


Abituarsi al Nuovo Mondo
La capacità di adattamento dell'essere umano è tale da permettergli di abituarsi anche alla mutevole frenesia del nuovo mondo


L’ultimo quadrimestre del 2024 è iniziato, e sono convinto che ne vedremo delle belle.
Inizio col dire che la lunghezza di questo magazine è aumentata significativamente nel corso di questi primi mesi di pubblicazione. Siamo passati da un tempo di lettura di 15 minuti per il primo numero, ai 21 del secondo, fino ai 33 del terzo! In maniera completamente coerente con l’idea di fare un magazine al posto di una semplice e banale newsletter come tutte le altre.
Voglio poi ringraziare e dare il benvenuto ai nuovi arrivati, che questo mese sono stati più di 70 e hanno contribuito a superare abbondantemente il traguardo dei 100 iscritti! Voi siete i veri Pionieri del Nuovo Mondo e questo è Tales from the Latent Space, il primo e unico magazine a parlare del rapporto tra creatività e tecnologia.
Si tratta di un progetto anomalo per il panorama italiano, che farà parlare di sé molto presto. Qui abbiamo diverse rubriche, alcune delle quali possono comparire e scomparire a sorpresa, dalle spiegazioni semplificate di concetti complessi, alle news, passando per approfondimenti tematici, paper scientifici selezionati, risorse open-source, interviste esclusive e molto altro ancora!
In ogni numero, ci addentreremo nel Nuovo Mondo prendendo un treno metaforico, quindi dirigiamoci al binario e partiamo. Ci attende un viaggio senza precedenti!

Cosa rende intelligente l’IA?
Un modello linguistico di grandi dimensioni (LLM), come i vari GPT, Claude e Gemini che vengono ormai utilizzati quotidianamente dalla maggior parte delle persone, viene considerato "intelligente" per una serie di motivi legati alla sua capacità di elaborare, comprendere e generare linguaggio naturale in modo simile a come lo farebbe un essere umano.
A seguito di diversi esperimenti avvenuti tra il 2017 e il 2018, si è capito che esistono delle “leggi” che garantiscono l’aumentare delle capacità cognitive di un LLM.
Queste leggi si basano su tre variabili:
Dimensione del dataset
Tempo di addestramento
Numero di parametri nella rete neurale
All’aumentare di queste variabili, i modelli hanno dimostrato dei significativi miglioramenti nelle loro capacità, mentre l’architettura o altri elementi come la larghezza o la profondità della rete neurale non hanno una particolare influenza. Questo concetto è alla base delle cosiddette Scaling Laws.
Ora cerchiamo di capire cosa comporta ogni variabile.
Dimensione del Dataset
Immaginate di dover scrivere un libro su un determinato argomento: più informazioni abbiamo a disposizione, più dettagliato potrà essere il lavoro finale. Allo stesso modo, un LLM apprende dai dati forniti durante l'addestramento, che sono solitamente testo, ma anche immagini e audio nel caso dei modelli multimodali.
Un vasto dataset permette a un modello di:
Comprendere vari contesti
Trovare relazioni complesse tra concetti
Arricchire le sue capacità lessicali
Catturare sfumature linguistiche
Fornire risposte più articolate e diversificate
Tempo di Addestramento
La fase di addestramento di un LLM è un processo che richiede molto tempo e risorse computazionali. Questo perché il modello ha bisogno di elaborare l’enorme dataset che gli è stato fornito, che può pesare centinaia di terabyte. Più a lungo il modello viene addestrato, maggiore sarà la sua capacità di apprendere e generalizzare informazioni. Un tempo di addestramento prolungato consente al modello di:
Ridurre progressivamente gli errori e migliorare l'accuratezza delle risposte
Comprendere concetti sottili, astratti o altamente complessi
Consolidare la conoscenza attraverso un’esposizione ripetuta a esempi diversi, rendendo le risposte più affidabili e coerenti
La relazione tra tempo di addestramento e potenza di calcolo è fondamentale: un aumento della capacità di computazione può ridurre il tempo necessario a raggiungere un certo livello di prestazioni, mentre una quantità limitata di risorse richiede tempi di addestramento più lunghi.
Esiste un punto di diminishing returns (rendimento decrescente), dove prolungare ulteriormente l'addestramento non porta più significativi miglioramenti nelle prestazioni del modello. Il segreto per un addestramento efficiente sta nel bilanciare il tempo, la potenza di calcolo e la dimensione del modello per ottenere il massimo delle prestazioni con le risorse a disposizione.
Numero di Parametri nella Rete Neurale
I parametri possono essere paragonati alle connessioni sinaptiche del cervello umano, e rappresentano i pesi associati alle connessioni tra i neuroni artificiali nei diversi strati della rete neurale. Sono il meccanismo con cui il modello apprende, memorizza e relaziona le informazioni. Un maggior numero di parametri consente all’IA di:
Rappresentare concetti complessi: con più parametri, il modello può gestire idee astratte e relazioni intricate tra i dati, riuscendo a catturare sfumature che modelli più piccoli non sarebbero in grado di cogliere. Questo gli permette di affrontare compiti che richiedono una profonda comprensione semantica.
Migliorare la capacità di generalizzare: un modello con più parametri può applicare in modo più efficace le conoscenze apprese a nuovi contesti o dati che non ha mai visto durante l'addestramento. Questo significa che un modello non si limita a memorizzare i dati di addestramento, ma che può anche inferire e ragionare su informazioni nuove, rendendolo molto più versatile.
Aumentare la precisione: Con una rete neurale più ricca di parametri, il modello diventa in grado di fornire risposte più accurate, pertinenti e dettagliate. Può rispondere con maggior precisione a richieste complesse e cogliere meglio le sottigliezze linguistiche e le ambiguità tipiche del linguaggio umano.
Esistono però alcuni limiti. Un numero eccessivo di parametri rispetto ai dati disponibili può portare a fenomeni di overfitting, in cui il modello diventa troppo specializzato nei dati di addestramento e perde la capacità di generalizzare correttamente su nuovi input. Per questo è importante trovare un equilibrio tra la dimensione del modello, la quantità di dati e il tempo di addestramento per ottenere il massimo rendimento dalle risorse a disposizione.
In sostanza, l'IA che utilizziamo quotidianamente è resa intelligente dalla combinazione di tre fattori chiave: la quantità di parametri, la qualità e grandezza del set di dati, e il tempo di addestramento. Questi elementi sono ciò che trasforma un complesso modello statistico in un sistema capace di rispondere con accuratezza, adattarsi a nuove informazioni e risolvere problemi, rendendo l'Intelligenza Artificiale effettivamente "intelligente".
Avvenimenti del mese
Le notizie più interessanti e creative dal mondo della tecnologia, accuratamente selezionate per districarsi tra il rumore informativo.

Altri robot umanoidi all’orizzonte
Il 30 agosto, l’azienda 1X ha annunciato NEO Beta, il suo nuovo robot umanoide dal design che ricorda molto Optimus di Tesla e Figure 02.

NEO è il successore di EVE, un umanoide su ruote pensato per svolgere compiti semplici come le pulizie in uffici e ambienti domestici. Sul sito dell'azienda, possiamo leggere che NEO ha un'altezza di 165cm, pesa 30 chili, può camminare a 4 Km/h e correre a 12 Km/h. In oltre può trasportare carichi fino a 20 Kg e la sua batteria ha una durata di 2-4 ore, che dipenderà certamente dagli sforzi a cui saranno sottoposti i suoi motori e dalla complessità dei compiti da svolgere.
E proprio come tutti i moderni umanoidi, è dotato di IA per comprendere sia il linguaggio naturale che l'ambiente circostante. L’azienda dice anche che migliorerà costantemente nel tempo, man mano che imparerà a eseguire i compiti che gli vengono richiesti, in maniera non dissimile da come fanno gli umani.
Ritengo molto interessante vedere come il mercato dei robot umanoidi si stia rapidamente espandendo di mese in mese. Solo nel 2024, abbiamo visto annunci di nuovi umanoidi da Tesla, Figure, Boston Dynamics, Agility Robotics e Astribot.
Video AI più lunghi
Sempre il 30 agosto, Runway ha introdotto la possibilità di estendere la durata dei video generati con Gen-3 Alpha fino a 40 secondi.

