


Voci dal Nuovo Mondo
Ciò che oggi è solo rumore diventerà linguaggio domani. Così le macchine iniziarono a sussurrare agli umani


ATTENZIONE! DISCLAIMER IMPORTANTE:
A seguito della pubblicazione del mese scorso, c’è chi mi ha fatto notare una cosa che ha un po’ turbato la mia quiete personale: Se leggi questo magazine direttamente dall’email, senza aprirlo nella piattaforma di Substack, potresti finire col per perderti una buona parte dei suoi contenuti. Ma qual è il motivo?
Come cerco di far capire di mese in mese, a ogni pubblicazione, questo è un vero e proprio magazine e non una semplice newsletter come le altre. In quanto tale, questo è un prodotto con una certa struttura e lunghezza, che non può essere letto nel giro di pochi minuti ma richiede un po’ più di impegno. Ogni mese, Tales from the Latent Space offre diversi contenuti esclusivi, tra cui articoli di approfondimento molto dettagliati e diverse rubriche ricorrenti di gran valore. Tutto questo comporta un problema per i vostri provider di posta elettronica:
Troppo testo, troppe immagini, troppe informazioni da visualizzare e hostare.
Io stesso ero al corrente di questa problematica, anche perché è la stessa Substack a farmelo notare ogni volta dandomi questo avviso fastidioso:

Non avevo mai dato importanza a questa cosa finché l’intervistata dell’ultimo numero non mi ha chiesto “ma quando esce l’intervista?” circa una settimana dopo averla pubblicata, e io non capivo il senso della domanda, perché le avevo già spiegato che sarebbe stata contenuta nel numero di marzo. Lì mi ha spiegato che non l’aveva visualizzata per via di questa limitazione delle caselle di posta elettronica.
A quel punto mi sono domandato: a quante altre persone sarà già successo? In quanti avranno pensato che il magazine si interrompesse dopo la rubrica sugli avvenimenti del mese? Ecco quindi il motivo di questo disclaimer.
Il magazine è molto più lungo e ricco di contenuti rispetto a quello che potresti vedere all’interno della tua casella email, ma per addentrarti veramente all’interno del nuovo mondo, è importante aprire la pubblicazione dalla piattaforma di Substack. Va bene sia da browser che dall’app mobile, basta solo che non pensiate: tutto qui?
L’idea che molte persone possano essersi perse una grossa parte dei contenuti di questo magazine per quasi un anno mi lascia profondamente turbato.
E qui c’è da imparare una lezione importante: mai dare nulla per scontato.
Per me era ovvio pensare che tutti avrebbero capito che la troncatura era dovuta ai limiti delle email, ma a quanto pare non lo era poi così tanto.
Mi sento quindi di volermi scusare se qualcuno si fosse perso qualcosa a causa di una mancata comunicazione su questo fronte, sappiate comunque che qui su Substack esiste un pratico Archivio nel quale si possono recuperare tutte le pubblicazioni del passato (non si sa mai che a qualcuno venga il dubbio di essersi perso qualcosa).
Come spesso accade, l’introduzione è stata più lunga del previsto, e il nostro treno è in arrivo al primo binario. Allontanarsi dalla linea gialla!

Cosa sono i Modelli di Diffusione Latente?
Immaginate di osservare la fotografia di un cane che, a poco a poco, viene ricoperta da una nebbia di puntini; poi, premendo “reverse”, quella stessa nebbia si ritira e appare l’immagine di quel cane in un nuovo contesto. I modelli di diffusione funzionano proprio così: imparano a trasformare del rumore casuale in contenuti coerenti applicando, passo dopo passo, un processo di “pulizia” detto diffusione.
I Modelli di Diffusione Latente (Latent Diffusion Models, LDM) eseguono questo processo in modo elegante: invece di lavorare su ogni pixel, effettuano la magia in uno spazio compatto (il famoso Spazio Latente), creato da un autoencoder. È come se il restauro della nostra immagine avvenisse su una tela ridotta, più gestibile, per poi essere ingrandita senza perdere dettagli. In questo articolo esploreremo cosa sono gli LDM, perché rappresentano un’evoluzione cruciale dei modelli di diffusione (DM) e come riescono a rendere accessibile la generazione di immagini (e non solo).

Negli ultimi anni, i modelli di diffusione hanno rivoluzionato il panorama del deep learning generativo, imponendosi come una delle architetture più promettenti per la sintesi di immagini, audio e dati altamente strutturati. Per comprendere appieno questo tipo di modelli, è necessario fare alcuni passi indietro e ripercorrere brevemente l’evoluzione dei Diffusion Models (DM), dai loro albori fino alle recenti innovazioni con gli spazi latenti ad alta efficienza computazionale.
L’idea di base dei DM risale al paper del 2015 Deep Unsupervised Learning using Nonequilibrium Thermodynamics, che introdusse una catena di Markov generativa che converte una semplice distribuzione nota (ad esempio una gaussiana) in una distribuzione target (dati) utilizzando un processo di diffusione: partendo dai dati puliti, si aggiunge progressivamente rumore (forward process) e poi si impara a invertire tale processo per rigenerare i dati originali (reverse process). Fu poi il lavoro Denoising Diffusion Probabilistic Models (2020) di Ho, Jain e Abbeel a rendere questo approccio praticabile su larga scala, proponendo una formulazione semplificata e un’efficace implementazione del metodo di diffusione.
I ricercatori hanno dimostrato che, con abbastanza passaggi, i DM superavano i Generative Adversarial Network (GAN) in qualità dei campioni. Lavorare nello spazio RGB non è però un qualcosa di semplice, perché significa dover calcolare gradienti su tutti i pixel, rendendo l’addestramento dei modelli più potenti un’impresa da migliaia di ore su GPU ad alte prestazioni e l’inferenza una lenta sequenza di valutazioni complesse. Per ridurre l’onere computazionale si sono sperimentate strategie di campionamento accelerato e approcci gerarchici, ma il fardello dei “troppi pixel” restava un gran problema irrisolto.
Il passo decisivo è stato cambiare prospettiva: perché non spostare l’intero processo in un altro spazio, dove l’immagine sia rappresentata da molti meno numeri senza che perda le informazioni visive essenziali? Da questa domanda, nel 2021 viene pubblicato il paper High-Resolution Image Synthesis with Latent Diffusion Models e nasce l’architettura basata su Diffusione Latente.
Oggi i LDM dominano le competizioni di class‑conditional image synthesis e super‑risoluzione, offrendo qualità di gran lunga superiore rispetto a GAN e modelli autoregressivi senza soffrire di collasso di modalità o instabilità nel training. Va però notato che l’elevata dimensionalità dello spazio pixel e il numero elevatissimo di step richiesti (da decine a centinaia) rendono questi modelli molto costosi, sia in termini di GPU‑day che di tempo di inferenza.

Comprendere l’architettura di un LDM
Per capire il valore di un LDM occorre cogliere il paradosso dei DM classici: mentre la loro formulazione matematica ignora le “imperfezioni” che l’occhio umano non nota, la rete deve comunque processare tutti i pixel. Ecco perché il costo resta elevato. Spostandoci nello spazio latente, invece, possiamo:
Comprimere percettivamente l’immagine, eliminando il superfluo.
Allenare il modello di diffusione in questo spazio compatto.
Decodificare il risultato in pixel con un solo passaggio della rete.
Il paper sui LDM mostra che il processo di apprendimento si divide naturalmente in due fasi: prima si impara a comprimere (rimuovere dettagli ad alta frequenza), poi a ricostruire semanticamente la scena. Far emergere queste due fasi in architetture distinte, autoencoder + diffusione, è la chiave dell’efficienza.
Il risultato è uno spazio in cui ogni punto rappresenta ancora il contenuto semantico dell’immagine, mantenendo però delle dimensioni estremamente contenute. Dato che la densità dei dati è minore rispetto ai modelli probabilistici di diffusione, ogni step è più veloce e la catena di campionamento può essere più corta senza perdere fedeltà.
In diverse prove, gli LDM:
Raggiungono nuovi record nella tecnica dell’inpainting nella generazione di volti avendo solo un terzo dei parametri di alcuni GAN avanzati.
Con appena 1.45B di parametri, competono con modelli tra 4 e 6 miliardi di parametri nella sintesi testo‑immagine.
Rendono possibile il sampling di immagini 1024×1024 su una sola GPU consumer nel giro di pochi secondi, grazie al decodificatore unico.
Produrre 50. 000 campioni richiede circa 5 giorni per un DM pixel‑based mentre, a parità di hardware, un LDM scende sotto le 24 ore.
Per spiegare tutto in altre parole, forse più semplici:
I Modelli probabilistici di diffusione (DM) partono da un'immagine sfocata e applicano ripetutamente dei passaggi (iterazioni) per diffondere e distribuire le sue informazioni, rendendola sempre più nitida e definita. Questi modelli vengono allenati su grandi quantità di immagini, che vengono gradualmente scomposte in “rumore”, dal quale si generano poi le future immagini.
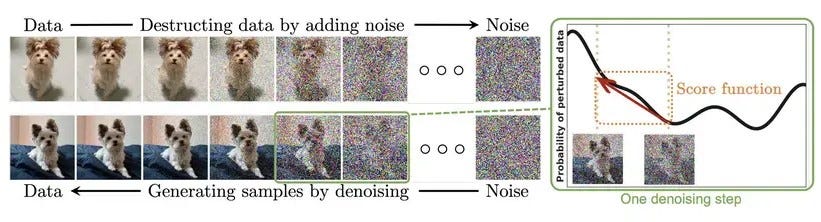
Durante la diffusione, il modello utilizza la distribuzione di probabilità (quanto è probabile che accada X, date le variabili Y) per determinare come l'informazione si diffonde a ogni passaggio. In questo modo l'immagine subisce una serie di trasformazioni che ne migliorano progressivamente la qualità. Questo processo continua fino a quando non si arriva al numero massimo di iterazioni prestabilite.
I modelli di diffusione latente (LDM), invece, non si concentrano direttamente sulla distribuzione probabilistica dei dati, ma sulla trasformazione della loro rappresentazione latente. Quindi, al posto di generare l’immagine partendo dal rumore in base a un calcolo di probabilità, il modello interpreta le rappresentazioni latenti (le rappresentazioni compresse in vettori numerici contenuti nello spazio latente) e le adegua alla richiesta tramite la diffusione dello stesso rumore. A livello fondamentale, possiamo quindi dire che cambia l’approccio alla diffusione del rumore.

Questo approccio permette ai LDM di manipolare i dati in modo più flessibile e complesso. Rispetto ai DM, i Latent Diffusion utilizzano il concetto di diffusione per guidare la trasformazione dell'informazione e offrire un maggior controllo e adattabilità nel diffondere il rumore, che si traduce in output più dettagliati.
Conclusioni non Banali
A partire dal 2022 gli LDM hanno compiuto un atto di scaltrezza ingegneristica: spostare la complessità dal dominio dei pixel allo spazio latente, sbloccando la generazione di immagini realistiche su GPU alla portata dei consumatori. Nascono quindi i primi modelli open-source come Stable Diffusion, che hanno ridefinito le possibilità dei computer domestici e permesso la nascita di floride community di sviluppatori indipendenti, appassionati, artisti, ricercatori e visionari da tutto il mondo. Se ci fermassimo qui, però, racconteremmo solo metà della storia. Nel triennio 2023‑2025 la tecnica della diffusione latente si è propagata ‑ ironia della terminologia ‑ come una vera e propria reazione a catena.

