


Le Fratture del Nuovo Mondo
Il boato di ciò che crolla è solo il preludio per una ricostruzione. Dove il terreno si spezza, nuove strade trovano spazio per nascere


Un caloroso benvenuto a tutte le nuove persone iscritte a Tales from the Latent Space!
Nell'ultimo mese abbiamo accolto circa 80 nuovi iscritti, e questo non può che riempirmi di gioia. Per i nuovi arrivati, lasciate che vi presenti rapidamente questo progetto: non una semplice newsletter, ma un vero e proprio magazine che ogni mese esplora l'intricato rapporto tra creatività e tecnologia, con rubriche dedicate e articoli di approfondimento vari e adatti a un pubblico eterogeneo.
Cosa rende speciale questo magazine?
Innanzitutto, non abbiamo competitor: questo è il primo e unico progetto editoriale italiano dedicato al vasto mondo della tecnologia, affrontato dal punto di vista della creatività, con un focus particolare sull'arte e sull'intelligenza artificiale. Ogni numero è caratterizzato da uno stile visivo unico e raffinato, da titoli intriganti basati su citazioni culturali e giochi di parole, e da contenuti approfonditi e accuratamente selezionati per sfuggire al rumore informativo tipico dei social media.
L'articolo di apertura è sempre una domanda a cui trovare risposte soddisfacenti, mentre la chiusura è un’intervista a qualche persona meravigliosa.
A partire da questo numero, voglio condividere la mia intenzione di ricercare attivamente qualcuno che desideri collaborare alla crescita di questo progetto unico. In particolare, sto cercando collaborazioni per la scrittura di articoli che esplorino ulteriori aspetti della simbiosi creatività-tecnologia, anche da punti di vista insoliti e inaspettati. Ad esempio, nella scorsa pubblicazione ho collaborato con l'associazione ForeseeAI per offrire una prospettiva giuridica all'approfondimento sulla musica generata con l'IA. Sto anche cercando qualcuno interessato a sviluppare la pagina Instagram del magazine, con l'obiettivo di trasformare questo progetto in una vera e propria startup, che parta dall'editoria per espandersi verso la consulenza e lo sviluppo di soluzioni tecnologiche su misura per le aziende.
Se l'idea ti intriga o conosci qualcuno di sufficientemente ambizioso e competente che possa essere interessato, contattatemi su LinkedIn.
Fun Fact: l'uscita di questo numero coincide con il secondo anniversario di ChatGPT, uno strumento che ha profondamente cambiato la vita di milioni di persone in tutto il globo e spalancato le porte del Nuovo Mondo.
Ora allontaniamoci dalla linea gialla, che siamo in partenza…

