


I Pensatori del Nuovo Mondo
Pensare al futuro per superare i limiti del presente, il pensiero è la materia prima di un mondo ancora in divenire


Anche febbraio è andato, ed è stato un mese davvero straordinario, che ci fa percepire l’incredibile accelerazione del Nuovo Mondo, in cui tutto può succedere nel giro di pochissimo tempo. Progressi che una volta avrebbero richiesto anni, se non decenni di lavoro, nel 2025 avvengono nel giro di pochi mesi, a volte settimane. Siamo appena all’inizio di un lungo viaggio che ci traghetterà verso un’epoca di abbondanza diffusa come non si era mai visto in tutta la storia dell’umanità.
Solo negli ultimi 30 giorni, si sono susseguiti così tanti annunci, aggiornamenti, novità, scoperte e ricerche da non riuscire nemmeno a seguirli tutti con la giusta attenzione. Da quando è iniziato l’anno nuovo, sono successe quasi più cose che in tutti i dodici mesi precedenti e, se ci pensiamo bene, questa cosa ha dell’incredibile.
Anche considerando solo i settori dell’IA e della robotica, che sono i principali sui quali riesco a focalizzarmi con le attuali risorse che ho a disposizione per scrivere questo magazine mensile, la quantità di notizie da coprire è più o meno equivalente ai volumi d’acqua trasportati da un fiume in piena. Per questo mese ho fatto davvero molta fatica ad addentrarmi nel rumore informativo per separare le novità veramente interessanti dalle informazioni tutto sommato trascurabili, al punto che la rubrica “Avvenimenti del mese” di questo numero è la più lunga che abbia mai dovuto scrivere da quando ho iniziato questo progetto a giugno 2024.
Questa nuova pubblicazione di Tales from the Latent Space si rivelerà quindi molto più ricca e approfondita del solito.
Approfitto di questo spazio introduttivo anche per ringraziare tutti i nuovi iscritti al magazine, siamo praticamente arrivati a 600! E ci tengo sempre a ribadire che voi siete i veri Pionieri del Nuovo Mondo, perché la vostra curiosità è ciò che alimenta questo progetto e mi dà la forza di continuare a dedicare oltre 40 ore mensili a questo progetto, conscio del fatto che andremo molto lontano e tutto questo diventerà il più grande punto di riferimento per gli appassionati di tecnologia in Italia.
Per tutte le nuove fantastiche persone giunte qui oggi, vi faccio una brevissima presentazione del progetto, del quale forse sapete ancora poco.
Anche se giunge a voi in forma di newsletter, questo è un vero e proprio magazine digitale, composto da diverse rubriche ricorrenti e da articoli di approfondimento.
Al suo interno potete trovare i contenuti più disparati, pensati per suscitare l’interesse di un pubblico vasto e variegato:
Una lunga risposta a una semplice domanda - Questa è la rubrica che apre ogni numero di Tales from the Latent Space (per gli amici Tales). È pensata per gli utenti più curiosi e fornisce spiegazioni molto approfondite, ma accessibili, a domande tipo Che cos’è un fine-tuning?, Che cos’è lo spazio latente?, Che cos’è l’AGI?, Che cos’è un LoRA? e così via. Tutte le informazioni contenute in questi approfondimenti vengono diligentemente ricontrollate e verificate in più passaggi, per assicurare una precisione enciclopedica ma con un linguaggio che risulti il meno tedioso possibile.
News degli ultimi 30 giorni (circa, in base a quanto dura il mese) accuratamente selezionate per sfuggire al rumore informativo.
L’edicola dei paper scientifici, una rubrica per i più curiosi che vogliono saperne un po’ di più su come funziona il Nuovo Mondo. Ogni mese, trovate tre pubblicazioni più o meno recenti che ho selezionato con gran criterio.
Il mercatino dell’open-source, una rubrica per i più smanettoni, che presenta sempre tre progetti interessanti con codice già pubblicato.
Fino a tre articoli di approfondimento (in questa fase del progetto, la lunghezza e la quantità di articoli è variabile di mese in mese) sui temi più disparati legati al mondo della tecnologia.
Un’intervista esclusiva a persone creative che stanno facendo qualcosa di eccezionale sfruttando la tecnologia per ampliare le loro possibilità creative.
L’angolo degli annunci, una nuova rubrica “di servizio”, che prima era inglobata in questa prima parte introduttiva ma che da questo numero diventa la chiusura di ogni pubblicazione. Al suo interno trovate annunci legati al progetto, i servizi offerti dall’azienda che sto costruendo, contatti e risorse per supportarci.
Ultima cosa: per quale motivo dico sempre che questo magazine esplora il rapporto tra creatività e tecnologia? Qualcuno che segue tutto questo da un po’ di tempo potrebbe essersi posto questo quesito, faticando a trovare risposte.
Data la descrizione del progetto, ci si potrebbe aspettare un focus molto più mirato sul design, sull’arte e su tutto quello che viene generalmente considerato “creativo”.
Ma raramente è stato così e gli articoli di approfondimento su queste tematiche sono sempre meno. Come mai? Il motivo è molto semplice e risiede nella definizione stessa di creatività (che un giorno spiegherò ampiamente nella rubrica di apertura).
Quando mi riferisco a questo termine, cerco sempre di intenderlo nel modo più ampio possibile, ed è per questo che ritengo che sia legata a doppio filo con la tecnologia. Un pittore o un compositore musicale non hanno nulla di più creativo rispetto a un ingegnere, un matematico o un ricercatore di microbiologia. La creatività si esprime in una vasta moltitudine di forme differenti e questo progetto vuol tentare di farle emergere tutte per combattere lo stereotipo secondo cui è creativo solo chi lavora in settori artistici, perché non è affatto così.
La vera creatività, per emergere e svilupparsi, ha bisogno di contaminarsi con quante più discipline possibili e la tecnologia è un vettore perfetto per fare ciò.
L’introduzione è stata più lunga del previsto, e il nostro treno è in arrivo al primo binario. Allontanarsi dalla linea gialla!

Cosa si intende con il termine Open-Source?
Quando parliamo di open-source possiamo riferirci a una vera e propria filosofia che ha rivoluzionato il modo in cui concepiamo, creiamo e condividiamo la conoscenza. Immaginate una grande libreria in cui ogni libro può essere curato da diversi autori, ognuno dei quali ha il diritto di leggere, studiare, fare una copia o una rivisitazione, annotare, scrivere, modificare e aggiungere nuovi capitoli. Ogni passaggio arricchisce il testo originale, creando un’opera collettiva in continua evoluzione.
Non si tratta più di custodire segreti industriali per mantenere un vantaggio esclusivo, ma di mettere a disposizione tutti gli strumenti necessari affinché ogni contributo possa integrarsi, migliorare il lavoro altrui o dare vita a qualcosa di nuovo e dinamico.
Questa è l’essenza dell’open source: un patrimonio di conoscenze che si alimenta della collaborazione e del contributo di una vasta moltitudine di menti diverse.
Un movimento legato al concetto di trasparenza, collaborazione e condivisione che va ben oltre l’ambito della programmazione, interessando anche il mondo fisico degli hardware, la ricerca accademica, l’arte e il design.

Un Mondo Senza Barriere
Nel settore tradizionale dello sviluppo software, il codice viene custodito gelosamente da aziende e istituzioni, in quanto segreto industriale. Al contrario, l’open-source nasce dal desiderio di abbattere le barriere tra sviluppatori e utenti, permettendo a chiunque di studiare, modificare e distribuire il codice. Questa apertura ha permesso sia una più rapida diffusione delle innovazioni tecnologiche, che la creazione di community globali che collaborano senza vincoli aziendali, geografici o culturali.
Negli anni ’70 e ’80, le comunità di hacker e pionieri dell’informatica iniziarono a condividere liberamente il loro lavoro, alimentando una nuova cultura basata sulla trasparenza e la verificabilità dell’innovazione. Con l’avvento del movimento GNU (GNU's Not Unix, un acronimo ricorsivo che evidenzia la sua funzionalità simile a Unix pur essendo un'alternativa completamente libera), guidato da Richard Stallman, e la successiva nascita di Linux da parte di Linus Torvalds, l’open-source si consolidò come un modello non solo di sviluppo, ma anche di etica tecnologica.
Queste iniziative hanno dimostrato che la collaborazione aperta può portare a prodotti affidabili e di qualità, in grado di competere con le soluzioni proprietarie.
Uno degli aspetti fondamentali del software open source è la sua licenza, che definisce i diritti e i doveri di chi utilizza, modifica e ridistribuisce il codice. Licenze come la GNU General Public License (GPL), la MIT License, o la Apache License stabiliscono un contratto di fiducia tra sviluppatori e utenti, garantendo che il software rimanga aperto e accessibile a tutti. Questo sistema giuridico funziona come il regolamento di un grande mercato in cui ogni partecipante è libero di innovare, purché rispetti le regole condivise.

Il Caso Linux: Una Rivoluzione Silenziosa
Il sistema operativo Linux è il più famoso esempio di successo del mondo open-source. Nato come un progetto collaborativo e gratuito, Linux è diventato il pilastro di innumerevoli infrastrutture: server aziendali, dispositivi mobile, sistemi embedded - una buona parte del nostro mondo si basa su Linux o altri sistemi da esso derivati.
Nel 1991, un giovane studente finlandese dell’Università di Helsinki, Linus Torvalds, intraprese il progetto di creare un kernel che potesse funzionare su un PC compatto. Torvalds intendeva realizzare un sistema in grado di sfruttare l'hardware a sua disposizione, ma soprattutto di permettere agli utenti di avere il controllo completo sul software. Il 25 agosto 1991, Torvalds pubblicò la prima versione del kernel Linux su un nuovo gruppo Usenet, invitando altri programmatori a testarlo e a contribuire al suo sviluppo. Questa prima versione, sebbene rudimentale e priva di molte funzionalità moderne, rappresentò la scintilla che avrebbe acceso una rivoluzione.
Ciò che rese il progetto di Torvalds così speciale fu la sua decisione di rilasciare il kernel sotto la licenza GNU GPL. Combinando il suo lavoro con il software GNU già sviluppato da Stallman, nacque un sistema operativo completo, noto oggi come GNU/Linux. Questa sinergia tra il kernel di Linux e gli strumenti GNU formò la base per una piattaforma versatile, in grado di adattarsi a numerosi contesti informatici.
La sua storia è una testimonianza del potere della collaborazione: migliaia di sviluppatori da tutto il mondo hanno contribuito al suo sviluppo, rendendolo una piattaforma robusta, sicura e flessibile. Il modello open-source favorisce un’innovazione esponenziale, da cui può beneficiare l’intera umanità. Quando un codice è pubblico, ogni bug può essere individuato e corretto da una community globale, rendendo i software più sicuri e in costante evoluzione.