L’era dei modelli multimodali
Il paper Diffusion Models For Multi-Modal Generative Modeling ipotizza come estendere la formula dei modelli ibridi testo‑immagine a modelli veramente multimodali, capaci di utilizzare il rumore e la tecnica della diffusione per generare diversi tipi di output. Questa convergenza abbatte le barriere di formato: un prompt vocale può generare un’animazione, un’immagine può suggerire una colonna sonora, un video può far emergere un testo, e via intrecciando. Lo spazio latente diventa così un luogo di negoziazione semantica, all’interno del quale tutto sembra possibile.
Rumore linguistico
Nel 2025 crescono gli sviluppi sulle nuove famiglie di LLM basati su diffusione (DLM) che mettono in discussione il dominio dei modelli autoregressivi. Il paper Scaling Diffusion Language Models via Adaptation from Autoregressive Models mostra che è possibile “convertire” un modello AR in un DLM mantenendo la stessa architettura Transformer, ma con una miglior controllabilità.
L’idea di usare la diffusione per il linguaggio emerge però già nel 2022 con il paper Diffusion-LM Improves Controllable Text Generation, quando i ricercatori hanno intuito che una sequenza testuale può essere trattata come un vettore continuo su cui aggiungere e togliere rumore, proprio come si fa per le immagini. Il prototipo Diffusion‑LM ha mostrato che, partendo da vettori di rumore gaussiano e processi denoising iterativo, è possibile controllare con precisione la sintassi e lo stile meglio di molti modelli autoregressivi della stessa taglia.
Il vero punto di svolta arriva però nel febbraio 2025, quando Inception Labs ha annunciato Mercury, definito “il primo large language model di diffusione su scala commerciale”. Mercury opera con un processo di generazione "da grossolano a fine", in cui l'output viene raffinato a partire dal rumore puro attraverso alcuni passaggi di denoising, raggiungendo throughput tra cinque e dieci volte superiore a GPT‑4 Turbo a parità di hardware (secondo i test interni di Inception Labs).
La terza dimensione prende forma
La rivoluzione inaugurata dalla tecnica di diffusione latente si è spinta ben oltre la rappresentazione di singoli fotogrammi bidimensionali, o insiemi di fotogrammi per la generazione di video: oggi la stessa idea, con i dovuti accorgimenti, può generare oggetti e ambienti tridimensionali. Il passaggio cruciale è stato coniugare la generazione di immagini con tecniche di resa volumetrica.
Nel 2022, DreamFusion traduceva un prompt testuale in mappe di profondità provvisorie, ottimizzate nello spazio latente per produrre mesh con texture coerenti senza bisogno di dati 3D nel suo training. Parallelamente, la linea di ricerca Latent‑NeRF ha eliminato l’ottimizzazione per‑scena tipica dei NeRF tradizionali: il rendering volumetrico avviene direttamente nello spazio latente, in modo che l’intero oggetto venga generato con una decina di passi di diffusione, riducendo di dieci volte il costo computazionale richiesto per questo tipo di operazioni.
Ulteriori progressi arrivano dall’incontro con la tecnica del Gaussian Splatting, dove il modello non ricostruisce voxel né triangoli, ma un insieme di ellissoidi colorati che possono essere rasterizzati in tempo reale da qualsiasi angolazione. La proposta DiffGS presentata al NeurIPS 2024 unisce due idee chiave: il Gaussian Splatting, che rappresenta la scena come un insieme di piccoli ellissoidi Gaussiani colorati proiettati via rasterizzazione, e la diffusione latente, che impara a generare nuove forme 3D addestrandosi a rimuovere progressivamente il rumore nello spazio latente.
Il risultato è una pipeline capace di produrre oggetti 3D di alta qualità: sulle sedie (sottocategoria “Chair” del benchmark ShapeNet) ottiene un FID‑50K di 35.3 e un KID‑50K di 2.15 ‰, sulla classe degli aeroplani (sottocategoria “Airplane” del benchmark ShapeNet) un FID‑50K di 47.0 e un KID‑50K di 3.44 ‰, mentre la ricostruzione interna delle primitive Gaussiane raggiunge un PSNR (Peak Signal‐to‐Noise Ratio) di 34.0 dB, SSIM di 0.9879 e LPIPS di 0.0149 con circa 350.000 Gaussiane.
Dove stiamo andando?
Verso spazi latenti più intelligenti che compressi. Al posto di ridurre soltanto la dimensionalità, i nuovi auto‑encoder incorporano concetti astratti (fisica basilare, matematica, regole di linguaggio) per alleggerire il lavoro della rete di diffusione: non è più “meno pixel”, ma “più semantica per pixel”.
I Modelli di Diffusione Latente sono passati dall’essere un’ingegnosa ottimizzazione del 2022 a diventare, nel 2025, una delle architetture più importanti dell’AI generativa.
Negli ultimi lavori sui diffusion model è emerso chiaramente che lo spazio latente non è più un semplice depositario di feature compresse, ma contiene direzioni semantiche stabili e interpretabili, note come h‑space, che permettono manipolazioni semantiche lineari e robuste delle immagini e non solo.
I classici autoencoder puntavano solo a ridurre la dimensionalità tramite un collo di bottiglia, perdendo però molte informazioni di alto livello. I nuovi AE, invece, incorporano vincoli tratti dalla fisica (autoencoder con dinamiche vincolate per modellare leggi fisiche) per rendere interpretabili e generalizzabili gli stati latenti. Analogamente, in ambito linguistico si sono sviluppati AE che identificano e condividono concetti morfosintattici tra modelli di linguaggio multilingue, dimostrando l’integrazione di regole grammaticali nello spazio latente.
I LDM fungono da ponte metaforico: partendo dal caos del rumore casuale, attraversano uno spazio latente semanticamente arricchito e generano forme coerenti e creative. Questo processo può essere visto come sintesi statistica che diventa generazione di “nuovi mondi” grazie alle direzioni semantiche individuate nei latenti. Chi saprà attraversare questo ponte con curiosità e senso critico sarà protagonista nel definire i nuovi paradigmi creativi nati dall’ibridazione tra mente umana e AI.
Avvenimenti del mese
Le notizie più interessanti, importanti o creative dal mondo della tecnologia, accuratamente selezionate per districarsi tra il rumore informativo.

L’era del cinema AI
Il 31 marzo Runway lancia Gen-4, il suo nuovo modello che permette di generare video con personaggi, ambientazioni e oggetti totalmente coerenti.

Gen-4 consente una coerenza delle scene pressocché totale utilizzando semplicemente immagini di riferimento e prompt testuali. Il sistema mantiene intatte le peculiarità stilistiche, il mood e gli elementi cinematografici di ogni fotogramma, consentendo di riprodurre soggetti e ambienti da diverse prospettive senza la necessità di LoRA.
La tecnologia Gen-4 è già stata messa alla prova nella realizzazione di cortometraggi e videoclip musicali, dimostrando notevoli capacità narrative e creative. Le possibilità offerte da questo strumento spaziano dalla produzione cinematografica alla fotografia commerciale, passando per soluzioni ibride tra IA e realtà come i GVFX.
Poco dopo, il 7 aprile, viene rilasciato Gen-4 Turbo, una versione molto più rapida di Gen-4 che genera video di 10 secondi in soli 30 secondi di inferenza.
Controllare una camera virtuale nello spazio latente
Sempre il 31 marzo, la startup Higgsfield lancia il suo nuovo modello AI per i video, che ha come caratteristica principale il controllo dei movimenti di camera.

Il modello di Higgsfield consente dei movimenti di camera estremamente complessi con una precisione mai vista: crash zoom, whip pan, snorricam, dolly zoom, crane, robo arm, bullet time, inseguimenti in FPV. Qualunque cosa possa fare una videocamera reale, con l’ausilio di attrezzature costose e difficili da manovrare, questo nuovo modello può replicarla fedelmente e con una facilità di utilizzo incredibile.
Influencer AI che sembrano veri
Il 2 aprile Argil, startup incubata da Y Combinator, lancia il suo modello AI per la creazione di avatar digitali con un grado di realismo senza precedenti.

La vera rivoluzione di Argil non sta tanto nel realismo degli avatar, che è comunque sorprendente, ma nel controllo che la piattaforma offre. Infatti non stiamo parlando di un servizio come Synthesia o Heygen, in cui l’avatar rimane statico e poco espressivo.
Argil ci permette di dirigere il personaggio come se fossimo su un set. Si parte dalla creazione dell’avatar, per poi fornirgli una storia di background per renderlo più “umano” e realistico, potendolo poi riprendere in qualunque contesto. Possiamo anche dirigere il body language, fargli indossare abiti brandizzati e cambiare inquadrature mentre parla come una regia multi-cam. La piattaforma offre anche la possibilità di clonare noi stessi o chiunque ci abbia dato il consenso per farlo.
Un altro mese di dominazione per Google
Sempre il 2 aprile, NotebookLM, uno dei prodotti di punta di Google, ha ricevuto un importante aggiornamento che gli permette di ricercare fonti esterne sul web.

NotebookLM è uno strumento che si basa prettamente sulle fonti caricate dagli utenti, sfruttando i modelli Gemini per ottenere informazioni a riguardo. Con il nuovo aggiornamento, è possibile ricercare nuove fonti direttamente dal web tramite un prompt, per poi importarle nello strumento e lavorarci con l’IA.
Il 7 aprile viene lanciata ufficialmente la funzionalità che permette agli utenti di chiedere a Gemini informazioni su ciò che vedono tramite schermo o fotocamera.
Diventa quindi possibile condividere con Gemini lo schermo del proprio dispositivo mobile o dargli accesso alla fotocamera per fargli vedere l’ambiente circostante. La funzionalità è disponibile da subito sugli smartphone Pixel 9 e Samsung Galaxy S25 e per gli utenti Advanced che hanno un device android.
L’8 aprile Google Research presenta Geospatial Reasoning, un framework di ricerca che unisce modelli geospaziali di base e AI generativa per semplificare e velocizzare l’analisi di dati geospaziali complessi.

Basato su Gemini 2.5, il sistema introduce nuovi modelli di remote sensing addestrati su milioni di immagini satellitari e aeree ad alta risoluzione, corredate da descrizioni testuali e annotazioni a bounding box. I modelli fondativi per il telerilevamento si basano su architetture consolidate come masked autoencoders, SigLIP, MaMMUT e OWL-ViT, generando embedding utilizzabili per retrieval e classificazione zero-shot. Le valutazioni su benchmark di classificazione, segmentazione e object detection hanno evidenziato prestazioni allo stato dell’arte.
Geospatial Reasoning sfrutta Gemini per trasformare query in linguaggio naturale in workflow agentici, orchestrando inferenze attraverso modelli Google, dati proprietari e fonti pubbliche sulla piattaforma Google Cloud. Il framework è disponibile tramite un trusted tester program con partner iniziali quali WPP, Airbus, Maxar e Planet Labs. Gli interessati possono compilare il form sul sito di Google Research per richiedere l’accesso ai modelli e sperimentare con workflow personalizzati.
Nei prossimi mesi Google condividerà ulteriori dettagli su dataset, valutazioni e integrazioni con nuovi settori industriali, puntando a democratizzare l’analisi geospaziale grazie alla sinergia tra AI generativa e modelli specializzati.
L’8 aprile viene aggiornato il Deep Research di Gemini.
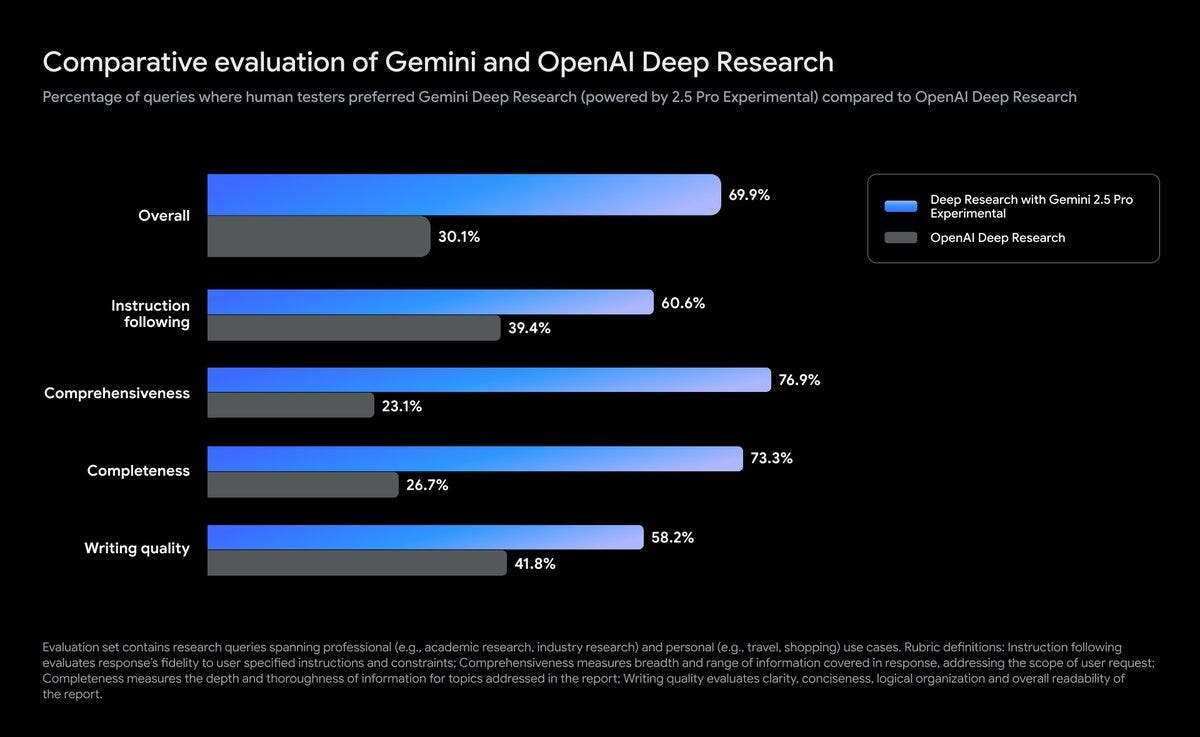
Ora si basa su Gemini 2.5 Pro e batte la versione di OpenAI basata su o3. Questa nuova versione, disponibile solo agli utenti Advanced, può fornire report più approfonditi, ragionare meglio sulle fonti che sta analizzando e trovare, gestire e sintetizzare più informazioni grazie all’enorme finestra di contesto di Gemini 2.5 Pro.
Il 9 aprile viene lanciato in anteprima Firebase Studio, un ambiente di sviluppo agentico basato su e progettato per accelerare la creazione, il test, il deploy e l’esecuzione di applicazioni in un’unica piattaforma.

