bisogni reali delle persone. Credo che oggi non abbia più senso distinguere tra reale e virtuale, poiché le due dimensioni sono sempre più intrecciate, con il virtuale che ha un impatto crescente sulla nostra realtà, le relazioni e la costruzione della conoscenza.
Nel tuo approccio al design sottolinei l’importanza di dare spazio all’identità dei clienti, piuttosto che lasciare un’impronta personale troppo marcata. È un concetto interessante e, in un certo senso, opposto all’idea dell’artista come autore. Come trovi l’equilibrio tra espressione personale e servizio al cliente?
Fare design significa progettare in relazione agli altri e con gli altri, non solo esprimere sé stessi. La differenza tra designer e artista sta nel fatto che l’artista mette al centro la propria visione, mentre il designer costruisce strumenti e linguaggi per una pluralità di persone. Sebbene oggi i ruoli tendano a sovrapporsi, per me il design è un atto collettivo, con la co-progettazione come cuore del mio approccio. Non si tratta solo di interpretare l’identità di un cliente, ma di creare insieme un ecosistema visivo che gli permetta di esprimersi al meglio. Il design non è mai un processo isolato, ma un dialogo continuo che valorizza il contesto, le necessità e le esperienze altrui. Per me, la vera sfida sta nell’allineare la visione creativa alle esigenze pratiche, mantenendo sempre un forte senso di responsabilità verso l’ambiente e la comunità.
L’equilibrio tra espressione personale e servizio al cliente, quindi, è un metodo che implica soluzioni che rispondano a necessità e contesto, dove ogni elemento trova il suo posto in modo armonico e funzionale.
Cosa ne pensi dell'intelligenza artificiale come strumento per la creatività?
L'intelligenza artificiale la vedo principalmente come uno strumento che, se utilizzato nel modo giusto, può potenziare il nostro lavoro e la nostra creatività. Non mi preoccupa tanto la tecnologia in sé, quanto il modo in cui potrebbe essere utilizzata. Ho trattato questi temi in alcuni articoli su The Daily Melon, come in Where’s the AI that actually does the crap that humans don’t wanna do? e Risk, but the players have 3 and a half fingers instead of 5. In generale, il confronto sull’AI con artisti mi ha dato una visione più ampia di come l'AI possa essere un mezzo espressivo. Mi fa riflettere che i timori verso l'AI ricordano quelli provati alla nascita della fotografia, come una reazione quasi negazionista.
Oltre a questi timori, spesso la critica riguarda i diritti e il copyright delle immagini, come se il nostro cervello fosse un modulo che produce idee originali dal nulla. Questo approccio richiama la visione platonica, ma oggi sappiamo che le idee sono frutto di stimoli e combinazioni di concetti. La vera domanda per me è: dove si differenziano, concettualmente, la nostra mente e quella di un'AI? Sebbene siano ovviamente diversi, nel processo creativo le somiglianze non sono così distanti. Certo, si potrebbe parlare a lungo di prompt e linguaggio, ma ritengo che l'AI sia un valido strumento di espressione artistica.
In privato mi avevi raccontato di avere un rapporto particolare con il suono e con l'utilizzo dell'audio nel design e nell’arte. Ti andrebbe di raccontarcelo?
Il suono per me è quasi un’ossessione. Anni fa, in un momento di solitudine, mi sono fatta una domanda che mi ha segnato: "Come faccio a sapere che il tic del forno è proprio il tic del forno pur non avendocelo davanti?". Da lì incredibilmente è nata la mia tesi magistrale, Ubik, dove ho esplorato la cultura del suono di sistema, ovvero quei suoni associati a macchine o interfacce che segnano le nostre interazioni uditive.
Da quel momento, la mia ricerca sul suono non si è mai fermata, portandomi a esplorare temi come la gerarchizzazione sonora e gli habitat naturali, fragili custodi di equilibri sonori.
Oggi, il suono è anche una tecnica artistica per me, un mezzo per stimolare il rapporto tra immagine e suono, spesso tramite la tecnica del databending, una forma di glitch art che manipola file aprendo e rielaborando dati in programmi non progettati per supportarli. Un altro esperimento interessante che sto portando avanti è l’uso del suono come trasportatore di immagini attraverso onde radio.