La Trasformazione del Mondo Fisico
Il concetto di open-source non si limita al software, ma si estende anche all'hardware, inteso come l’insieme dei progetti che rendono accessibili le specifiche tecniche, i file CAD, i diagrammi elettrici o i firmware che controllano il funzionamento dei dispositivi. L'obiettivo è consentire a chiunque di studiare, modificare, riprodurre e migliorare i progetti hardware, creando così un ecosistema collaborativo che favorisce l'innovazione, replicando nel mondo fisico il successo dei software aperti. Progetti come Arduino, RepRap, Raspberry Pi e poi l’avvento della stampa 3D hanno aperto la strada a una nuova generazione di creatori appassionati detti maker, ingegneri e designer che possono sperimentare liberamente con l’elettronica e la meccanica.
Rispetto al software, con l’hardware aumenta la complessità, perché oltre ai file di progettazione bisogna gestire anche i componenti fisici, le specifiche di assemblaggio, gli eventuali componenti alternativi e le considerazioni sui costi di produzione. Per essere considerato effettivamente open, l'hardware deve rilasciare tutti i file e i progetti necessari per la sua realizzazione – incluse schede, layout dei circuiti stampati (PCB), disegni meccanici con eventuali file per la stampa 3D e, in molti casi, anche il firmware necessario al funzionamento del dispositivo.
Immaginate un laboratorio dove ogni progetto, ogni schema elettrico e ogni disegno tecnico è disponibile per essere studiato, modificato e migliorato. Questa è la filosofia dell’open source applicata al mondo hardware. In condizioni normali, la progettazione di un dispositivo fisico richiede risorse ingenti e competenze specialistiche, ma grazie alla condivisione delle informazioni e alla collaborazione globale, anche i piccoli innovatori possono contribuire alla creazione di tecnologie rivoluzionarie.
La vera e propria nascita del mondo hardware open-source può essere identificata nell’anno 2005, grazie all’avvento di progetti pionieristici come RepRap, un'iniziativa che ha rivoluzionato il mondo della stampa 3D, creando una prima stampante che produceva da sé la maggior parte dei suoi stessi componenti. Questo dispositivo autoreplicante dava la possibilità, a chiunque disponeva di una piccola somma di denaro, di avere a disposizione un piccolo sistema produttivo con cui poter creare gli oggetti di cui si necessita per la vita di tutti i giorni.
Nello stesso anno nasce Arduino, che ha introdotto il concetto di microcontrollore facilmente programmabile e personalizzabile, accompagnato da un ecosistema di shield (accessori hardware) e una community che è crescita rapidamente a livello globale. Con Arduino si possono realizzare piccoli dispositivi elettronici come controllori di luci, di velocità per motori, sensori di ogni tipo, automatismi per il controllo della temperatura e dell'umidità e molti altri progetti che utilizzano sensori, attuatori e comunicazione con altri dispositivi. La scheda è abbinata a un semplice ambiente di sviluppo integrato per la programmazione del microcontrollore. Tutto il software e gli schemi circuitali sono distribuiti con licenze open-source.
Allo stesso modo, nel 2012 entra in gioco anche il Raspberry Pi, che pur non essendo completamente open-source a livello di alcuni componenti (come il chip Broadcom, che rimane proprietario), ha reso estremamente popolari le schede a basso costo e ha ispirato innumerevoli applicazioni educative, hobbistiche e industriali.
La sinergia tra hardware e software open-source ha reso possibile una prototipazione rapida ed economica. Con le stampanti 3D domestiche e i circuiti integrati è possibile passare da una buona idea a un prototipo funzionante in tempi record. Questa democratizzazione della produzione sta abbattendo le barriere d’ingresso, consentendo a chiunque di sperimentare, innovare e apprendere nuove competenze.

Conclusioni non banali
La filosofia open-source ripensa dalle fondamenta il concetto classico di proprietà intellettuale, mettendo in discussione l'idea che il valore di un'innovazione risieda nella sua segretezza o nella sua esclusività. Condividere volontariamente i dettagli tecnici e progettuali significa abbandonare il paradigma in cui il vantaggio competitivo si basa principalmente sul mantenimento di informazioni riservate. In questo nuovo contesto, il valore non è più attribuito a un'idea in quanto tale, ma alla capacità di combinare, rielaborare e migliorare continuamente le conoscenze, senza contare la possibilità che un sistema aperto diventi uno standard globale.
In un mondo in cui le informazioni sono ampiamente accessibili, l'innovazione si alimenta della sinergia tra diverse fonti di sapere. La condivisione dei progetti consente a sviluppatori, ingegneri, studenti, appassionati e imprenditori di prendere spunti da soluzioni già collaudate, adattarle alle nuove esigenze e integrarle in modelli di business innovativi. Questo approccio dinamico accelera il progresso tecnologico, stimolando anche la creazione di soluzioni più robuste e flessibili, capaci di evolversi in risposta ai cambiamenti del mercato.
L'adozione di questo modello ha avuto un impatto profondo in settori emergenti come il Web3 e l'Intelligenza Artificiale aperta, dove l'accesso libero ai dati e agli algoritmi favorisce la nascita di piattaforme e applicazioni innovative. Le aziende che adottano questo approccio sono incentivate a creare modelli di business che bilancino l'accesso al sapere con le necessità economiche di investimento, sviluppo e manutenzione.
Da questo punto di vista, la proprietà intellettuale diventa un meccanismo strutturato che favorisce la condivisione e la collaborazione, piuttosto che un semplice strumento di esclusività. In tal senso, le licenze open-source stabiliscono regole chiare su come il materiale tecnico possa essere utilizzato e modificato, senza eliminare l’irrinunciabile incentivo economico per chi investe nella creazione di nuove tecnologie.
Avvenimenti del mese
Le notizie più interessanti e creative dal mondo della tecnologia, accuratamente selezionate per districarsi tra il rumore informativo.

Le nuove frontiere del ragionamento
Il 31 gennaio, OpenAI rilascia la serie di modelli o3-mini, che cambiano tutte le carte messe sul tavolo dall’azienda grazie alla possibilità di utilizzarli per eseguire ricerche e alla loro disponibilità immediata anche per gli utenti gratuiti.

A differenza di quanto mostrato a dicembre durante i “12 giorni”, OpenAI ha rilasciato o3-mini-medium (chiamato solo o3-mini su ChatGPT) e o3-mini-high, abbandonando la versione “low” forse a causa delle performance non eccellenti. Questi vari livelli indicano il “grado di intelligenza” dei modelli, che aumenta insieme al Test-time Computing. Per dirlo in maniera molto semplificata: più tempo un modello impiega nel produrre i suoi token, migliore sarà la qualità del suo output.
Sia o3-mini che o3-mini-high superano i punteggi di o1 in diversi benchmark.
Il limite di messaggi per gli utenti Plus è di 150 al giorno per il medium e 50 alla settimana per o3-mini-high, mentre gli utenti Pro hanno un utilizzo illimitato. Come DeepSeek R1, integrano anche la funzionalità di ricerca web, che risulta molto più utile e precisa rispetto alle possibilità di GPT-4o.
Pochi giorni dopo, il 2 febbraio, viene annunciato e rilasciato Deep Research per gli utenti Pro. Un agente di ricerca avanzato basato su o3 che può analizzare centinaia di risorse online in pochi minuti per produrre report dettagliati.
Nel momento in cui riceve una richiesta, Deep Research risponde con una serie di domande per avere più informazioni su cui basare le ricerche. Poi inizia a lavorare per alcuni minuti, dai 5 ai 30 in base alla complessità della richiesta, e alla fine restituisce un report dettagliato con tutte le fonti che ha consultato. Gli utenti Pro hanno a disposizione 100 richieste al mese, mentre gli utenti Plus, per i quali non è ancora disponibile, avranno 10 richieste al mese.
Il 5 febbraio, viene rilasciato un piccolo aggiornamento riguardo alla possibilità di utilizzare ChatGPT su WhatsApp, che gli consente ora di ricevere immagini e messaggi vocali. Presto sarà anche possibile connettere il proprio account alla chat di WhatsApp per un utilizzo più ampio.
Il 12 febbraio, l’amministratore delegato di OpenAI Sam Altman pubblica su X un post in cui descrive la roadmap dell’azienda per i prossimi mesi. Rilevando alcune informazioni molto interessanti sull’imminente GPT-4.5 e sul futuro GPT-5.

Inizia parlando di quanto sia scomodo il fatto di dover sempre scegliere manualmente il modello più adatto ai propri compiti dal menù a tendina, per poi fare un annuncio molto importante: Rilasceremo GPT-4.5, il modello che internamente abbiamo chiamato Orion, come nostro ultimo modello non basato su catena di pensieri.
Questa frase è praticamente la fine di un'epoca, perché sta implicitamente dicendo che i modelli transformer, per come li conosciamo oggi, hanno raggiunto il loro limite massimo di scalabilità. Non a caso, lo stesso giorno è stato pubblicato un articolo sul blog di Nvidia che parla proprio di questo argomento.
Altman prosegue dicendo che: Un obiettivo primario per noi è unificare i modelli della serie o e i modelli della serie GPT creando sistemi che possano usare tutti i nostri strumenti e sapere quando riflettere a lungo e quando no. Poi aggiunge: Sia in ChatGPT che nella nostra API, rilasceremo GPT-5 come sistema che integra molta della nostra tecnologia, tra cui o3. Non distribuiremo più o3 come un modello separato.
Quindi la versione “completa” di o3 non arriverà come modello standalone, ma come strumento di GPT-5, che non sarà più un modello vero e proprio ma una sorta di agente orchestratore, che si occuperà di interpretare le richieste degli utenti per capire quale strumento o modello si addice maggiormente a quel compito.
Questo significa che il nostro approccio a ChatGPT potrebbe cambiare, perché tutto dipenderà solo dai nostri prompt e non più dalla combinazione di prompt, scelta del modello e dello strumento.
Il 13 febbraio viene aggiunto a o1 il supporto per i documenti e a o3-mini quello per documenti e immagini. Sono inoltre aumentati di 7 volte i limiti di utilizzo di o3-mini-high per gli utenti Plus, arrivando a 50 richieste giornaliere.
Il 15 febbraio viene rilasciata una nuova versione di GPT-4o più "intelligente", creativa e con una personalità maggiormente definita. Questo aggiornamento rende l’utilizzo di ChatGPT molto più piacevole e utile in diversi campi come il coding, la scrittura creativa e il brainstorming.
Il 27 febbraio viene rilasciato il tanto atteso GPT-4.5, il "modello più grande e migliore di sempre per la chat" che sarà anche l’ultimo membro della famiglia GPT per come abbiamo imparato a conoscerla finora.