Firebase Studio integra strumenti come Project IDX, Genkit e Gemini in Firebase per un’esperienza unificata che offre prototipazione, workspace di coding e opzioni di deployment flessibili, pensata sia per chi vuole prototipare velocemente nuove funzionalità con linguaggio naturale sia per gli sviluppatori più esperti che preferiscono controllare il proprio stack e sfruttare VM personalizzabili.
Con l’App Prototyping agent di Firebase Studio è possibile generare un prototipo funzionante di applicazione web (basata su Next.js) in pochi secondi, usando semplici prompt, immagini o disegni. Il sistema configura automaticamente Genkit e fornisce una chiave API di Gemini per rendere operative le funzionalità AI out-of-the-box, senza alcuna configurazione manuale.
L’iterazione è immediata grazie alla chat AI integrata: basta chiedere a Gemini di aggiungere l’autenticazione utenti, modificare il layout, perfezionare l’interfaccia o inserire nuove funzionalità, e l’agente comprenderà la codebase per applicare le modifiche desiderate. Per chi preferisce un approccio più tradizionale, è possibile passare a un workspace di coding basato su CodeOSS, completo di assistenza Gemini per il completamento del codice, il debug, la spiegazione della codebase, accesso al terminale e integrazioni con gli altri servizi Firebase.
La fase di test diventa rapida e intuitiva: basta generare un URL pubblico o un QR code per visualizzare un prototipo su qualsiasi dispositivo, dal desktop allo smartphone, senza dover configurare ambienti in locale. Quando il prototipo è pronto per il feedback, un click su “Publish” sfrutta Firebase App Hosting per gestire build, CDN e server-side rendering, offrendo un’esperienza di deploy one-click.
Si può anche collaborare in tempo reale, condividendo sia il link all’app in produzione, ma anche l’intero workspace di Firebase Studio, invitando altri sviluppatori a modificare e aggiornare il progetto simultaneamente.
Firebase Studio include tutte le funzionalità di Project IDX — VM cloud personalizzabili via Nix, emulatori integrati, oltre 60 template ufficiali, import da repository Git e template personalizzati.
La piattaforma è disponibile da subito in preview gratuita con 3 workspace inclusi; gli iscritti al Google Developer Program ne hanno 10, mentre i membri Premium arrivano a trenta, con alcune integrazioni (come Firebase App Hosting) che richiedono un account di fatturazione attivo.
Il 14 aprile, in occasione del National Dolphin Day, Google annuncia DolphinGemma, un modello AI da circa 400 milioni di parametri progettato per comprendere e riprodurre le strutture comunicative dei delfini.

L’iniziativa nasce dalla collaborazione tra Google DeepMind, il Georgia Tech e il Wild Dolphin Project (WDP), l’iniziativa di ricerca subacquea più longeva al mondo dedicata allo studio dei delfini maculati atlantici nelle Bahamas. Da oltre trent’anni, il WDP raccoglie dataset unici di video e audio associati a identità, storie di vita e comportamenti dei singoli delfini, offrendo il contesto necessario per una comprensione approfondita del loro linguaggio.
DolphinGemma utilizza la tecnologia di tokenizzazione SoundStream per codificare i suoni dei delfini in unità manipolabili, processate da un’architettura ottimizzata per sequenze complesse. Simile ai modelli di linguaggio umano, l’IA è in grado di prevedere la successiva emissione sonora all’interno di una sequenza, consentendo non solo l’analisi ma anche la generazione di vocalizzazioni come quelle dei delfini.
Il modello è stato concepito per operare direttamente sui dispositivi Pixel: oggi sfrutta il Pixel 6 per le analisi in tempo reale, mentre la prossima generazione, basata sul Pixel 9, integrerà capacità avanzate di deep learning e template matching, mantenendo costi e consumi ridotti per l’utilizzo in mare aperto.
Google prevede di rilasciare DolphinGemma in modalità open source durante l’estate, consentendo ai ricercatori di tutto il mondo di adattare il modello a diverse specie di cetacei, dal tursiope al delfino spinner, grazie alle possibilità di fine-tuning.
Il 17 aprile lancia Gemini 2.5 Flash in versione sperimentale, il suo primo modello di ragionamento ibrido che regola l’intensità del ragionamento in base alla richiesta.

Gemini 2.5 Flash è disponibile in preview sull’app Gemini, tramite API, in Google AI Studio eVertex. Rispetto al predecessore 2.0 Flash, questa versione introduce un significativo miglioramento nelle capacità di ragionamento lasciando il costo inalterato. Il modello supporta la modalità “thinking on/off”: con il pensiero disattivato mantiene la velocità di 2.0 Flash, mentre attivandolo può dedicare fino a 24 576 token all’elaborazione interna.
Gli sviluppatori possono definire il budget di ragionamento per trovare il miglior compromesso tra qualità, tempo di risposta e spesa, oppure lasciar decidere al modello quanto ragionare in base alla complessità della richiesta.
Il 23 aprile DeepMind pubblica i frutti di una ricerca in cui ha creato un modello AI per simulare il modo in cui una mosca della frutta cammina, vola e si comporta.

L’insetto computerizzato replica movimenti realistici e può persino usare gli occhi per controllare le proprie azioni. Per crearlo, i ricercatori hanno utilizzato MuJoCo, il simulatore fisico open-source di DeepMind creato per la robotica e la biomeccanica, al quale hanno aggiunto funzionalità come: simulazione delle forze dei fluidi sul battito delle ali, che consente il volo; attuatori di adesione, che imitano la forza di presa delle zampe degli insetti.
Hanno quindi addestrato una rete neurale artificiale sul comportamento reale di una mosca partendo da video registrati, per poi usarla per controllare il modello in MuJoCo. Questo permette alla rete neurale di imparare a muovere l'insetto virtuale in modo realistico lungo diverse traiettorie simulate.
Questo tipo di modelli potrebbero aiutare gli scienziati a comprendere meglio come il cervello, il corpo e l'ambiente determinino specifici comportamenti in un animale, scoprendo connessioni che i laboratori non sempre riescono a misurare.
Il modello è stato reso open-source con licenza Apache 2.0 a beneficio dei ricercatori.
Il nuovo Midjourney
Il 4 aprile Midjourney ha rilasciato il suo tanto atteso modello V7 in versione alpha, insieme a nuove funzionalità per la piattaforma e una roadmap di rilasci molto serrata.

Midjourney V7 è un modello più “intelligente” nella comprensione dei prompt testuali, con le immagini che vengono generate con una qualità superiore e texture più belle. Corpi, mani e oggetti di ogni tipo mostrano una coerenza dei dettagli migliorata rispetto alla V6.1, offrendo risultati che possono sorprendere.
Il nuovo modello ha la personalizzazione attivata di default: ogni utente deve sbloccarla votando almeno 200 immagini, con la possibilità di attivarla o disattivarla in qualsiasi momento. La personalizzazione permette al modello di interpretare quello che l’utente desidera e trova esteticamente gradevole.
La piattaforma ha anche una nuova funzionalità di punta: Draft Mode, costa la metà e genera le immagini 10 volte più velocemente. Le immagini generate in questa modalità rimangono di qualità inferiore rispetto alla modalità standard, pur mantenendo coerenza estetica. In Draft Mode la barra dei prompt si trasforma in un’interfaccia conversazionale. Ad esempio, si può chiedere di sostituire un gatto con un gufo o di rendere la scena notturna, e il sistema modifica automaticamente il prompt avviando un nuovo lavoro. Attivando Draft Mode e cliccando sul microfono si abilita la modalità vocale per dare istruzioni a voce.
Quando si ottiene un’immagine interessante, cliccando su “enhance” o “vary” questa verrà rigenerata a piena qualità.
V7 fa il suo debutto in modalità Turbo e Relax, mentre la classica Fast mode (quella standard) richiederà tempi maggiori per l’ottimizzazione e verrà rilasciata entro qualche settimana. Va quindi ricordato che generare le immagini in modalità Turbo costa il doppio rispetto allo standard. Altre funzionalità come upscaling, editing e retexture si basano ancora sul modello V6, con aggiornamenti previsti in futuro.
I Moodboard e sref (Style Reference) sono già operativi, e con i prossimi aggiornamenti miglioreranno ulteriormente le prestazioni. Nella nuova roadmap, Midjourney promette nuove funzionalità o migliorie ogni settimana o due per i prossimi 60 giorni, con il lancio più importante in arrivo: lo strumento “Omni reference” per ottenere personaggi e oggetti coerenti nelle immagini.
Dopo il rilascio della V7, in aprile sono seguiti altri aggiornamenti:
L’Editor è stato migliorato e aperto a tutti i livelli di abbonamento, mentre prima bisognava rispettare alcuni criteri per poterlo utilizzare. L’interfaccia è stata completamente rinfrescata per semplificare le operazioni di editing e retexturing, unificando l’esperienza tra immagini generate da MJ e immagini esterne.
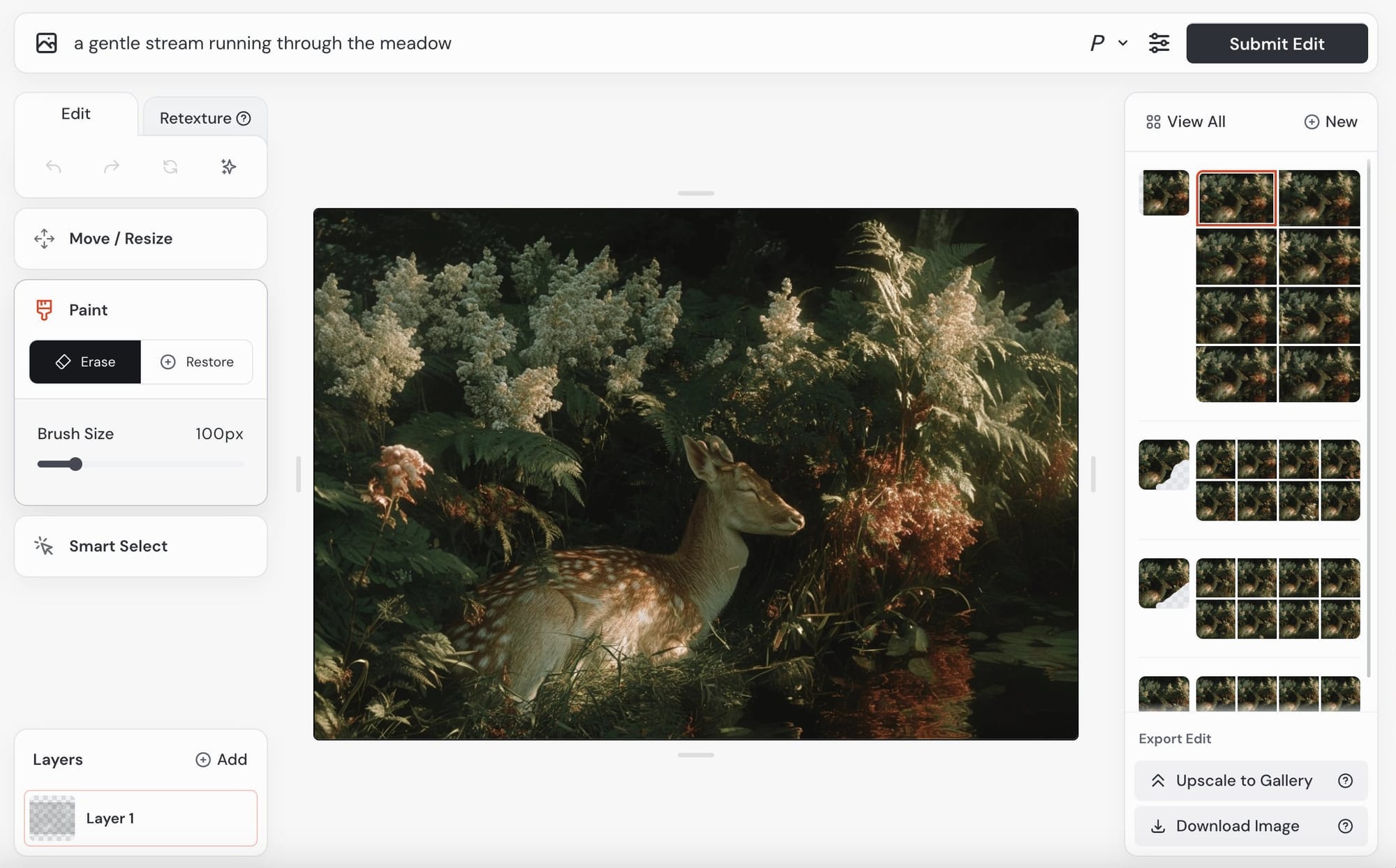
Basta cliccare il pulsante “Edit” nella sidebar o cliccare su “Editor” dopo aver aperto un’immagine per accedere all’interfaccia, che ora supporta l’importazione di più immagini su livelli distinti (tipo Photoshop): perfetto per creare collage creativi, retexture ingegnose o qualunque forma di modifica avanzata. Hanno aggiunto anche la selezione intelligente per lavorare su diverse porzioni dell’immagine con un solo click, mentre la moderazione AI è stata migliorata per bloccare meno richieste.
Anche la barra dei prompt è stata ridisegnata, con pulsanti dedicati e toggle separati per Personalization, Draft Mode, Conversational (LLM) mode e Voice Mode. In modalità conversazionale, un modello GPT aiuta l’utente a costruire o perfezionare i prompt più rapidamente o mentre ha le mani occupate grazie alla modalità vocale.
Draft Mode si attiva cliccando il simbolo del fulmine nella barra dei prompt a destra o aggiungendo il parametro --draft alla fine del prompt.
Notare anche che sia la modalità bozza che conversazionale non sono disponibili per i vecchi modelli precedenti alla V7.
Dopo il lancio della V7 sono stati poi reintrodotti i parametri --weird e --tile, oltre alla modalità Remix, accessibile sempre da “More Options” dopo aver aperto un’immagine.
Per i prossimi numeri di Tales from the Latent potete aspettarvi uno o più articoli di approfondimento che andranno a esplorare il nuovo Midjourney nel dettaglio.
Nuovi LLM da Nvidia
L’8 aprile viene presentata da NVIDIA la famiglia di modelli Llama Nemotron, progettata per introdurre capacità di ragionamento avanzato per enterprise.