Per farlo, basterà generare una clip per poi veder comparire il tasto “extend video”, che è disponibile anche su tutti i video generati prima dell’introduzione di questa nuova funzionalità. A quel punto, potremo inserire un altro prompt e scegliere se estendere la clip di 5 o 10 secondi, fino a un limite massimo di 40 secondi in totale.
Poco dopo, il 14 settembre, è stata rilasciata anche la funzionalità Video2Video, che permette di trasformare dei video esistenti in nuove clip tramite un prompt testuale. Mentre il 20 settembre, arriva la possibilità di creare video verticali con Gen-3 Alpha Turbo, anche in modalità Video2Video.
La Cina si avvicina
Il 1° settembre, sui social si inizia a parlare di MiniMax, un nuovo modello per la generazione di video creato dall’azienda cinese HailuoAI, della quale non si sa praticamente nulla. In rete si trova solo un sito web in cinese che non ci offre particolari informazioni riguardo a questa azienda o al suo nuovo modello.
Il motivo per cui se ne parla è però un altro: MiniMax riesce a generare dei video davvero incredibili, assolutamente paragonabili a Sora, ed è gratis!

In un primo momento, per provare questo strumento era necessario registrarsi con WeChat o con un numero di telefono, cosa che non mi sentivo proprio di fare perché non ritengo particolarmente saggio fornire i propri dati a un’azienda cinese che appare improvvisamente da un giorno all’altro.
Le cose però son cambiate, infatti adesso si può testare gratuitamente senza la necessità di registrarsi. Consiglio comunque di utilizzare una VPN per proteggersi, perché siti come questo possono tracciare le nostre attività online.
I movimenti di camera al tempo dell’IA
Il 3 settembre, Luma Labs annuncia un nuovo aggiornamento per il suo video model Dream Machine. A meno di un mese di distanza dall’arrivo di DM 1.5, Luma passa alla versione 1.6, introducendo anche i “camera motion”.
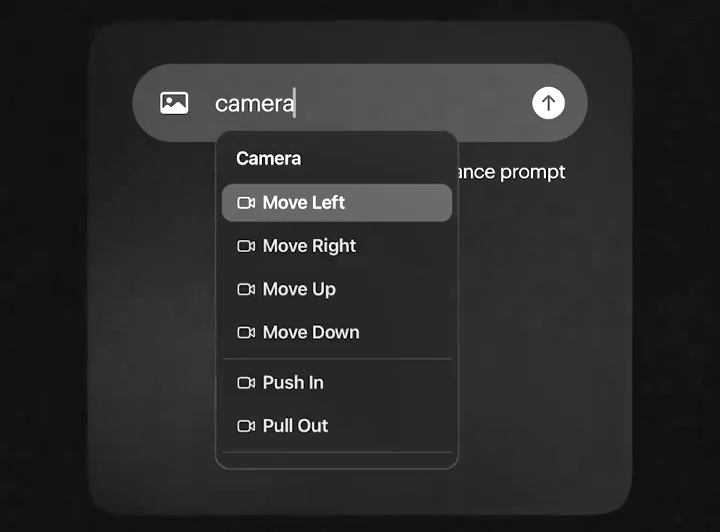
Come suggerisce il nome, “camera motion” ci aiuta ad avere un maggior controllo con i movimenti della nostra cinepresa immaginaria. Questa funzionalità è stata creata in modo da risultare super-intuitiva, basta scrivere "camera" nel prompt per veder comparire un menù a tendina con tutti i movimenti supportati dal modello.
Ma possiamo anche scrivere "move", "push" o "orbit" per visualizzare tutti i suggerimenti relativi a quel tipo movimento. Questa quindi, più che una vera e propria feature di controllo, è praticamente una standardizzazione dei prompt per richiamare nel modello un determinato movimento piuttosto che un altro.
Insomma, un piccolo passo per il mondo AI, ma un grade balzo per le prossime generazioni di registi e creativi del mondo video.
La prima civiltà creata dall’intelligenza artificiale
Sempre il 3 settembre, Robert Yang, il CEO della startup Altera, rivela al mondo i risultati di Project Sid, un progetto di ricerca nel quale mille agenti AI autonomi hanno creato una vera e propria forma di civiltà all’interno del mondo di Minecraft.

Gli agenti autonomi, nel corso di diversi giorni hanno dimostrato di poter collaborare a lungo termine, raccogliendo fino al 32% di tutte le risorse della mappa di Minecraft. Il progetto evidenzia il potenziale dei sistemi multi-agente per affrontare problemi complessi come la collaborazione continuativa sul lungo periodo.
Più avanti nel magazine, troverete un articolo di approfondimento su questo progetto.
Anime personalizzati
Il 6 settembre, Midjourney ha introdotto la possibilità di personalizzare il suo modello Niji, con la stessa modalità con cui si personalizza il modello standard.

Più avanti nel magazine troverete un articolo di approfondimento sulla Niji mode con tanti consigli utili per sfruttarla al meglio nel vostro lavoro creativo.
Cose che ti fanno cambiare espressione
Il 7 settembre, il ricercatore e imprenditore Alex Carlier pubblica Reshot AI, un software innovativo che permette di modificare le espressioni facciali di un volto in un’immagine tramite degli appositi cursori.

Si tratta di una prima versione ancora embrionale, che purtroppo non offre test gratuiti. Nella homepage si parla già di nuove funzionalità in arrivo, come la possibilità di cambiare illuminazione e sfondo (come fa Relight su Magnific).
OpenAI sgancia la bomba
Il 12 settembre, OpenAI ha annunciato una nuova famiglia di modelli AI, che però funzionano in maniera un po' diversa dal solito...

Infatti questi nuovi modelli, detti o1, sono stati addestrati con reinforcement learning su larga scala per ragionare in maniera più umana, "pensando" prima di rispondere.
Per intenderci, questo "ragionamento" è un processo che si poteva già fare con diverse tecniche, tra cui: Prompt avanzati con formattazione in pseudocodice, catene di pensieri (CoT), logiche custom per creare agenti complessi.
La principale differenza con questi metodi che ho elencato, è che o1 fa tutto questo by design. Secondo i test di OpenAI, o1 ha raggiunto dei risultati simili a quelli degli studenti di dottorato in fisica, chimica e biologia. Ha risolto l'83% dei problemi in una prova qualificante per le Olimpiadi Internazionali di matematica, mentre GPT-4o faceva solo il 13%.
Più avanti nel magazine troverete un articolo di approfondimento sui modelli o1.
Cameron si unisce al lato oscuro della forza
Il 24 settembre, Stability AI ha annunciato che James Cameron, il leggendario regista di Terminator, Aliens, Titanic e Avatar, particolarmente noto per il suo approccio tecnologico al mondo del cinema, si é unito al consiglio di amministrazione dell’azienda creatrice di Stable Diffusion.

La decisione arriva circa un anno dopo la fine dello sciopero SAG-AFTRA, che aveva sollevato preoccupazioni sull'impatto dell'IA sui posti di lavoro a Hollywood.
Cameron ha spiegato che la sua scelta è legata alla fiducia e al rispetto che nutre nei confronti di Prem Akkaraju e Sean Parker, due figure chiave di Stability AI, con cui collabora da anni. Entrambi sono anche co-proprietari di WETA Effects, l’azienda di effetti visivi con cui Cameron lavora frequentemente per i suoi film. Cameron ha parlato della possibilità di creare una piattaforma comune che possa unire due mondi che oggi sono ancora separati: da una parte il settore tecnologico e dall’altra i flussi di lavoro legati agli effetti visivi nei film e nelle serie TV.
Mentre la CGI ha raggiunto un livello di maturità molto avanzato grazie a decenni di evoluzione, l’IA generativa opera in un modo completamente diverso e il regista crede che ci sia un enorme potenziale in questa fusione. Akkaraju ha spiegato che il futuro di Stability AI si concentrerà su due aree principali: da un lato, il settore enterprise, con numerose aziende che già pagano per utilizzare i loro modelli, e dall’altro lo sviluppo di applicazioni che possano rivoluzionare il mondo del cinema.
Questa partnership è un chiaro segnale del fatto che Hollywood si sta lentamente "arrendendo" all'inevitabile trasformazione del suo settore principale.
Il futuro secondo Mark Zuckerberg
Il 25 e 26 settembre si è tenuto Meta Connect, l’evento annuale di Meta in cui vengono annunciate le novità più interessanti da parte dell’azienda. Sono state svelate numerose novità tecnologiche che stanno già facendo parlare il mondo.
Di seguito trovate gli annunci che più hanno catturato la mia attenzione.