Se qualcuno è curioso di esplorare di più, può seguire il mio profilo Soundcloud.
Hai una vasta esperienza anche nell'ambito del cosiddetto Web3, un settore molto vasto e variegato, spesso frainteso e associato solo alle cryptovalute, che rappresentano però la punta dell'iceberg. Quali pensi che siano le principali sfide e opportunità per le aziende e i creativi che vogliono passare a questa nuova frontiera di internet?
Il Web3 è un territorio che trovo estremamente affascinante per la sua capacità di ridefinire le logiche di interazione, creazione e collaborazione. Ciò che lo rende unico e più equo non è solo la decentralizzazione, che permette di pensare fuori dagli schemi e sfidare le grandi multinazionali e i centri di potere, ma anche la possibilità di creare uno spazio proprio, sostenuto da una comunità attiva e in crescita. Un aspetto che ho vissuto personalmente con il progetto Cryptogirl, una community femminista digitale che mirava a rendere l’ambiente web3 più inclusivo, sostenibile e paritario. L’esperienza di co-creare questa realtà mi ha permesso di comprendere quanto la vera forza di questo ecosistema stia nel suo spirito di collaborazione e apertura mentale.
Nel mio percorso da artista, curatrice e divulgatrice in solitaria, credo che uno degli aspetti più interessanti del Web3 sia proprio la possibilità di costruire legami più autentici e proficui, lontani dai soliti circuiti chiusi, mettendo in connessione individui e idee, favorendo una cultura condivisa che va oltre il profitto e punta invece alla crescita collettiva. La sfida per le aziende e i creativi, quindi, non è solo quella di adattarsi a un nuovo paradigma tecnologico, ma di comprendere come utilizzare le opportunità del Web3 per costruire realtà più inclusive e collaborative, in cui il valore non si misura solo in termini economici, ma anche in impatto sociale e culturale.
Domanda difficile: come potrebbe essere dragonemelone tra 10 anni? C’è una direzione specifica nella quale vorresti andare o un qualcosa a cui vorresti lavorare?
Tra dieci anni, chi può davvero dire cosa ci riserva il futuro, considerando quanto tutto cambi in fretta?
Se dovessi provare a immaginare, però, mi piacerebbe che dragonemelone evolvesse in qualcosa di inaspettato, magari proprio per distaccarmi da quello che potrei pianificare ora. Anche e soprattutto perché ignoro persino io cosa mi passi per la testa, potrei anche decidere di trovarmi su una spiaggia deserta a preparare panzerotti baresi in completa tranquillità, chi lo sa.
A parte gli scherzi, il mio desiderio è continuare a fare ciò che faccio ora, ma con più risorse, energie e soprattutto una rete di persone che si supportano vicendevolmente. Più di tutto, affrontare nuove sfide con un atteggiamento più leggero, in modo che ogni passo abbia il gusto e la visione di una bella scoperta.
L’angolo degli annunci
Per ora gli annunci rimangono sempre gli stessi delle pubblicazioni precedenti, ma vi assicuro che stiamo lavorando al business plan dell’azienda che gestirà il magazine, al sito web e a tante altre cose. Nel frattempo, l’annuncio qui sotto rimane sempre valido!

Per il 2025 voglio tentare di trasformare questo magazine in una vera e propria Startup innovativa, collocata all’intersezione tra il mondo dei media e della tecnologia. Per farlo, le mie sole forze non bastano e cerco qualcuno con cui espandere il team di lavoro, così da poter creare più contenuti e portare gli approfondimenti di Tales from the Latent Space anche su Instagram per ampliare la portata del progetto. Cerco quindi una collaborazione a medio-lungo termine per gestire la pagina del magazine e creare più contenuti. Si offre una quota in quella che sarà la futura azienda legata al magazine (con un contratto) e formazione di alto livello sui principali strumenti AI, in cambio di una ragionevole quantità di tempo da concordare. Se l'idea ti intriga o conosci qualcuno con la giusta ambizione e competenza che possa abbracciare questa missione, contattami su LinkedIn.
Prossimamente, condividerò anche il business plan della startup, che si chiamerà Monumenta AI e non sarà legata solo ai media, insieme a un manifesto d’intenti che racconti la visione complessiva del progetto.