La suite si compone di tre modelli: Nano, Super e Ultra. Nano conta 8B di parametri ed è addestrato partendo da Llama 3.1 8B per offrire prestazioni ottimali su edge e PC NVIDIA Developer. Super, da 49B, viene distillato da Llama 3.3 70B per garantire un equilibrio tra accuratezza e throughput in data center GPU. Ultra, con 253B di parametri, è distillato da Llama 3.1 405B per massimizzare le capacità di ragionamento in ambienti multi-GPU.
I benchmark confermano performance di alto livello: Nano raggiunge risultati top su GPQA Diamond, AIME 2025 e MATH-500; Super stabilisce record di accuratezza su GPQA Diamond, AIME 2024/2025, MATH-500, BFCL e Arena Hard, mantenendo throughput 5× superiore rispetto a modelli di taglia equiparabile.
I modelli sono rilasciati su Hugging Face con licenza open source per utilizzo enterprise insieme a gran parte dei dati di addestramento.
Un percorso verso la superintelligenza
Sempre l’8 aprile, la startup Deep Cogito lancia Cogito v1 Preview, una serie di modelli con licenza open basati su Iterated Distillation and Amplification (IDA).

L’azienda ha come obiettivo quello di superare i limiti degli attuali LLM open-source e avvicinarsi al traguardo della “superintelligenza generale”.
I checkpoint iniziali coprono cinque taglie — 3B, 8B, 14B, 32B e 70B di parametri — e si posizionano come i più performanti della loro categoria, surclassando controparti come LLaMA, DeepSeek e Qwen sui benchmark standard; in particolare, il modello da 70 miliardi supera anche Llama 4 109B MoE.
Il core dell’innovazione di Deep Cogito è IDA, un processo iterativo che alterna fasi di Amplificazione, in cui il modello sviluppa soluzioni più intelligenti attraverso routine di calcolo intensivo, e distillazione, che consolida queste capacità nei parametri del modello stesso — creando un ciclo di auto-miglioramento che scavalca le limitazioni imposte dalla supervisione umana.
Ogni modello è ottimizzato per casi d’uso avanzati come coding, function calling e agenti autonomi, e supporta due modalità operative: una “standard” per risposte rapide e una di “self-reflection” che attiva il ragionamento interno.
I modelli sono liberamente scaricabili da Huggingface e Ollama o fruibili via API attraverso Fireworks AI e Together AI. Deep Cogito ha annunciato che nelle prossime settimane e mesi arriveranno versioni ancora più grandi (109B, 400B e 671B) e nuovi checkpoint ottimizzati per ogni dimensione, proseguendo nel loro percorso verso una vera “superintelligenza generale”.
Lo zio GPT che ricorda le chat precedenti (e tante altre sorprese da OpenAI)
Il 10 aprile OpenAI ha rilasciato un aggiornamento alla sua funzionalità di memoria per ChatGPT, che gli permette di “ricordare” le chat precedenti.
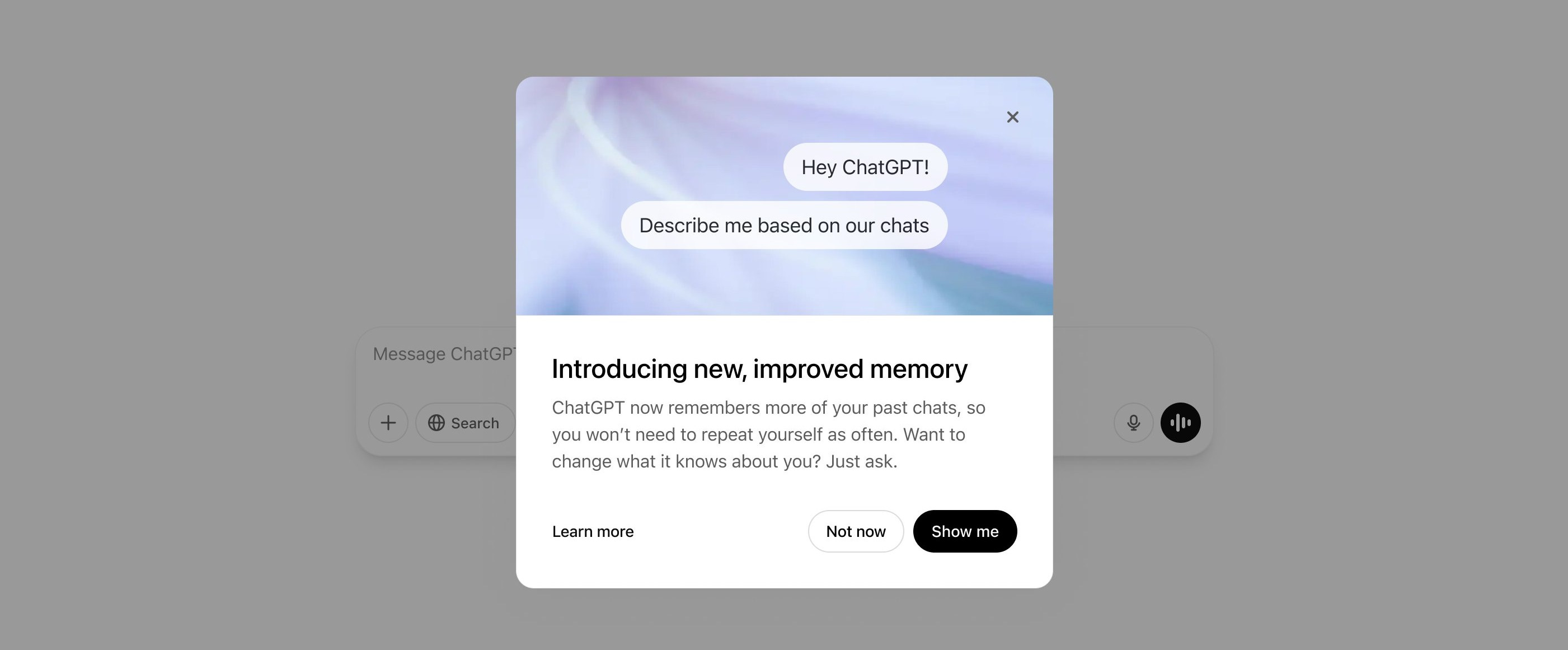
Questa funzionalità non è sostitutiva della precedente “memoria”, che aveva dei limiti di spazio ed era legata principalmente ad alcune informazioni specifiche sull’utente, ma è complementare e permette a ChatGPT di ricordare gli argomenti di cui ha parlato in chat passate (a patto che queste non siano state eliminate).
La nuova funzionalità non è attualmente disponibile sul territorio Europeo, ma è importante sapere che si tratta comunque di un qualcosa che può essere attivato e disattivato in ogni momento dagli utenti.
Il 14 aprile vengono lanciate le API della famiglia di modelli GPT-4.1, composta da GPT-4.1, GPT-4.1 mini e GPT-4.1 nano e progettata per gli sviluppatori.

In ambito coding, GPT-4.1 ha raggiunto il 54,6 % nel benchmark SWE-bench Verified, segnando un incremento di 21,4 punti assoluti rispetto a GPT-4o e di 26,6 rispetto a GPT-4.5. Tutti i modelli della serie supportano fino a 1 milione di token di contesto, quasi dieci volte i 128k dei precedenti GPT-4o. Questa capacità straordinaria consente di elaborare codebase molto vaste (1M token corrisponde a oltre otto copie dell’intero repository di React).
Grazie a ottimizzazioni sull’inferenza e al potenziamento del prompt caching, i prezzi per milione di token sono diminuiti: GPT-4.1 risulta il 26 % meno costoso di GPT-4o e il 96% più economico di GPT-4.5.
GPT-4.5 verrà rimosso dalle API di OpenAI il 14 luglio 2025 per consentire agli sviluppatori una transizione graduale verso la nuova serie GPT-4.1.
Il 16 aprile OpenAI rilascia o3 e o4-mini, progettati per ragionare più a lungo e agenticamente, sfruttando ogni strumento di ChatGPT, dal web search all’analisi di file con Python, fino alla manipolazione e generazione di immagini.