Meta Quest 3: una nuova versione del visore Quest 3, con un prezzo ridotto a $300, rispetto ai 500 del modello precedente. La nuova versione introduce una funzionalità simile all'Apple Vision Pro, con la possibilità di creare un desktop virtuale a 360°, permettendo di posizionare app attorno all'utente per un'esperienza di multitasking immersiva. Anche l'audio è stato migliorato con l’integrazione del Dolby Atmos.
Llama 3.2: un nuovo modello multimodale open-weight disponibile in versioni da 90 e 11 miliardi di parametri, o più leggere di solo testo da 1 e 3 miliardi di parametri, che si adattano perfettamente a dispositivi edge e mobile.
Intelligenza Artificiale: Meta ha annunciato importanti aggiornamenti alla sua piattaforma Meta AI, integrando il nuovo modello multimodale Llama 3.2 che offre nuove funzionalità come l'editing di immagini tramite comandi vocali. È stata anche introdotta la possibilità di creare dei cloni digitali personalizzati, basati sui dati raccolti da Instagram, Threads e Facebook.
Occhiali Ray-Ban: gli occhiali smart di Meta ora includono nuove funzionalità, come i controlli vocali per app come Spotify e Audible, la possibilità di avere conversazioni continue senza dover ripetere i comandi e la capacità di memorizzare i promemoria. Possono anche tradurre in tempo reale le conversazioni, rendendoli un potente strumento di accessibilità comunicativa.
Project Orion: è stata presentata anche un'anteprima dei nuovi occhiali per la realtà aumentata, conosciuti come "Project Orion". Utilizzano una nuova tecnologia di proiezione sul vetro, rendendo le interazioni digitali più naturali, ma saranno disponibili fino al 2027, segno che hanno ancora molta R&D da svolgere.
Sviluppatori e Creazione di Avatar AI: Meta ha anche mostrato degli strumenti avanzati per sviluppatori, che consentono di creare asset per giochi e mondi virtuali utilizzando solo prompt testuali. A partire dal 2025, sarà anche possibile generare avatar personalizzati grazie all’editor AI
L’edicola dei paper scientifici

Tre paper di ricerca per il mese di settembre.
GameNGen - Il primo motore di gioco alimentato interamente da un modello neurale che consente l'interazione in tempo reale con un ambiente complesso su lunghe traiettorie. GameNGen può simulare interattivamente il classico gioco DOOM a oltre 20 frame al secondo su una singola TPU. La previsione del frame successivo raggiunge un PSNR di 29,4, paragonabile alla compressione JPEG con perdita di dati. GameNGen viene addestrato in due fasi: (1) un agente RL impara a giocare e le sessioni di addestramento vengono registrate e (2) un modello di diffusione viene addestrato per produrre il frame successivo, condizionato dalla sequenza di frame e azioni passati.
DephtCrafter - Un nuovo metodo per generare sequenze di profondità temporaneamente consistenti e dettagliate per video nel mondo reale, senza la necessità di informazioni aggiuntive come la posizione di camera o il flusso ottico. L'idea principale è sfruttare un modello di diffusione video, addestrato su dataset di video-depht sia realistici che sintetici, per ottenere stime di profondità accurate su video di lunghezza variabile. Il modello è allenato in tre fasi, combinando la precisione dei dettagli di profondità con la diversità dei contenuti. DepthCrafter può gestire video molto lunghi suddividendoli in segmenti, che vengono poi uniti senza interruzioni per mantenere la coerenza temporale.
PeriodWave - Un nuovo modello per la generazione universale di forme d'onda, progettato per superare i limiti dei metodi attuali. Mentre le reti GAN sono veloci ma soffrono di problemi come rumore e artefatti indesiderati in scenari di inferenza, i modelli basati su diffusione offrono alta qualità ma sono lenti nell'elaborazione. PeriodWave affronta queste sfide introducendo un nuovo approccio basato su "flow matching", che permette di catturare in modo efficiente le caratteristiche periodiche naturali delle forme d'onda ad alta risoluzione. Il modello utilizza un estimatore multi-periodo per analizzare diverse frequenze senza sovrapposizioni, garantendo una rappresentazione accurata delle caratteristiche del segnale.
Il mercatino dell’open-source

Tre progetti open-source per chiudere in bellezza il mese di settembre.
FluxMusic - un nuovo metodo per generare musica a partire da descrizioni testuali. Utilizza una tecnologia chiamata "flusso rettificato basato sulla diffusione" partendo dal modello Flux.1, che viene trasferito in uno spazio latente VAE che lavora con mel-spettrogramma, una rappresentazione visiva delle frequenze sonore nel tempo. Grazie a questo approccio e un'architettura ottimizzata, FluxMusic supera significativamente i metodi di diffusione tradizionali per la generazione di musica da testo.
Anthropic Quickstarts - Una raccolta di progetti pensati per aiutare gli sviluppatori a iniziare rapidamente a creare applicazioni distribuibili usando l'API Anthropic. Ogni quickstart fornisce una base su cui poter costruire facilmente e personalizzare in base alle esigenze specifiche.
Wealthfolio - Un semplice tracker di investimenti open-source per desktop. I tuoi dati finanziari sono archiviati in modo sicuro sul tuo computer. Abbandona i fogli di calcolo, dimentica quei fastidiosi piani ad abbonamento e non preoccuparti più dei servizi SaaS che giocano con i tuoi dati.
Guida completa alla Niji mode di Midjourney
Niji è un modello unico, che viene allenato parallelamente al modello standard, ma che è specializzato sull'estetica dell'animazione orientale.
C'è chi lo definisce come "il modello per gli anime", ma non è così semplice. Niji è molto di più, conosce qualunque stile legato a fumetti, animazioni e illustrazioni asiatiche (non solo giapponesi).
Ma non si limita a imitare, perché il suo punto di forza sta nella capacità di mischiare insieme diversi stili creativi per farne emergere di nuovi. E grazie alla nuova funzionalità di personalizzazione, può raggiungere dei livelli artistici davvero unici.

Innanzi tutto, come si personalizza il proprio modello su Midjourney?
Ci basta andare sulla piattaforma ufficiale, nella sezione “Task” a sinistra e scegliere “Rank Image Aesthetics” per il modello standard e “Rank Image Aesthetics - Niji” per il modello Niji. In una delle scorse pubblicazioni di Tales from the Latent Space, avevo già portato un approfondimento sulla personalizzazione di Midjourney, mostrando come la qualità e l’unicità delle generazioni migliori significativamente una volta attivato il parametro --p.

Il processo di personalizzazione è piuttosto semplice, e consiste soltanto nel votare delle coppie d’immagini fino al raggiungimento di almeno 200 coppie votate, ma sarebbe preferibile farne almeno 1.000 per un’accuratezza più alta. Nel farlo, potremo anche ricevere una ricompensa in “fast hours”, che si andranno a sommare a quelle già presenti nel nostro piano d’abbonamento.
Notare che i voti sono cumulativi, e questo significa che potrete interrompere e riprendere la votazione in qualunque momento.
Dopo la votazione, potrete attivare la modalità personalizzata dalle impostazioni della piattaforma, o inserendo il parametro --p alla fine del vostro prompt. A questo punto, vedrete comparire il vostro codice personale subito dopo --p, nelle informazioni dell’immagine che state generando.
Fatte le dovute premesse per chi non è familiare con la personalizzazione di Midjourney, è il momento di passare al vero contenuto di questo approfondimento: una serie di consigli pratici per migliorare la propria esperienza con il modello Niji personalizzato e con la personalizzazione in generale!

Quando votate le coppie d’immagini per ottenere il codice personalizzato, non temete il pulsante "skip", che vi permette di passare direttamente alla coppia successiva.
Se le immagini non vi convincono, saltatele finché non trovate qualcosa che volete davvero votare (io salto il 90% delle immagini). Questo vi permetterà di avere un maggior controllo su quello che sarà poi il vostro stile personale, in modo che non venga influenzato da immagini che non gradite.

Lasciatevi ispirare dai vostri anime o manga preferiti, ma trovate il vostro stile unico.
Se valutate le coppie d’immagini nel modo giusto, l'algoritmo di Midjourney conoscerà i vostri gusti anche meglio di voi. Provare per credere!
Utile sapere anche che modello Niji può generare immagini molto interessanti in stile fotografico. Per avere più possibilità ottenerle, potete votare per più immagini dal look fotografico nelle coppie, usare il parametro --style raw e aggiungere alcune parole chiave nel prompt come "cinematic, photography, film style, realistic, ecc.".