Che cos’è un RAG?
Nel secondo numero di Tales from the Latent Space, vi avevo raccontato il funzionamento dei LoRA, utilizzando la metafora dell’immensa biblioteca di cui avevo già parlato per spiegare lo Spazio Latente nella primissima pubblicazione.
Oggi è il momento di ritornare in quella biblioteca virtuale, perché dobbiamo parlare di RAG (Retrieval-Augmented Generation), una tecnica che permette ai modelli di Intelligenza Artificiale di rispondere con precisione a richieste molto specifiche su nuove informazioni che non erano parte del dataset di addestramento.
Se lo spazio latente è una biblioteca misteriosa e i LoRA sono un metodo elegante di aggiungere nuovi scaffali pieni di informazioni senza sconvolgerne l'ordine, il RAG rappresenta una svolta nel modo in cui la biblioteca viene consultata e arricchita. Immaginate di aprire una porta e di ritrovarvi in una nuova sezione della biblioteca fatta su misura per voi, in cui ci sono solo le informazioni più rilevante per ciò che dovete chiedere. Il RAG è una tecnica che unisce memoria parametrica e non parametrica per generare risposte molto precise su determinati argomenti.
Per comprendere al meglio il suo funzionamento, dobbiamo esplorare il ruolo dei cosiddetti database vettoriali, capire le similitudini con i LoRA e relazionare il tutto con il concetto di Spazio Latente.
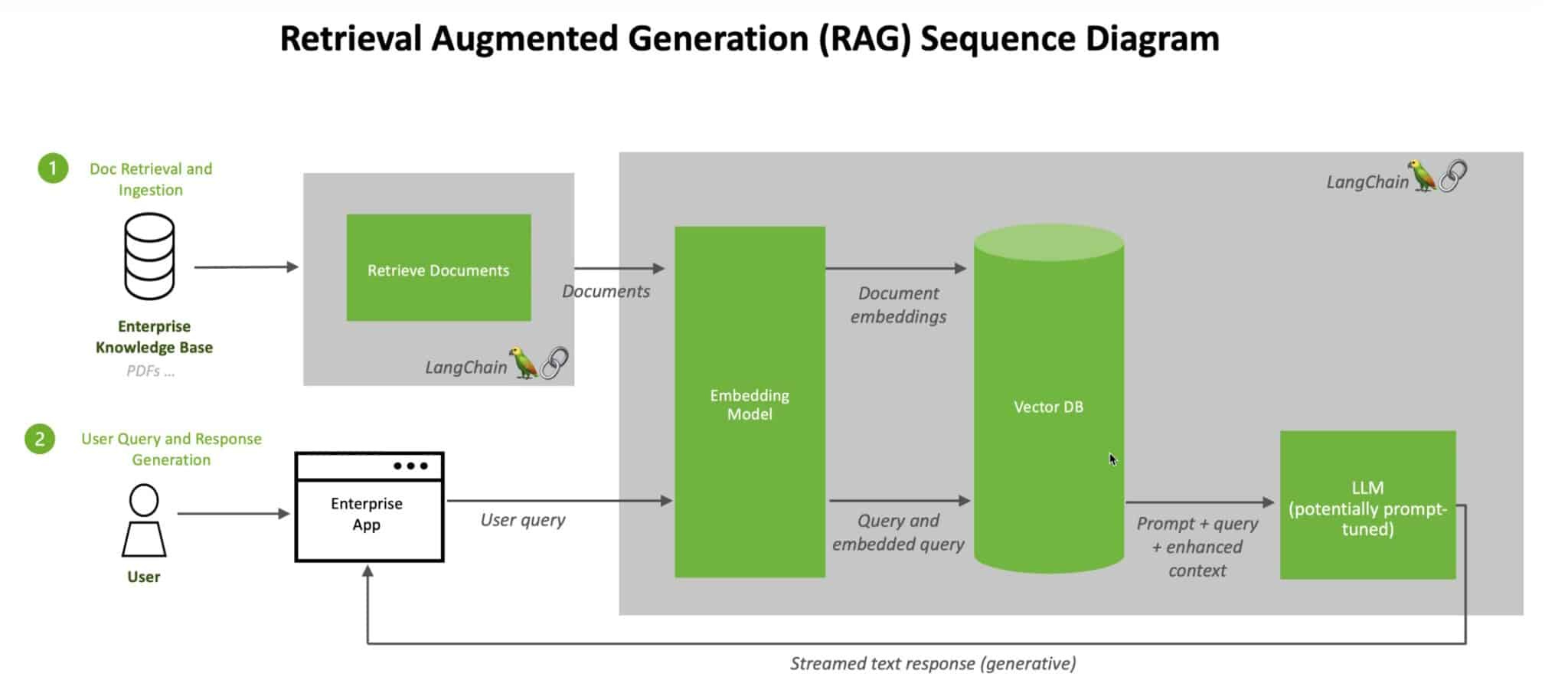
Nel regno del RAG, lo Spazio Latente di un modello– che ricordiamo essere una rappresentazione compressa e organizzata dei dati – non è più l’unica fonte di conoscenza. Questa biblioteca virtuale si estende ben oltre i propri confini, collegandosi a un sistema di memorie esterne chiamato vector database.
Un vector database non è altro che un archivio costruito per gestire nuovi dati rappresentati come vettori. Ogni elemento in questo archivio (che siano testi, immagini, o altro) è tradotto in un "punto" numerico nello spazio latente. Come succede nel mondo reale, dove libri categorizzati come simili finiscono vicini sugli scaffali, anche in un vector database gli elementi correlati si trovano vicini.
Per capire il ruolo dello spazio latente nel RAG, dobbiamo analizzare due elementi principali:
Il modello generativo e il suo spazio latente interno:
Ogni modello generativo, come GPT, utilizza uno spazio latente per rappresentare le informazioni apprese durante il processo di addestramento. Quando un utente fornisce un prompt, questo viene trasformato in una rappresentazione vettoriale (un punto nello spazio latente), che guida la risposta generativa del modello.
Il vector database e il suo spazio latente:
Il vector database opera in un proprio spazio vettoriale, che può essere considerato come uno "spazio latente esterno", separato dal modello generativo. Questo viene creato durante la fase di incorporamento (embedding) dei dati. Quando il modello generativo riceve un prompt, viene tradotto in un vettore nello spazio del vector database. Il sistema poi cerca i vettori più vicini, usando misure di similarità come la distanza coseno o la norma euclidea, per identificare le informazioni pertinenti.
Questi due spazi non sono identici, ma sono relazionati attraverso il processo di incorporamento. La chiave del successo del RAG è l'abilità di tradurre un prompt dallo spazio latente del modello principale in un vettore che sia interpretabile nel vector database. Questo avviene grazie all'uso di modelli di embedding condivisi o compatibili.
Quando un sistema RAG riceve un input, lo trasforma in un vettore che poi consulta il vector database per trovare i contenuti più rilevanti. Immaginate di avere un assistente capace non solo di leggere tutti i libri nella biblioteca interna dello spazio latente, ma anche di fare una corsa in una biblioteca vicina per trovare informazioni aggiuntive. Questo è esattamente ciò che accade: il RAG unisce le risorse interne del modello (la memoria parametrica) con un’architettura di retrieval basata sui vettori, trovando dati freschi e contestualizzati.
Similitudini con un LoRA
Se LoRA aggiungono nuovi scaffali alla struttura della biblioteca, adattando un modello generalista a compiti specifici senza toccare gli scaffali originali (i parametri), il RAG è come se dotasse la biblioteca di un sistema di connessione con altre biblioteche vicine. Le sue risposte non sono limitate a ciò che è già negli scaffali interni, ma si basano su una combinazione intelligente di risorse interne ed esterne.
Entrambi condividono lo stesso obiettivo: ottimizzare l’uso delle risorse. Nel caso dei LoRA, si tratta di sfruttare un numero ridotto di parametri per adattare i modelli. Nel caso del RAG, l’efficienza viene raggiunta andando direttamente alle fonti rilevanti tramite il vector database, facilmente aggiornabile senza nuovi addestramenti.
Lo spazio latente e il RAG
Qui entra in gioco lo spazio latente, che fa da ponte tra i dati interni e quelli esterni. Quando il modello consulta il vector database, non si limita a effettuare una semplice ricerca testuale. Utilizza i vettori come una sorta di linguaggio universale per rappresentare sia gli input che gli output. Questo approccio sfrutta il meglio di due mondi: la memoria parametrica del modello, che è statica e consolidata, e la memoria non parametrica del vector database, che è dinamica e aggiornabile. Insieme, permettono al RAG di combinare la precisione delle conoscenze interne con la freschezza di informazioni nuove e specifiche.