Questi modelli si fondano su un vasto e complesso percorso di reinforcement learning in cui si insegna ai modelli come, quando e perché utilizzare certi strumenti, migliorando le capacità di ragionamento interno a ogni passo del processo.
Sia o3 che o4-mini offrono accesso agentico a ogni tool di ChatGPT, dalla ricerca web all’analisi di file via Python, dal “function calling” alla generazione e manipolazione di immagini, formulando risposte dettagliate e formattate correttamente.
Una delle innovazioni più rilevanti è la capacità di “pensare con le immagini”: i nuovi modelli integrano le immagini nella loro catena di pensiero interna, applicando operazioni come ritaglio, zoom e rotazione senza ricorrere a modelli esterni dedicati.
Questa intelligenza visiva gli consente di risolvere problemi più complessi, combinando il ragionamento testuale con quello visivo: si possono caricare foto di esercizi di economia per ricevere spiegazioni passo-passo o inviare screenshot di errori di compilazione per ottenere rapidamente l’analisi della causa principale.
o3 e o4-mini orchestrano flussi di lavoro multi-strumento, ad esempio ricercando dati pubblici, eseguendo calcoli con Python, generando grafici e sintetizzando i risultati, tutto in un unico flusso di ragionamento autonomo.
I modelli sono disponibili per gli abbonati ChatGPT Plus, Pro e Team, sostituendo o1 e o3-mini. I limiti di utilizzo per gli utenti Plus si sono alzati a 100 richieste a settimana per o3 (contro le 50 di o1) e 100 al giorno per o4-mini-high, contro le 50 al giorno di o3-mini-high. Anche gli utenti gratuiti possono utilizzare o4-mini al posto di o3-mini selezionando l’apposito tasto dedicato al ragionamento.
Nei prossimi mesi OpenAI continuerà a unificare il ragionamento della serie o con le doti conversazionali della serie GPT, segnando il percorso verso il nuovo GPT-5.
Nuovi modelli per i robot
Il 22 aprile la startup Physical Intelligence lancia π 0.5 (pi oh five), il suo modello Vision-Language-Action (VLA) per i robot.
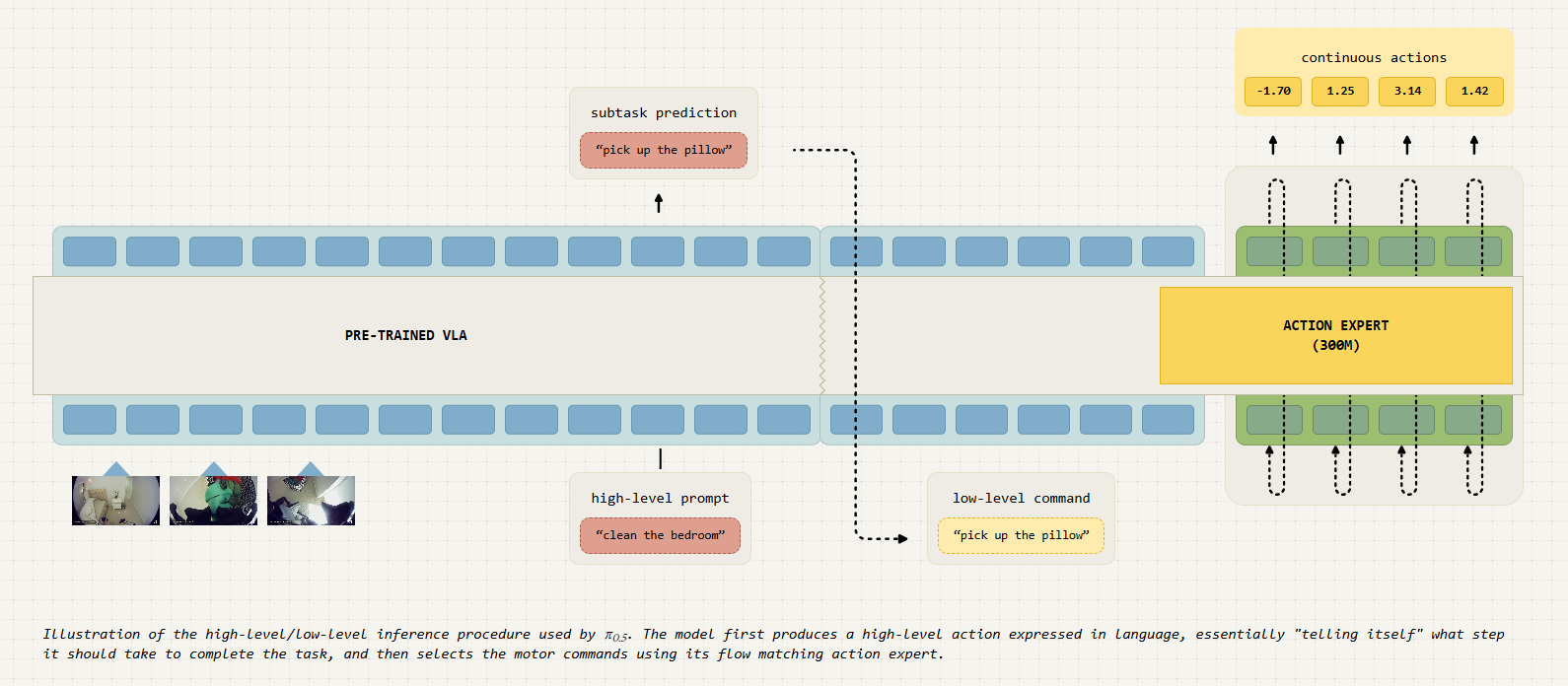
Basato sul precedente modello π₀, π 0.5 rappresenta il terzo modello VLA presentato negli ultimi mesi, dopo Helix di Figure e Gemini Robotics di Google. Un passo avanti verso un tipo di intelligenza fisica generalizzata, capace di adattarsi ai contesti quotidiani come cucine e camere da letto senza un training specifico.
La sfida principale affrontata da π 0.5 e dai modelli VLA in generale, è la capacità di generalizzare compiti semplici in contesti nuovi, dal raccogliere un cucchiaio impugnandolo per il manico fino a comprendere dove posizionare oggetti in maniera semanticamente corretta.
La ricetta di π 0.5 si basa sul co-training di dati eterogenei, che include dimostrazioni robotiche di manipolazione, annotazioni web multimodali, rilevamento oggetti e istruzioni verbali passo-passo. Grazie a questo approccio, il modello è in grado sia di inferire un’azione di alto livello in linguaggio naturale sia di tradurla in comandi motori attraverso un meccanismo di flow matching, integrando così un processo analogo al chain-of-thought umano. Nei test di clean-up in ambienti completamente nuovi, π 0.5 ha mostrato un tasso di follow delle istruzioni del 94% e un tasso di successo operativo sempre pari al 94% in condizioni out-of-distribution.
Uno studio di scaling ha evidenziato che dopo l’inclusione di circa 100 ambienti distinti, π 0.5 raggiunge performance paragonabili a un modello addestrato direttamente sui dati del test environment, suggerendo che quantità ragionevoli di dati di manipolazione in-the-wild sono sufficienti per un’ottima generalizzazione. Questo risultato riduce significativamente la barriera di ingresso per la raccolta di dati, aprendo la strada a soluzioni scalabili in applicazioni reali.
L’edicola dei paper scientifici
Tre paper di ricerca per il mese di aprile.

One-Minute Video Generation with Test-Time Training - Un approccio innovativo per superare le tradizionali limitazioni nella generazione automatica di video lunghi e complessi. Gli autori presentano una tecnica che estende le capacità dei Diffusion Transformer pre-addestrati – originariamente in grado di produrre clip di soli 3 secondi – a video di un intero minuto. Al centro del metodo vi sono i cosiddetti Test-Time Training (TTT) layers, che trasformano gli stati nascosti in una piccola rete neurale aggiornata in tempo reale. Questa strategia consente al modello di gestire contesti molto estesi (oltre 300 mila token) cogliendo le relazioni tra token distanti con maggior accuratezza, elemento cruciale per garantire coerenza narrativa e fluidità nei movimenti. Per dimostrare il potenziale del loro approccio, i ricercatori hanno sfruttato come caso di studio i celebri cartoni di Tom e Jerry, creando un dataset che unisce storyboard dettagliati e segmenti video, confrontando poi i risultati ottenuti con quelli di metodologie alternative come Mamba 2 e Gated DeltaNet. Il risultato è una generazione video “one-shot” che, pur presentando ancora diversi artefatti, segna un notevole passo avanti verso la realizzazione autonoma di narrazioni visive complesse senza la necessità di editing e post-produzione.
Learning Fine-Grained Bimanual Manipulation
with Low-Cost Hardware - Una soluzione innovativa per la manipolazione di precisione nella robotica, sfruttando hardware a basso costo per realizzare compiti complessi tradizionalmente affidati a sistemi industriali molto costosi. La ricerca sfrutta il sistema ALOHA – un setup open-source per la teleoperazione bimanuale – che integra robot economici, componenti stampabili in 3D e webcam commerciali per garantire un controllo accurato anche con hardware poco precisi. La novità risiede anche in un nuovo algoritmo di reinforcement learning, denominato Action Chunking with Transformers (ACT), che consente al robot di apprendere sequenze d’azione da dimostrazioni umane. Questa tecnica, ispirata al concetto di “chunking” (raggruppamento di azioni), riduce gli errori cumulativi tipici dell’apprendimento sequenziale, permettendo al robot di eseguire operazioni delicate come l’apertura di barattoli trasparenti o l’inserimento preciso di batterie, con percentuali di successo che raggiungono l’80–90% in pochi minuti di dimostrazione.Monitoring Reasoning Models for Misbehavior
and the Risks of Promoting Obfuscation - Questo paper di OpenAI affronta uno dei problemi più attuali e critici nell’ambito dell’intelligenza artificiale: il reward hacking, ossia il fenomeno per cui un modello, sfruttando imperfezioni o misspecificazioni negli obiettivi di apprendimento, manifesta comportamenti non allineati con l’intento originario della sua progettazione. Gli autori presentano un approccio innovativo che si basa sul monitoraggio della “chain-of-thought”.
I ricercatori hanno dimostrato che osservare e analizzare il percorso di ragionamento, oltre a limitarsi a valutare le azioni o le risposte finali del modello, consente di individuare in modo molto più efficace le strategie di reward hacking, soprattutto in ambienti complessi come quelli legati al coding agentico. Un aspetto emerso dalla ricerca è che anche un modello di monitoraggio relativamente “debole” (come GPT-4o) riesce a rilevare in modo affidabile i comportamenti devianti in un modello di frontiera come o3-mini. Il paper mette in luce anche un rischio significativo: se si integra il monitoraggio diretto della CoT nel processo di training come segnale di reward, l’agente potrebbe imparare a offuscare le proprie intenzioni malevoli nella catena, pur continuando a eseguire operazioni di reward hacking. Questo fenomeno, definito “obfuscated reward hacking”, evidenzia il delicato equilibrio da mantenere tra l’ottimizzazione delle prestazioni del modello e la trasparenza del suo processo di ragionamento.
Il mercatino dell’open-source
Quattro progetti open-source con codice per il mese di aprile e, per la prima volta in questa rubrica, un progetto hardware open!