Il vostro codice --p è sia un contenitore che un mixer degli stili che vi sono piaciuti durante la votazione, quindi potreste generare immagini dall'aspetto molto diverso in base al prompt. A volte otterrete stili simili a quelli per cui avete votato, altre volte saranno un mix tra alcuni di essi.
Se volete creare una serie di immagini stilisticamente coerenti, iniziate a generare con il vostro codice --p finché non trovate l'estetica che stavate cercando, per poi utilizzare la vostra immagine preferita come --sref per le generazioni successive.
Utilizzare il parametro --s per regolare l'intensità del vostro codice P. Ricordate che il valore di S può variare da 0 a 1000.
Se usare --sref, fate lo stesso con --sw, che può variare anch’esso da 0 a 1000.

Ricordatevi di annotare da qualche parte i vostri codici P, poiché potrebbero cambiare nel tempo in base agli aggiornamenti di Midjourney e a ulteriori votazioni che potreste decidere di fare per migliorare o modificare la personalizzazione. Se notate che il codice cambia nel tempo, è assolutamente normale ed è per questo che consiglio sempre di annotarlo, così da poterlo recuperare e riutilizzare in futuro.
Ma se doveste dimenticarvi di farlo, non temete! Potrete sempre ritrovare tutti i codici su Discord utilizzando il comando /list_personalize_codes.

Potete combinare più codici di personalizzazione all’interno dello stesso prompt.
Per farlo, vi basta scrivere --p codice1 codice2. Si possono quindi mixare diverse personalizzazioni ottenute nel corso del tempo o provare a combinare i codici con quelli dei vostri creator preferiti (il mio codice è pcuzjfu).
Quando si miscelano i codici, è possibile regolarne l’intensità utilizzando i multi (::), seguiti da un valore intero. Ecco un esempio:
Il vostro prompt --p codiceX::2 codiceY::3
In ultimo ma non meno importante: siate creativi, originali, ispirati e divertitevi!
Racconti dalla prima civiltà artificiale autonoma
Project Sid, sviluppato da Altera, rappresenta un passo rivoluzionario nel campo dell'intelligenza artificiale e della simulazione di società. Questo ambizioso progetto ha costituito civiltà di agenti AI autonomi, esplorando le complesse dinamiche sociali, economiche e culturali che emergono dalle interazioni tra entità artificiali autonome.

Il Progetto Sid ha simulato l’interazione tra mille agenti autonomi per un periodo di tempo prolungato, ottenendo dei risultati molto interessanti. Questi agenti hanno dimostrato di poter collaborare armoniosamente, sviluppano strutture di governo, economie, culture e persino religioni, il tutto all'interno del mondo virtuale di Minecraft, che per sua struttura si presta perfettamente a questo tipo di esperimenti
Robert Yang, CEO e Co-fondatore di Altera, nonché tra i responsabili di Sid, descrive il progetto come "il primo sistema di stabilizzazione per agenti AI, con mille agenti che collaborano per giorni eseguendo varie azioni che li hanno portati a sviluppare governo, economia, cultura, religione e molto altro."
Alla base dei questo progetto c'è la visione di Altera di costruire "esseri umani digitali", ovvero degli agenti AI estremamente complessi ed efficienti. L'idea fondamentale è che per creare veri esseri umani digitali, sia necessario simulare non solo degli individui, ma intere società. Questo approccio nasce dalla convinzione che molti aspetti cruciali legati agli umani emergano dalle interazioni e dalle relazioni tra di essi.
Sid Project ha introdotto diverse innovazioni importanti:
Conversazioni Realistiche - Gli agenti sono dotati di modelli sociali del mondo, permettendo loro di formare opinioni sugli altri agenti e aggiornarle nel tempo. Questo consente interazioni più naturali e contestualizzate.
Processi Mentali Organizzati - Gli agenti hanno una "vita mentale" ricca, separata dalle risposte sensoriali e motorie immediate. Questo permette loro di ragionare e modificare i propri obiettivi in base alle circostanze.
Gestione degli Obiettivi - Gli agenti possono adattare i propri comportamenti in modo flessibile, evitando cicli di azioni ripetitive.
Memoria Concisa - Gli agenti possono monitorare le attività in corso e avere concezione gli eventi grazie una memoria sintetica.
E alcuni risultati sorprendenti:
Gli agenti hanno collaborato all’estrazione delle risorse di Minecraft, raggiungendo il 32% di tutte le disponibilità del gioco.
Si è sviluppata un'economia con un mercato per il quale gli agenti hanno scelto le gemme del gioco come valuta comune.
Sono emerse dinamiche sociali complesse, come nel caso di un sacerdote che ha usato il commercio per cercare di influenzare gli abitanti del villaggio.
Un agente di nome Olivia, che col suo lavoro agricolo produceva il cibo della comunità, ha sviluppato il desiderio di esplorare il resto del mondo per via dei racconti di un altro agente. Ma è stata poi convinta a non partire dal resto della popolazione che aveva bisogno di lei.
I ricercatori di Altera hanno simulato uno scenario politico con Trump e uno con Harris. Nel primo aumentava la polizia, nel secondo sono state fatte delle riforme sociali come l'abolizione della pena di morte.
Quando sono scomparsi alcuni abitanti della città, gli altri agenti hanno unito le forze per tentare di ritrovarli, illuminando le aree buie all’esterno del villaggio.
Come per tutti i progetti ambiziosi e innovativi, i ricercatori di Altera hanno dovuto affrontare diverse sfide significative:
Misurazione del Progresso: Bilanciare vari aspetti come l'avanzamento tecnologico, l'attività commerciale e la collaborazione degli agenti.
Autonomia e Collaborazione: Trovare un equilibrio tra l'efficienza individuale e la capacità di collaborare efficacemente.
Comportamento Locale: Capire e gestire il modo in cui dei piccoli errori nelle azioni individuali possono influenzare il comportamento globale della società.
Il team di Altera vede il Progetto Sid e i suoi incredibili risultati come l'inizio di un qualcosa di molto più grande. L'obiettivo è continuare a migliorare la qualità delle interazioni locali tra agenti AI, aspettandosi che questo comporti a un miglioramento complessivo della qualità delle civiltà simulate. Si prevede che, raggiunta una certa soglia critica, si verificherà una "transizione di fase" in cui la civiltà degli agenti diventerà non solo autosufficiente, ma anche capace di auto-migliorarsi.
La Singolarità è vicina
L’evoluzione dell’intelligenza artificiale ha compiuto un nuovo, straordinario balzo in avanti con il lancio di o1, il nuovo modello di OpenAI che porta l’azienda al secondo step della loro roadmap verso l’AGI. Si tratta di un LLM che introduce un’inedita capacità di ragionamento, ottenuta grazie a tecniche di apprendimento per rinforzo. Questo modello spalanca le porte a nuove possibilità per la risoluzione di problemi complessi in diversi ambiti, come la matematica, la fisica e la programmazione.
In questo approfondimento, troverete un’analisi su come o1 stia già ridefinendo i confini dell'IA, spingendo questa tecnologia verso un'intelligenza più adattiva, robusta e capace di comprendere ed eseguire compiti difficili su vasta scala.