Pensatelo come un traduttore simultaneo: trasforma ogni richiesta in un formato numerico che può essere confrontato con i dati esterni, consentendo al modello di capire quali informazioni sono davvero pertinenti.
Un'altra caratteristica interessante dei RAG è il modo in cui integrano i documenti esterni nel processo generativo. Esistono due approcci principali: il metodo RAG-Sequence, in cui il modello utilizza lo stesso documento per generare l'intera risposta, e il metodo RAG-Token, che permette di consultare più documenti per ogni token generato. È come se un bibliotecario potesse consultare un unico libro o saltare rapidamente da un testo all'altro per estrarre solo i dettagli più utili. Questa flessibilità consente ai RAG di essere estremamente versatili, adattandosi sia a risposte concise che a elaborazioni più complesse.
Con il RAG, la biblioteca virtuale diventa un hub connesso a una rete di informazioni potenzialmente infinite. Le risposte non vengono più generate solo su ciò che è già stato imparato, ma attingendo da un archivio aggiornabile, mantenendo però l’efficienza e la precisione che caratterizzano i moderni LLM.
Avvenimenti del mese
Le notizie più interessanti e creative dal mondo della tecnologia, accuratamente selezionate per districarsi tra il rumore informativo.

La guerra dei modelli per le immagini si intensifica
Il 28 ottobre, Magnific ha rilasciato Mystic v2.5, l’evoluzione del loro modello per le immagini creato a partire da Flux. Per chi segue il magazine da un po’ di tempo, si ricorderà dell’approfondimento che feci alcuni mesi fa su Mystic, rilasciato inizialmente su Freepik, azienda che possiede una parte di Magnific.

La qualità delle immagini è migliorata significativamente rispetto alla precedente versione, così come la comprensione dei prompt e le anatomie. Rimane però ancora un modello pieno di imperfezioni, che stupisce per le sue proprietà artistiche, ma che non convince fino in fondo per mancanza di strumenti dedicati all’editing e per la necessità di scrivere prompt più lunghi e dettagliati di quanto non si vorrebbe per ottenere dei buoni risultati e avere un buon controllo sulle generazioni.
Pochi giorni dopo, il 17 novembre, è stato rilasciato un importante aggiornamento per Mystic 2.5: Style Reference, ovvero la possibilità di utilizzare delle proprie immagini come riferimento per guidare lo stile delle generazioni. Una funzionalità chiaramente ispirata da Midjourney, che offre questa possibilità da più di sei mesi. Lo Style Reference di Mystic funziona molto bene e permette di ampliare notevolmente le possibilità del modello, che di base sarebbe molto più limitato in termini stilistici rispetto alla più nota controparte Midjourney.
L’arrivo di questa funzionalità, che sta lentamente prendendo piede in tutti i modelli, ci può far riflettere su quanto rapidamente le altre aziende stiano colmando il loro divario con Midjourney, che fino a pochi mesi fa sembrava molto più grande rispetto a oggi. Vedremo se con l’arrivo della V7, previsto per gennaio, MJ riuscirà a staccarsi nuovamente dai suoi competitor sempre più agguerriti.
Il bello del nuovo mondo è anche questo, il fatto di non poter prevedere con certezza quali saranno le aziende e le tecnologie che domineranno il mercato negli anni a venire. Sicuramente, i modelli open-source continueranno a giocare un ruolo cruciale, mentre diverse aziende finiranno per essere acquisite da realtà più grandi o si fonderanno tra loro per non diventare irrilevanti.
Ricerche nelle proprie chat
Il 29 ottobre, OpenAI ha rilasciato una funzionalità tanto semplice quanto utile: la possibilità di eseguire ricerche all’interno delle proprie chat.
Mentre due giorni dopo, il 31 ottobre, ha rilasciato ChatGPT Search, una sorta di motore di ricerca integrato direttamente all'interno della classica interfaccia di chat, che fornisce risposte aggiornate con link alle fonti.
Il modello deciderà autonomamente di cercare sul web in base alle richieste dell’utente, ma si può anche attivare la ricerca manualmente cliccando sulla nuova icona posta di fianco alla graffetta per allegare i file.
A differenza delle query su Google, con questo strumento possiamo formulare quesiti in maniera conversazionale, ottenendo risposte dettagliate che considerano l'intero contesto della chat. Un’altra funzionalità utile, è la possibilità di inserire un link nella chat, ad esempio il collegamento a un articolo, e chiedere al modello di preparare un altro contenuto basato su quelle informazioni.
Al momento la funzionalità Search è ancora in fase beta, e a volte può risultare poco precisa, soprattutto con delle richieste un po’ più complesse rispetto a una semplice ricerca. Ad esempio, mi è capitato di chiedere indicazioni per passare da un punto A a un punto B usando i mezzi pubblici e, per quanto non mi abbia fornito informazioni false, mi ha proposto delle soluzioni molto più complicate di quanto non fosse necessario. Per intenderci, al posto di propormi un solo autobus più un pezzo a piedi, mi aveva suggerito di prendere la metro, poi un regionale, un pullman e infine il pezzo a piedi, triplicando il tempo e i costi necessari. Consiglio quindi di non affidarsi totalmente a Search per certi compiti, e di utilizzarlo solo per confermare delle informazioni che abbiamo già ottenuto in altri modi.
In futuro, OpenAI punta a integrare Search con il suo modello o1 e all’interno di Canvas, così da aumentare la portata della nuova funzionalità.
Animazioni meravigliose
Il 30 ottobre, Wonder Dynamics presenta Wonder Animation in versione beta, una nuova soluzione AI per creare film animati basata su tecnologia Video to 3D Scene.