GPT-4.5 rappresenta il culmine di un processo di scaling dell’apprendimento non supervisionato. Aumentando le risorse computazionali, la quantità e qualità dei dati di addestramento, insieme a innovazioni di architettura e ottimizzazione, OpenAI ha ottenuto un modello con una conoscenza più ampia e una comprensione più profonda del mondo, portando a una riduzione delle allucinazioni e a una maggiore affidabilità.
GPT-4.5 è fondamentalmente una versione migliorata di GPT-4o, addestrata con una combinazione di tecniche tra cui il fine-tuning supervisionato e l’apprendimento per rinforzo da feedback umano. Il training è stato fatto con nuovi dataset altamente curati, inclusi dati pubblici, proprietari e sviluppati internamente, con una parte dei dati che proviene da modelli più piccoli.
I test accademici e i benchmark interni hanno evidenziato miglioramenti significativi rispetto a GPT-4o, soprattutto nell’AIME ‘24 (Matematica), dove segna un punteggio del 36.7% contro il 9.3% del modello precedente. In un test interno (quindi non pubblico) creato da Cognition, l'azienda che ha sviluppato l'agente per il coding Devin, arriva quasi ai livelli di Sonnet 3.7 nella programmazione agentica.
Il modello supporta il caricamento di immagini, file e l’utilizzo dello strumento Canvas, ma non può usare la modalità vocale avanzata o la condivisione dello schermo.
Questo è probabilmente dovuto al suo costo estremamente elevato, che è anche il principale problema di GPT-4.5. Andando a vedere il prezzo delle sue API, risulta 30 volte più costoso rispetto a GPT-4o negli input e 15 volte più costoso negli output.
Si può quindi affermare che, rispetto alle sue effettive performance, molto simili ad altri modelli SOTA rilasciati questo mese, abbia un costo spropositato.
GPT-4.5 è attualmente disponibile in anteprima solo per gli utenti Pro, mentre gli utenti Plus e Team potranno utilizzarlo a partire dalla prossima settimana. Per gli utenti Enterprise ed Edu arriverà la settimana dopo ancora, mentre non è stato detto nulla riguardo agli utenti gratuiti.
Il giorno dopo, il 28 febbraio, è stato annunciato il rilascio di Sora anche per gli utenti europei, britannici e svizzeri.
Verso una risoluzione dei problemi più comuni per i modelli video AI
Il 4 febbraio viene rilasciato il paper di VideoJAM, un nuovo framework realizzato in collaborazione tra Meta AI e l’Università di Tel Aviv, pensato per risolvere il problema dei movimenti realistici nei modelli AI per la generazione di video.

Il problema che intende risolvere è chiaro: i modelli attuali si concentrano principalmente sull'aspetto visivo, come colori e texture, trascurando spesso la naturalezza del movimento tra i fotogrammi. Il risultato è che, sebbene le immagini possano apparire di alta qualità, i movimenti tra un fotogramma e l’altro risultano spesso innaturali o fisicamente errati.
VideoJAM affronta questa criticità insegnando ai modelli a comprendere e generare non solo l'aspetto visivo, ma anche la dinamica del movimento. Per farlo, utilizza una tecnica chiamata Optical Flow, che analizza lo spostamento dei pixel da un frame all'altro, trasformando queste informazioni in una sorta di "mappa" RGB.
Il framework introduce due innovazioni principali:
Durante la fase di addestramento, il modello viene modificato per imparare a predire contemporaneamente sia l’immagine che la rappresentazione del movimento (optical flow).
Durante la fase di inferenza, viene introdotto un meccanismo detto Inner-Guidance, che permette al modello di utilizzare la previsione del movimento per guidare e correggere il processo di generazione.
Uno degli aspetti più interessanti di VideoJam è la sua semplicità di implementazione: bastano pochi livelli aggiuntivi ai modelli video pre-addestrati per ottenere miglioramenti significativi, senza la necessità di modificare il dataset o aumentare il numero di parametri.
I gemelli di Google
Il 5 febbraio Google ha rilasciato le prime versioni ufficiali di Gemini 2.0, dopo aver presentato i nuovi modello per la prima volta a dicembre 2024.

I rilasci principali sono:
2.0 Pro Experimental - un modello con finestra di contesto da ben 2milioni di token che eccelle nel coding ed è disponibile per gli utenti Advanced, in Google AI Studio o su Vertex.
2.0 Flash-Lite - nuovo modello più veloce ed efficiente, che supera 1.5 Flash pur mantenendo costi e velocità simili. Ha una finestra di contesto da 1milione di token ed è disponibile in Google AI Studio o su Vertex.
2.0 Flash Thinking Experimental - modello di ragionamento che può eseguire ricerche o interagire con Maps e YouTube. Disponibile a tutti gli utenti nell’app di Gemini.
Rispetto alla serie 1.5, i nuovi modelli performano meglio solo di pochi punti percentuale nella maggior parte dei Benchmark, tranne nel Q&A, dove raggiungono anche il triplo del punteggio. Questo significa che la serie 2.0 è molto più affidabile e tenderà ad avere meno allucinazioni, ma non è particolarmente più “intelligente” rispetto ai modelli precedenti di casa Google.
Poco più avanti, il 13 Febbraio, viene introdotta in Gemini la possibilità che il modello ricordi le conversazioni avute in altre chat precedenti. Una funzionalità attivabile e disattivabile a piacimento.
Sempre il 13 febbraio, Google annuncia anche l'integrazione del suo modello video Veo 2 all’interno di YouTube Shorts. Con questa nuova funzionalità, i creatori potranno generare clip generate dall’IA direttamente dall’app, migliorando sia la velocità di creazione sia la qualità dei contenuti grazie a degli output realistici e a effetti cinematografici avanzati.
L’aggiornamento consente di creare sia sfondi animati che clip autonome. Attualmente disponibile per utenti in Stati Uniti, Canada, Australia e Nuova Zelanda, l’integrazione verrà progressivamente estesa ad altre regioni. Per garantire una maggior trasparenza, ogni video generato verrà contrassegnato dal watermark SynthID di Google che aiuta a identificare i contenuti generati con AI.
Il 19 febbraio Google Research annuncia AI co-scientist, un innovativo sistema AI progettato per supportare i ricercatori nell’identificazione di nuove ipotesi scientifiche e nel perfezionamento dei progetti di ricerca.

Basato su Gemini 2.0, questo sistema multi-agente agisce come un collaboratore virtuale, in grado di sintetizzare informazioni complesse e di proporre strategie di ricerca originali. AI co-scientist integra una serie di agenti specializzati – tra cui Generation, Reflection, Ranking, Evolution, Proximity e Meta-review – che collaborano in modo iterativo per generare, valutare e affinare le ipotesi. Questo processo, che ricrea in modo virtuale il ragionamento scientifico, permette di:
Generare ipotesi innovative a partire da obiettivi di ricerca espressi in linguaggio naturale
Produrre panoramiche dettagliate e protocolli sperimentali adatti a testare tali ipotesi
Applicare tecniche di auto-valutazione basate sul sistema Elo, dimostrando che ipotesi con punteggi più alti corrispondono a una qualità superiore dei risultati
Il sistema è stato messo alla prova in diversi contesti di ricerca biomedica:
Drug repurposing per la leucemia mieloide acuta (AML): AI co-scientist ha proposto candidati per il riposizionamento di farmaci, ipotesi che sono state successivamente validate in laboratorio attraverso test in vitro, evidenziando la sua capacità di individuare trattamenti efficaci a dosaggi clinicamente rilevanti.
Scoperta di nuovi target per la fibrosi epatica: Il sistema ha identificato target epigenetici in modelli di organoidi epatici umani, suggerendo potenziali interventi che potrebbero invertire la progressione della malattia.
Spiegazione dei meccanismi di resistenza antimicrobica: Attraverso un’analisi in silico, AI co-scientist ha evidenziato come le isole cromosomiche indotte da fagi possano interagire con diversi tipi di code virali, ampliando il campo di azione dei batteriofagi e contribuendo alla diffusione della resistenza.
I creatori del sistema, Juraj Gottweis e Vivek Natarajan, sottolineano che l’obiettivo principale di AI co-scientist è quello di aumentare la produttività degli scienziati, non di sostituirli. Il sistema è pensato per essere uno strumento di collaborazione che integra il giudizio umano con la capacità di analisi e sintesi di grandi volumi di dati, permettendo così ai ricercatori di superare le difficoltà legate all’enorme crescita della letteratura scientifica e alla complessità interdisciplinare della ricerca moderna.
Semplificando la creazione di effetti visivi
Il 6 febbraio Pika rilascia Pikadditions, un nuovo metodo semplice e intuitivo per creare effetti speciali digitali (visual effects) per i propri video.

A differenza di altri metodi basati su AI come i Generative Visual Effects (GVFX) di Runway, che richiedono diversi passaggi di post-produzione e una pianificazione attenta delle inquadrature, Pikadditions permette di inserire elementi generati dall’IA direttamente in un video già esistente usando un'immagine di riferimento e un prompt testuale che descriva l’interazione del nuovo elemento con il video.
L’obiettivo di Pika è chiaro: superare i competitor offrendo un'esperienza utente fluida e accessibile anche a chi non ha competenze nel campo della post produzione video. Anche se la tecnologia non ha ancora raggiunto i livelli delle grandi produzioni cinematografiche, il valore di Pikadditions sta proprio nella sua accessibilità.
Il 20 febbraio viene rilasciato Pikaswaps, un nuovo strumento che permette di sostituire qualunque elemento presente in un video reale usando un’immagine e un prompt testuale. Per fare un esempio, con Pikaswaps si può sostituire una barca in movimento con una banana gonfiabile gigante.
Il 27 febbraio rilascia Pika 2.2, una versione aggiornata del loro modello di punta, al quale è stata aggiunta la possibilità di selezionare due immagini da utilizzare come frame di inizio e fine di una clip, per transitare fluidamente da una scena all’altra.
Il chatbot per i designer
Il 7 febbraio Krea rilascia Krea Chat, un'interfaccia in stile chatbot che sfrutta DeepSeek R1 per utilizzare gli strumenti di Krea in maniera conversazionale.
Questo strumento semplifica il processo creativo consentendo agli utenti di interagire con l’IA in modo naturale e colloquiale. Krea Chat permette di generare immagini e video, lasciando anche la possibilità di modificare diversi elementi visivi esistenti, il tutto tramite una semplice conversazione.
Animazioni sonore
Il 10 febbraio Luma rilascia la funzionalità Image to Video per il suo modello Ray 2.