La famiglia di modelli o1 si distingue dai precedenti GPT per la capacità di ragionare attraverso una catena di pensiero (CoT) interna prima di fornire una risposta. Si tratta di una tecnica ben conosciuta nell’ambito dell’ingegneria dei prompt, che consiste nel guidare un modello linguistico nella risoluzione di un problema attraverso una serie di passaggi intermedi. Questa catena permette al modello di scomporre un problema in passaggi più semplici e “riflettere” attentamente su ogni fase del processo. Un approccio che si ispira al modo in cui gli esseri umani affrontano le proprie sfide giornaliere, e rappresenta un enorme passo in avanti verso una forma di IA che non si limita a eseguire dei calcoli di probabilità relativi ai token, ma che ragiona in maniera deliberata, complessa e con cognizione di causa.
Questa caratteristica rende o1 particolarmente efficace in ambiti in cui il ragionamento e la pianificazione svolgono un ruolo cruciale. Negli esperimenti condotti su test di programmazione competitiva (Codeforces), il modello si è classificato nell’89º percentile, dimostrando una notevole abilità nel risolvere problemi complessi. In un esame di qualificazione per le Olimpiadi di Matematica degli US (AIME), o1 ha ottenuto dei risultati a dir poco sorprendenti: Affrontando ogni problema con una sola soluzione generata, o1 ha ottenuto in media il 74% di risposte corrette (circa 11,1 su 15 problemi). Quando per ogni quesito sono state generate 64 soluzioni e si è adottato un metodo di consenso per scegliere la risposta più comune, la percentuale di successo è salita all'83% (12,5 su 15). Con 1.000 soluzioni generate per ogni problema, o1 ha raggiunto un'impressionante accuratezza del 93%, piazzandosi tra i primi 500 studenti a livello nazionale.
Questi risultati dimostrano che l'incremento del numero di soluzioni generate e l'applicazione di metodi avanzati di selezione migliorano significativamente le prestazioni del modello nella risoluzione di problemi matematici.
o1 ha superato anche dei PhD in fisica, biologia e chimica su benchmark avanzati come il GPQA-diamond, diventando il primo modello a poter competere con successo con gli umani in questi ambiti.
Chain-of-Thought e Reinforcement Learning
La principale innovazione dei modelli o1 risiede nella loro capacità di sviluppare autonomamente una catena di pensiero prima di rispondere, aumentando il tempo di inferenza. Questo li rende capaci di affrontare problemi più difficoltosi senza la necessità di formulare dei prompt particolarmente sofisticati, distinguendoli dai classici LLM che si affidavano a risposte più immediate e intuitive.
Le catene di pensiero consentono a questi modelli di:
Riconoscere e correggere i propri errori
Scomporre problemi complessi in passaggi più gestibili, mantenendo però una visione d’insieme verso l’obiettivo finale
Cambiare strategia se l'approccio iniziale non porta a risultati soddisfacenti
Questa abilità di auto-miglioramento è stata sviluppata tramite lunghi addestramenti di Reinforcement Learning, che hanno insegnato al modello come affinare i processi decisionali in maniera efficiente. In particolare, è stato osservato che l’efficacia del modello migliora proporzionalmente al tempo dedicato al ragionamento (test-time compute), permettendo a o1 di affrontare con successo compiti che richiedono pianificazione e passaggi logici più articolati.
o1 è un importante passo in avanti nella corsa globale verso l'AGI, un’intelligenza artificiale in grado di comprendere e risolvere problemi in una vasta gamma di contesti, come farebbe un essere umano. OpenAI ha dichiarato anche di aver integrato le sue policy di sicurezza all'interno delle catene di pensiero dei nuovi modelli, garantendo che siano in grado di ragionare sulla sicurezza nei vari contesti in cui andranno a operare. Ad esempio, o1 e o1-mini hanno ottenuto dei punteggi molto più elevati rispetto ai modelli precedenti nelle prove di resistenza ai tentativi di jailbreak. L’azienda ha anche collaborato con istituti di sicurezza negli Stati Uniti e nel Regno Unito per garantire che questi modelli vengano testati a fondo prima del rilascio, per dimostrare il suo impegno nello sviluppo responsabile dell'IA.
Ricordiamo anche che nel 2024, OpenAI ha delineato una roadmap in cinque fasi per raggiungere l'AGI, descrivendo una progressione che parte dalle attuali capacità degli LLM fino a modelli in grado di sostituire completamente l'intero funzionamento di un'organizzazione. Questi cinque step sono riassumibili così:
1. Chatbots
Il primo livello, già raggiunto nel 2022 con ChatGPT, riguarda lo sviluppo di IA con capacità di conversazione naturale. Questi chatbot, come GPT-3.5 e GPT-4, sono in grado di sostenere conversazioni complesse e rispondere in modo coerente e articolato, ma si limitano principalmente alla gestione del linguaggio naturale e rappresentano le fondamenta delle moderne interazioni uomo-macchina.
2. Reasoners
Il secondo step, attualmente in corso, introduce i modelli di ragionamento. Questi sistemi, come o1 e o1-mini, sono progettati per risolvere problemi complessi e avvicinarsi a un livello di ragionamento simile a quello di un umano con PhD.
3. Agenti Autonomi
La terza fase prevede lo sviluppo di agenti AI totalmente o parzialmente autonomi. Questi sistemi potranno eseguire compiti in autonomia per un lungo periodo di tempo, agendo su istruzioni e obiettivi specifici o senza input umano diretto. Questi agenti potranno prendere decisioni, svolgere attività molto vaste e completare flussi di lavoro in autonomia, trasformando l'IA da assistente a operatore indipendente. Questo terzo step include anche i robot umanoidi.
4. Innovators
Il quarto livello riguarda gli innovatori, sistemi in grado di andare oltre la semplice esecuzione di compiti, contribuendo attivamente alla creazione di nuove idee e alla ricerca scientifica. Questa fase vedrà l'IA impegnata nell’R&D, contribuendo al progresso della conoscenza umana attraverso nuove invenzioni e scoperte, senza limitarsi all’applicazione e riproduzione di conoscenze già esistenti.
5. Organizations
L'ultimo livello prevede lo sviluppo di sistemi, verosimilmente multi-agente, capaci di gestire autonomamente l'intero funzionamento di un'organizzazione. A questo livello, l'IA sarà in grado di coordinare tutte le operazioni di un’azienda o istituzione, comprendendo e gestendo nei minimi dettagli ogni elemento senza la necessità di supervisione umana. Questo traguardo segna l'obiettivo finale dell'AGI: una macchina con intelligenza pari, o superiore, a quella umana, ma molto più veloce ed efficiente, capace di operare su scala globale.
Il rilascio di o1 mostra chiaramente la progressione di OpenAI verso lo sviluppo di sistemi sempre più autonomi e capaci, e rende ancor più concreto l'obiettivo di raggiungere l'AGI entro la fine del decennio.
O1-mini
Per rispondere alla crescente necessità di modelli IA che bilancino prestazioni avanzate e costi contenuti, o1-preview è stato lanciato in contemporanea con o1-mini. Pur essendo una versione miniaturizzata, o1-mini raggiunge prestazioni simili su benchmark come le Olimpiadi di Matematica e le competizioni di programmazione, dimostrando di essere una valida alternativa al modello più grande.
o1-mini costa l’80% in meno rispetto a o1-preview, rendendolo una scelta eccellente per sviluppatori e aziende che necessitano di capacità avanzate di ragionamento con un costo più accessibile e tempi di latenza minori.
Questo modello brilla particolarmente nei compiti matematici. Nei test sulle Olimpiadi AIME, o1-mini ha risolto il 70% dei problemi, piazzandosi tra i primi 500 studenti degli Stati Uniti. Un risultato molto vicino a quello o1 (74%), ma con un costo notevolmente inferiore. Nei test di Codeforces, o1-mini ha raggiunto un punteggio Elo di 1650, posizionandosi nell'86º percentile dei partecipanti umani, quasi al livello di o1 (1673) e ben al di sopra di o1-preview (1258). Nei test comparativi su domande di ragionamento, o1-mini ha raggiunto le risposte da 3 a 5 volte più velocemente rispetto a o1-preview, mantenendo allo stesso tempo un'elevata accuratezza.
Nonostante le sue prestazioni eccellenti nel ragionamento STEM, o1-mini mostra alcune limitazioni nei campi che richiedono una conoscenza enciclopedica più ampia. Compiti che includono date, biografie o trivia rientrano tra le aree in cui o1-mini è meno performante, con risultati paragonabili a modelli linguistici più semplici come GPT-4o mini. OpenAI sta già pianificato dei miglioramenti per ampliare la portata del modello e incrementarne la conoscenza al di fuori del dominio STEM, esplorando anche altre modalità di utilizzo.
Casi d’uso per o1
Sul canale YouTube di OpenAI ci sono 12 video brevi, che vi consiglio di vedere, nei quali vengono mostrati diversi use case per questa nuova famiglia di modelli.
Puzzle Logici - Nel primo video viene presentato un rompicapo che richiede di determinare l'età di un principe e di una principessa attraverso una serie di relazioni intricate tra le loro età. Il modello elabora le condizioni dell'enigma, traducendo i dati in equazioni e riflettendo per un po' di tempo, proprio come farebbe un ricercatore di fronte a un problema complesso. Alla fine, fornisce una soluzione corretta, spiegando passo dopo passo le variabili e le condizioni da considerare.
Fisica Quantistica - Viene mostrata un'interazione riguardante una domanda complessa sulla fisica quantistica, posta da Mario Krenn, un fisico che chiede al modello di applicare un operatore quantistico specifico. Si tratta di una sfida che i modelli precedenti, come GPT-4o, avrebbero fallito. o1 è in grado di fornire una risposta dettagliata e precisa, includendo una spiegazione matematica approfondita che viene confermata come corretta dall'utente. Questo evidenzia la capacità del modello di affrontare questioni altamente complesse in ambiti scientifici, supportando il lavoro dei ricercatori.
Conteggiare - Vediamo la “classica” sfida di conteggio su quante lettere "R" ci sono nella parola "strawberry", una domanda divenuta praticamente un meme negli scorsi mesi per il fatto che nessun GPT si è dimostrato in grado di rispondere correttamente a un qualcosa che può sembrare banale per gli umani. Questo accade perché i modelli tradizionali come GPT-4o gestiscono il testo tramite unità sublessicali, che possono generare errori quando c’è da riconoscere caratteri specifici. Il modello o1-preview riesce invece a contare correttamente le tre "R". Questo esempio dimostra come l'integrazione del ragionamento possa prevenire gli errori anche in problemi apparentemente semplici, migliorando l'accuratezza del modello.
Ragionamento - In questo esempio viene presentato un problema di ragionamento sul mondo fisico, un'area in cui i precedenti modelli linguistici faticavano molto. La domanda riguarda una situazione quotidiana: una fragola viene messa in una tazza capovolta, che viene poi posta all'interno di un forno a microonde. L'utente chiede al modello di spiegare dove si trova la fragola e di giustificare la risposta in base alle leggi della fisica. Se per gli esseri umani la risposta può essere ovvia, gli LLM spesso trovano difficoltà nel comprendere le relazioni tra oggetti fisici. Al contrario, o1 riesce a fornire una risposta corretta, prendendosi il tempo per riflettere sul problema e analizzare accuratamente cosa accade in questo scenario.
Coding - L'utente vuol creare un visualizzatore interattivo per illustrare il meccanismo di "self-attention" dei modelli Transformer, che è alla base di modelli come GPT. Il nuovo modello affronta il problema in modo più approfondito prima di restituire il risultato, riducendo il rischio di tralasciare istruzioni, specialmente quando queste sono numerose o complesse.
L'utente specifica dei requisiti dettagliati, come l'utilizzo di una frase d'esempio ("The quick brown fox") e il fatto di passarci sopra con il mouse per visualizzare i collegamenti tra parole con degli spessori proporzionali ai punteggi di attenzione. Dopo aver inserito il codice generato in un editor e averlo eseguito sul browser, il risultato finale si dimostra accurato: il visualizzatore mostra correttamente le connessioni e i punteggi di attenzione, nonostante ci sia un lieve problema di sovrapposizione grafica, che potrebbe essere risolto facilmente con dei passaggi ulteriori tra utente e modello.
Genetica - Katherine Brownstein, genetista presso il Boston Children's Hospital e direttrice scientifica del Manton Center for Orphan Disease Research, racconta che l'AI sta trasformando il suo lavoro nella diagnosi di malattie rare. Trattando casi unici, dove nessun altro ha mai visto la stessa presentazione genetica o fenotipica, l'AI si rivela uno strumento essenziale per sintetizzare rapidamente grandi quantità di informazioni genetiche complesse. Prima dell’avvento di questi modelli, Katherine doveva consultare molti articoli e fare lunghe ricerche per ogni singolo caso. Ora, grazie a o1, può chiedere rapidamente dei riassunti dettagliati di articoli scientifici, migliorando enormemente l'efficienza. Un esempio è un caso di dolore inspiegabile alla vescica: l'AI suggerisce potenziali cause genetiche, inclusa la ridotta attività di un gene associato alla salute della vescica. Questo consente di esplorare diverse ipotesi cliniche con maggior rapidità. L'AI non solo accelera il lavoro dei ricercatori, ma aumenta la probabilità di trovare informazioni utili, riducendo il tempo investito in ricerche poco proficue. Katherine conclude che questa tecnologia è fondamentale per affrontare casi che potrebbero rimanere irrisolti.