Uno strumento che consente di girare una scena con qualsiasi telecamera, in qualsiasi luogo, e di trasformare la sequenza in una scena animata con personaggi CG in un ambiente 3D. La parte più innovativa della tecnologia Video to 3D Scene di Wonder Animation è la sua capacità di filmare e modificare sequenze con tagli multipli e varie inquadrature (ampio, medio, primi piani). La tecnologia utilizza quindi l'intelligenza artificiale per ricostruire la scena in uno spazio 3D e abbina la posizione e il movimento di ogni telecamera ai personaggi e all'ambiente.
Questo crea essenzialmente una rappresentazione virtuale della scena live-action contenente tutte le impostazioni della telecamera e l'animazione del corpo e del viso dei personaggi in una scena 3D, con elementi completamente modificabili (animazione, personaggio, ambiente, illuminazione e dati di tracciamento della telecamera). Il tutto è integrabile con software come Maya, Blender o Unreal.
Personalità vocali
Il 31 ottobre, Suno ha lanciato Personas, una funzionalità che cattura l'anima di una canzone. Mantenendo la voce, l'energia e l'atmosfera di una traccia e ti permettono di conservare quella "essenza" distintiva come un bene creativo unico.

Per creare una Persona, basta trovare una canzone preferita, cliccare su "..." e selezionare "Crea" seguito da "Crea una Persona". È possibile scegliere tra rendere la Persona pubblica o privata; le Personas pubbliche possono essere utilizzate da altri utenti e rimandano al profilo e alla Persona originale.
Attualmente, la funzionalità è disponibile in beta per tutti gli abbonati Pro e Premier, che possono creare fino a 200 canzoni utilizzando Personas senza costi aggiuntivi. Dopo queste 200, ogni nuova canzone creata con Personas costerà 10 crediti, come per qualsiasi nuova creazione.
Poco dopo, il 19 novembre, è stata finalmente resa disponibile in fase beta la V4 del loro modello per la generazione di musica, migliorando significativamente la qualità complessiva di ogni brano prodotto. Il nuovo modello porta con sé la funzionalità “Remaster”, che permette di rigenerare un vecchio brano utilizzando la V4 per migliorarne la qualità. In particolare, questo nuovo modello riesce a generare delle voci più profonde, dei brani ben equalizzati con tutti i volumi e le frequenze al posto giusto, testi migliori e arrangiamenti musicali più precisi e armoniosi.
Suno versione 4 è attualmente disponibile in beta per tutti gli utenti Pro e Premier, ma verrà resa disponibile a tutti una volta superata la fase di beta.
Controllare una videocamera virtuale
Il 1 novembre, Runway ha rilasciato Camera Control, una funzionalità che permette di migliorare significativamente il controllo della camera all’interno di una clip generata con Gen-3 Alpha Turbo, potendo scegliere direzione e velocità del movimento.
Una funzionalità molto attesa, che era già presente nel precedente modello Gen-2, ma che diventa incredibilmente più precisa sul nuovo Gen-3 Alpha. Ora gli utenti possono caricare un'immagine e muoversi al suo interno, quasi come un ambiente 3D simulato. Per ottenere dei risultati più precisi, si può combinare il nuovo strumento con i classici prompt testuali, che permettono un controllo maggiore.
Il 22 novembre, Runway rilascia anche Expand Video, una funzionalità che consente di espandere l’aspect ratio di un video generando nuove informazioni intorno all’inquadratura di partenza. Molto utile per trasformare una clip orizzontale in una verticale e vice versa, senza dover eseguire un crop in post-produzione. Ma anche per creare dei rapidi zoom digitali, espandendo una clip prima in verticale e poi di nuovo in orizzontale, così da ottenere un’inquadratura più distante.
Appena tre giorni dopo, il 25 novembre, viene presentata anche un’altra funzionalità, o meglio un nuovo modello detto Frames, che non è però un video model, ma bensì un generatore di immagini. Runway aveva già a disposizione un suo modello per le immagini statiche, ma la sua qualità non era delle migliori ed è rimasto molto indietro mentre l’azienda si concentrava sulla creazione di Gen-3 Alpha.
Frames sembra invece un grande passo avanti in termini di qualità complessiva e controllo stilistico, offrendo immagini altamente cinematografiche con un’ampia gamma di stili, che possono essere mantenuti coerenti nel tempo.
Il potere della voce
Il 12 novembre, ElevenLabs ha rinnovato Projects, il suo strumento per la creazione di lunghe narrazioni audio coinvolgenti come gli audiolibri.
Creatori, editori e aziende utilizzano Projects per trasformare libri in audiolibri, sceneggiature in voice-over o qualsiasi testo in dialoghi multi-speaker di alta qualità.
Poco più avanti, il 19 novembre, hanno rilasciato un’interfaccia no-code che permette la creazione di agenti AI conversazionali facilmente implementabili su siti web, dispositivi mobile o sistemi telefonici, offrendo bassa latenza, configurabilità completa e scalabilità. Gli utenti hanno la possibilità di personalizzare vari aspetti degli agenti, tra cui la lingua principale, la voce, il messaggio iniziale e il prompt di sistema per definire la loro personalità. Si può anche scegliere tra diversi LLM e regolare dei parametri come la creatività delle risposte e il limite di utilizzo dei token.
Insegnare ai modelli video come funziona il mondo
Il 13 novembre, la startup Odyssey, di cui avevo già parlato nel secondo numero del magazine, che sta tentano di creare il video model più avanzato sul mercato, ha mostrato al mondo il suo approccio al training di questo modello.