Grazie al nuovo Img2Vid si può sfruttare tutta la precisione di Ray 2, che al momento è tra i migliori modelli video AI sul mercato, per animare le proprie immagini, aumentando le possibilità creative dello strumento.
Due settimane dopo, il 24 febbraio, viene introdotta anche la possibilità di generare effetti sonori per le proprie clip generate. Una funzionalità estremamente utile, soprattutto per tutti gli utenti che non sono pratici con il sound design. Da persona che ha lavorato per anni nel settore audiovisivo, mi sento di dire che uno dei grossi limiti di molti creativi che utilizzano l’IA per creare narrazioni, spesso anche molto ben fatte da un punto di vista visivo, era proprio la mancanza di suono o la poca cura che riuscivano a dedicare a questo aspetto importante.
Grazie a questa nuova introduzione di Luma viene, almeno in parte, abbattuta anche una delle ultime barriere che ci separano dal rendere le produzioni cinematografiche veramente accessibile a chiunque.
Fornire un computer agli LLM
Il 12 febbraio Microsoft lancia OmniParser V2, uno strumento di parsing visivo che converte screenshot di interfacce grafiche in dati strutturati interpretabili dagli LLM, trasformando qualunque modello linguistico in un agente che può usare il computer.

Rispetto alla versione precedente, OmniParser V2 offre una precisione notevolmente migliorata nell’identificazione di elementi interattivi anche di dimensioni ridotte, con un incremento di accuratezza a un punteggio di 39.6 nel benchmark ScreenSpot Pro utilizzando un modello come GPT-4o. La latenza operativa è stata ridotta del 60% grazie a un’ottimizzazione del modello per la captioning delle icone, garantendo tempi di elaborazione medi di 0.6-0.8 secondi su hardware di fascia alta.
Per facilitare l’adozione e la sperimentazione, Microsoft ha sviluppato OmniTool, un ambiente containerizzato (basato su Docker) progettato per Windows, che permette di utilizzare OmniParser V2 in sinergia con diversi LLM. Grazie a questo ecosistema, gli sviluppatori possono creare agenti autonomi in grado di navigare, pianificare ed eseguire azioni direttamente sulla UI.
Il 26 febbraio rilascia invece Phi-4-multimodal e Phi-4-mini, che espandono ulteriormente la famiglia di modelli leggeri (lightweight) open-source Phi dopo il rilascio di Phi-4 del mese scorso. Phi-4-multimodal (con 5.6B di parametri) integra l'elaborazione vocale, visiva e testuale, mentre Phi-4-mini (con 3.8B di parametri) eccelle nelle attività basate sul testo.
Nuovi ricercatori AI
Il 14 febbraio Perplexity rilascia il suo Deep Research, un nuovo strumento di ricerca avanzata simile a quello lanciato pochi giorni prima da OpenAI.

Deep Research di Perplexity è in grado di generare in pochi minuti dei report o articoli di approfondimento molto dettagliati, analizzando decine di fonti. Gli utenti gratuiti hanno a disposizione 5 query giornaliere, mentre gli abbonati Pro possono effettuare fino a 500 ricerche al giorno. Una quantità di interazioni significativamente superiore a quelle offerte dall’agente di OpenAI, che è attualmente limitato a 100 richieste mensili per gli utenti Pro, il cui abbonamento ha un costo di $200 al mese.
I benchmark possono evidenziare ulteriori dettagli sulle prestazioni del Deep Research di Perplexity. Ad esempio, questo strumento ha ottenuto un punteggio del 93,9% sul SimpleQA. Sul test Humanity’s Last Exam, un benchmark molto più vasto e complesso, Perplexity ha raggiunto il 21,1%, contro il 26,6% ottenuto dalla versione di OpenAI. Per quanto la differenza possa sembrare minima (5,5 punti percentuali), implica variazioni non indifferenti nella qualità degli output, rendendoli meno approfonditi, precisi e completi rispetto alla controparte di OpenAI.
Pochi giorni dopo, il 18 febbraio, Perplexity lancia R1 1776, una versione del modello cinese DeepSeek R1 che è stata post-addestrata per fornire informazioni non censurate, imparziali e fattuali. Per farlo, è stato creato un set di valutazione multilingue diversificato con oltre 1000 esempi, utilizzando annotatori umani e giudici LLM appositamente progettati.
Il tutto senza intaccare le capacità matematiche e di ragionamento originali.
“L’IA più intelligente sulla Terra”, così dicono…
Il 18 febbraio xAI lancia Grok 3, il tanto atteso modello di ultima generazione creato dall’azienda di Elon Musk per competere con OpenAI e offrirlo come servizio aggiuntivo agli utenti della piattaforma X.

Grok 3 è stato addestrato utilizzando il supercluster Colossus di xAI, composto da circa 200.000 GPU. Secondo le dichiarazioni di Musk durante la presentazione, Grok 3 supera i modelli rivali come o3-mini-high, DeepSeek R1 e Gemini 2 su diversi benchmark legati a matematica, scienze e programmazione.
Non sono però stati mostrati i risultati del modello su molti benchmark chiave come Codeforces, ARC-AGI, Humanity's Last Exam o General Language Understanding, e questo può far pensare a un’azione di cherry picking per far apparire il modello migliore di quanto non sia realmente. Diversi esperti hanno anche sollevato alcune perplessità riguardo ai costi computazionali eccessivamente elevati per aver ottenuto un modello che tutto sommato supera la concorrenza solo di pochi punti percentuali su dei test molto specifici, che potrebbero essere inclusi nel dataset stesso del modello.
Tra le novità introdotte con Grok 3, spiccano le funzionalità “Think” e “Big Brain”, che consentono al modello di ragionare a più livelli per scomporre problemi complessi e migliorare la qualità degli output. xAI ha presentato anche DeepSearch, una funzionalità molto simile al Deep Research di OpenAI, Perplexity e Google.
Grok 3 è disponibile inizialmente agli abbonati Premium e Premium+ di X, con un nuovo piano “SuperGrok” in arrivo destinato a chi desidera sfruttare al massimo le capacità avanzate del modello, in maniera simile al piano Pro di OpenAI.
Collaborazione domestica tra robot umanoidi
Il 20 febbraio Figure annuncia Helix, il loro nuovo modello Vision-Language-Action (VLA) che permette ai robot di comprendere il mondo circostante e agire su di esso con una fluidità mai vista prima.

Questo non è un semplice modello AI di nuova generazione: è un cambio di paradigma che fonde percezione, linguaggio e controllo motorio.
Ciò che spicca di Helix, sono i suoi risultati innovativi per il settore della robotica:
Controllo del corpo: il modello può gestire un controllo continuo ad alta frequenza (200 Hz) dell’intero corpo superiore dell’umanoide, includendo movimenti di polsi, torace, testa e singole dita.
Collaborazione multi-robot: il sistema consente a due robot o più robot di operare simultaneamente, coordinandosi in compiti di manipolazione a lungo termine, anche con oggetti mai visti prima.
Adattabilità agli oggetti sconosciuti: grazie a comandi in linguaggio naturale, i robot dotati di Helix possono afferrare e manipolare migliaia di piccoli oggetti domestici, senza la necessità di addestramenti specifici
Architettura unificata: Helix utilizza un singolo set di pesi della rete neurale per apprendere e mettere in atto diverse operazioni, dal Pick & Place alla gestione di cassetti e frigoriferi, eliminando la necessità di addestramenti per ogni compito
Efficienza: con i suoi 7 miliardi di parametri, è progettato per operare direttamente su GPU incorporate a basso consumo
Questo modello risponde alle sfide più complesse degli ambienti domestici, dove la varietà e l’imprevedibilità degli oggetti richiedono una capacità di adattamento e generalizzazione inedita per la robotica.
Helix si basa su una struttura duale, che sembra ispirarsi al modello della mente umana descritto dallo psicologo Daniel Kahneman nel suo libro Pensieri lenti e veloci:
System 2 (S2): Un modulo di visione-linguaggio pre-addestrato che opera a 7-9 Hz, che comprende il linguaggio naturale, riflette semanticamente sulle scene e pianifica le sue azioni di conseguenza (pensiero lento)
System 1 (S1): Un modello di controllo motorio, capace di tradurre la comprensione dell'S2 in azioni precise, in tempo reale a 200 Hz, garantendo un controllo fluido e coordinato in tempo reale (pensiero veloce)
Questa architettura “System 1, System 2” permette a Helix di unire la capacità di ragionamento lento e accurato con una rapida esecuzione delle azioni, superando il tradizionale compromesso tra generalizzazione e velocità. I test dimostrativi mostrano dei robot Figure 02 che collaborano in scenari complessi come l’organizzazione di generi alimentari in una cucina dopo averli ricevuti dal sacco della spesa, operando su oggetti completamente nuovi
Il modello è stato addestrato con circa 500 ore di dati di alta qualità, utilizzando tecniche di auto-annotazione per generare istruzioni linguistiche retrospettive, garantendo così una forte capacità di generalizzazione pur mantenendo un’efficienza di training paragonabile a dataset di apprendimento per compiti singoli. La capacità di Helix di adattarsi a spazi d’azione ad alta dimensionalità, senza necessità di interventi specifici per ogni compito, rappresenta un notevole passo avanti nel rendere la robotica umanoide pronta per l’uso quotidiano nei contesti domestici.
Il mostro della programmazione
Il 24 febbraio Anthropic lancia Claude 3.7 Sonnet insieme a un nuovo Agente AI chiamato Claude Code, pensato per efficientare il lavoro dei programmatori.