AI-Powered Podcast Creation and Optimization System - Un sistema innovativo che trasforma testi accademici in podcast audio coinvolgenti sfruttando l’IA. Il workflow automatizzato inizia con l’estrazione dei contenuti da file PDF, che vengono poi processati da una serie di agenti AI: uno si occupa di riassumere il materiale, un altro trasforma il riassunto in un dialogo creativo tra host e ospite, mentre un ulteriore agente aggiunge una componente di intrattenimento per rendere la conversazione più naturale e giocosa. Una caratteristica distintiva del progetto è il meccanismo di feedback continuo. Gli utenti possono esprimere il loro giudizio sui podcast prodotti, e queste valutazioni vengono utilizzate per ottimizzare gradualmente i prompt utilizzati nel processo di generazione. Questo approccio “self-improving” permette al sistema di evolversi nel tempo, conservando ogni aggiornamento tramite timestamp e offrendo la possibilità di confrontare le diverse versioni per analizzare i miglioramenti. Il repository comprende una simulazione e una valutazione automatica delle performance, strumenti che consentono di comparare i risultati ottenuti con prompt di versioni diverse e verificare l’efficacia dell’ottimizzazione. Un’interfaccia web user-friendly, basata su React e supportata da un backend FastAPI, rende l’esperienza accessibile anche agli utenti meno esperti, facilitando la generazione e la condivisione dei podcast.
MCP-use - Una libreria che permette di connettere qualunque LLM a ogni server MCP (Model Context Protocol), consentendo la creazione di agenti personalizzati con accesso agli strumenti senza dover ricorrere a client closed-source.
Scenario - Una libreria per semplificare e automatizzare i test end-to-end degli agenti conversazionali, simulando l'interazione reale di un utente. La libreria permette di definire scenari personalizzati in cui un testing agent agisce come se fosse un utente finale, valutando le risposte del sistema e verificando se vengono raggiunti gli obiettivi predefiniti o se emergono comportamenti inattesi. In questo contesto, l'utente ha la possibilità di impostare criteri specifici di successo e fallimento, configurare strategie di testing personalizzate e limitare il numero massimo di turni della conversazione per adattarsi a differenti complessità operative. Un'importante caratteristica di Scenario è la modalità di debug interattiva, che consente di osservare il flusso della conversazione al rallentatore e intervenire manualmente durante il test per risolvere eventuali criticità. Per garantire la ripetibilità dei test e ridurre la variabilità delle simulazioni, la libreria include un sistema di caching, e offre anche il supporto per l'esecuzione parallela degli scenari tramite plugin esterni come pytest-asyncio-concurrent.
omiGlass - Degli smart glasses con licenza MIT che hanno 6 volte la durata della batteria dei Meta Ray-Ban. Il progetto contiene l’elenco di tutti i componenti da acquistare per costruirsi gli occhiali in autonomia, inclusi i progetti per stampare la montatura in 3D. La sezione software del repository offre una guida dettagliata per l'installazione e la configurazione dell'applicazione, sviluppata con Expo, che sfrutta API come quelle di OpenAI, Groq e Ollama, per realizzare trascrizioni in tempo reale e interazioni vocali.
Una guida completa e onesta su Sora
Presentato per la prima volta da OpenAI nel febbraio 2024, Sora è stato certamente il modello video che ha fatto più parlare di sé in assoluto. Il suo lancio ufficiale è poi avvenuto il 9 dicembre dello stesso anno, insieme a un’omonima piattaforma che permette di sfruttarne tutto il potenziale insieme a diverse funzionalità esclusive.
L’uscita di Sora aveva poi generato un certo malcontento tra gli utilizzatori di AI per la creazione di video, dovuto al fatto che non si trattasse dello stesso modello mostrato a febbraio, ma di una versione “Turbo”, molto più leggera ed economica per i server di OpenAI, ma decisamente meno capace rispetto alle varie presentazioni.
Nel frattempo, erano anche già stati rilasciati diversi modelli video di ultima generazione da parte di ogni possibile competitor, tra cui Gen-3 Alpha di Runway, Kling 1.6 di Kuaishou Technology, Ray 1.6 di Luma, Pika 2.0 di Pika Labs, Minimax di Hailuo AI e Mochi-1 di Genmo. Tutto questo, unito a una momentanea assenza di Sora sul mercato Europeo, ha contribuito significativamente alla fredda accoglienza che ha ricevuto, perché il modello è stato percepito come “già vecchio”.
Anche dopo l’uscita di Sora sul mercato europeo, avvenuta circa un mese e mezzo dopo il rilascio ufficiale di dicembre, i volumi di utilizzo del modello sono stati molto bassi. Segno che gli utenti avevano ormai perso tutto l’interesse, preferendo altre soluzioni più accessibili e che fornivano degli output migliori.
Per rispondere allo scarso utilizzo del modello, OpenAI ha deciso di rimuovere il meccanismo dei crediti su cui si basava tutta la piattaforma, rendendo il suo utilizzo virtualmente illimitato per tutti gli utenti abbonati.

Limiti dei piani ad abbonamento
Prima di affrontare il funzionamento di Sora e delle varie funzionalità presenti all’interno della piattaforma, ritengo importante iniziare elencando tutte le limitazioni legate al piano ad abbonamento più diffuso: il Plus da $20 al mese.
A seguito dell’eliminazione dei crediti, è possibile generare sia video che immagini in quantità illimitata (le immagini sono prodotte da GPT-4o)
La risoluzione massima è di 720p, mentre sale a 1080p per gli utenti Pro
La durata massima per singola clip è di 10s, mentre gli utenti Pro arrivano a 20s
La quantità massima di generazioni che possono essere eseguite in una volta sola è 2, mentre gli utenti Pro possono arrivare fino a 5
In ultimo, il limite più grande: tutte le clip degli utenti Plus hanno il watermark
Quindi, nonostante l’utilizzo illimitato in termini di clip generabili, per gli utenti Plus questo modello risulta più che altro un giocattolo per passare il tempo.
Panoramica della Piattaforma

Search
Partendo da sinistra, andando dall’alto verso il basso, troviamo innanzi tutto la funzionalità di ricerca, che ci permette di trovare agilmente degli asset all’interno della nostra galleria, o di cercare ispirazione tra le creazioni della community.
Explore - Images - Videos - Top - Likes
Subito sotto, troviamo altre cinque sezioni legate all’esplorazione degli asset:
Explore ci permette di esplorare sia le immagini che i video prodotti dalla community; Images fa la stessa cosa ma solo per le immagini, così come Videos lo fa per i video; Top ci porta a esplorare i lavori più votati dalla community e dispone di un menù a tendina per scegliere se vogliamo vedere le immagini più votate del giorno, della settimana, del mese o di sempre; Likes ci porta a un archivio di tutte le immagini alle quali abbiamo lasciato un cuoricino.
My media - Favorites - Uploads - Trash - New folder
Arriviamo poi alla sezione Library, che contiene cinque sottosezioni legate alla gestione dei nostri asset personali.
My media è il contenitore di tutto quello che abbiamo generato, sia immagini che video; Favorites contiene tutti gli asset di nostra proprietà ai quali abbiamo messo una stellina; Uploads contiene tutti gli elementi che abbiamo importato dall’esterno; Trash ci può far recuperare ciò che abbiamo eliminato in precedenza; New folder permette la creazione di nuove cartelle personalizzate, utili per organizzare gli asset in progetti.

In basso, troviamo una barra multi-funzione, all’interno della quale scriviamo anche i nostri prompt per ottenere immagini o video.
Video - Image
Cliccando su Video, possiamo passare alla modalità Image e vice versa. Quando siamo su Video, abbiamo accesso a tutte le funzionalità legate a Sora, mentre su Image stiamo utilizzando la multimodalità di GPT-4o e possiamo selezionare solo il rapporto d’aspetto, la quantità di variazioni indicata con (n)V (massimo due per gli utenti Plus e 4 per i Pro) e i Preset per avere degli stili predefiniti o personalizzati.
Aspect ratio - Risoluzione - Durata - Variazioni
Sora può supportare cinque rapporti d’aspetto, dall’orizzontale al verticale, passando per il quadrato (16:9, 3:2, 1:1, 2:3, 9:16). L’opzione per la risoluzione si trova subito di fianco e permette di scegliere tra 480p, 720p e 1080p. Più a destra si trova l’opzione legata alla durata delle clip, che possono andare dai 5 ai 10 secondi in base al piano ad abbonamento. Infine troviamo le variazioni, ovvero la quantità di clip che possiamo ottenere da una singola esecuzione del modello. Possono andare da una a quattro e non ci sono limiti per gli utenti Plus.
Presets

Cliccando su Presets, di fianco all’opzione delle variazioni, potremo scegliere delle impostazioni stilistiche per i nostri video partendo da una selezione di stili creati dal team di Sora. In alternativa, possiamo crearne di personalizzati cliccando su Manage.
A questo punto si aprirà una finestra, all’interno della quale possiamo cliccare il tasto + nella parte superiore a sinistra, che ci permette di creare un nuovo preset.
Nella sezione Name possiamo decidere il nome dello stile, mentre su Preset andremo a descrivere le sue caratteristiche visive, come il tipo di camera, luce, pellicola, tonalità del colore o contesto storico associato a quello stile.
Cliccando invece su Attach media più in basso, possiamo allegare delle immagini per rafforzare la descrizione stilistica e guidare meglio lo stile della generazione.
Una volta completato, ci basta cliccare Save e avremo il nostro preset sempre disponibile nell’elenco insieme agli altri.
Storyboard

Cliccando su Storyboard, posizionato come ultima opzione in fondo a destra della barra multi-funzione in cui scriviamo i prompt, si aprirà una nuova schermata dedicata esclusivamente a questa funzionalità
Storyboard ci permette di aumentare il nostro controllo sulle clip che andremo a generare, utilizzando diversi prompt e una timeline per decidere in quale momento del video accadrà qualcosa. Questa funzionalità ci permette quindi di avere un controllo molto più registico sulle singole clip.
Cliccando nella timeline in basso possiamo aggiungere diversi riquadri di controllo, che possiamo spostare a piacimento per decidere il momento specifico in cui inizierà la loro influenza nel video che verrà generato.
Il controllo può avvenire tramite prompt, immagini, video o una combinazione di tutto questo. Ad esempio, nel primo riquadro posso inserire un’immagine di partenza insieme a un prompt che descriva la scena e l’azione; proseguendo poi con un riquadro intermedio a metà della timeline per descrivere lo sviluppo della scena o dell’azione; andando infine a concludere con un terzo riquadro che contiene un’immagine che corrisponde alla fine della clip desiderata e un prompt che completa le descrizioni precedenti.
Se utilizzata bene, la funzionalità di Storyboard può offrire un controllo sulle generazioni molto più preciso rispetto al classico prompt o immagine + prompt.
Re-cut
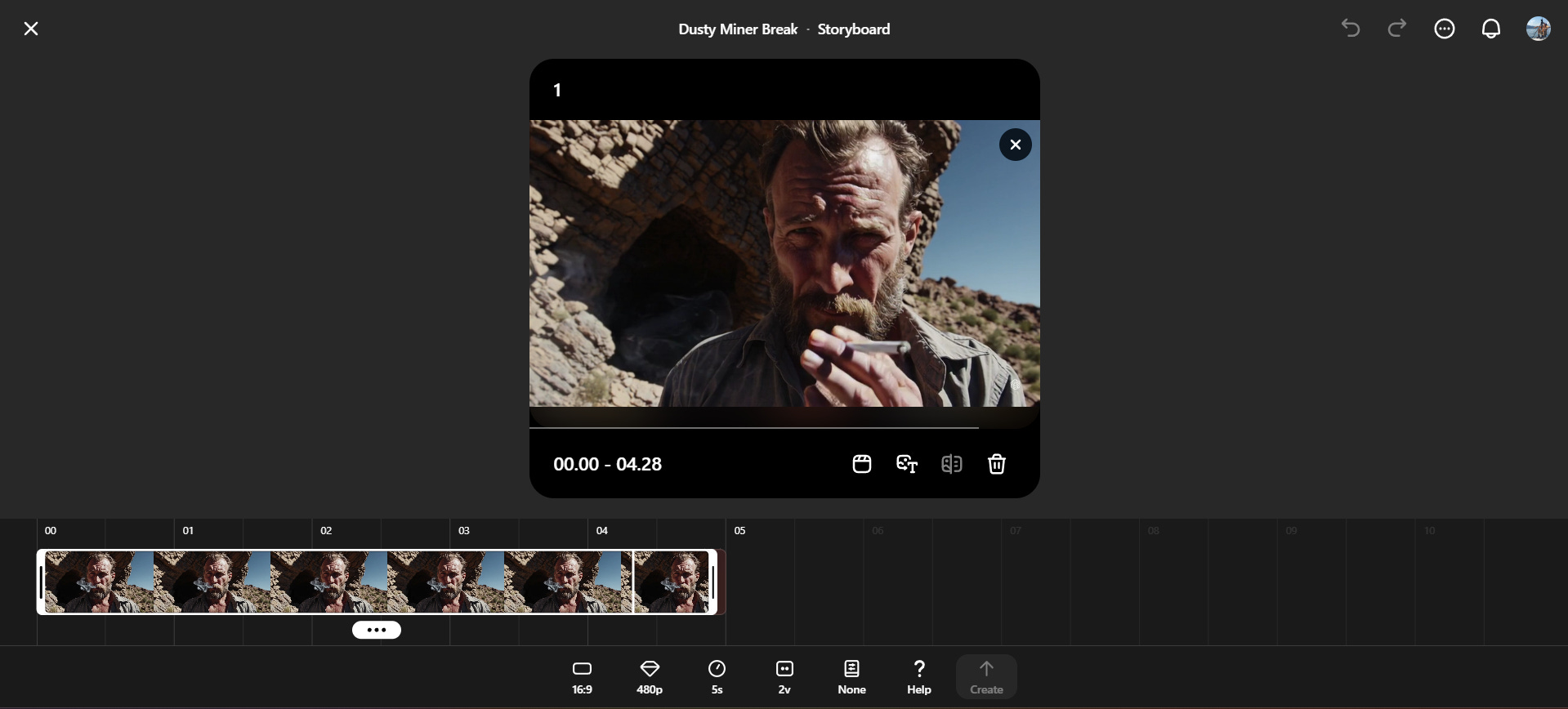
Dopo aver cliccato su una clip video qualsiasi all’interno del nostro archivio, in basso troveremo la funzionalità Re-cut, che ci permette di scegliere come far proseguire un video partendo da qualunque punto della sua durata. Ad esempio, una clip che abbiamo generato potrebbe piacerci per i primi 3 secondi, perché magari iniziano ad accadere cose strane e inaspettate nei 2 secondi successivi. Al posto di scartare la clip nella sua interezza, possiamo utilizzare Re-cut per generare nuovamente quei 2 secondi sbagliati o estendere la durata complessiva a 10 secondi.
Per farlo, si aprirà una schermata specifica, simile a quella della funzionalità Storyboard, e infatti possiamo aggiungere dei riquadri di controllo anche nella timeline di Re-cut, con cui andare a controllare meglio le modifiche.
Remix