I fondatori di Odyssey, Oliver Cameron e Jeff Hawke, vantano una lunga esperienza nel settore delle auto a guida autonoma presso aziende come Cruise, Wayve, Waymo e Tesla. Questa competenza ha ispirato l'approccio di Odyssey nella raccolta di dati reali su larga scala per l'addestramento dei loro modelli. La startup utilizza un sistema di acquisizione portatile che consente di raccogliere informazioni in ambienti difficilmente accessibili, come foreste, spiagge e parchi. Questo dispositivo, simile a uno zaino, è dotato di sei telecamere, due LiDAR e un'unità di misura inerziale (IMU), permettendo la cattura di immagini panoramiche a 360 gradi in alta risoluzione con dati di profondità accurati.
L'obiettivo di Odyssey è combinare questi dati reali con tecniche di rendering avanzate per addestrare modelli generativi capaci di creare mondi virtuali dettagliati e realistici. Questo approccio mira a rivoluzionare la produzione di film e videogiochi, offrendo agli artisti strumenti più potenti per dare vita alle loro visioni creative.
Le chicche di Anthropic
Il 14 novembre, Anthropic lancia un nuovo strumento per la sua Console detto Prompt Improver, progettato per ottimizzare la qualità dei prompt per Claude.

Questo strumento automatizza l'applicazione di tecniche avanzate di ingegneria dei prompt, è particolarmente utile per adattare prompt utilizzati in altri modelli AI o per ottimizzare prompt scritti manualmente. In test interni, l'utilizzo del Prompt Improver ha aumentato l'accuratezza del 30% in un test di classificazione multilabel.
Poco dopo, il 21 novembre, ha aggiunto la possibilità di inserire contenuti direttamente da Google Docs. Poi il 26 sono stati introdotti gli stili personalizzati per Claude, permettendo agli utenti di adattare le risposte del chatbot alle proprie esigenze comunicative. Questa funzionalità offre tre stili predefiniti: Formale, per risposte chiare e raffinate; Conciso, per risposte brevi e dirette; Esplicativo, per risposte educative che approfondiscono nuovi concetti.
Ma si possono creare anche stili personalizzati caricando contenuti che riflettano il proprio modo di comunicare, consentendo a Claude di adattarsi a vari contesti, come la redazione di documentazione tecnica o la creazione di contenuti marketing.
AI shopping
Il 18 novembre, l’omonima azienda dietro al motore di ricerca AI Perplexity ha lanciato Perplexity Shopping, una nuova funzionalità che permette di cercare e acquistare prodotti direttamente dalla loro app web o mobile.

Si tratta di un’innovativa esperienza di shopping online, che permette agli utenti abbonati a Perplexity Pro di effettuare transazioni direttamente all’interno del servizio, ricevendo anche una spedizione gratuita. La nuova funzionalità è inizialmente disponibile solo negli Stati Uniti.
Come ChatGPT, ma gratuito
Sempre il 18 novembre, Mistral ha annunciato alcuni importanti aggiornamenti per Le Chat, la sua interfaccia conversazionale simile a ChatGPT.

Le principali novità di Le Chat sono: Ricerca web con citazioni, adesso Mistral può cercare informazioni online e fornire risposte aggiornate, esattamente come ChatGPT Search. Canvas, un'interfaccia per la scrittura collaborativa quasi identica alla versione di OpenAI, con la differenza che può eseguire e visualizzare il codice, un po' come fa Claude con i suoi Artifacts. Comprensione di documenti e immagini, grazie al nuovo modello multimodale Pixtral Large, le Chat può analizzare PDF e immagini, fornendo approfondimenti su grafici, tabelle e formule.
Grazie alla collaborazione con Black Forest Labs, Mistral ha integrato al suo interno Flux Pro per generare immagini di qualità. Le Chat Agents, si possono creare agenti personalizzati per automatizzare attività ripetitive, come la scansione di ricevute o il riassunto di lunghe trascrizioni delle proprie riunioni
L'aggiunta di tutte queste nuove funzionalità, rende le Chat di Mistral una vera e propria alternativa gratuita a ChatGPT Pro.
Sognare in grande
Il 25 novembre, Luma Labs ha lanciato una nuova interfaccia per Dream Machine, il suo modello per la generazione di video, che include una serie di nuove funzionalità.

La piattaforma consente agli utenti di ideare, visualizzare e condividere idee in maniera intuitiva, senza la necessità di ricorrere a tecniche avanzate di prompt engineering. Dream Machine incorpora Luma Photon, un nuovo modello per le immagini progettato per supportare i creativi nella creazione di contenuti visivi, dai racconti cinematografici alle idee di prodotto.
Tra le nuove funzionalità introdotte spicca la possibilità di utilizzare immagini di riferimento per sviluppare personaggi unici e coerenti, che possono essere poi animati con Dream Machine 1.6. Un'altra novità è rappresentata da Brainstorm, uno strumento integrato che facilita l'esplorazione di nuove idee, pensato per supportare chi si trova in fase di blocco creativo. Luma Labs descrive queste implementazioni come un passo avanti per rendere la creazione di contenuti visivi più fluida e accessibile, mantenendo però la possibilità di personalizzazione.
Tre ore con Sora
Il 26 novembre, intorno alle ore 16, qualcuno ha pubblicato su Hugging Face una versione non autorizzata di Sora, il modello video avanzato di OpenAI.
La versione di Sora che è stata rilasciata, detta “turbo”, può generare clip video in 1080p della durata di 10 secondi, con tempi di rendering sorprendentemente ridotti rispetto alle versioni precedenti. Purtroppo il modello è rimasto disponibile solo per tre ore: OpenAI ha prontamente chiuso il programma di accesso anticipato e bloccato l’API connessa ad Hugging Face.
La pubblicazione del modello è stata opera di un gruppo di beta tester, che hanno giustificato il gesto con un lungo comunicato critico verso il programma di accesso anticipato di OpenAI. Gli artisti coinvolti lamentano il fatto che, nonostante il loro contributo gratuito in termini di feedback e test, il programma abbia privilegiato le esigenze di marketing dell’azienda piuttosto che il reale supporto ai creativi.
Gli artisti hanno accusato OpenAI di “art washing” — sfruttare il lavoro non retribuito dei creativi per promuovere il modello come uno strumento utile per il mondo artistico, mentre le ricompense offerte erano, secondo loro, irrisorie rispetto al valore commerciale e promozionale generato.
L’edicola dei paper scientifici

Tre paper di ricerca per il mese di novembre.
MuVi - Un innovativo framework progettato per generare musica che si allinea ai contenuti visivi di un video, affrontando le sfide legate alla comprensione delle dinamiche visive e alla creazione di una colonna sonora che armonizzi con il ritmo, la melodia e la narrazione visiva. Grazie a un adattatore visivo appositamente sviluppato, MuVi analizza il contenuto video per estrarre caratteristiche rilevanti sia a livello contestuale che temporale. Questi dati vengono poi utilizzati per generare una musica che non solo rispecchia il mood e il tema del video, ma si sincronizza anche con il suo ritmo e la sua cadenza.
ControlMM - Un nuovo approccio per la generazione di movimenti controllabili in tempo reale ad alta precisione, superando le limitazioni di velocità e qualità dei modelli di diffusione del movimento attualmente disponibili. Questo sistema integra segnali di controllo spaziali all'interno di un modello generativo basato su motion mask, introducendo due elementi chiave: 1. Masked Consistency Modeling, che utilizza un mascheramento casuale e la ricostruzione per garantire movimenti di alta qualità, riducendo al minimo le discrepanze tra i segnali di controllo iniziali e quelli estratti dal movimento generato. 2. Inference-Time Logit Editing, che modifica la distribuzione predetta per generare movimenti strettamente aderenti ai segnali di controllo, migliorando ulteriormente la precisione. Durante l'inferenza, ControlMM consente una decodifica parallela e iterativa di più token di movimento, garantendo una generazione estremamente veloce, fino a 20 volte più rapida rispetto agli altri metodi basati su diffusione.
Skyeyes - Un framework che permette di generare sequenze fotorealistiche di immagini da da terra utilizzando esclusivamente immagini aeree. Questo approccio trasforma le prospettive aeree in esperienze immersive a livello del terreno, migliorando applicazioni come la guida autonoma e il gaming con ambienti 3D più realistici. Il sistema combina una rappresentazione 3D con un modello di generazione coerente per garantire immagini omogenee e geometricamente consistenti, anche in presenza di grandi lacune visive. Le immagini generate offrono una coerenza spaziale e temporale avanzata, migliorando la comprensione e la visualizzazione delle scene a partire da prospettive aeree. Skyeyes affronta la mancanza di dataset pubblici contenenti immagini geo-allineate di vista aerea e terrestre creando un ampio dataset sintetico grazie all’utilizzo di Unreal Engine.
Il mercatino dell’open-source