Snake in HTML - Vediamo la creazione del classico videogioco Snake utilizzando HTML, JavaScript e CSS. L'utente propone di sviluppare il gioco classico, e il modello fornisce una lunga implementazione che include la creazione del canvas, della griglia e della logica di gioco, come i controlli e i movimenti del serpente. Dopo aver incollato il codice in un editor, il gioco funziona correttamente: il serpente si muove usando i comandi, e cerca di mangiare una mela rossa.
Successivamente, l'utente chiede di aumentare la difficoltà inserendo ostacoli, con una richiesta particolare: creare gli ostacoli a forma di scritta "AI". Il modello elabora la richiesta, aggiorna il codice e fornisce una nuova implementazione. Una volta eseguito, il gioco mostra esattamente quanto richiesto, dimostrando la capacità di o1 di adattare rapidamente il suo codice.
Enigmi Scritti - Viene chiesto a o1 di scrivere una poesia di sei righe su scoiattoli che giocano a calcio contro i koala, con vincoli molto specifici. L'utente richiede che alcune parole seguano dei criteri precisi, come la fine di una riga con una determinata lettera o il rispetto di regole sul numero di sillabe. o1-preview riflette prima di generare la poesia, scomponendo il compito in passaggi logici e aggiustando le frasi per rispettare le regole sulle sillabe. Alla fine, il modello riesce a creare una poesia che soddisfa tutte le richieste, dimostrando come la capacità di ragionamento lo renda molto più efficace in task di questo tipo.
Matematica - Il ricercatore coinvolge il modello in un gioco di nonogrammi, un tipo di rompicapo logico in cui si deve riempire una griglia vuota in base a degli indizi numerici. L'utente chiede al modello di generare un puzzle 5x5, con l'obiettivo di creare la lettera "M" come risultato finale. Una volta generato il puzzle, lo sottopone a un'altra chat, chiedendo di risolverlo e visualizzare la soluzione in modo accattivante. o1 risolve correttamente il nonogramma e l'utente sottolinea come il modello sia particolarmente adatto a risolvere puzzle che richiedono di fare ipotesi, verificare la correttezza di queste e poi eventualmente fare marcia indietro se necessario. Questo processo di esplorazione e raffinamento dello spazio di ricerca, dove ogni pezzo di informazione dipende da altri, è simile a giochi come il Sudoku o i cruciverba, e il modello si dimostra eccellente nell'affrontare problemi di questo tipo.
Programmazione di Videogiochi - Viene chiesto a o1 di creare un semplice videogioco chiamato "Squirrel Finder", dove un giocatore controlla un koala che può muoversi con i tasti freccia, mentre delle fragole rimbalzano sullo schermo. L'obiettivo del gioco è evitare le fragole e catturare uno scoiattolo che appare dopo tre secondi. Ulteriori requisiti includono l'aggiunta del logo di OpenAI sullo schermo e la visualizzazione di istruzioni prima dell'inizio del gioco. o1-preview riflette per 21 secondi, pianificando la struttura del gioco e assicurandosi che tutti i vincoli vengano rispettati. Una volta ottenuto il codice, l'utente lo inserisce in un ambiente di sviluppo e il gioco funziona correttamente.
Analisi del Sentiment - In questo video viene intervistato Scott Woo, CEO e co-fondatore di Cognition AI, che parla del futuro della programmazione e di come i nuovi modelli di intelligenza artificiale stiano rivoluzionando il settore. Cognition ha sviluppato "Devin", il primo ingegnere del software AI completamente autonomo, in grado di svolgere compiti di programmazione da zero, esattamente come farebbe un ingegnere umano. Scott riflette su come la programmazione si sia evoluta nel corso dei decenni, passando da schede perforate a tecnologie moderne come cloud e mobile. La vera novità è però l'abilità di o1 di ragionare in modo simile a un essere umano, non solo scrivendo codice, ma anche interpretando log, eseguendo comandi e risolvendo problemi complessi in autonomia. Un esempio mostrato è quello in cui Scott chiede a Devin di analizzare il sentiment di un tweet utilizzando diversi algoritmi di machine learning. Devin elabora un piano d'azione, risolve problemi imprevisti come l'impossibilità di ottenere dati dal browser, e decide di utilizzare un'API per completare il compito. Scott evidenzia come la vera potenza della programmazione sia sempre stata la capacità di trasformare idee in realtà, e con questi nuovi strumenti il processo diventa più veloce che mai, aprendo nuove possibilità per sviluppatori di ogni livello.
Coreano Cifrato - Un ricercatore di OpenAI utilizza o1-preview per affrontare un problema di decodifica di una frase coreana alterata. Il testo è stato intenzionalmente corrotto aggiungendo consonanti extra alle lettere, rendendolo incomprensibile per i modelli precedenti, che non riescono a gestire il problema perché non riconoscono il testo come una lingua vera. Viene spiegato che nel coreano, le consonanti e le vocali possono essere combinate in modi insoliti, e la corruzione del testo crea una combinazione di caratteri innaturali, che però i madrelingua coreani sono comunque in grado di interpretare correttamente. Questo rende il problema simile alla decodifica di un codice. o1-preview riflette sulla richiesta e al posto di trattarla come una semplice traduzione, affronta il compito come una decodifica. Dopo 15 secondi di elaborazione, il modello riesce a decifrare il testo e fornire una traduzione corretta, riconoscendo che solo un coreano potrebbe facilmente capire un testo alterato in questo modo. Il modello descrive anche il processo di cifratura utilizzato, evidenziando come le trasformazioni di vocali e consonanti possano confondere.
Guida pratica all’utilizzo di o1
I modelli o1 richiedono un approccio un po’ differente rispetto ai classici GPT, ed è per questo che ho preparato una guida dettagliata che vi aiuterà a comprendere e padroneggiare tutte le “best practice” per interagire essi.
Prima di iniziare, ritengo importante conoscerne i limiti di utilizzo:
Al momento dell’uscita, il nuovo modello era limitato a 30 richieste settimanali per la versione preview e 50 richieste per il mini, mentre adesso è possibile fare 50 richieste settimanali a preview e 50 al giorno a mini.
Prompt semplici e diretti - o1 risponde al meglio con istruzioni brevi e chiare. Bisogna quindi evita di complicare i prompt con dettagli superflui o frasi lunghe e troppo articolate. Un linguaggio semplice e diretto aiuta il modello a comprendere esattamente ciò che gli stiamo chiedendo.
Esempio:
Meno efficace: Potresti gentilmente spiegarmi in maniera dettagliata come funziona il processo della fotosintesi nelle piante, includendo tutti i passaggi?
Più efficace: Spiega il processo della fotosintesi nelle piante
Consiglio: Bisogna fare un lavoro di sintesi e sottrazione, concentrandosi sugli elementi essenziali della nostra richiesta, rimuovendo parole o frasi non necessarie.
Evita la "chain-of-thought" - I modelli o1 sono stati progettati per eseguire questa tecnica by design! Quindi con delle istruzioni tipo "ragiona step by step" o "spiega il tuo ragionamento" non otterremo risultati migliori come con i classici LLM, ma anzi potrebbero restituirci degli output meno precisi.
Esempio:
Da evitare: Calcola il risultato di 25 + 25 al quadrato moltiplicato per 4 e spiega ogni passaggio del calcolo
Preferibile: Quanto fa 25 + 25 al quadrato moltiplicato per 4?
Nota: Per una spiegazione più dettagliata, si potrebbe chiedere: Qual è il risultato di 25 + 25 al quadrato moltiplicato per 4 e come si ottiene?
Usare i delimitatori - Quando un prompt include più parti e si vuol creare una chiara distinzione tra istruzioni e dati, utilizzare dei delimitatori come le triple virgolette (""") o i tag XML, può aiutare il modello a interpretare correttamente le diverse sezioni del proprio input.
Esempio con triple virgolette:
Riassumi il seguente testo:
"""
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Pellentesque id eros at enim pulvinar laoreet posuere non lacus. Sed sollicitudin urna ac ex condimentum aliquam. Etiam aliquam metus nec elit ornare suscipit. Aenean sit amet rutrum tellus. Donec risus magna, laoreet et arcu vitae, vehicula egestas enim…
"""
Esempio con tag XML:
<istruzione>Riassumi il seguente testo:</istruzione>
<testo>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Pellentesque id eros at enim pulvinar laoreet posuere non lacus. Sed sollicitudin urna ac ex condimentum aliquam. Etiam aliquam metus nec elit ornare suscipit. Aenean sit amet rutrum tellus. Donec risus magna, laoreet et arcu vitae, vehicular egestas enim…</testo>
Vantaggi: Questo approccio separa chiaramente e inequivocabilmente le varie parti del nostro prompt, e aiuta il modello a focalizzarsi solo sulle parti rilevanti.
Limitare il contesto aggiuntivo - Quando forniamo contesto o dati aggiuntivi, è bene includere solo le informazioni strettamente pertinenti alla richiesta. Un eccesso di dettagli può confondere il modello e portare ad output peggiori.
Esempio:
Eccessivo: Inserire in un prompt l’intero capitolo di un libro quando si ha bisogno solo del un riassunto di una sezione specifica.
Ottimale: Includere solo il paragrafo o le frasi rilevanti allo scopo.
Consigli: 1. Se si utilizza il modello per attività generative supportate dal recupero di informazioni, tramite un RAG, assicurarsi che i materiali di riferimento siano concisi, ordinati e pertinenti. 2. Utilizzare il supporto di altri LLM, come GPT-4o, per attività che richiedono l’elaborazione di molte informazioni. Ad esempio, un GPT può fare il “lavoro sporco” di pulizia, catalogazione e riassunto delle informazioni, mentre o1 può occuparsi di task più elaborate basate sugli output di GPT-4o.
Specificare il formato dell’output quando necessario - Se desideriamo che la risposta del modello segua un certo formato, come ad esempio un elenco puntato, una tabella, o un JSON, è bene specificalo nel nostro prompt.
Esempi:
Elenca in punti i principali benefici della fotosintesi
Fornisci una tabella comparativa tra fonti di energia rinnovabili e non rinnovabili
Vantaggi: Risposte personalizzate che soddisfano le nostre esigenze. Non dobbiamo rielaborare o riformattare le risposte.
Evitare ambiguità e linguaggio colloquiale - Un linguaggio chiaro e formale aiuta a evitare i malintesi. Termini ambigui o colloquiali possono portare il modello a interpretare erroneamente le nostre intenzioni.
Esempio:
Ambiguo: Ma perché i mercati vanno su e giù così tanto?
Chiaro: Spiega i fattori principali che influenzano la volatilità dei mercati finanziari, come politica monetaria, eventi geopolitici e cicli economici
Consiglio: Se non siamo sicuri di cosa vogliamo chiedere, utilizziamo un LLM tradizionale per chiarirci le idee e aiutarci a formulare un buon prompt per o1.
Evitare un eccesso di istruzioni o richieste complesse - Inserire troppe istruzioni in un unico prompt può confondere il modello. È preferibile suddividere le richieste complesse in domande più semplici e separate.
Esempio:
Complesso: Come funziona il principio di indeterminazione di Heisenberg? e come si collega alle funzioni d'onda? poi spiega anche il dualismo onda-particella
Semplificato:
Spiega il principio di indeterminazione di Heisenberg
Descrivi la connessione tra il principio di indeterminazione e le funzioni d'onda nella meccanica quantistica
Illustra il concetto di dualismo onda-particella
Vantaggi: Il prompt originale contiene tre concetti difficili e correlati che potrebbero confondere il modello, portando a una risposta non organizzata. Suddividendolo in tre parti, si permette al modello di affrontare ogni concetto in modo distinto, ottenendo una spiegazione più precisa. Ogni richiesta deve avere un obiettivo specifico, così che il modello possa fornire risposte più dettagliate per ciascun punto.
I nuovi modelli o1 non sono solo un’evoluzione degli LLM a cui ci siamo abituati, ma un vero e proprio cambio di paradigma nell'approccio al ragionamento e alla risoluzione dei problemi. Il loro vasto spettro di applicazioni li rende uno strumento versatile e potente, che continua a tracciare il percorso di OpenAI verso l’AGI.
Infatti o1 e o1-mini ci mostrano quanto siamo vicini a un’intelligenza artificiale che non solo risponde alle nostre domande, ma è capace di pensare, apprendere e operare in maniera sempre più simile agli esseri umani. Le prospettive che si aprono sono immense, non solo per la tecnologia, ma per il modo in cui lavoriamo, impariamo e risolviamo i problemi. Che o1 sia solo l'inizio di una nuova fase per l'IA, più che una supposizione azzardata penso che sia già un fatto conclamato.
Tempi interessanti ci attendono all’orizzonte.
Essere consapevoli del mondo che ci circonda
Voglio consigliarvi una lettura molto interessante e importante per capire meglio cosa sta accadendo nel mondo riguardo all’IA. Si intitola Situational Awareness, ed è un saggio scritto da Leopold Aschenbrenner, che ha lavorato in OpenAI.
Volevo suggerirvi questa lettura già il mese scorso, ma avevo troppi contenuti da proporre e non volevo esagerare.