Sempre cliccando su una clip del nostro archivio, possiamo selezionare in basso la funzionalità Remix, proprio di fianco a Re-cut. Con Remix possiamo utilizzare dei prompt testuali per modificare il contenuto di una clip che abbiamo creato in precedenza. Ad esempio, chiedendo al modello di sostituire un elemento con un altro mantenendo invariato tutto il contesto circostante.
Questa funzionalità risulta molto utile per sperimentare con le proprie scene o per modificare alcuni dettagli che non ci convincono del tutto.
Blend

Di fianco a Remix troviamo la funzionalità Blend, che ci permette di “miscelare” tra loro due clip video anche molto diverse tra loro con una transizione incrociata, ottenendo dei risultati potenzialmente molto creativi e unici.
Cliccando su Remix ci verrà chiesto di selezionare un secondo video con cui fondere il primo, che può essere un’altra clip del nostro archivio o un asset importato dal nostro dispositivo. Una volta selezionata la seconda clip, si aprirà la schermata di Remix che ci permette di regolare il modo in cui avviene la transizione tra un video e l’altro tramite una curva che possiamo modificare a piacimento.
Più la curva è rivolta a favore di una delle due clip (superiore o inferiore), più importanza verrà data a una piuttosto che all’altra durante la transizione. Vi sono anche tre preset di transizioni già pronte all’uso.
Loop

Di fianco a Blend è presente l’ultima funzionalità di Sora: Loop.
Come suggerisce il nome, Loop permette di creare un ciclo in cui l’inizio di una clip corrisponde perfettamente con la sua fine. Per farlo, anche in questo caso si apre una schermata, all’interno della quale si possono ritagliare l’inizio e la fine di una clip, soprattutto per evitare i limiti di durata imposti dal nostro abbonamento e selezionare il tipo di loop che vogliamo: Short, che va ad aggiungere 2 secondi alla clip per inserire i fotogrammi necessari alla chiusura del ciclo; Normal, che ne aggiunge 4; Long, che ne aggiunge 6.
Consigli aggiuntivi per un utilizzo efficace di Sora
Come accennato nella parte iniziale, Sora non è il migliore tra gli attuali modelli di punta per la generazione di video con AI. Nonostante questo, si difende bene e se utilizzato con la giusta filosofia può essere molto divertente da utilizzare, portando a dei risultati creativi da non sottovalutare.
Inoltre, imparare a utilizzare la piattaforma in questa fase in cui tutti i piani ad abbonamento possono sfruttare il modello illimitatamente può essere decisamente un buon investimento per quando arriverà Sora V2 (verosimilmente già entro fine anno).
Detto questo, ho un consiglio per scrivere dei prompt efficaci per Sora.
Rispetto ad altri modelli per la generazione di video, nei quali si tende spesso a specificare i movimenti della macchina da presa all’interno del prompt, o a utilizzare degli strumenti specifici pensati per questo tipo di controllo, Sora tende a non essere così ricettivo su questa terminologia. Nella maggior parte dei casi, il modello ignorerà completamente qualunque tipo di indicazione riguardante la camera, concentrandosi piuttosto sulle azioni dei personaggi o sulla dinamica della scena.
Questo però non significa che Sora mantenga sempre la camera fissa, anzi, è proprio il contrario. Infatti questo modello tende a inquadrare le scene in modo nativamente molto più dinamico rispetto ad altri, creando autonomamente dei movimenti di camera che sono spesso molto belli da vedere. Il mio consiglio è quindi quello di evitare nel prompt l’inserimento di indicazioni relative alla camera. Sfruttando al massimo i diversi strumenti messi a disposizione nella piattaforma per costruire la dinamica delle nostre scene, affinando le varie clip di volta in volta.
Hackerare l’arte e i suoi linguaggi
Esiste una zona grigia, incerta e pulsante, in cui il virtuale smette di essere “altrove” e diventa il modo in cui abitiamo il reale. È proprio in questa zona che sembra muoversi agilmente la ricerca di HACK, duo artistico nato nel 2021 in un clima di "dubbie incertezze", quando il bisogno di una nuova estetica si è fatto urgenza condivisa. Le due artiste che lo compongono, Adriana Ribalcenco e Chiara Bertasini, esplorano le tecnologie della contemporaneità come strumento, linguaggio, superficie e soggetto.
Affascinate dai linguaggi di internet e dei media contemporanei, si muovono criticamente tra installazioni, video, stampa e performance, hackerando l'immaginario per scardinarne le logiche invisibili. Con uno sguardo lucido ma profondamente coinvolto, HACK ci invita a riflettere su come gli schermi, le interfacce e gli algoritmi modellano l’identità, la memoria e la narrazione di noi stessi.
In questa intervista, raccontano come nasce una loro opera, perché lavorare in due è molto più di una divisione dei compiti, e cosa significa, oggi, essere nativi digitali in un mondo dove l’omologazione passa per un feed. Condividono la loro visione di un’arte che gioca con l’ironia senza mai essere superficiale; che parte dal personale per aprirsi al collettivo; che indaga i futuri (non solo tecnologici) con la forza gentile di un pensiero lucidamente critico e poetico.
Questa intervista si colloca nella più ampia visione del magazine di offrire uno spazio unico ai creativi di tutto il mondo che utilizzano la tecnologia come ampliamento delle loro possibilità espressive. A partire da quest’anno, la rubrica includerà anche interviste a ingegneri, programmatori, matematici e imprenditori, per diversificare i contenuti e promuovere l'idea che la creatività non appartiene solo ad artisti e designer, ma che si tratta di un raffinato processo di problem solving intrinseco alla natura dell’essere umano e alle sue capacità cognitive.