Tre progetti open-source con codice per il mese di novembre.
Convert Archive - Uno script Python per convertire il proprio archivio di X (Twitter) in un set di dati di addestramento per la messa a punto di un modello linguistico basato sulla propria personalità (o qualunque altro use case ci venga in mente). Estrae anche tutti i tweet, thread e media in file markdown in modo che si possano leggere facilmente o utilizzare per un sito web.
Twenty - Un’alternativa open-source a Salesforce, dotata di potenti funzionalità che garantiscono un pieno controllo e aiutano a gestire la propria attività in modo efficiente. L'applicazione trae ispirazione da Notion, uno strumento noto per la sua interfaccia intuitiva e le vaste possibilità di personalizzazione.
RTranslator - App di traduzione in tempo reale offline per Android. Ci si connette a qualcun’altro che ha l'app, si collegano le cuffie, si mette il telefono in tasca e si conversa come se l'altra persona parlasse la stessa lingua.
Come usare al meglio il nuovo Editor di Midjourney
Lo scorso mese Midjourney ha lanciato il suo attesissimo Image Editor che per la prima volta consente di caricare e modificare immagini esterne.
Questo nuova interfaccia è dotata di alcune funzionalità già note, come la modifica di alcune aree di un’immagine tramite Inpainting e il ridimensionamento tramite Outpainting, ma la vera novità è il Retexturing, una loro versione di ControlNet che permette trasformare lo stile delle immagini mantenendone la struttura di base.

Al momento della pubblicazione di questo articolo, l'accesso al nuovo Editor è limitato ad utenti selezionati. Per poterlo utilizzare, bisogna rispettare almeno uno di questi tre criteri:
Aver generato almeno 10.000 immagini
Avere un abbonamento annuale di qualunque livello
Aver mantenuto un abbonamento mensile per almeno 12 mesi consecutivi
Questa fase di rilascio graduale serve principalmente a testare un nuovo sistema di moderazione parzialmente automatizzato che, spoiler, funziona malissimo e tende spesso a bloccare molte generazioni perché ne fraintende il senso. Ma a parte questi inconvenienti, che verranno certamente risolti nel futuro prossimo, lo strumento risulta molto interessante e divertente, migliorando significativamente l’esperienza complessiva nell’utilizzo di Midjourney e le nostre possibilità creative.
Panoramica del nuovo Editor
Appena entriamo nell’Editor, la prima cosa che noteremo saranno i due grossi tasti per importare un’immagine esterna. Con quello blu possiamo utilizzare un link che riporta all’immagine, ad esempio cercando su Google ciò di cui abbiamo bisogno per poi fare: tasto destro —> “Copia l’indirizzo dell’immagine”, così da non doverla salvare sul nostro dispositivo per importarla nell’Editor.
Al contrario, con il tasto arancione possiamo caricare un’immagine direttamente dal nostro device, a patto che non superi i 10 MB di peso.

In alto a sinistra, possiamo scegliere tra le classiche funzionalità dell’Editor, ovvero la modifica di singole aree dell’immagine (Inpainting) selezionabili tramite un pennello e guidabili con un prompt, e l’aggiunta di nuove informazioni intorno all’immagine (Outpainting) tramite ridimensionamento o modifica dell’aspect ratio.
O utilizzare il nuovo Retexture (ControlNet) per modificare lo stile e il contenuto di un’immagine mantenendo inalterata la sua struttura di partenza, un po’ come avere dei contorni che possiamo riempire a piacimento. Tutte queste funzionalità possono anche essere mischiate tra loro per creare dei workflow più complessi.
Un ottimo metodo per aumentare la precisione e l’efficacia dei nostri prompt quando utilizziamo Retexute o cerchiamo di modificare singole aree di un’immagine esterna, è quello di descriverla nella sua interezza aggiungendo le giuste parole chiave per rendere effettiva la modifica. Per evitare di preparare noi una descrizione, Midjourney ci ha fornito il pulsante "Suggest Prompt", che utilizza la sua funzionalità “Describe” per preparare una bozza di prompt che possiamo utilizzare come base.

Più sotto, troviamo dei tasti per modificare l’aspect ratio di un’immagine, trasformandola ad esempio da orizzontale a verticale, da quadrata a orizzontale, da verticale a quadrata, e così via. Seguiti da un pulsante per eseguire un ingrandimento dell’immagine di 2x e trasportarla nella galleria insieme a tutte le altre, o salvarla direttamente sul nostro dispositivo.
Qui va fatto notare che, fin tanto che lavoriamo un’immagine all’interno del nuovo Editor, questa rimarrà in “Stealth Mode” anche se disponiamo di un abbonamento “Basic” o “Standard”. Per chi non lo sapesse, questa modalità impedisce che una nostra immagine finisca in home page nella sezione Esplora.

In alto a destra troviamo poi i tasti “View All” e “New”, che servono rispettivamente a vedere la galleria di tutti i lavori che abbiamo fatto con l’Editor e ad aprire un nuovo progetto per iniziare a modificare un’altra immagine.

Consigli pratici
Il nuovo Editor di Midjourney è compatibile con tutti i suoi parametri, che vanno sfruttati al meglio. Si può usare Character Reference per modificare il volto di un personaggio, Style Reference per guidare lo stile delle generazioni, Image Reference per influenzare il contenuto, Personalize per aggiungere un po’ della propria personalità, Chaos e Weird per ottenere delle immagini più variegate e insolite.
In tal senso, non ci sono dei veri e propri limiti, a parte la moderazione automatica.
Uno degli aspetti più importanti di Midjourney, e del suo nuovo Editor, è la scrittura dei prompt. La chiarezza e la precisione possono fare la differenza tra riuscire a ottenere esattamente ciò che abbiamo in mente e abbandonare l’idea dopo diversi tentativi falliti. Ad esempio, nel momento in cui vogliamo modificare una porzione della nostra immagine, o cambiarne lo stile con Retexture, descrivere l’intera scena al posto del singolo elemento può portare a dei risultati molto più interessanti.
Nell’esempio qui sotto, possiamo vedere come il mio tentativo di rendere fotorealistico il classico dipinto Viandante sul mare di nebbia, non sia andato a buon fine utilizzando un prompt semplicissimo come “photo realism”.