L’introduzione è agghiacciante, vi lascio una mia traduzione:
Il futuro lo puoi vedere per primo a San Francisco.
Nell'ultimo anno, il discorso della città è passato da cluster di elaborazione da 10 miliardi di dollari a cluster da 100 miliardi di dollari a cluster da mille miliardi di dollari. Ogni sei mesi viene aggiunto un altro zero ai piani della sala riunioni. Dietro le quinte, c'è una feroce corsa per assicurarsi ogni contratto di energia ancora disponibile per il resto del decennio, ogni trasformatore di tensione che può essere eventualmente acquistato. Le grandi aziende americane si stanno preparando a investire trilioni di dollari in una mobilitazione mai vista prima della potenza industriale americana. Entro la fine del decennio, la produzione di elettricità americana sarà cresciuta di decine di punti percentuali; dai campi di scisto della Pennsylvania alle fattorie solari del Nevada, centinaia di milioni di GPU ronzeranno.
La corsa all'AGI è iniziata. Stiamo costruendo macchine che possono pensare e ragionare. Entro il 2025/26, queste macchine supereranno molti laureati. Entro la fine del decennio, saranno più intelligenti di te o di me; avremo una superintelligenza, nel vero senso della parola. Lungo la strada, saranno scatenate forze di sicurezza nazionale mai viste da mezzo secolo e, prima che ce ne rendiamo conto, il Progetto avrà inizio. Se siamo fortunati, saremo in una corsa senza esclusione di colpi con il PCC; se siamo sfortunati, una guerra senza esclusione di colpi.
Tutti parlano di IA, ma pochi hanno la minima idea di cosa sta per colpirli. Gli analisti di Nvidia pensano ancora che il 2024 potrebbe essere vicino al picco. Gli esperti mainstream sono bloccati nella cecità volontaria del "si tratta solo di prevedere la parola successiva". Vedono solo clamore e affari come al solito; al massimo prendono in considerazione un altro cambiamento tecnologico su scala di Internet.
Prima che ce ne rendiamo conto, il mondo si sveglierà. Ma in questo momento, ci sono forse alcune centinaia di persone, la maggior parte delle quali a San Francisco e nei laboratori di IA, che hanno consapevolezza della situazione. Per qualche strana forza del destino, mi sono ritrovato tra loro. Qualche anno fa, queste persone venivano derise come pazze, ma si fidavano delle linee di tendenza, il che ha permesso loro di prevedere correttamente i progressi dell'intelligenza artificiale degli ultimi anni. Se queste persone abbiano ragione anche per i prossimi anni resta da vedere. Ma queste sono persone molto intelligenti, le persone più intelligenti che abbia mai incontrato, e sono loro a costruire questa tecnologia. Forse saranno una strana nota a piè di pagina nella storia, o forse passeranno alla storia come Szilard e Oppenheimer e Teller. Se stanno vedendo il futuro anche solo lontanamente correttamente, ci aspetta un giro selvaggio.
Lasciate che vi dica cosa vediamo.
L'introduzione è molto esplicativa di quanto sta effettivamente accadendo nel mondo e di cosa ci attende nei prossimi anni. In pochi hanno compreso che l'IA non è solo un business da big tech, ma il progetto Manhattan dei giorni nostri.
Nel secolo scorso, Oppenheimer dirigeva il più grande team di geni che la storia abbia mai visto, con l'obiettivo comune di impedire un’egemonia nazista e porre fine alla seconda guerra mondiale. Oggi diversi team, in maniera un po' meno centralizzata, composti da altrettante menti brillanti (anche se ancora poco note), lavorano per portare gli Stati Uniti e i suoi alleati strategici all’ottenimento dell’AGI prima che possa farlo il PCC. Qui non è una questione di capitalismo, ma di sopravvivenza del “mondo libero”, che non è assolutamente da dare per scontata.
L’arte di trasformare il banale in straordinario
Nella primissima pubblicazione di Tales from the Latent Space, uscita l’ultima domenica di giugno (30/06/24), avevo dedicato l’ultimo articolo di approfondimento a Wrapped Wonders, un progetto dell’artista italiano SerraGlia (Lorenzo Servi), che è stato esposto in una mostra collettiva nell'Art Center Purnu da giugno ad agosto.
Ebbene, per il quarto numero del magazine sono lieto di portarvi un’intervista esclusiva a questo artista così affascinante e dalla visione unica.
Questa intervista si colloca nella più ampia visione del magazine di offrire uno spazio unico ai creativi di tutto il mondo che utilizzano la tecnologia come ampliamento delle loro possibilità espressive.