Claude 3.7 Sonnet è un modello di ragionamento ibrido, specializzato nella programmazione e progettato per coniugare la rapidità di risposte immediate con la capacità di “extended thinking”, un ragionamento approfondito step by step tramite catena di pensiero. Questa modalità di funzionamento, ispirata al modo in cui il cervello umano tende a bilanciare risposte intuitive e riflessioni ponderate, permette al nuovo Sonnet di essere più flessibile.
Tramite API, gli utenti possono anche controllare il budget del “pensiero” del modello.
I punteggi di Sonnet 3.7 nei principali benchmark sono piuttosto insoliti, perché nonostante si tratti di un modello di ultima generazione, viene surclassato dai competitor in praticamente ogni test. Tranne due: Agentic Coding e Agentic Tool Use.
Il primo è tratto da SWE‑bench Verified, una versione curata e validata del benchmark SWE‑bench, ideato per valutare la capacità dei modelli di linguaggio di risolvere problemi reali di ingegneria del software. In questo test, Claude 3.7 Sonnet supera il modello di ragionamento o3-mini-high del 42,6%.
Mentre il secondo misura l’abilità degli agenti AI di operare in scenari interattivi e complessi, evidenziando sia la loro capacità di risolvere i compiti che la loro affidabilità nel tempo.
Parallelamente al lancio del nuovo modello, Anthropic presenta anche Claude Code, un nuovo strumento agentico dedicato al coding, pensato per essere un collaboratore attivo per gli sviluppatori: riesce a cercare e leggere codice, modificare file, eseguire test, e persino eseguire commit e push su GitHub, interagendo tramite terminale. Questo agente per il coding ha già dimostrato la sua efficacia, riuscendo a completare in un singolo passaggio attività che in genere richiederebbero oltre 45 minuti di lavoro manuale, ottimizzando il processo di sviluppo.
Voci artificialmente umane
Il 26 febbraio la startup Hume ha rilasciato Octave, il primo LLM progettato per il Text-to-Speech empatico di alta qualità.
Si tratta di un modello concettualmente simile a quelli di ElevenLabs, addestrato su un'enorme mole di dati linguistici molto diversi tra loro, ma con la differenza che può effettivamente recitare in modo simile agli esseri umani.
Le sue funzionalità principali sono tre:
Voice design: con una semplice descrizione testuale è possibile ottenere qualunque timbro vocale di alta qualità
Recitazione: esattamente come un regista spiegherebbe a un attore come interpretare quella scena, con Octave possiamo guidare l'emotività del modello grazie a un prompt
Comprensione del contesto: trattandosi di un LLM e non di un semplice modello T2S, Octave può comprendere un testo come farebbe un attore umano. Questo gli consente di capire colpi di scena, segnali emotivi, tratti caratteriali e come combinarli tra loro per trasmettere emozioni
Il grado di realismo delle sue voci è eccellente, ma risulta solo leggermente superiore a quelle della più nota ElevenLabs. La principale peculiarità di Octave risiede quindi nella capacità di adattare dinamicamente l’emotività al testo e alla possibilità di ricevere istruzioni precise su come interpretare ciò che legge.
Un moderno scriba
Sempre il 26 febbraio, ElevenLabs rilascia Scribe, il miglior modello Speech-to-Text sul mercato, che supera persino le performance di Whisper di OpenAI.

Sfruttando un modello ASR (Automatic Speech Recognition) all’avanguardia, Scribe può trascrivere audio in 99 lingue, offrendo un grado di precisione mai visto.
Il modello ha diverse funzionalità interessanti:
Timestamps: permette una sincronizzazione perfetta dei sottotitoli
Speaker diarization: distingue e identifica con chiarezza ogni interlocutore
Audio-event tagging: può arricchire le trascrizioni con informazioni contestuali sugli eventi sonori che possono avvenire in sottofondo
Scribe ha dimostrato prestazioni eccezionali in benchmark importanti come FLEURS e Common Voice, raggiungendo oltre il 98% di precisione nelle lingue maggiormente parlate e migliorando significativamente la trascrizione di lingue tradizionalmente meno supportate, come il serbo, il cantonese e il malayalam.
Il modello può essere facilmente integrato tramite API, rendendolo ideale per sviluppatori e aziende che desiderano ottimizzare la gestione dei contenuti audio. Con un’interfaccia intuitiva e la possibilità di avviare la trascrizione in tempo reale, Scribe rappresenta un nuovo standard per la conversione automatica della voce in testo e aiuta ElevenLabs a rafforzare la sua posizione nel campo dell’IA applicata all’audio.
L’edicola dei paper scientifici
Tre paper di ricerca per il mese di febbraio.

Scaling up Test-Time Compute with Latent Reasoning:
A Recurrent Depth Approach - Un nuovo approccio architettonico ai modelli linguistici che permette di scalare il calcolo “test-time” ragionando implicitamente all’interno dello spazio latente. Questo modello funziona iterando un blocco ricorrente, ragionando con una profondità arbitraria durante il “test-time”. Questo va in contrasto con i modelli di ragionamento tradizionali che aumentano il calcolo producendo più token. A differenza degli approcci basati sulla catena di pensiero, questo non richiede dati di training specializzati. Può funzionare con piccole finestre di contesto e può cogliere tipi di ragionamento che non sono facilmente rappresentabili a parole. Nel paper si parla di un modello proof-of-concept da 3,5 miliardi di parametri e 800 miliardi di token.Brain2Qwerty - Un metodo rivoluzionario per trasformare l’attività cerebrale in testo scritto, senza la necessità di interventi chirurgici invasivi. La ricerca dimostra come segnali neurali raccolti tramite magnetoencefalografia (MEG) ed elettroencefalografia (EEG) possano essere decodificati con precisione grazie a Brain2Qwerty, un’architettura di intelligenza artificiale basata su reti convoluzionali, transformer e un character-level language model per affinare la decodifica e ridurre gli errori. I test condotti su 35 partecipanti hanno evidenziato risultati promettenti: con la MEG, il modello ha raggiunto un tasso di errore del 32%, mentre con EEG il margine di errore è stato maggiore (67%), a causa della qualità del segnale più bassa. Nei migliori soggetti, la decodifica si è rivelata particolarmente efficace, con un errore ridotto al 19%, dimostrando il potenziale della tecnologia per superare il divario tra le BCI invasive e quelle non invasive.
Nonostante il sistema necessiti ancora di ulteriori sviluppi per arrivare a un’applicazione in tempo reale, i risultati indicano una chiara direzione per il futuro della neurotecnologia.
DexterityGen - Un innovativo controller di base progettato per consentire ai robot di eseguire manipolazioni manuali estremamente precise e complesse, combinando l’apprendimento per rinforzo alla teleoperazione umana. Tradizionalmente, l’addestramento dei robot per compiti di destrezza manuale si basa su due strategie principali: la teleoperazione umana, che consente di apprendere imitando movimenti, ma è limitata dalla difficoltà di riprodurre movimenti sicuri senza feedback tattile, e l’apprendimento per rinforzo in simulazione, che soffre di un divario tra il mondo virtuale e la realtà e richiede una sofisticata progettazione dei premi. DexGen unisce i vantaggi di entrambi gli approcci, preaddestrando un modello generativo su un vasto dataset di movimenti legati alla destrezza appresi in simulazione tramite RL. Questo modello viene poi utilizzato per trasformare i comandi di movimento grezzi di un operatore umano in azioni precise, stabili e sicure. I test condotti dimostrano che DexGen migliora significativamente la stabilità nella manipolazione e consente ai robot di eseguire compiti complessi come la rotazione e il riposizionamento di oggetti nelle dita, oltre all'uso di strumenti come penne, siringhe e cacciaviti.
Il mercatino dell’open-source
Tre progetti open-source con codice per il mese di febbraio.

MedRAX - Un agente di ragionamento medico progettato per l’interpretazione automatizzata delle radiografie toraciche, che integra in modo sinergico diversi strumenti di analisi visiva, segmentazione, localizzazione e generazione di referti, consentendo così di affrontare in maniera efficace e precisa le complesse sfide diagnostiche tipiche della pratica clinica. Basato su un’architettura modulare che sfrutta i framework LangChain e LangGraph, il sistema utilizza le capacità visive di GPT-4o come base, permettendo di rispondere a domande mediche articolate senza necessità di ulteriore addestramento specifico. MedRAX incorpora al suo interno moduli specializzati quali CheXagent, LLaVA-Med, PSPNet, Maira-2, SwinV2 e DenseNet-121, estendendosi perfino alla generazione di immagini sintetiche tramite RoentGen, e offre così una piattaforma completa e versatile che supporta sia implementazioni locali che soluzioni basate sul cloud, il tutto accessibile attraverso un’interfaccia sviluppata con Gradio. Il sistema viene validato dall’adozione di ChestAgentBench, un benchmark accurato composto da 2.500 query mediche, suddivise in sette categorie, elaborate su un dataset di 675 casi clinici curati da esperti, che ne conferma le elevate prestazioni rispetto a soluzioni sia open source che proprietarie, segnando un importante passo avanti verso la diffusione di sistemi automatizzati per l’interpretazione delle radiografie.
BiRefNet - Un modello che permette di separare i soggetti dallo sfondo con estrema precisione, segmentando sia le immagini statiche che i video. Il sistema è basato su un’architettura innovativa che integra in maniera sinergica due meccanismi di riferimento bidirezionale, con l’obiettivo di migliorare l’estrazione e la fusione di informazioni da dati complessi in ambito di computer vision. Il modello proposto si basa su un flusso parallelo di elaborazione che permette di combinare efficacemente diverse rappresentazioni, ottenendo così risultati accurati e prestazioni ottimizzate in termini di efficienza computazionale. Il progetto si distingue per la sua architettura modulare, che ne favorisce l’adattabilità a compiti differenti, come il riconoscimento di immagini e il restauro visivo, rendendolo uno strumento prezioso tanto per la ricerca quanto per applicazioni industriali.
ASAP - Un progetto che punta a colmare il divario tra la simulazione e la realtà per l’apprendimento di abilità complesse e agili nei robot umanoidi. Sviluppato sul framework multi-simulatore HumanoidVerse e arricchito dai precedenti risultati di Human2Humanoid, ASAP adotta un’architettura modulare che separa in maniera netta i simulatori, i compiti e gli algoritmi, permettendo trasferimenti fluidi tra diversi ambienti simulati – tra cui IsaacGym, IsaacSim e Genesis – e applicazioni reali. Il repository offre una guida dettagliata per la configurazione di ambienti Conda e Mamba, illustrando passaggi specifici per l’installazione e il testing dei simulatori, e include pipeline dedicate al training per il motion tracking, evidenziate da esempi come l’imitazione della celebre mossa “Siuuu” di Cristiano Ronaldo. Con un approccio orientato sia alla ricerca accademica che all’innovazione tecnologica, ASAP si propone di fornire una solida piattaforma di sviluppo e sperimentazione per la robotica umanoide, facilitando il trasferimento di politiche di controllo tra simulazione e mondo reale e contribuendo in maniera significativa all’avanzamento degli studi in ambito di apprendimento per rinforzo e dinamiche fisiche realistiche, il tutto sotto una licenza MIT che ne incentiva la collaborazione e l’evoluzione continua.
Le nuove Leggi di Scalabilità
Negli ultimi anni, il mondo dell’Intelligenza Artificiale ha assistito a un rapido incremento della complessità e delle capacità generali dei modelli. In questo contesto, le scaling laws si sono affermate come una solida base per comprendere e prevedere come le prestazioni di un modello possano migliorare con l’aumentare delle risorse impiegate: dati, parametri e potenza computazionale. L’idea di fondo è semplice: all’aumentare delle risorse, il modello tende a migliorare in modo prevedibile.
Con l’evolversi della tecnologia e l’aumentare della complessità richiesta per le nuove applicazioni, è emersa anche la necessità di superare e ripensare i paradigmi attuali, introducendo nuove dimensioni alle leggi di scalabilità.