Al contrario, con un prompt più descrittivo ed elaborato come “Photography of a man in a dark green suit and black tie, with short blond hair, stands on the top of a foggy mountain, holding a walking stick. He looks at the distant landscape with rocks covered by white clouds” ha portato a dei risultati sorprendenti.

Un buon prompt è la chiave per ottenere degli ottimi risultati anche quando vogliamo usare l’Editor per modificare un’immagine esterna. Ad esempio, se vogliamo inserire dei nuovi elementi all’interno di una vera fotografia, i prompt molto semplici potrebbero rivelarsi totalmente inefficaci.
Nel prossimo esempio si può notare come il prompt “UFO” non abbia comportato alcuna modifica al cielo di questa fotografia.

Mentre un prompt molto più elaborato come “A giant UFO is flying in the blue sky of the Italian city, passing over the historic building” ha portato il modello ad aggiungere effettivamente l’elemento richiesto nella foto.

Il segreto per sfruttare al meglio Midjourney, così come il suo Image Editor e molti altri strumenti per la generazione d’immagini è l’iterazione continua. Combinare l’Editor con la retexturizzazione e sperimentare con stili diversi senza temere di dover riscrivere più volte i propri prompt per migliorare il risultato finale, è tra le chiavi per ottenere dei risultati estremamente soddisfacenti con questo strumento.
Le nuove funzionalità dell’Editor offrono infinite possibilità creative, che si tratti di trasformare dei bozzetti in immagini complesse e dettagliate, creando ambientazioni uniche o dando vita a fumetti dinamici. Con un po’ di pratica, puoi ottenere risultati sorprendenti e personalizzati.
Gli Androidi sono tra noi
Gli androidi hanno affascinato l'immaginario collettivo per decenni, trovando spazio nelle opere di fantascienza e incarnando il desiderio umano di creare macchine simili a noi. Ma cos'è realmente un androide?
Nella letteratura, sono definiti come sofisticati robot antropomorfi, progettati per imitare l'aspetto e il comportamento umano in tutto e per tutto. Dai romanzi di Isaac Asimov ai capolavori del cinema come Blade Runner, gli androidi rappresentano il connubio tra tecnologia e umanità, permettendoci di esplorare i limiti etici e filosofici del rapporto tra uomo e macchina.
La startup polacca Clone Robotics si inserisce in questo contesto non come narratore di storie futuristiche, ma come protagonista di una rivoluzione tecnologica già in atto, che vuol trasformare la fantascienza in realtà tangibile.
Clone Robotics è partita con lo sviluppo di una mano robotica tra il 2019 e il 2023, un progetto che ha rappresentato il primo passo verso la creazione di androidi completi. Questa mano è stata progettata per replicare l'aspetto di una vera mano umana, e per comprendere la versatilità unica nel nostro ambiente urbano. Tutto ciò che ci circonda, dai nostri smartphone alle maniglie delle porte, è stato progettato per adattarsi alle mani umane, e Clone Robotics ha capito l'importanza di creare un dispositivo capace di interagire con questi oggetti con la nostra stessa abilità.
Una caratteristica unica della mano di Clone è la sua pelle trasparente, che non è solo un dettaglio estetico, ma una scelta ingegneristica volta a mostrare il complesso funzionamento dei muscoli artificiali al suo interno. Questa trasparenza permette di osservare gli intricati movimenti dei muscoli sintetici in azione, rendendo evidente la sofisticazione del loro design.
Il cuore di queste innovazioni è rappresentato dai muscoli sintetici, ispirati al concetto di muscolo McKibben: tubi di rete con palloncini interni. Quel design sperimentale è stato poi ridefinito, arrivando a sviluppare dei muscoli che si contraggono applicando una corrente elettrica. Invece di affidarsi a pompe esterne, il team ha deciso di riempire il palloncino con un fluido e introdurre un elemento riscaldante. Applicando la corrente, il fluido bolle, causando la contrazione del muscolo. Una soluzione apparentemente semplice, ma estremamente ingegnosa.
Oltre ai muscoli, la mano robotica vanta una struttura scheletrica simile a quella umana, con 27 gradi di libertà e movimenti complessi del polso e del pollice, offrendo una destrezza paragonabile alla nostra. Il tutto è alimentato da un sistema idraulico sofisticato, che utilizza una pompa d'acqua da 500 watt e una rete di 36 valvole, ognuna dotata di sensori di pressione. Per garantire precisione nei movimenti, dei sensori magnetici forniscono feedback in tempo reale sulla dinamica delle giunture.
Dopo la mano, è arrivato anche il torso umanoide, presentato poche settimane fa con un video su YouTube, è dotato di sofisticate capacità bimanuali che gli permettono l'uso simultaneo e coordinato di entrambe le braccia. Questa caratteristica amplia significativamente le funzionalità del robot, permettendogli di eseguire compiti complessi che richiedono un alto grado di coordinazione e destrezza. L'uso efficace di entrambe le braccia è essenziale per raggiungere prestazioni simili a quelle umane in vari scenari, come la manipolazione di oggetti delicati, operazioni di assemblaggio intricate e assistenza in procedure mediche.
Un'altra caratteristica distintiva del torso umanoide di Clone Robotics è il suo avanzato design articolare: gomiti attuati, colonna cervicale, spalle antropomorfe, muscoli del collo, questo design offre un range di movimenti simili a quelli dell'anatomia umana. Questa precisione biomeccanica, ottenuta grazie a studi approfonditi di biomimesi, migliora le capacità di movimento del robot e gli permette di navigare in ambienti complessi, svolgendo compiti con un grado di agilità mai vista prima nella robotica umanoide.
Per gestire efficacemente i muscoli artificiali, viene utilizzato un sofisticato sistema di valvole a matrice, che riduce la necessità di componenti ingombranti, risultando in un design più compatto ed efficiente. Il sistema di valvole offre diversi vantaggi, tra cui una maggiore reattività e agilità, un miglior controllo dei singoli gruppi muscolari, un peso complessivo ridotto e una maggiore efficienza energetica.
Il sistema opera a una potenza massima di soli 200 watt e questo offre numerosi vantaggi, tra cui una riduzione dell'impatto ambientale, costi operativi inferiori e un'autonomia maggiore con le batterie, che richiederanno meno cicli di ricarica a parità di ore lavorate.
La tecnologia di Clone Robotics offre molte applicazioni, dalle protesi avanzate ai sistemi di teleoperazione che richiedono un controllo certosino. L'azienda sta lavorando anche allo sviluppo di androidi superintelligenti, dotati di IA e di una struttura muscoloscheletrica simile a quella umana, puntando a espandere la gamma di compiti che questi robot possono svolgere. L'azienda vuol rimanere attiva anche nella progettazione di mani robotiche sempre più realistiche e reattive, continuando a innovare il settore delle protesi avanzate.
L'obiettivo finale è integrare l'intelligenza artificiale per operazioni autonome, portando la collaborazione tra umani e robot a un nuovo livello in diversi settori industriali e della vita comune. Con il continuo evolversi della tecnologia e la riduzione dei costi di produzione, è sempre più plausibile aspettarsi che questi androidi inizino a camminare per le strade e convivere con noi nelle nostre abitazioni, supportando una popolazione globale sempre più anziana e bisognosa di assistenza.
Eterna AI Agency: il futuro del modelig
L’intervistata del sesto numero di Tales from the Latent Space è Nina Khaldi, fondatrice di Eterna AI Agency e pioniera nell’uso dell’intelligenza artificiale per la moda e il design. In questa conversazione, Nina ci racconta di come la necessità abbia trasformato il suo rapporto con la tecnologia, portandola a sviluppare progetti visionari come Ace Nova, una modella AI cosmopolita, e Baby Love, un’entità fluida nata dalla metamorfosi artistica. Attraverso Eterna Agency, Nina dà vita a un nuovo concetto per l’industria del fashion, più digitale e meno legato alla realtà fisica, che fonde sostenibilità, estetica e innovazione.
Questa intervista si colloca nella più ampia visione del magazine di offrire uno spazio unico ai creativi di tutto il mondo che utilizzano la tecnologia come ampliamento delle loro possibilità espressive. A partire dall'anno prossimo, questa rubrica includerà anche interviste a ingegneri, programmatori e matematici, per diversificare i contenuti e promuovere l'idea che la creatività non appartiene solo ad artisti e designer, ma che si tratta di un raffinato processo di problem solving intrinseco alla natura dell’essere umano e alle sue capacità cognitive.