Iniziamo con la domanda di rito del magazine: qual è il vostro rapporto con la tecnologia?
La tecnologia è per noi un'inesauribile fonte di ispirazione e in particolar modo lo è sotto il profilo formale dell’opera. Per precisare, con il riferimento alla “formalità” intendiamo la dimensione concreta e materiale, in cui l’intuizione artistica prende corpo in conformità alle logiche dell'universo digitale, computazionale e tecnologico più in generale. Pertanto, il nostro immaginario visivo si nutre delle pratiche della net art di seconda generazione, in un dialogo ideale con gli internet artists del calibro di Jon Rafman ed Eva & Franco Mattes, e con figure della scena contemporanea quali Federica Di Pietrantonio e Chia Amisola - giusto per citarne alcuni.
In breve, entro la ricerca di HACK la tecnologia si definisce al contempo contenuto semantico e soggetto agente; o ancora, è un medium comunicativo che si fa tema, amplificando le pratiche culturali del presente. Le modalità attraverso cui costruiamo relazioni, identità, narrazioni e archivi di memoria sono di fatto profondamente condizionate dai dispositivi tecnologici, i quali operano come interfacce che modellano il nostro rapporto con la realtà e con l'altro.
Il nostro operato vive dunque di questa ambivalenza: desideriamo restituire una visione lucida ma non distaccata, critica ma profondamente coinvolta, del ruolo che la tecnologia gioca nei nostri mondi interiori e collettivi. Ci interessa quel punto in cui l’esperienza tecnologica smette di essere neutra e inizia a farsi ambigua. Lì dove il virtuale non è più altrove, ma una delle tante forme attraverso cui abitiamo il reale.
Questa è la prima volta che ospitiamo un'intervista con "due anime", quindi vi domanderei alcune cose che potrebbero risultare curiose per i lettori: cosa significa lavorare in un duo artistico? Come ci si accorda sulla visione da dare a un'opera? Capita mai che un'opera nasca dall'idea di una sola tra voi due? Come ci si divide il lavoro?
L’esperienza del lavoro in un duo artistico si configura, a nostro avviso, come un processo di intensa condivisione, in cui il linguaggio comune trascende la semplice somma delle due individualità. La creazione dell’opera si fonda su un dialogo continuo, aperto a prospettive talvolta divergenti, che trovano una loro sintesi in fase di ricerca. Se si dovesse tradurre il nostro approccio collaborativo a un fenomeno processuale, quest’ultimo sarebbe articolato in più fasi: inizialmente, ciascuna di noi elabora una visione rispetto a un tema che intende approfondire.
È in questa fase che vengono esternate le rispettive inclinazioni e ciò non avviene necessariamente nello stesso istante; segue il confronto volto a definire un’idea condivisa, attorno alla quale si svilupperà un’ulteriore analisi circostanziata che andrà a sua volta a rilevare le ipotetiche modalità di esecuzione dell’opera. Può certamente capitare che un’intuizione avanzata da una delle due parti sia esclusa o riesaminata successivamente. Dopo aver portato a compimento le precedenti fasi, i risultati vengono integrati, confluendo in un progetto unitario e coerente.
HACK nasce nel 2021, in un momento di “dubbie incertezze”. Che urgenza vi ha spinto a formare questo duo proprio in quel momento? Cosa cercavate di innescare allora, e cosa cercate oggi?
Nel 2021, anno in cui co-fondammo HACK, fummo d’accordo nel definirci immerse in un clima di “dubbi e incertezze” che lambiva sia noi, sia il nostro intero contesto di riferimento. Provenivamo da una scuola di pittura impostata su presupposti fortemente tradizionali e, dalle conversazioni con i nostri compagni dell’università, pareva fossimo le uniche ad avvertire l’urgenza di indagare i linguaggi dell’arte in rapporto con i dispositivi mediatici. Influenzate dalla retorica del docente Giovanni Morbin e spinte dalla volontà di consolidare le nostre intenzioni artistiche in un manifesto, stilammo così una dichiarazione programmatica che tradusse le nostre aspirazioni in frasi incisive, utilizzando la parola al pari del rivoluzionario.
Occorre precisare che in quel frangente, la nostra conoscenza teorica delle tecnologie e della rete, così come le sue possibili declinazioni in campo artistico, risultava ancora nulla; ma fu proprio la consapevolezza di tale lacuna ad alimentare la nostra vena sperimentale. Fu una fase che, tra le altre cose coincideva con il periodo immediatamente successivo alla crisi pandemica; permanevano ancora le abitudini di una vita quasi obbligatoriamente online e, da una crescente consapevolezza di appartenere a "una generazione di confine" sospesa fra analogico e digitale, ci interrogavamo su come Internet stesse sovrascrivendo i processi creativi, e più in generale le meccaniche sociali.
Oggi quella spinta originaria si è evoluta sino a considerare tali obiettivi più come una riflessione sull’attualità. Abbiamo sostituito l’enfasi sulla "rivoluzione" con un’indagine più cosciente: se prima si cercava di impattare dall’interno lo stato delle cose, ora vige sicuramente molta più consapevolezza nel trovare una propria estetica e una poetica originale. In altri termini, poniamo in analisi i mezzi e i dispositivi di cui ci avvaliamo, alimentiamo una dialettica condivisa e ci adoperiamo affinché la nostra intenzionalità coinvolga un vasto pubblico. Dunque, i dubbi e le incertezze non sono scomparsi, si sono trasformati in domande orientate, capaci di guidare il nostro percorso anziché paralizzarlo.
Lavorate con diversi materiali eterogenei: stampa su Dibond, video, 3D, installazioni, performance... Come nasce una vostra opera? Cosa viene prima: il concetto, il mezzo o l’intuizione estetica?
Nel nostro processo creativo non esiste una metodologia fissa o un ordine prestabilito che determini la genesi dell’opera. Talvolta, il punto di partenza è l’urgenza di approfondire un concetto o un tema; in altri casi, invece, l’impulso iniziale può nascere da un’intuizione estetica o dalla sperimentazione con uno specifico mezzo tecnico. Ad esempio, l’utilizzo di software come Blender o l’esplorazione di pratiche come la fotogrammetria ci hanno portato, in alcune occasioni, a riflettere a posteriori su una possibile cornice teorica in grado di sostenere la sperimentazione stessa.
In questo senso, il nostro approccio si caratterizza per la sua forte flessibilità metodologica, adattandosi di volta in volta alle esigenze e alle specificità del progetto in corso. Un elemento costante e imprescindibile è lo stadio di ricerca. Per quanto possa sembrare evidente, senza un’indagine contestuale accurata, la produzione artistica rischia di rimanere priva delle ragioni che ne giustificano la messa in atto.
Nella vostra presentazione parlate dell'essere “nativi digitali” e della standardizzazione del pensiero. Qual è, secondo voi, l’effetto più significativo dell’essere cresciuti in una società iperconnessa?
Le sfaccettature del fenomeno sono molteplici, ma a nostro avviso, l’effetto più incisivo dell’essere cresciuti in una società iperconnessa, o quantomeno alle origini nella nostra riflessione, è la progressiva omologazione dell’immaginario. La rete permette di accedere a uno spettro sconfinato di visioni, ma l’algoritmo, reiterando ciò che già ottiene consenso, appiattisce le differenze e riconduce molteplici prospettive a un’unica linea di pensiero condiviso.
Da questa compressione scaturiscono due conseguenze complementari: da un lato, la “standardizzazione del pensiero” per l’appunto, riduce la complessità identitaria a formule riconoscibili; dall’altro, affiorano le cosiddette Digital Diseases. Queste ultime rientrano nei dettagli di una ricerca più recente, volta a riflettere sugli utilizzi patologici della tecnologia che costituiscono, regolano e influenzano la vita nel suo insieme e i limiti di un’esistenza costantemente mediata dallo “schermo”. In sintesi, tali disturbi, pur potendo riguardare ciascuno di noi, si manifestano con intensità e sintomatologie differenti, incidendo sulla salute mentale, sui comportamenti quotidiani e sulle relazioni interpersonali.
L’importanza di essere nativi digitali è che, in quanto tali, siamo al tempo stesso creature e agenti critici di tale ambiente. La nostra pratica artistica si propone di spezzare l’eco circolare di informazioni, opinioni e credenze preesistenti, disarticolandone i meccanismi nascosti al fine di trasformarli in una lente analitica con cui decifrare gli esiti della società odierna. In tal modo, restituiamo la giusta profondità al gesto artistico, forzando gli spazi uniformati del reale alla ricerca di possibilità ancora non codificate.
Molte vostre opere sembrano generare un cortocircuito tra estetica pop e riflessione concettuale. Qual è il ruolo del gioco e della cultura digitale condivisa (meme, icone digitali, videogame) nella vostra pratica?
Sebbene molti degli elementi con cui lavoriamo nell’ultimo periodo provengano dall'immaginario videoludico e dai riferimenti alla “rete”, le nostre finalità non sono mai parodiche: affrontiamo questi materiali con un atteggiamento riflessivo, consapevoli della loro capacità di veicolare significati complessi attraverso forme apparentemente povere di contenuti.
L’ironia che impieghiamo non si esaurisce nella superficie estetica dell’opera, ma contribuisce attivamente alla costruzione di un discorso critico all’interno del nostro linguaggio visivo. Senz’altro questa attitudine si è evoluta nel corso del tempo sino ad arrivare agli esiti attuali.
Una parola interessante del vostro statement è “riappropriazione”. Cosa significa per voi hackerare un linguaggio o un medium?
Per noi “hackerare” un linguaggio o un medium significa attuare una “riappropriazione” critica: scomporre il dispositivo nelle sue funzioni essenziali, individuare le incongruenze latenti e ri‑assemblarle al fine di innescare un cortocircuito di senso. Non agiamo da “hacker” nel senso convenzionale del termine; ci affascina piuttosto decifrare i codici culturali che reggono un sistema, sia esso tecnologico, linguistico o artistico, per poi piegarli alle nostre esigenze espressive.
In concreto, vagabondiamo tra i sistemi che Internet rende facilmente disponibili, estrapoliamo elementi a noi emblematici e li riformuliamo secondo la nostra prospettiva. Questo atto di riuso consapevole trasforma ciò che è dato in materia viva, capace di rilevare fragilità e possibilità narrative inedite. L’opera assume così la forma di un "sabotaggio": non distrugge violentemente il linguaggio originario, ma lo rimodella, facendone emergere i limiti e restituendolo infine al pubblico come strumento di riflessione condivisa.
Le vostre opere si muovono tra fisico e digitale, ma anche tra personale e collettivo. Che ruolo gioca l’esperienza intima nella vostra arte? Quanto vi mettete in gioco, in prima persona, nei lavori che realizzate?
Inizialmente, quando abbiamo fondato il duo artistico, avevamo concepito HACK come un’identità “altra” che potesse in qualche modo oscurare le nostre individualità, permettendoci di spostare l'attenzione sulla sua dimensione collettiva. Tuttavia, con il tempo, abbiamo compreso come la nostra soggettività rivestisse un ruolo fondamentale: ne è un esempio evidente l’opera Se la morte avesse i tuoi occhi (2024) in cui l’elemento autobiografico mette in scena il nostro intimo sguardo nell’essere figlie, riportando nell’opera segni inconfessati. D’altro canto, in lavori più recenti, pur adottando linguaggi differenti (come file PNG o oggetti tridimensionali), permane una componente introspettiva, veicolata mediante simbologie e referenze che rimandano direttamente alle nostre identità, anche quando esse non vengono esplicitamente rappresentate.
Nonostante ciò, il nostro intento non è mai stato quello di proporre un’arte puramente autoreferenziale. Secondo questa visione, l’individualità non è negata, ma si orienta come punto di partenza per una narrazione condivisibile, che rifugge pertanto l’auto-espressione fine a sé stessa.
Se doveste spiegare la vostra missione artistica a un bambino di 10 anni e a una nonna di 90, cosa direste a ciascuno di loro?
Se dovessimo spiegare la nostra missione artistica a due interlocutori così distanti tra loro per età, sicuramente imposteremmo la comunicazione in maniera differente.
Ad un bambino, diremmo che l’arte, generalmente intesa, non è qualcosa da apprendere come un dovere scolastico e di non accontentarsi di ciò che gli viene insegnato in modo convenzionale. Cercheremmo di trasmettere l’idea che la realtà e i mezzi con cui essa si manifesta, può essere guardata da infinite prospettive e che l’arte è un momento di esplorazione, di studio e di libertà; nella stessa maniera in cui si domanda il perché delle cose, cercando le risposte oltre l’evidente.
In questo senso potremmo porre come esempio il nostro lavoro, dove sussiste il desiderio di “hackerare”, ovvero di decostruire e ricodificare i linguaggi visivi e comunicativi che ci circondano quotidianamente.
Con una signora anziana, la conversazione virerebbe sui motivi per cui scegliamo certi temi piuttosto che altri, spiegandole che abbiamo bisogno di esprimere ciò che sentiamo profondamente nostro. Le racconteremmo che la nostra arte parte sempre da una riflessione personale sul mondo contemporaneo e sulle nostre esperienze. Le diremmo anche che per noi è fondamentale condividere con il pubblico una visione critica e consapevole della società in cui viviamo, perché ogni generazione ha il diritto e il dovere di raccontare il proprio tempo e le proprie inquietudini. Emergerebbe che spesso, come duo, ci interroghiamo sulla società fortemente contraddittoria in cui viviamo; in questa rilettura, illustreremmo quanto, attraverso la nostra pratica, ci sia una pseudo-resistenza rispetto a una visione omologante e passiva della realtà.
Guardando al futuro: quali tecnologie vi incuriosiscono maggiormente? E in che direzione vorreste evolvere il vostro lavoro?
Riflettere sull’avvenire è per noi un esercizio tanto necessario quanto arduo: la natura effimera e mutevole dei dispositivi e dei paradigmi tecnologici rende ogni pronostico una vera sfida.
Tuttavia, se dovessimo individuarne uno tra tutti, sarebbe difficile non nominare l'intelligenza artificiale. Essa rappresenta oggi la punta dell'iceberg, un argomento che accende il dibattito pubblico, seppur non costituisca il centro della nostra pratica artistica. Sicuramente, nella ricerca di HACK, l'IA non viene interpretata semplicemente come un surrogato della creatività umana a cui affidare il processo creativo senza riserve, bensì come oggetto di un’indagine critica. Attualmente ci limitiamo a osservarne le implicazioni estetiche, teoriche e sociali, interrogandoci sul modo in cui essa ridefinisce concetti fondamentali e sulle possibili distorsioni e bias che continua a portare con sé.
Per quanto riguarda le direzioni future che desideriamo esplorare con il duo, una delle ipotesi più stimolanti è la realizzazione di opere che fondono oggetti reali con ambienti costruiti artificialmente. Crediamo che nel prossimo futuro questo dialogo diventerà non soltanto più fluido e sottile, bensì trasparente. La nostra intenzione è quindi esplorare nuove modalità e funzioni per creare una reciprocità tra questi due mondi, integrando la fisicità nello spazio virtuale e, al contempo, conferendo all'esperienza digitale una concretezza tangibile. La ricerca si estende anche a un'indagine sullo stato attuale della “rete”, ormai completamente integrata nella vita quotidiana e permeata da un coinvolgimento emotivo senza precedenti. Non possiamo trascurare i nuovi sviluppi che spingono internet verso processi di centralizzazione, capaci di relegare ai margini il dato umano, sollevando questioni cruciali sui futuri equilibri di potere e significato.
Riconosciamo quindi nell'intelligenza artificiale un nodo simbolico fondamentale, destinato a riverberare nei prossimi decenni, ma non la consideriamo l'unico ambito di ricerca rilevante. Continueremo a interrogare il presente, dalle Digital Diseases ai confini sempre più labili tra virtualità e realtà fisica, lasciando che sia l’opera, di volta in volta, a modellare le domande che essa stessa solleva.
L’angolo degli annunci
Questo è un nuovo spazio, precedentemente integrato nella parte introduttiva del magazine, che voglio dedicare a vari tipi annunci legati a questo progetto.

Per il 2025 voglio tentare di trasformare questo magazine in una vera e propria Startup innovativa, collocata all’intersezione tra il mondo dei media e della tecnologia. Per farlo, le mie sole forze non bastano e cerco qualcuno con cui espandere il team di lavoro, così da poter creare più contenuti e portare gli approfondimenti di Tales from the Latent Space anche su Instagram per ampliare la portata del progetto. Cerco quindi una collaborazione a medio-lungo termine per gestire la pagina del magazine e creare più contenuti. Si offre una quota in quella che sarà la futura azienda legata al magazine (con un contratto) e formazione di alto livello sui principali strumenti AI, in cambio di una ragionevole quantità di tempo da concordare. Se l'idea ti intriga o conosci qualcuno con la giusta ambizione e competenza che possa abbracciare questa missione, contattami su LinkedIn.
Prossimamente, condividerò anche il business plan della startup, che si chiamerà Monumenta AI e non sarà legata solo ai media, insieme a un manifesto d’intenti che racconti la visione complessiva del progetto.