Le Scaling Laws tradizionali e il loro impatto sui Modelli Linguistici
A partire dal 2020, tutto il settore dell’intelligenza artificiale è stato profondamente influenzato dallo studio Scaling Laws for Neural Language Models, pubblicato da OpenAI. Questo lavoro ha evidenziato che le performance dei modelli linguistici aumentano in modo prevedibile con l’incremento dei parametri, dei dati di addestramento e della potenza computazionale. L’idea centrale era che, per ottenere risultati migliori, non bastasse affinare algoritmi e architetture esistenti, ma che occorresse “scalare” la dimensione del modello in maniera sistematica.
I ricercatori avevano notato l’esistenza di una relazione quasi matematica tra il miglioramento delle prestazioni di un modello, l’aumento del numero di parametri, l’espansione del dataset di addestramento e l’incremento della potenza computazionale impiegata. Questo concetto ha avuto un impatto notevole sia dal punto di vista teorico che pratico: ha permesso di prevedere in anticipo come i modelli si comporteranno all’aumentare delle risorse, e ha spinto l’industria a investire in infrastrutture di calcolo sempre più potenti.
Un aspetto fondamentale delle scaling laws tradizionali è la loro capacità di quantificare i rendimenti marginali, ovvero il guadagno in performance ottenuto aggiungendo ulteriori risorse (come un incremento nel numero di parametri o nella potenza di calcolo). All'inizio, ogni nuova unità di risorsa porta a miglioramenti significativi, ma con l'aumentare del modello, ogni ulteriore incremento produce benefici progressivamente minori – un fenomeno noto come rendimenti marginali decrescenti o diminishing returns. Questi miglioramenti seguono una curva di tipo potenza, una legge matematica espressa dalla formula:

In cui la performance y cresce in funzione della risorsa x ma con un tasso che diminuisce man mano che x aumenta. In questo modo, si evidenzia come l'incremento delle risorse porti a benefici prevedibili, anche se non in modo lineare.
A un certo punto, i benefici ottenuti da un ulteriore incremento di risorse tendono a diminuire, evidenziando un punto di saturazione. Questa osservazione ha stimolato una riflessione sul rapporto tra dimensione e qualità, spingendo i ricercatori a esplorare nuove strategie per superare i limiti intrinseci del semplice aumento delle risorse.
Per chiarire meglio questi concetti, è utile introdurre alcuni tecnicismi. Quando parliamo di scaling, intendiamo un’operazione di ingrandimento delle componenti di un modello: se da un lato l’aggiunta di parametri permette di catturare relazioni sempre più complesse nei dati, dall’altro è necessario disporre di dataset di dimensioni sufficienti per evitare un fenomeno chiamato overfitting.
Spiegandolo in termini semplici, un modello molto grande che viene addestrato su pochi dati rischia di “imparare a memoria” molti esempi specifici, perdendo la sua capacità di generalizzare rispetto a nuovi contesti.
Il contributo del paper del 2020 è stato rivoluzionario perché ha fornito un quadro quantitativo che ha permesso di prevedere con una buona approssimazione le prestazioni dei modelli man mano che venivano scalati. Questi risultati hanno avuto ripercussioni non solo sullo sviluppo di modelli linguistici sempre più performanti, ma anche sulla progettazione di intere infrastrutture di calcolo dedicate all’IA.

Le nuove Scaling Laws e l’Era dell’Intelligenza
Negli anni successivi al 2020, il settore AI ha continuato a evolversi, e nuovi approcci sono emersi per sfruttare appieno le risorse computazionali. Nel 2024, diverse aziende hanno iniziato a rendersi conto di star raggiungendo il punto in cui le Scaling Laws non garantiscono più ritorni significativi sugli investimenti necessari ad addestrare nuovi modelli di frontiera. Era quindi necessario trovare nuovi approcci per proseguire la scalata degli LLM verso nuove vette di “intelligenza”, ma come?
OpenAI inizia ad applicare un nuovo approccio, che non sostituisce il metodo precedente ma ne crea una continuazione diretta, arrivando alla creazione dei cosiddetti “modelli di ragionamento”, come o1 e o3.
Un recente articolo pubblicato da NVIDIA ha preso in esame questo nuovo approccio, evidenziando che il concetto di scaling non si limiterà più solamente al pretraining (l’addestramento iniziale dei modelli) ma si estenderà anche a due fasi successive.
L’analisi di NVIDIA si articola in tre punti principali, che portano all’emersioni di due nuove leggi di scalabilità:
Pretraining Scaling: Questo aspetto riguarda il tradizionale approccio in cui l’aumento della dimensione del modello, dei dati e della potenza computazionale porta a miglioramenti diretti nelle prestazioni. Come discusso nel capitolo precedente, questa relazione è ben definita e ha permesso di stabilire delle previsioni attendibili sui miglioramenti ottenibili.
Post-Training Scaling: Una volta preaddestrato, un modello può essere ulteriormente ottimizzato per compiti specifici. Questo processo, detto post-training, include tecniche come il fine-tuning, la distillazione e il reinforcement learning. Queste metodologie consentono di adattare un modello generico a contesti particolari, migliorando la sua precisione in applicazioni specifiche.
Test-Time Scaling: Una delle innovazioni più interessanti nell’ambito degli LLM riguarda l’applicazione di maggior potenza computazionale durante il processo di inferenza, cioè nel momento in cui il modello risponde a una richiesta. Questa tecnica, che racchiude il concetto di Catena di Pensiero (CoT) e si estende nel cosiddetto Long Thinking, consente al modello di ragionare in maniera più approfondita su quesiti complessi. Invece di generare una risposta immediata, il modello esegue più passaggi interni e impiega cicli computazionali aggiuntivi per esplorare, valutare e perfezionare le proprie ipotesi prima di formulare una risposta finale, garantendo così degli output più accurati.
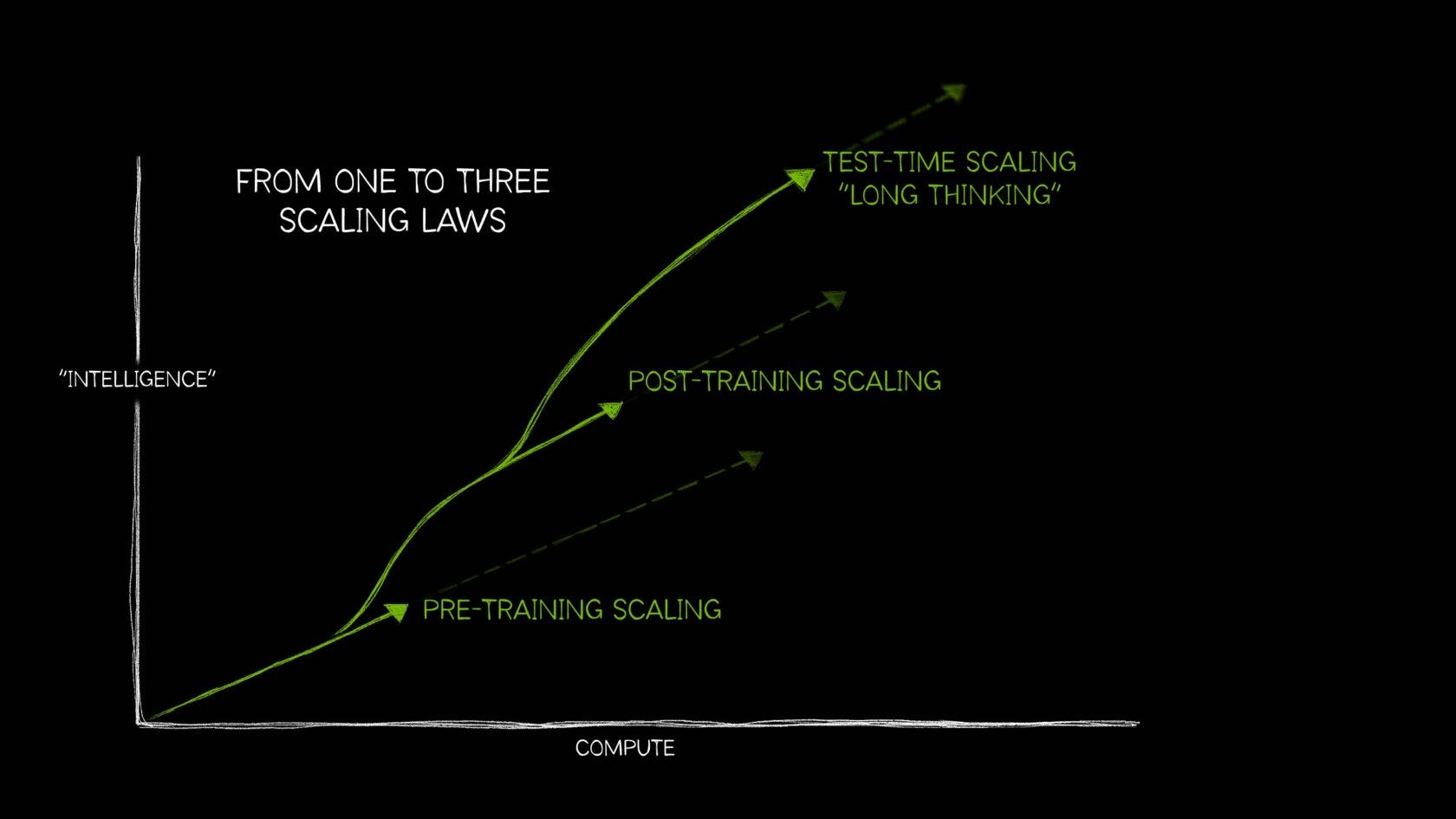
Il concetto di test-time scaling rappresenta una svolta fondamentale nel campo dell’IA. Prima dell’avvento di o1 di OpenAI, i modelli di linguaggio rispondevano in maniera “one-shot”, fornendo una risposta immediata che, in contesti complessi, poteva risultare superficiale o imprecisa. Con l’adozione del long thinking, il modello adotta un approccio simile a quello umano: analizza il problema in maniera graduale, valutando diverse possibilità prima di giungere a una conclusione.
Le nuove scaling laws introdotte da NVIDIA ampliano il concetto di scalabilità a diverse fasi del ciclo di vita di un modello, dal pretraining all’inferenza, e aprono nuove prospettive per l’intelligenza artificiale. Tutto questo ci porta verso sistemi IA in grado di affrontare compiti sempre più complessi e articolati, avvicinandosi sempre di più alle modalità di ragionamento tipiche dell’intelligenza umana.