Iniziamo con la domanda di rito del magazine: Ci descriveresti il tuo rapporto con la tecnologia?
Il mio rapporto con la tecnologia è sempre stato legato alla creatività, ma da ragazza ero abbastanza lontana da tutto ciò che fosse tecnologico. Ancora oggi faccio fatica con cose tipo il televisore o i telecomandi, che mi irritano.
Ho iniziato a usare Photoshop per necessità economiche in realtà, sembra strano ma il materiale accademico in forma fisica può costare follie. Studiavo pittura tradizionale all’Accademia di Belle Arti, ma a un certo punto mi sono trasferita a Berlino per un percorso personale, continuando a preparare gli esami per l’università. A Berlino, però, non avevo accesso ai laboratori dell’Accademia e nemmeno abbastanza soldi per comprare i materiali da disegno e pittura, che sono super costosi. Quindi ho iniziato a lavorare in digitale, usando il mio PC con una versione craccata di Photoshop, che era l’unico strumento che avevo.
Da lì si è aperto un mondo: il digitale è diventato il mio ambiente naturale, e ora è il cuore del mio lavoro. Da quasi dieci anni sono motion designer, e non potrei immaginare la mia vita senza questa svolta.
Per me la tecnologia è uno strumento per creare, esplorare e divertirsi. Lo stesso vale per l’intelligenza artificiale: credo che possa essere un supporto incredibile per spingere la creatività e lasciarsi sorprendere da ciò che si può realizzare.
Chi è Ace Nova?
Nel 2023 ho iniziato a esplorare gradualmente il mondo dell'intelligenza artificiale. Riconoscendone il potenziale, ho deciso di lanciare un progetto per mostrarne le capacità, aprendo il profilo Instagram di Ace Nova (@Only.A.c.e). Qui mi sono concentrata sullo sviluppo di un modello virtuale coerente, creando immagini e scenari artistici e orientati alla moda.
Per certi versi, Ace l’ho costruita un po’ su misura, riflettendo gusti simili ai miei, la stessa provenienza e persino un percorso lavorativo affine. All’inizio, l’idea era di renderla ancora più realistica: condividevo nelle stories i miei luoghi e la mia quotidianità, pensando di darle una vita quasi parallela alla mia.
Poi però mi sono detta: che noia la mia vita da non-influencer!
Così ho deciso di spaziare. E se possiamo spaziare, perché non farlo? Alcuni aspetti originali sono rimasti, ma lei si è evoluta moltissimo, diventando qualcosa di molto più libero e creativo. Ad oggi è una figura dinamica, un'innovativa modella AI che unisce l'eleganza classica a un'anima urbana. Modella virtuale italiana con base a Bruxelles, Ace è una creativa cosmopolita che ama la bellezza, l'arte e i ritmi travolgenti della musica elettronica.
Il suo stile è una fusione audace di sofisticazione senza tempo e sperimentazione moderna, ispirando innovazione e inclusività. A luglio siamo state citate nella tesi di laurea di una talentuosa studentessa, Benedetta Soregaroli, dell'ITS di Brescia, intitolata Moda, Showroom e IA: riflessi del nostro tempo. A settembre 2024 invece, Ace è stata una dei protagonisti della straordinaria esposizione "Light Vision" organizzata da Art Innovation a Times Square, New York. Attualmente è uno dei designer Brand Ambassador per RefabricAI, leader nelle soluzioni AI per i professionisti della moda, incarnando il suo spirito innovativo e la sua dedizione al mondo del design.
Purtroppo, il mondo dei social può essere davvero spietato (detesto Instagram). Il profilo di Ace è stato pesantemente penalizzato, e credo che i social non siano ancora pronti ad accogliere figure umane digitali. Tra segnalazioni ingiuste e l'etichetta "MADE WITH AI", i modelli digitali stanno subendo una grande ingiustizia da parte delle piattaforme.
Ma non preoccupatevi: Ace non si arrende.
E invece Baby Love?
Baby è nata diversi mesi dopo Ace, come un progetto personale molto più creativo. Stavo lavorando a una collaborazione sul tema della Metamorfosi con un’artista AI fortissima e specializzata proprio in questo concetto. Essendo un progetto così specifico, ho passato giorni a promptare e generare immagini, con risultati che erano sempre un po’ “off.” Finché, all’improvviso, è comparso questo essere dal nulla, e da lì è diventato un personaggio stabile che fa innamorare.
Baby è un’entità di un’altra dimensione: sempre modella, ma fluida nella sua essenza, capace di fondersi con materiali, forme e la natura stessa. Essendo nata da un progetto basato sulla metamorfosi, la sua capacità di unirsi a forme organiche e naturali la rende perfetta nel suo habitat estetico. È impossibile usarla come una semplice modella da copertina, letteralmente.
Credo fermamente che il mondo del modeling con l’IA rischi sempre più di scivolare nella logica del “veloce e facile,” puntando tutto sulla quantità e trascurando la qualità. Ma niente di davvero bello o ben fatto può essere semplice o immediato, e Baby ne è la prova. Con BabyLove, è possibile creare qualcosa di straordinario e autentico, trasformando il prompt in una tela bianca su cui riscrivere le regole. Per me è un gioco continuo: elevare la realtà, renderla fantastica e un po’ improbabile, spingendomi sempre oltre i limiti del prevedibile e del già visto.
Ad oggi Baby vive più per progetti specifici, di natura etica e ambientale.
Come nasce Eterna Agency? Raccontaci della tua visione a riguardo
Eterna è la mia bimba, amo e credo questo progetto incredibilmente. Più lo scopro, lo analizzo e lo sviluppo, più sento che è esattamente il posto in cui dovrei essere.
Eterna, come Ace, è nata dal lato più giocoso di questo percorso, ma ha rapidamente preso vita come risposta a un vuoto evidente. Quando ho iniziato con Ace, era impossibile trovare spazi per modelle AI che non fossero saturi di contenuti volgari e privi di qualità. Ancora oggi è frustrante vedere come la figura femminile AI venga spesso banalizzata e sfruttata. Non si tratta di moralismo, perché credo che l’erotismo vada esplorato, ma con gusto, creatività e rispetto. Ace non trovava il suo posto, così ho deciso di crearlo io, costruendo una community che oggi accoglie modelle AI uniche e creatori visionari del mondo della moda e del design.
Da questa idea è nato un vero team: la nostra social media manager e AI artist Melissa Debernardi @WhatIf.now, Diana Mota, fotografa di moda e Avatar designer nonché creatrice della nostra punta di diamante @Zoeysummer.sun, e Andrea Lettieri, il nostro web design e Flux AI expert. Senza di loro sarei persa.
“Siamo un’Agenzia Creativa Digitale specializzata nella produzione di contenuti visivi per i settori della moda e del design. Dalle modelle digitali personalizzate ai virtual brand ambassador, fino a servizi fotografici di nuova generazione, diamo vita al tuo brand attraverso l’innovazione alimentata dall’IA e un’estetica audace e sofisticata.
In Eterna ridefiniamo il modo in cui i brand raccontano la loro storia nell’era digitale, mescolando creatività e tecnologia per creare contenuti visivi audaci, innovativi e sostenibili. Trasformiamo visioni uniche in realtà, offrendo soluzioni che uniscono arte e innovazione all’avanguardia. Realizziamo realtà visive completamente personalizzabili, di grande impatto e progettate per ridurre al minimo l’impronta ambientale. Immaginiamo un futuro per la moda libero dagli sprechi e dalla sovrapproduzione. Per noi, la produzione fisica non è il punto di partenza, ma l’atto finale: un processo consapevole e mirato, riservato a ciò che è davvero essenziale. Al centro di tutto rimane l’umanità, che continua a essere la forza motrice della creatività, elevata – e mai sostituita – dalle tecnologie avanzate.
La nostra visione? Un’eleganza visiva sostenibile e innovativa, che celebra responsabilità, bellezza e progresso.
Questo è il vero lusso che il futuro merita."
Inizia così il nostro sito e non potrei spiegarlo meglio.
Questo testo non è solo una presentazione ma un vero e proprio manifesto.
Cosa manca all'AI modeling per prendere piede?
Manca un po’ di coraggio e, secondo me, anche delle regolamentazioni necessarie per mantenere un giusto equilibrio con il reale. Mi spiego meglio: immagino un mondo in cui l'AI supporti la produzione digitale nella fase di pre-produzione, ma lascerei l’esperienza di una sfilata, ad esempio, alle modelle reali, magari affiancate da video o altre integrazioni digitali. È fondamentale mantenere il giusto spazio e la dignità per l’atto performativo. Serve equilibrio.
Vedo anche una certa mancanza di sensibilità estetica, parlando in generale, anche se ci sono moltissimi creatori straordinari. Però, quando al poco gusto si aggiunge un’anatomia imperfetta, l’effetto horror è praticamente garantito.
C’è poi appunto una questione tecnica. È vero che l'AI si sta evolvendo a velocità impressionante, ma c’è ancora molto da fare e da imparare prima di poter avere un controllo totale sugli strumenti. Ad oggi, ad esempio, applicare texture precise ai capi di abbigliamento è ancora una sfida, ma siamo davvero molto vicini a superarla.
Alle modelle AI non manca nulla; ai loro creatori, forse, un po’ di educazione visiva e competenze tecniche, ma alla fine stiamo tutti facendo del nostro meglio per migliorarci e superarci.
Quali sono secondo te i malintesi più comuni sul mondo fashion AI? C'è qualcosa che vorresti chiarire o spiegare meglio?
Purtroppo e per fortuna, quando si parla di AI si finisce inevitabilmente per affrontare temi di filosofia ed etica. La paura dell’uomo di essere sostituito dalle macchine si sta facendo più concreta che mai, e offrire servizi che non si limitano al supporto grafico ma includono veri e propri personaggi digitali può risultare, a molti, controverso e inquietante. Con Eterna, però, vogliamo sensibilizzare non solo a un uso etico dell’AI dal punto di vista visivo e responsabile sul piano sociale, ma anche far riflettere su quanto di ciò che abbiamo accettato come "normale" fino ad ora, a livello umano, non sia stato né giusto né sostenibile.
Prendiamo il caso degli influencer, ad esempio. Una persona reale che cambia tre magliette al giorno davanti a una webcam per promuovere brand diversi. Ragioniamo un attimo: per produrre una semplice maglietta bianca servono circa 2500 litri d’acqua, solo per la produzione, senza considerare tutta la filiera dietro. Ora moltiplichiamo questo per almeno tre cambi d’abito al giorno, ogni giorno, per anni, per ogni influencer che sceglie questa carriera. Stiamo parlando di sprechi colossali.
Dietro al mondo della moda c’è un enorme utilizzo di risorse e spreco che raramente viene discusso, nonostante sia la seconda industria più impattante a livello ambientale. Non possiamo continuare a ignorarlo.
Con l’intelligenza artificiale possiamo immaginare una strada alternativa, più sostenibile, che riduca questi sprechi senza rinunciare alla creatività e alla bellezza, trovando un equilibrio tra innovazione e responsabilità.
Questo ad esempio è uno dei Nostri punti di forza e mio preferito, sempre preso dal nostro sito:
"Creatività Ecosostenibile
Eliminando la necessità di voli, set fisici e spreco di materiali, ti aiutiamo a ridurre la tua impronta di carbonio offrendo al contempo immagini eccezionali."
Un’altra questione delicata riguarda l’aspetto lavorativo: “Quante persone perderanno il lavoro?” È una domanda legittima, ma va bilanciata con una realtà spesso trascurata: l’AI non solo elimina, ma crea anche nuove opportunità. Stiamo forse facendo gli stessi lavori dell’epoca dell’Impero Romano? Non credo, e nemmeno quelli dei tempi dei nostri nonni. La società si evolve, e lo stesso vale per la tecnologia, che segue sempre le necessità dell’uomo, non il contrario.
Con il progresso tecnologico, si ridistribuiranno posizioni lavorative e si creeranno nuovi ruoli, probabilmente più sostenibili e rispettosi. E parliamoci chiaro, molte delle posizioni lavorative che temiamo l’AI possa sostituire sono le più agevolate, la punta di un iceberg luminoso. Ma il mondo della moda e degli eventi, per esempio, è pieno di mansioni brutali, mal pagate e prive di rispetto per la dignità umana.
Dobbiamo davvero proteggere posti di lavoro che spesso non offrono condizioni di vita e lavorative accettabili? O forse è il momento di immaginare nuovi ruoli che garantiscano maggiore qualità della vita, sicurezza e soddisfazione?
La tecnologia, ricordiamolo, è un supporto, non un ostacolo.
Più in generale, per il mondo AI non voglio essere né troppo ottimista né ingenua. Quello che mi preoccupa davvero dell’uso dell’AI è il suo impiego in ambito militare e legale. La creazione di immagini, voci e video sempre più realistici rende sempre più difficile distinguere ciò che è autentico da ciò che non lo è, e questo può avere conseguenze enormi, ad esempio nel sistema giudiziario. Quanto all’uso militare, preferisco non pensarci neanche, perché sì, quello mi spaventa davvero, altro che una modella AI che sfila su nuvole rosa.
Abbiamo parlato di molte personalità digitali, ma poco dell'essere umano che c'è dietro a tutto questo. Ti andrebbe di raccontarci qualcosa su di te, Nina?
Mi sono laureata in Belle Arti presso l'Accademia di Bologna, nel dipartimento di Arti Visive, e ho completato il mio percorso accademico all'estero frequentando il corso di illustrazione presso l'UWE (University of the West of England) a Bristol. Tornata in Italia, ho seguito un corso di specializzazione in Grafica Digitale allo IED di Milano, avviando contemporaneamente la mia carriera come Motion Designer. Ho lavorato inizialmente in Italia, per poi trasferirmi in Belgio nel 2021, continuando nel settore degli eventi come visual e motion designer.
Ora ho ufficialmente lanciato il progetto Eterna Agency e sto frequentando il corso di specializzazione in Fashion Marketing presso il CAD (College of Art and Design di Bruxelles), portando avanti in parallelo il lavoro... insomma, non ci si ferma mai!