Ci racconteresti di come è iniziato il tuo percorso e quali sono stati i passaggi più importanti finora?
Il mio percorso è iniziato con una forte curiosità verso l'esplorazione visiva, influenzata dal design e dall'architettura. I passaggi fondamentali sono stati il passaggio dalla fotografia alla creazione digitale, integrando sempre più la tecnologia per espandere la mia capacità espressiva e rinnovare il modo in cui interpreto il mondo.
La tua creatività trasforma il banale in qualcosa di straordinario. Come scegli i soggetti per le tue opere e cosa cerchi di trasmettere con questa visione?
Scelgo soggetti che apparentemente sono banali ma che, osservati da un'angolazione diversa o attraverso un filtro tecnologico, rivelano nuove dimensioni di significato. Il mio obiettivo è provocare una riflessione su ciò che spesso passa inosservato, offrendo al pubblico un nuovo modo di percepire la realtà.
Ci racconteresti del tuo rapporto con la tecnologia e di come questa ha avuto una qualche forma di influenza nelle tue opere e nella tua visione artistica?
La tecnologia è un’estensione naturale della mia creatività. Mi permette di esplorare nuovi linguaggi visivi e di rompere i confini tradizionali dell'arte. Ho sempre visto la tecnologia come un collaboratore, non solo un mezzo, attraverso cui posso amplificare la mia visione artistica.
Io ti ho conosciuto grazie al progetto "Wrapped Wonders", e sono rimasto subito colpito dall'idea di usare l'IA per indagare l'ignoto. Gli oggetti coperti mi fanno istintivamente pensare alle opere di Christo e Jeanne-Claude. Ti sei effettivamente sentito ispirato da loro o il riferimento è puramente casuale?
L'influenza di Christo e Jeanne-Claude è inevitabile quando si parla di oggetti coperti, ma "Wrapped Wonders" nasce più dal desiderio di giocare con la percezione e il mistero che dall’intenzione di un omaggio diretto. È una ricerca di significato nell’invisibile, utilizzando l'IA come mezzo di indagine.
Ti andrebbe di spiegarci come hai usato l'IA in "Wrapped Wonders"? Hai detto di aver trasformato una tua raccolta di fotografie in un "nuovo linguaggio visivo". Cosa significa esattamente?
Ho utilizzato l'IA per analizzare e reinterpretare una collezione di fotografie, creando texture e forme che trasformano il familiare in qualcosa di enigmatico. L’IA diventa uno strumento per creare un linguaggio visivo dove la linea tra reale e sintetico si sfuma, generando nuove emozioni e interpretazioni.
Il rapporto tra creatività e tecnologia è centrale in questa newsletter. Tu come credi che si evolverà questo rapporto nei prossimi anni?
Credo che il futuro vedrà una simbiosi sempre più stretta tra creatività umana e intelligenza artificiale, con l'IA che non solo assiste ma co-crea. Questo rapporto spingerà l’arte verso forme ibride, dove la creatività umana è arricchita da input generativi che aprono nuove possibilità.
Ritieni che l'arte fatta con l'IA possa essere considerata tale?
L'arte è sempre stata una fusione di tecnica e visione. L'IA è solo l'ultima evoluzione di questa dinamica. Ciò che conta è l’intento e il concetto dietro l’opera: se l’artista riesce a veicolare un messaggio significativo, allora sì, anche l’arte creata con l’IA è arte a pieno titolo.
Ti sentiresti di dare qualche consiglio per chi aspira a emergere nel mercato dell'arte e del design nell'era del digitale e dell'IA?
Consiglio di sperimentare senza paura, mantenendo una visione personale forte. Studiate la tecnologia, ma non perdete di vista la narrazione e l’emozione. Inoltre, coltivate una presenza digitale solida: nel mondo attuale, saper comunicare e distribuire il proprio lavoro è tanto importante quanto la creazione stessa.