Nuove Scaling Laws nel campo della Robotica
Le scaling laws hanno finora giocato un ruolo essenziale nello sviluppo di nuovi modelli linguistici, ma alcune recenti innovazioni nel settore della robotica stanno aprendo la strada a nuove applicazioni di questi principi. Nel recente articolo di presentazione del modello Helix, della startup di robotica Figure, è stato messo in luce come il concetto di scaling possa essere applicato anche ai robot.
Helix è un nuovo modello Vision-Language-Action che permette ai robot di comprendere il mondo circostante e agire su di esso con precisione e fluidità quasi umana. Può far eseguire ai robot operazioni complesse che richiedono la capacità di riconoscere, interpretare e manipolare l’ambiente circostante.
Le scaling laws di Figure evidenziano alcune differenze fondamentali rispetto agli approcci tradizionali: la scala di apprendimento e controllo non è più misurata unicamente in termini di aumento dei parametri, ma anche in termini di capacità di adattarsi a contesti estremamente variabili e imprevedibili, come quelli che si incontrano in un ambiente domestico. Invece di programmare manualmente ogni abilità del robot o dover raccogliere grosse quantità di dati dalle simulazioni o dal mondo reale, Helix permette di imparare nuove capacità semplicemente ricevendo delle istruzioni in linguaggio naturale.
In altre parole, Helix sfrutta la conoscenza che ha appreso durante la fase di training per comprendere nuovi comandi e tradurli in azioni. Questo rende il robot molto più efficiente e scalabile: man mano che il modello diventa più performante, il robot impara sempre più abilità senza bisogno di addestramenti su misura.
Un dato particolarmente interessante riguarda le curve di scaling, che dimostrano come, utilizzando una quantità relativamente ridotta di dati di addestramento (in proporzione ai moderni dataset per il single-task imitation learning), Helix riesca a generalizzare e ad acquisire nuove abilità per gli spazi ad alta dimensionalità.
Si potrebbe quindi affermare che le leggi di scalabilità non sono un concetto confinato ai soli modelli linguistici, ma possono essere applicate con successo anche in domini che richiedono l’integrazione di percezione del mondo fisico, ragionamento e azione.
È importante sottolineare che il successo di Helix non dipende esclusivamente dall’aumento dei parametri o dalla dimensione del dataset, ma anche da innovazioni nell’architettura e nell’ottimizzazione del flusso di dati tra i diversi componenti del sistema. Questo approccio olistico consente di superare i limiti imposti dai tradizionali metodi imitativi, rendendo possibile la generalizzazione zero-shot, ovvero la capacità di affrontare situazioni nuove rispetto all’addestramento.
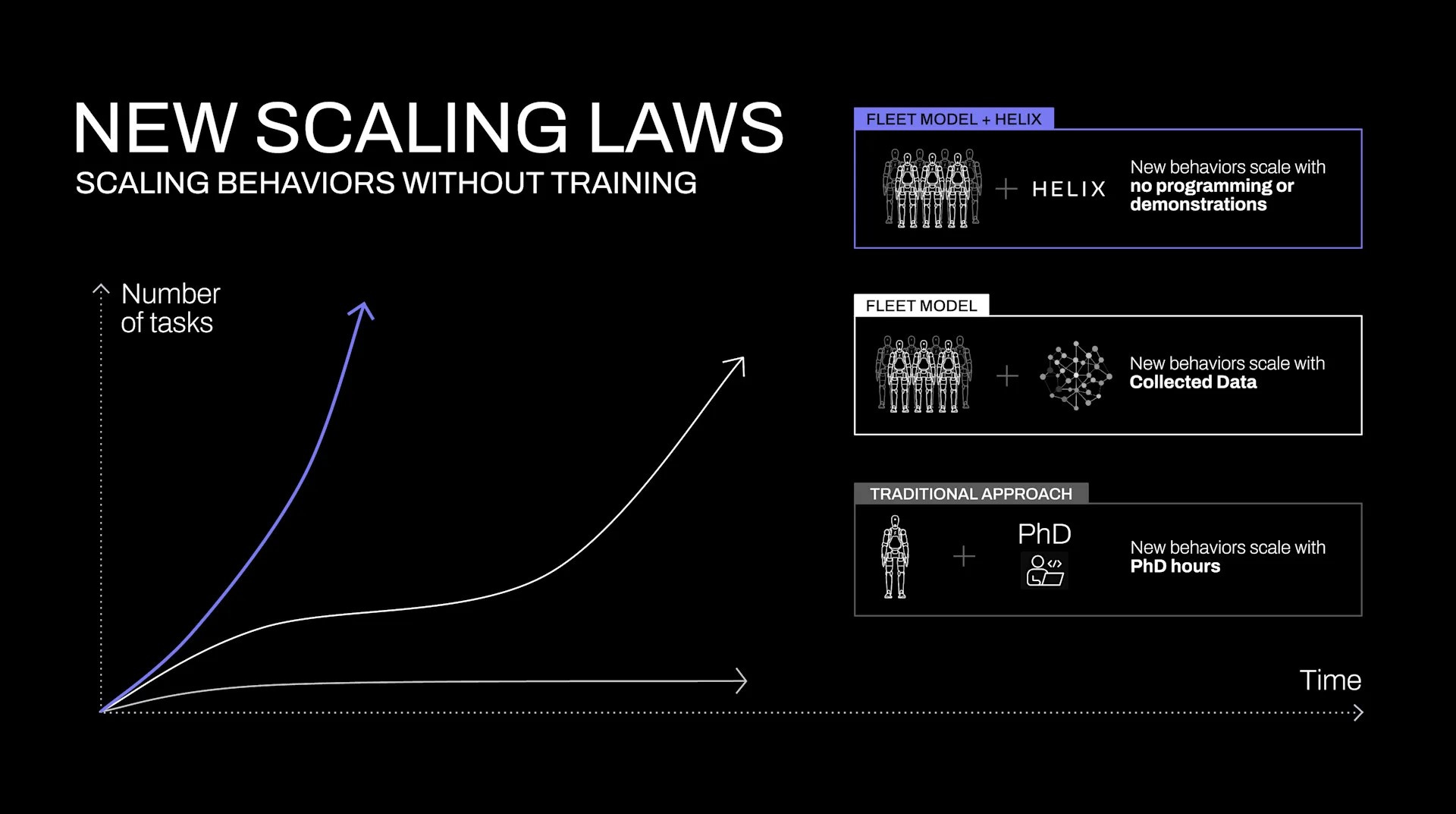
I dati quantitativi e le curve di scaling presentate da Figure mostrano chiaramente che l’incremento della potenza computazionale, se ben indirizzato e combinato con architetture innovative, può portare a un’accelerazione esponenziale nella capacità dei robot di apprendere e adattarsi. Questi sviluppi evidenziano un salto qualitativo nelle capacità dei sistemi robotici, suggerendo anche una convergenza tra i modelli di linguaggio e i sistemi di controllo motorio, che apre nuove frontiere per applicazioni che richiedono un’interazione sinergica tra la comprensione del linguaggio e l’esecuzione di compiti complessi.
Le scaling laws tradizionali hanno fornito una base solida per comprendere il rapporto tra parametri, dati e performance, mentre le nuove prospettive introdotte da NVIDIA hanno espanso il paradigma includendo fasi di post-training e inferenza aumentata. Parallelamente, l’applicazione di questi concetti al controllo robotico sta aprendo le porte alla creazione di sistemi che possono operare in ambienti complessi e dinamici, con una capacità di adattamento e generalizzazione che fino a pochi anni fa sembrava irraggiungibile.
L’Archeologo dei Media
L’intervistato del nuovo numero di Tales from the Latent Space è Riccardo Silano, un artista e sperimentatore che possiamo definire archeologo dei media. Il suo operato esplora dei territori ancora da scoprire nel regno della creatività, con un approccio unico che mette in relazione passato e presente attraverso l’uso di vecchie apparecchiature audiovisive e intelligenza artificiale generativa.
Dalla sua esperienza con una rete televisiva locale alla creazione di installazioni di videoarte, fino alle più recenti sperimentazioni con l’IA, il suo percorso è una continua riconversione e riscoperta. La sua arte emerge dall’interazione tra strumenti tecnologici di epoche diverse, creando un’estetica che fonde la fisicità analogica con l’imprevedibilità del digitale. In questa intervista, ci racconta di come il recupero di tecnologie obsolete possa generare nuove narrazioni visive, portando il suo lavoro a evolversi verso la creazione di mondi ibridi tra flora e fauna, e di come l’IA sia diventata uno strumento di collaborazione attiva nel suo processo creativo.
Dalle sue creature aliene fino alla creazione di esperienze immersive, il suo sguardo sul futuro è tanto critico quanto visionario. Un viaggio tra memoria e innovazione, dove il passato non è mai davvero superato, ma si trasforma in materia viva per costruire un futuro ancora incerto, ma ricco di sorprese.
Questa intervista si colloca nella più ampia visione del magazine di offrire uno spazio unico ai creativi di tutto il mondo che utilizzano la tecnologia come ampliamento delle loro possibilità espressive. A partire da quest’anno, la rubrica includerà anche interviste a ingegneri, programmatori, matematici e imprenditori, per diversificare i contenuti e promuovere l'idea che la creatività non appartiene solo ad artisti e designer, ma che si tratta di un raffinato processo di problem solving intrinseco alla natura dell’essere umano e alle sue capacità cognitive.

Nella tua biografia ti definisci come un "archeologo dei media", un termine che mi ha incuriosito molto, ti andrebbe di spiegarci che cosa significa? È legato al tuo rapporto con la tecnologia?
Sono sempre stato affascinato dai racconti delle generazioni precedenti riguardo l'avvento di innovazioni tecnologiche rivoluzionarie - come quando i miei nonni mi raccontavano lo stupore e il cambiamento sociale provocato dall'arrivo della prima televisione nelle loro case. Quando lavoro con l'intelligenza artificiale generativa, non mi vedo semplicemente come un utilizzatore di strumenti, ma piuttosto come un documentarista che esplora e fotografa le possibilità immaginative e trasformative intrinseche a questa tecnologia. Ogni pezzo di tecnologia, che sia un vecchio apparecchio audiovisivo o un modello AI, porta con sé una propria voce, una propria storia, una propria influenza sul risultato finale.
Spesso si pensa all’innovazione come a un processo di superamento del passato, mentre tu sembri interessato a rispolverare. Il che può sembrare anche insolito, dato che sui social ti chiami "newmediapioneer". Cosa ti spinge a scavare nei vecchi media per la tua comunicazione?
Quando macchine costruite in periodi diversi entrano in dialogo tra loro si crea una sorta di alchimia temporale dove passato e presente possono incontrarsi o scontrarsi, per generare uno tipo di sguardo archeologico: dopo tutto ciò che oggi viene celebrato come il futuro, spesso accompagnato da un marketing che ne amplifica l'hype, è destinato inevitabilmente a diventare passato. Essere un new media pioneer, per me oggi significa documentare e immaginare attivamente l'evoluzione di questi dispositivi mentre avviene.
Nel 2019 hai trasformato una perdita in una nuova direzione creativa, riconvertendo apparecchiature obsolete in installazioni di videoarte. Puoi raccontarci di quel periodo?
Nel 2019 ho vissuto un momento di transizione cruciale dopo aver partecipato per diversi anni alla gestione di un emittente TV locale insieme ad altri soci fondatori che animavano quella che era chiamata Telelissone e poi TMB, Tele Monza Brianza. Quando l'interesse generale nel progetto iniziò a scemare, mi ritrovai solo e decisi a malincuore di interrompere questa avventura. Fu proprio in quel momento che realizzai quanto le competenze acquisite potessero essere riconvertite in una nuova direzione. Davanti a me si apriva un intero universo di possibilità: mixer analogici, generatori di segnale, filtri, monitor, telecamere - apparecchiature ancora perfettamente funzionanti ma considerate obsolete per la produzione commerciale. Scoprii un mondo di connessioni possibili e di "voci" che aspettavano di essere liberate da queste tecnologie, rimaste in silenzio dopo che il gruppo umano che le utilizzava aveva cambiato rotta.
Questo passaggio si rivelò sorprendentemente liberatorio. Mi permise di affrancarmi dalle dinamiche di produzione legate a esigenze commerciali per esplorare una dimensione più puramente artistica. La vera gratificazione che trovai in questa trasformazione fu l'opportunità di abbandonare la manipolazione visiva mediata dal computer – mouse, tastiera, tavolette grafiche e touchscreen – per riscoprire qualcosa di profondamente fisico: collegare cavi BNC o RCA in matrici complesse, manipolare direttamente bottoni, fader e altri dispositivi di controllo.
Questa esplorazione ha aperto la strada alla mia ricerca di visual originali per alimentare le installazioni di videoarte che stavo creando. Paradossalmente, questo percorso mi ha poi riportato "nella scatola" – inside the box, nel computer – per iniziare, tra il 2021 e il 2022, la mia esplorazione nel mondo dell'intelligenza artificiale generativa.
Dal teatro alla fotografia, dal design alla televisione: il tuo percorso è stato tutt’altro che lineare. Quanto è importante, secondo te, l’adattabilità per chi lavora con i media e la tecnologia?
Il mio bagaglio di esperienze professionali diverse rappresenta una ricchezza non tanto di esecuzione pratica di processi, ma prima di tutto di vocabolario e di gergo tecnico che mi permette di rievocare professionalità, mood e timbri sonori piuttosto che mondi visivi. Quando lavoro con l'intelligenza artificiale, attingo costantemente a questo repertorio di conoscenze stratificate. È come una forma di "crate digging" professionale: recupero elementi da varie discipline e li metto in dialogo tra loro.
Questa interdisciplinarietà mi permette di vedere possibilità che potrebbero sfuggire a chi ha seguito percorsi più lineari. La vera potenza dell'adattabilità nell'era dell'AI generativa sta proprio in questa capacità di orchestrare dialoghi tra linguaggi diversi. Non si tratta semplicemente di imparare nuovi strumenti, ma di comprendere le logiche profonde che li accomunano e di saper tradurre concetti da un dominio all'altro. È un'abilità che diventa sempre più preziosa man mano che le tecnologie evolvono rapidamente e richiedono continuamente nuove modalità di interazione.
L’intelligenza artificiale è entrata nel tuo processo creativo nel 2021. Cosa ha rappresentato per te questa transizione? Quali possibilità ha aperto che prima non immaginavi?
Affacciarsi sul mondo dell'AI, interessato a capire sempre di più e a restare aggiornato su quello che si muove in questo campo, è stata prima di tutto l'occasione per entrare in contatto con persone e iniziative sempre più interessanti: dal progetto collettivo "OUR T2 REMAKE” del 2023 alla nomination ai The [esc] Awards di pochi giorni fa.
Un aspetto particolarmente affascinante di questa transizione è stato scoprire come l'AI possa funzionare non solo come strumento, ma come collaboratore nella creazione. Nel mio progetto LAPSES, curato attualmente da Fellowship in Daily Highlights, ad esempio esploro come sistemi AI interpretano e trasformano input geometrici in realtà fotografica, rivelando nel processo come questi sistemi "comprendono" e costruiscono il mondo visivo. Questa evoluzione mi ha portato da un approccio di semplice implementazione a un vero e proprio modello di co-creazione. Forse la possibilità più sorprendente è stata scoprire che, attraverso l'AI, posso non solo creare arte ma anche costruire strumenti personalizzati per crearla - un passaggio fondamentale che trasforma il rapporto tradizionale tra artista e strumento, rendendo il confine tra creazione artistica e sviluppo di strumenti sempre più fluido e dinamico.
Le tue creature aliene simili a piante sono molto suggestive e attorno a esse hai creato dei mondi unici. Da dove nasce questo immaginario?
Ho esplorato a lungo la dimensione ibrida la tra locomozione e l'essere radicati al suolo, abitata da creature impossibili ma fotorealistiche al confine tra flora e fauna. Questa serie, LONELY ANTS, è stata esposta fino al 12 gennaio 2025 presso la Stadthausgalerie di Sonthofen (Germania). Su una scala diversa di grandezza, però sempre lavorando su questo tema di spostare verso il regno vegetale una mobilità che nell'esperienza cognitiva quotidiana è appannaggio del regno animale, ho esplorato una dimensione più ampia con G.I.A.N.T.S. per la rassegna Daily curata da Fellowship durante l’estate 2024.
Nel mio ultimo lavoro, LAPSES, esploro questo tipo di infusione di movimento in ciò che di solito concepiamo come statico, a livello di paesaggi, ecosistemi e anche interi pianeti. Questo immaginario per me è una chiave per esplorare le potenzialità immaginative delle AI che non potrebbero rivelarsi se non andando a stimolare qualcosa che non è immediatamente concepibile per noi umani, ma che testimonia anche la capacità emergente di creare qualcosa di credibile, quasi verosimile, ma completamente nuovo rispetto ai dataset su cui questi modelli sono stati allenati.
Ci puoi raccontare della tua collaborazione con Dreamflare e delle sfide che hai affrontato nella creazione dell'opera interattiva Deep?
La prima sfida è stata bilanciare una dimensione documentaristica con una dimensione di prodotto di intrattenimento che, per design della piattaforma Dreamflare, richiedeva anche interattività su una durata complessiva di più di 12 minuti. Inoltre, anche se è passato solo un anno, avevamo a disposizione strumenti molto più rudimentali. Per esempio, semplici scene con un punto di vista in prima persona per esplorare gli ambienti che potevano essere quelli di un veicolo sottomarino non erano purtroppo ancora producibili. Ricordo di aver depennato dalla mia ipotesi di sceneggiatura tantissime soluzioni, molti tipi di inquadrature, proprio per i limiti imposti dalla tecnologia di quel periodo.
Come bilanci la tua visione con l'imprevedibilità dell'IA generativa? Quando lavori con questi strumenti ti senti più creatore o co-creatore?
L'imprevedibilità dell'AI generativa è un valore aggiunto di questo medium. Mi sento come un esploratore, affascinato da questo non-controllo, come avere a che fare con una strumentazione analogica in cui l'accordatura è ancora più preziosa e apprezzabile proprio perché è così difficile mantenerla a lungo. Gli output selezionati che tra centinaia o tra migliaia, finiscono per entrare a far parte di un'opera finita sono proprio tanto più preziosi quanto rappresentano dei momenti di interazione quasi irripetibile.
C’è qualcosa che vorresti sperimentare nei tuoi prossimi progetti?
Sì, credo che il prossimo futuro vedrà i pionieri dell'intelligenza generativa essere impegnati e richiesti a sperimentare un nuovo paradigma di media che già esistono come prototipi: il mondo delle esperienze videoludiche generate da IA. Passeremo dal generare immagini e clip video a creare intere esperienze immersive tramite prompt, aprendo un territorio inesplorato dove i confini tra artista, designer e sviluppatore si faranno ancora più sfumati. È una direzione che mi entusiasma perché rappresenta l'evoluzione naturale del dialogo tra macchine che sto già esplorando nei miei progetti attuali. Con LAPSES ho iniziato a creare generatori parametrici che fungono da partecipanti in un dialogo tra diversi domini visuali. Portare questo approccio nel contesto di esperienze interattive complete significherebbe aggiungere un nuovo livello di complessità a questo scambio, includendo anche l'interazione umana in tempo reale. In fondo, la mia pratica di archeologia dei media è sempre stata orientata a documentare i momenti di transizione tecnologica. E questa potrebbe essere una delle più affascinanti: il punto in cui non generiamo più solo contenuti, ma intere esperienze.
L’angolo degli annunci
Questo è un nuovo spazio, precedentemente integrato nella parte introduttiva del magazine, che voglio dedicare a vari tipi annunci legati a questo progetto.

Per il 2025 voglio tentare di trasformare questo magazine in una vera e propria Startup innovativa, collocata all’intersezione tra il mondo dei media e della tecnologia. Per farlo, le mie sole forze non bastano e cerco qualcuno con cui espandere il team di lavoro, così da poter creare più contenuti e portare gli approfondimenti di Tales from the Latent Space anche su Instagram per ampliare la portata del progetto. Cerco quindi una collaborazione a medio-lungo termine per gestire la pagina del magazine e creare più contenuti. Si offre una quota in quella che sarà la futura azienda legata al magazine (con un contratto) e formazione di alto livello sui principali strumenti AI, in cambio di una ragionevole quantità di tempo da concordare. Se l'idea ti intriga o conosci qualcuno con la giusta ambizione e competenza che possa abbracciare questa missione, contattami su LinkedIn.
Prossimamente, condividerò anche il business plan della startup, che si chiamerà Monumenta AI e non sarà legata solo ai media, insieme a un manifesto d’intenti che racconti la visione complessiva del progetto.